目录
1. 使用
1.1 c_str()
1.2 find() & rfind()
1.3 substr()
1.4 打印网址的协议域名等
1.5 find_first_of()
2. string() 模拟实现
2.1 构造函数的模拟实现
2.2 operator[] 和 iterator 的模拟实现
2.3 push_back() & append() & += 的模拟实现
2.4 insert() & erase() 的模拟实现
2.5 resize() 模拟实现
2.6 析构函数和复制重载模拟
大部分的用法我在上一篇已经讲解过了,这边文章主要讲解还有的部分用法以及string类的模拟实现。
1. 使用
1.1 c_str()
- c_str() 用于返回一个指向以 null 结尾的 C 字符串(即以 null 终止的字符数组)的指针,该字符串包含了
std::string对象的内容。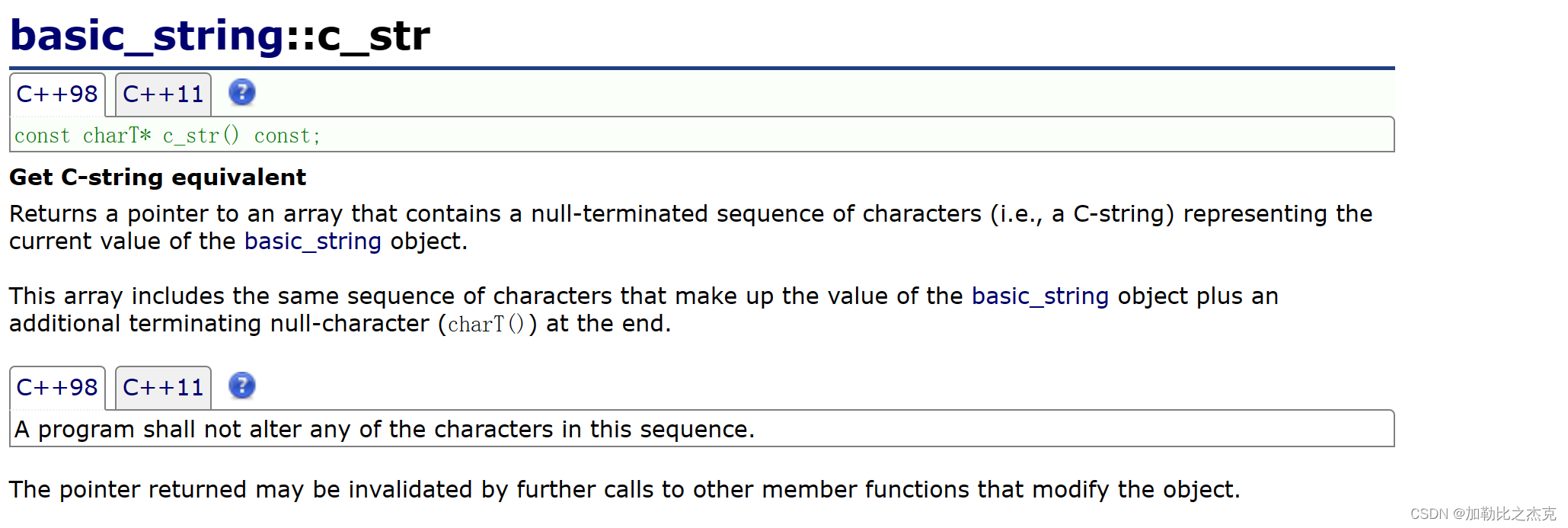
void string_test1()
{std::string str("Hello, world!");// 使用 c_str() 返回指向以 null 结尾的 C 字符串的指针const char* cstr = str.c_str();// 打印返回的 C 字符串std::cout << "C string: " << cstr << std::endl;
}1.2 find() & rfind()
find 函数用于在字符串中查找子串。find 函数有多个重载版本,可以根据需要进行使用。主要的两个版本如下:
-
size_t find(const string& str, size_t pos = 0) const;这个版本的find函数在当前字符串中从位置pos开始查找子串str,并返回找到的子串的第一个字符的位置索引。如果未找到子串,则返回string::npos。 -
size_t find(const char* s, size_t pos = 0) const;这个版本的find函数与上一个版本类似,但接受一个 C 风格的字符串作为参数,而不是std::string对象。 -
其他版本:

void string_test2()
{std::string str = "Hello, world!";std::string substr = "world";// 在字符串中查找子串size_t found = str.find(substr);if (found != std::string::npos) {std::cout << "子串 '" << substr << "' 在字符串中的位置索引为: " << found << std::endl;}else {std::cout << "未找到子串 '" << substr << "'." << std::endl;}
}rfind 用于在字符串中从后向前查找子串,并返回找到的子串的第一个字符的位置索引。
- 主要用法:size_type rfind (const basic_string& str, size_type pos = npos) const;
- 其他用法:

void string_test2()
{std::string str = "Hello, world!";std::string substr = "world";// 在字符串中查找子串size_t found = str.rfind(substr);if (found != std::string::npos) {std::cout << "子串 '" << substr << "' 在字符串中的位置索引为: " << found << std::endl;}else {std::cout << "未找到子串 '" << substr << "'." << std::endl;}
}1.3 substr()
substr 是 C++ 中 std::string 类的成员函数,用于从字符串中提取子串:
-
basic_string substr (size_type pos = 0, size_type len = npos) const; - 其他用法:

这里是这两个重载函数的参数说明:
pos:指定子串的起始位置,即要提取的子串在原始字符串中的起始索引。- len:可选参数,指定要提取的字符数目。如果不指定或者指定为
npos,则提取从pos开始直到字符串末尾的所有字符。
void string_test3()
{std::string str = "Hello, world!";// 提取子串,从索引位置 7 开始,包括 5 个字符std::string sub1 = str.substr(7, 5);std::cout << "子串1: " << sub1 << std::endl;// 提取子串,从索引位置 7 开始,直到字符串末尾的所有字符std::string sub2 = str.substr(7);std::cout << "子串2: " << sub2 << std::endl;}1.4 打印网址的协议域名等
- 我们可以使用 find() 和 substr() 分开打印网址的协议和域名
void string_test4()
{string url1("https://legacy.cplusplus.com/reference/string/basic_string/substr/");string url("https://mp.csdn.net/mp_blog/creation/editor?spm=1000.2115.3001.4503");string protocol;string domain;string port;size_t pos = 0;pos = url.find(":");if (pos != string::npos){protocol = url.substr(0, pos);}int pos1 = pos + 3;pos = url.find('/', pos1);if (pos1 != string::npos){domain = url.substr(pos1, pos - pos1);}int pos2 = pos + 1;port = url.substr(pos2);cout << protocol << endl;cout << domain << endl;cout << port << endl;
}
1.5 find_first_of()
find_first_of 用于在字符串中查找第一个与指定字符序列中的任何一个字符匹配的字符,并返回其位置索引,主要用法如下:
-
size_type find_first_of (const basic_string& str, size_type pos = 0) const;
这里是参数说明:
str:指定要搜索的字符序列。pos:可选参数,指定搜索的起始位置。默认值为 0,表示从字符串的开头开始搜索。
- 其他用法:

用法示例:
void string_test5()
{std::string str("PLease, replace the vowels in this sentence by asterisks.");std::string::size_type found = str.find_first_of("aeiou");while (found != std::string::npos){str[found] = '*';found = str.find_first_of("aeiou", found + 1);}std::cout << str << '\n';
}2. string() 模拟实现
2.1 构造函数的模拟实现
- 无参构造,切忌不能全都初始化为0,这里会导致未定义的错误。
string():_string(nullptr),_size(0),_capacity(0){}const char* c_str()
{return _string;
}- 正确定义方法如下:
string():_string(new char[1]),_size(0),_capacity(){_string[0] = '\0';}- 但一般不会这样定义,一般定义全缺省的形式:
string(const char* ch = ""):_size(strlen(ch)){_capacity = _size;// 多开一个空间用来存放 '\0'_str = new char[_capacity + 1];strcpy(_str, ch);}2.2 operator[] 和 iterator 的模拟实现
- operator[] 是一个运算符重载,返回第pos个位置的值,代码如下:
size_t size() const
{return _size;
}// 注意这里是传引用返回,不是传值返回,传值就不能改变_str() 里面的值了
char& operator[](size_t pos)
{assert(pos >= 0 && pos < _size);return _str[pos];
}void string_test2()
{string str1("hello world");for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;
}- 如果对于const的成员,就要用const来修饰函数,并且要求返回值不能修改,那么返回值也要加上const来修饰:
const char& operator[](size_t pos) const
{assert(pos >= 0 && pos < _size);return _str[pos];
}- 测试代码
void string_test2(){string str1("hello world");// const 类型对象const string str2("hello handsome boy");for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;// 可以进行修改for (size_t i = 0; i < str1.size(); ++i){str1[i]++;}cout << endl;for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;for (size_t i = 0; i < str2.size(); ++i){cout << str2[i] << " ";}cout << endl;// 会报错,不能进行修改/*for (size_t i = 0; i < str2.size(); ++i){str2[i]++;}*/}- iterator 在上一篇文章将结果,是类似于指针的形式,但是实际上可以拿指针来实现,也可以不用指针实现,以下是用指针实现的模式。
- 首先要有begin() 和 end() 两个函数,如下:
typedef char* iterator; iterator begin() {return &_str[0]; }iterator end() {return &_str[_size]; } - 对于const类型与非const构成重载:
typedef const char* const_iterator; const_iterator begin() const {return &_str[0]; }const_iterator end() const {return &_str[_size]; } - 测试代码
void string_test3(){string str1("hello world");const string str2("hello handsome boy");string::iterator it = str1.begin();while (it != str1.end()){cout << *it << " ";++it;}cout << endl;it = str1.begin();while (it != str1.end()){++(*it);++it;}while (it != str1.end()){cout << *it << " ";++it;}cout << endl;string::const_iterator itt = str2.begin();while (itt != str2.end()){cout << *itt << " ";++itt;}// 会报错/*itt = str2.begin();while (itt != str2.end()){++(*itt);++itt;}*/}
2.3 push_back() & append() & += 的模拟实现
- 既然要插入字符串,那么肯定是需要扩容的,在库中可以使用 reserve() 进行扩容,我们也可以手动实现一个 reserve() 函数。
实现思路如下:
- 先new一块大小为n的空间;
- 然后把_str中的内容拷贝到tmp中;
- 接着释放掉_str指向的空间;
- 最后再让_str指向tmp。
void reserve(size_t n = 0)
{if (n > _capacity){char* tmp = new char[n];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}
}push_back的实现思路:
- 首先检查_size 和 _capacity 相不相等,如果相等就需要扩容;
- 在_size的位置插入字符,然后_size++;
- 在_size的位置插入'\0'。
void push_back(char ch)
{if (_size == _capacity){int newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}_str[_size++] = ch;_str[_size] = '\0';
}append插入的实现思路:
- 首先计算要插入的字符串的长度len;
- 如果_size + len > _capacity 就需要扩容;
- 再用strcpy() 把字符串拷贝进_str。
string& append(const char* ch)
{size_t len = strlen(ch);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, ch);_size = _size + len;return *this;
}operator+=的实现就直接调用append 和 push_back 就可以了
string& operator+=(char ch)
{push_back(ch);return *this;
}string& operator+=(const char* ch)
{append(ch);return *this;
}- 测试代码
void string_test4(){string str1("hello world");str1.push_back(' ');str1.push_back('h');str1.push_back('e');str1.push_back('l');str1.push_back('l');str1.push_back('o');str1.push_back(' ');str1.push_back('h');str1.push_back('a');str1.push_back('n');str1.push_back('d');str1.push_back('s');str1.push_back('o');str1.push_back('m');str1.push_back('e');str1.push_back(' ');str1.push_back('b');str1.push_back('o');str1.push_back('y');str1.append(" hello handsome boy");for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;}void string_test5(){string str1("hello world");str1 += ' ';str1 += "hello handsome boy";for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;}2.4 insert() & erase() 的模拟实现
insert() 就是在某个位置插入字符或者字符串,首先讲一下插入字符思路如下:
- 判断pos是否合法;
- 检查是否需要扩容;
- 将pos位置之后的字符全都向后移动一位;
- 在pos位置插入字符;
- _size++;
注意这里的end要给_size + 1,如果给_size,当pos == 0的时候,最后一轮进循环end会变为-1,然而end是size_t类型的,-1就会变为整形的最大值,就会死循环。
就算把end改为int类型也不行,因为括号内比较的类型是end和pos,而pos是size_t类型的,会发生类型转换,还是会把end转换成size_t类型,因此还是会死循环。
string& insert(size_t pos, char ch)
{assert(pos >= 0 && pos <= _size);if (_size == _capacity){size_t newcapacity = _capacity == 0 ? 4 : 2 * _capacity;reserve(newcapacity);}size_t end = _size + 1;while (end > pos){_str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;return *this;
}insert() 插入字符串类型:
- 计算是否需要扩容以及pos位置是否合法;
- 将第pos位置之后的元素移动len个字符;
- 在pos位置插入字符串;
- _size加上len;
这里的移动有两种思路,一种是每次移动一次,移动len次
另一种是直接移动len次
先看一下每次移动一次的,时间复杂度为 O(N^2) , 比较容易理解:
string& insert(size_t pos, const char* ch)
{assert(pos >= 0 && pos <= _size);size_t len = strlen(ch);if (len + _size > _capacity){reserve(len + _size);}size_t pos1 = pos;while (len--){size_t end = _size + 1;while (end > pos1){_str[end] = _str[end - 1];--end;}_str[pos1] = *ch;++ch;++pos1;++_size;}return *this;
}一次直接移动len次,以下是动图图解:

string& insert(size_t pos, const char* ch)
{assert(pos >= 0 && pos <= _size);size_t len = strlen(ch);if (len + _size > _capacity){reserve(len + _size);}int end = _size + len;while (end >= pos + len){_str[end] = _str[end - len];--end;}strncpy(_str + pos, ch, len);_size += len;return *this;
}erase()就是删除某个位置的元素,较为容易,直接上代码:
string erase(size_t pos = 0, size_t len = npos)
{assert(pos >= 0 && pos < _size);if (len >= _size - pos){_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + 1);_size = _size - len;}return *this;}- 测试代码
void string_test6(){string str1("hello world");str1.insert(0, 'x');for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;str1.insert(12, 'y');for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;str1.insert(0, "zzz");for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;str1.insert(16, "dddddddddddd");for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;str1.erase(16,12);for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;}2.5 resize() 模拟实现
之前讲过 resize() 的三种形式,这里就不详细讲解了,有兴趣的可以看上一篇文章:
STL —— string(2)-CSDN博客![]() https://blog.csdn.net/m0_68617301/article/details/136954250
https://blog.csdn.net/m0_68617301/article/details/136954250
这里直接讲模拟实现方式:
void resize(size_t n, char ch = '\0')
{if (n < _size){_str[n] = '\0';}else if (n >= _size){reserve(n);for (size_t i = _size; i < n; i++){_str[i] = ch;}_str[n] = '\0';_size = n;}return *this;
}- 测试代码
void string_test7(){string str1("hello world");str1.resize(20, 'x');for (size_t i = 0; i < str1.size(); ++i){cout << str1[i] << " ";}cout << endl;cout << str1.size() << endl;}2.6 析构函数和复制重载模拟
- 这里的析构函数同样也涉及到深浅拷贝的问题,因为这里也同样有一个在堆上开辟的空间,如果调用编译器自己生成的析构函数,就会造成对同一块空间重复释放的问题,需要我们自己编写析构函数:
~string()
{_size = _capacity = 0;if (_str != nullptr){delete[] _str;}
}string& operator=(string& str)
{if (this != &str){_size = str._size;_capacity = str._capacity;char* tmp = new char[_capacity];delete[] _str;strcpy(tmp, str._str);_str = tmp;}return *this;
}










![[自研开源] 数据集成之分批传输 v0.7](https://img-blog.csdnimg.cn/direct/cc203271f1e94b9186cd195781d39c03.png)