文章目录
- 一、MySQL主从搭建
- 1.MySQL主从的目的?
- 2.MySQL主从原理
- 3.搭建步骤
- 二、Django中实现MySQL读写分离
- 1.使用sqlite实现读写分离
- 2.MySQL实现读写分离
- 三、Django中使用连接池
- 1.使用池的目的
- 2.Django中使用MySQL连接池
一、MySQL主从搭建
1.MySQL主从的目的?
1.读写分离读写分离,在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读)2.单个实例并发量低,提高并发量是提升I/O性能;随着日常生产中业务量越来越大,I/O访问频率越来越高,单机无法满足,此时做多库的存储,有效降低磁盘I/O访问的频率,提高了单个设备的I/O性能。也即减少了磁盘I/O的频率,分摊了数据库压力。3.只在主库写,读数据都去从库确保数据安全;做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据的丢失。
2.MySQL主从原理
MySQL服务器之间的主从同步是
基于二进制日志机制(binlog),主服务器使用二进制日志(binlog)来记录数据库的变动情况,从服务器通过读取和执行该日志文件来保持和主服务器的数据一致
'MySQL主从原理'步骤一:主库db的更新事件(update、insert、delete)被写到binlog日志中步骤二:从库发起连接,连接到主库步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog日志内容并写入到relay log中步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db中
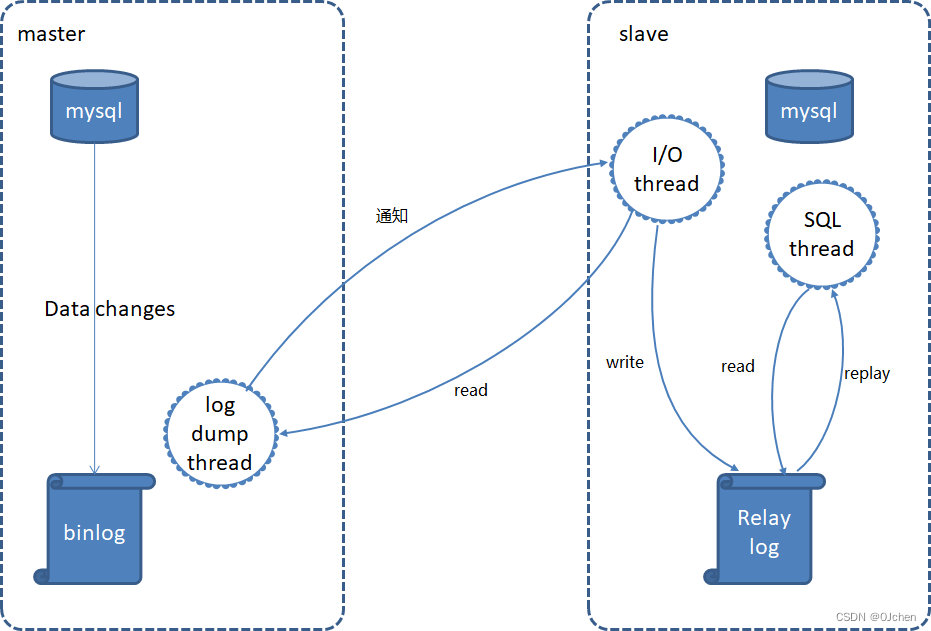
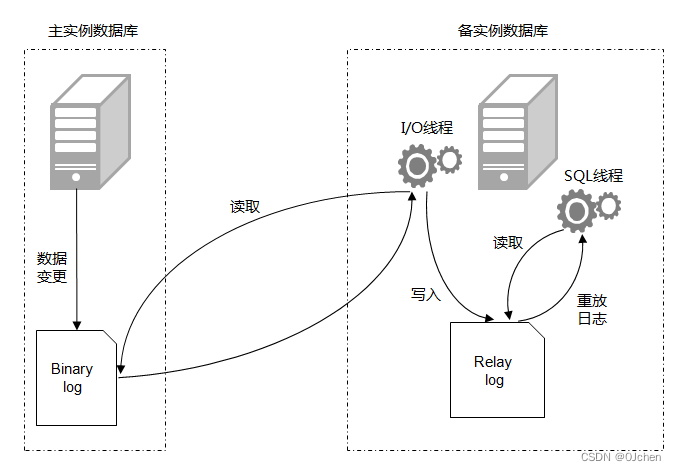
3.搭建步骤
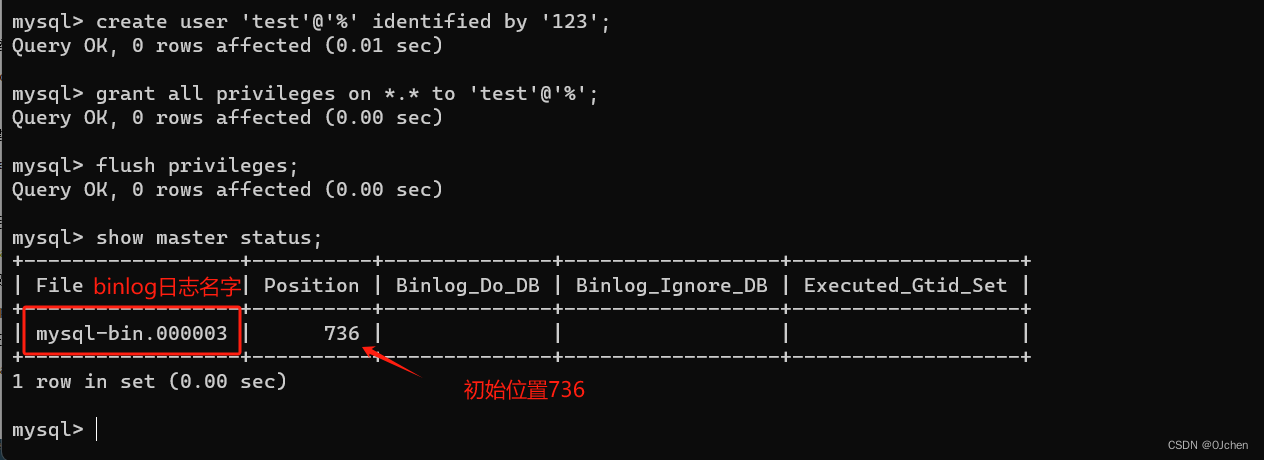
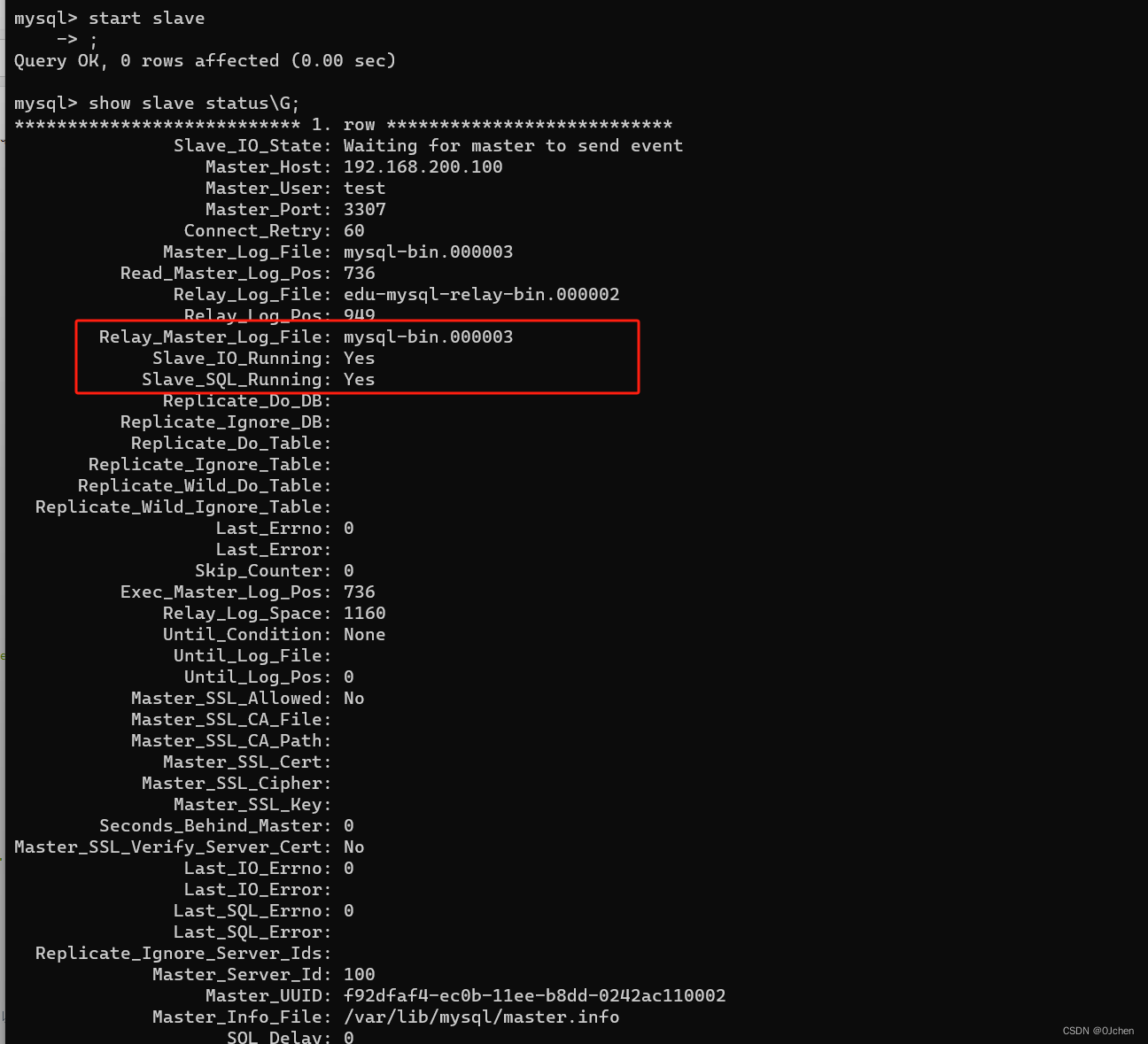
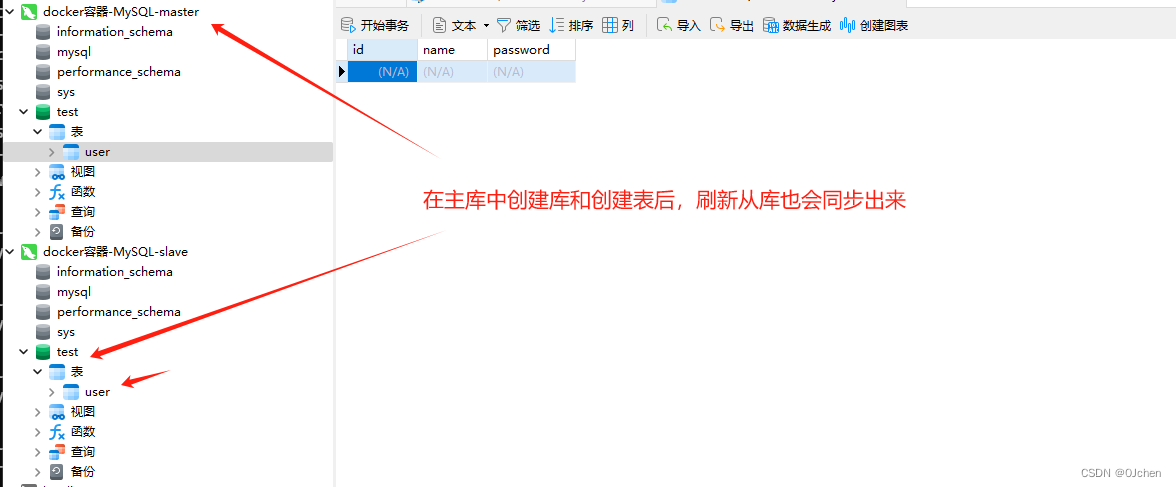
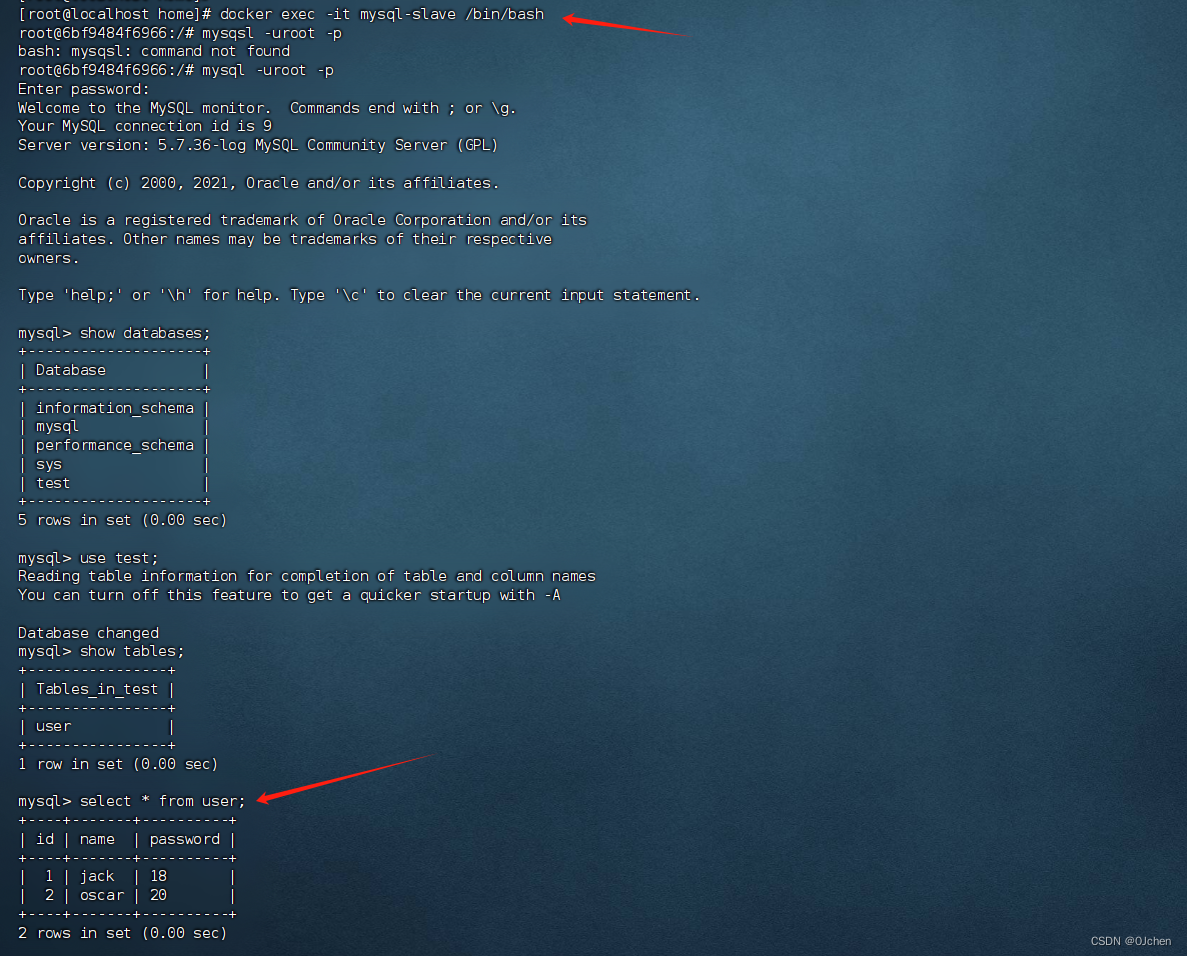
'我这里演示,用两台机器(使用MySQL的docker镜像模拟两台机器)'-注意:搭建主从,MySQL的版本必须要完全一致,我这里在docker上面镜像模拟,所以用的同一个镜像-主库:192.168.200.100 3307-从库:192.168.200.100 3306第一步:拉取MySQL5.7的镜像第二步:创建文件夹,文件(目录映射)'主库的'mkdir /home/mysqlmkdir /home/mysql/conf.dmkdir /home/mysql/data/touch /home/mysql/my.cnf'从库的'mkdir /home/mysql1mkdir /home/mysql1/conf.dmkdir /home/mysql1/data/touch /home/mysql1/my.cnf第三步(重要):编写mysql配置文件(主,从)-主库配置,参照自己本机安装的MySQL配置的my.ini来即可,但是会有区别[mysqld]user=mysqlcharacter-set-server=utf8default_authentication_plugin=mysql_native_passwordsecure_file_priv=/var/lib/mysqlexpire_logs_days=7sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONmax_connections=1000# 搭建主从这下面两句必须加,服务端设置的id号,开启MySQL的binlog日志server-id=100log-bin=mysql-bin[client]default-character-set=utf8[mysql]default-character-set=utf8-从库配置[mysqld]user=mysqlcharacter-set-server=utf8default_authentication_plugin=mysql_native_passwordsecure_file_priv=/var/lib/mysqlexpire_logs_days=7sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONmax_connections=1000# 同上一样,设置服务端的id号(不能重复),开启从库的relay log日志server-id=101 log-bin=mysql-slave-bin relay_log=edu-mysql-relay-bin [client]default-character-set=utf8[mysql]default-character-set=utf8第四步:启动mysql容器,并做端口和目录映射docker run -di -v /home/mysql/data/:/var/lib/mysql -v /home/mysql/conf.d:/etc/mysql/conf.d -v /home/mysql/my.cnf:/etc/mysql/my.cnf -p 3307:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7docker run -di -v /home/mysql1/data/:/var/lib/mysql -v /home/mysql1/conf.d:/etc/mysql/conf.d -v /home/mysql1/my.cnf:/etc/mysql/my.cnf -p 3306:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7第五步:连接主库mysql -uroot -P 3307 -h 192.168.200.100 -p-输入密码-在主库创建用户并授权-创建test用户create user 'test'@'%' identified by '123';-授权用户grant all privileges on *.* to 'test'@'%' ;-刷新权限flush privileges;-查看主服务器状态(显示如下图三)show master status; 第六步:连接从库mysql -uroot -P3306 -h 192.168.200.100 -p-输入密码-配置change master to master_host='192.168.200.100',master_port=3307,master_user='test',master_password='123',master_log_file='mysql-bin.000003',master_log_pos=0;'''配置详解change master to master_host='MySQL主服务器IP地址', master_user='之前在MySQL主服务器上面创建的用户名', master_password='之前创建的密码', master_log_file='MySQL主服务器状态中的二进制文件名', master_log_pos='MySQL主服务器状态中的position值';'''-启用从库start slave;-查看从库状态(如下图四)show slave status\G; # 保证IO和sql线程是yes的 \G是以json形式展示,不写默认以列表展示(列表展示有点乱)第七步:在主库创建库,创建表,插入数据,看从库(本地看和远端看,图五六)

二、Django中实现MySQL读写分离
1.使用sqlite实现读写分离
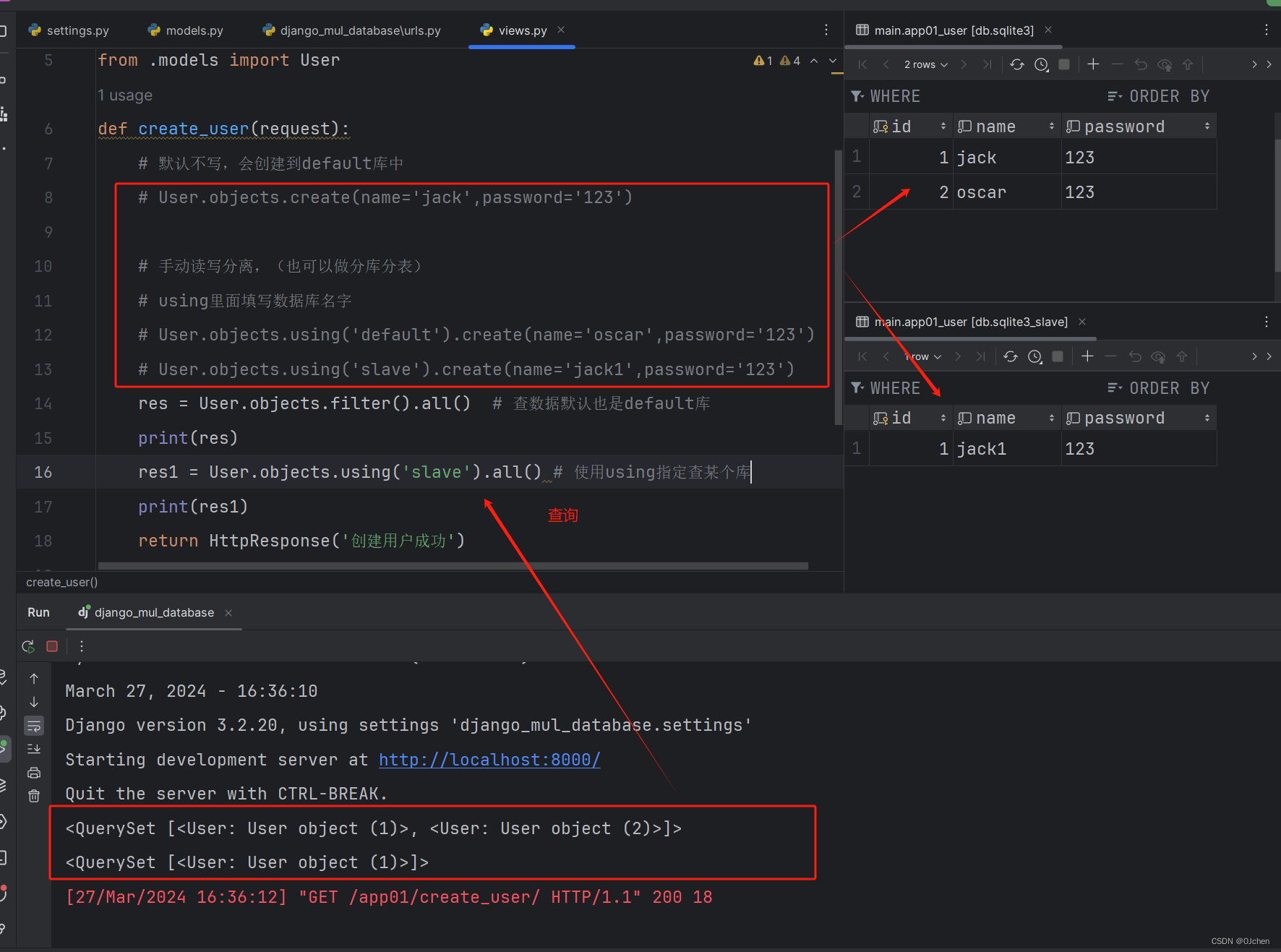
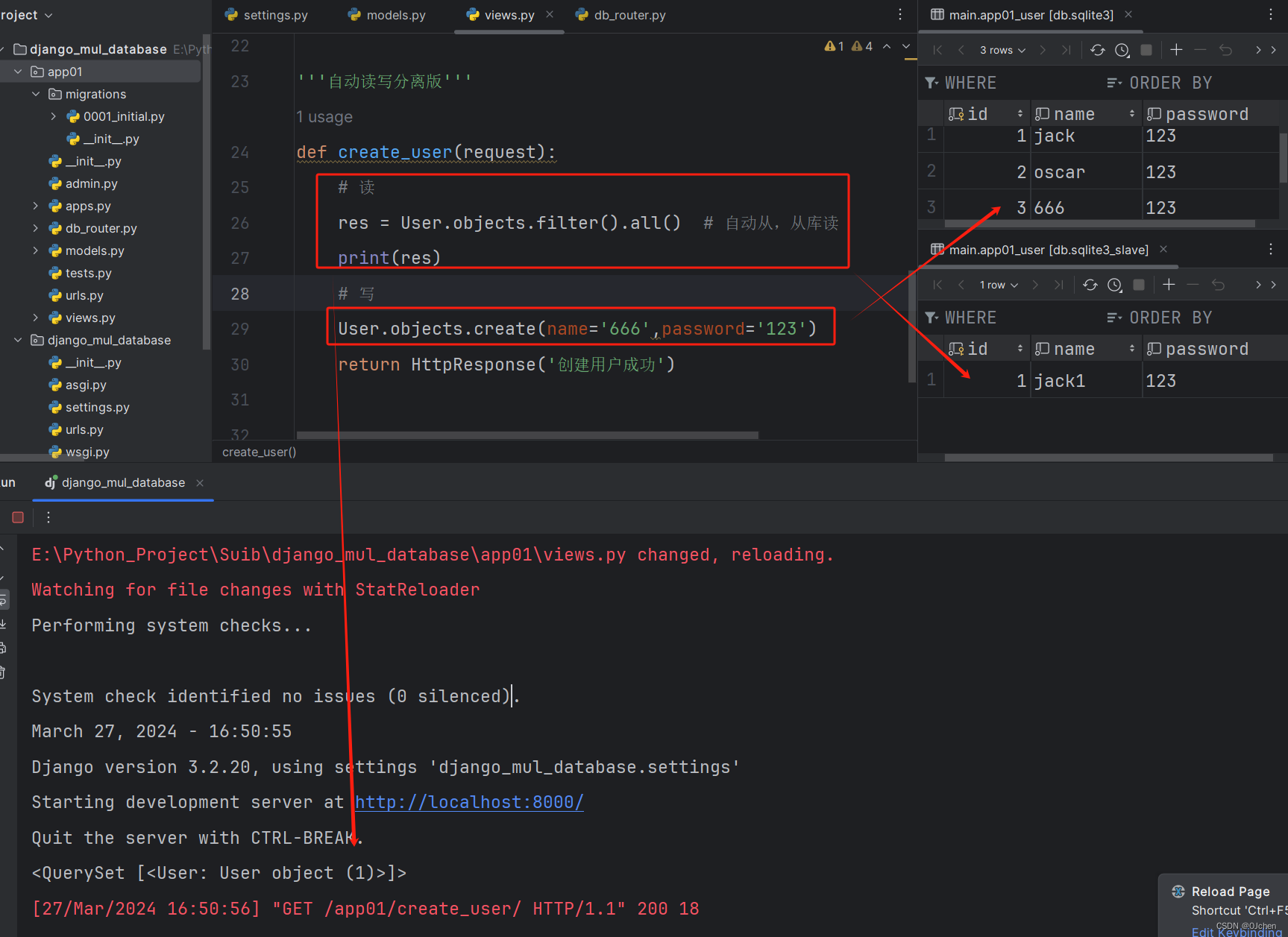
'这里先使用sqlite实现'第一步:配置文件配置多数据库DATABASES = {'default': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db.sqlite3',},'slave': {'ENGINE': 'django.db.backends.sqlite3','NAME': BASE_DIR / 'db.sqlite3_slave',}}第二步:(配置models.py),然后迁移表时,可以指定迁到哪个库中'models.py'class User(models.Model):name = models.CharField(max_length=32)password = models.CharField(max_length=32)python manage.py makemigrationspython manage.py migratemigrate --database=配置文件中数据库配置的名字 # 不写默认迁移到defaultpython manage.py migrate --database=slave第三步:配置视图,创建表数据(下图一) 手动读写分离版'view.py'from django.shortcuts import render,HttpResponsefrom .models import Userdef create_user(request):# 默认不写,会创建到default库中# User.objects.create(name='jack',password='123')# 手动读写分离,(也可以做分库分表)# using里面填写数据库名字# User.objects.using('default').create(name='oscar',password='123')User.objects.using('slave').create(name='jack1',password='123')res = User.objects.filter().all() # 查数据默认也是default库print(res)res1 = User.objects.using('slave').all() # 使用using指定查某个库print(res1)return HttpResponse('创建用户成功')第四步:自动读写分离版'写一个py文件,db_router.py(命名随便),然后在其中写一个类'class DBRouter(object):# 读def db_for_read(self, model, **hints):# 如果有多个从库就可以做负载 ['db1','db2','db3',],随机抽一个(random)return 'slave'# 写def de_fore_write(self, model, **hints):return 'default''然后在配置文件中配置一下,就是上面写的db_router.py的路径'DATABASE_ROUTERS = ['app01.db_router.DBRouter', ]这样之后就可以自动读写分离了(看图二)
2.MySQL实现读写分离
'使用上面搭建的MySQL主从来做'第一步:在配置文件中配置MySQL数据库'''使用MySQL做读写分离(远端)'''DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'userv','USER': 'root','HOST': '192.168.200.100','PORT': 3307,'PASSWORD': '123456',},'slave': {'ENGINE': 'django.db.backends.mysql','NAME': 'userv','USER': 'root','HOST': '192.168.200.100','PORT': 3306,'PASSWORD': '123456',}}第二步:迁移表python manage.py makemigrationspython manage.py migrate第三步:直接在视图层查询或添加数据测试'''MySQL版读写分离'''def create_user(request):# 写# User.objects.create(name='jack66',password='123')# 读res = User.objects.filter(id=1).first()print(res)print(res.name)return HttpResponse('创建用户成功')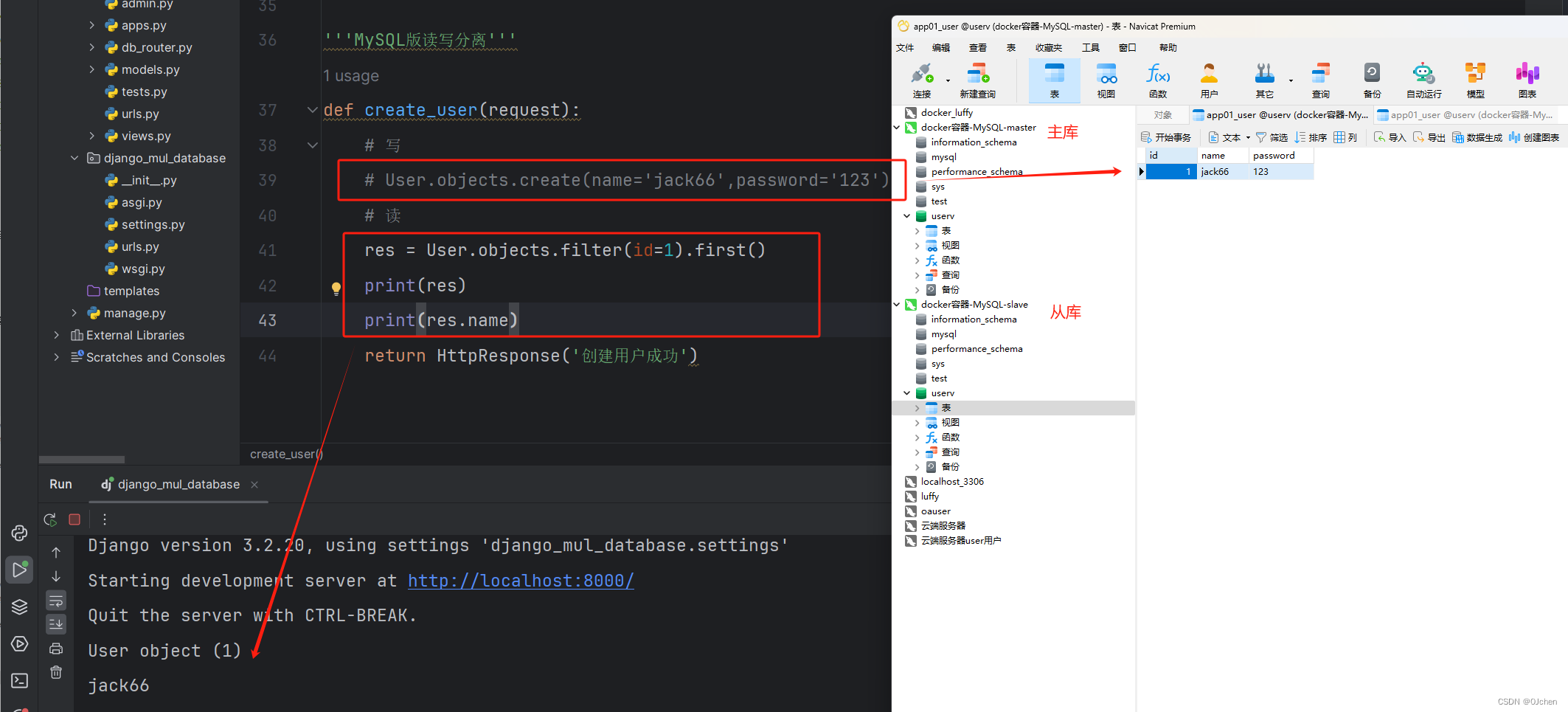
三、Django中使用连接池
1.使用池的目的
使用池的目的 --->为了控制链接数量-线程池-redis连接池-自带连接池 redis.ConnectionPool-mysql连接池-pymysql:dbutils模块-sqlalchemy:自带的-django:没有连接池-一个请求就是一个链接,用完就释放-第三方连接池
2.Django中使用MySQL连接池
1.安装pip install django-db-connection-pool2.在配置文件中配置(用上面案例的修改一下即可,把ENGINE修改一下,添加POOL_OPTIONS)DATABASES = {'default': {'ENGINE': 'dj_db_conn_pool.backends.mysql','NAME': 'userv','USER': 'root','HOST': '192.168.200.100','PORT': 3307,'PASSWORD': '123456','POOL_OPTIONS': {'POOL_SIZE': 2,'MAX_OVERFLOW': 2}},'slave': {'ENGINE': 'dj_db_conn_pool.backends.mysql','NAME': 'userv','USER': 'root','HOST': '192.168.200.100','PORT': 3306,'PASSWORD': '123456','POOL_OPTIONS': {'POOL_SIZE': 2,'MAX_OVERFLOW': 2}}}2.1.起一个脚本,弄1000个线程执行from threading import Threadimport requestsdef task():res = requests.get('http://127.0.0.1:8000/app01/create_user/')print(res.text)if __name__ == '__main__':l = []for i in range(1000):t = Thread(target=task)t.start()l.append(t)for i in l:i.join()3.查看MySQL有多少链接数:show status like 'Threads%';'下图一是,配置连接池的效果,下图二是没有配置连接池的效果'
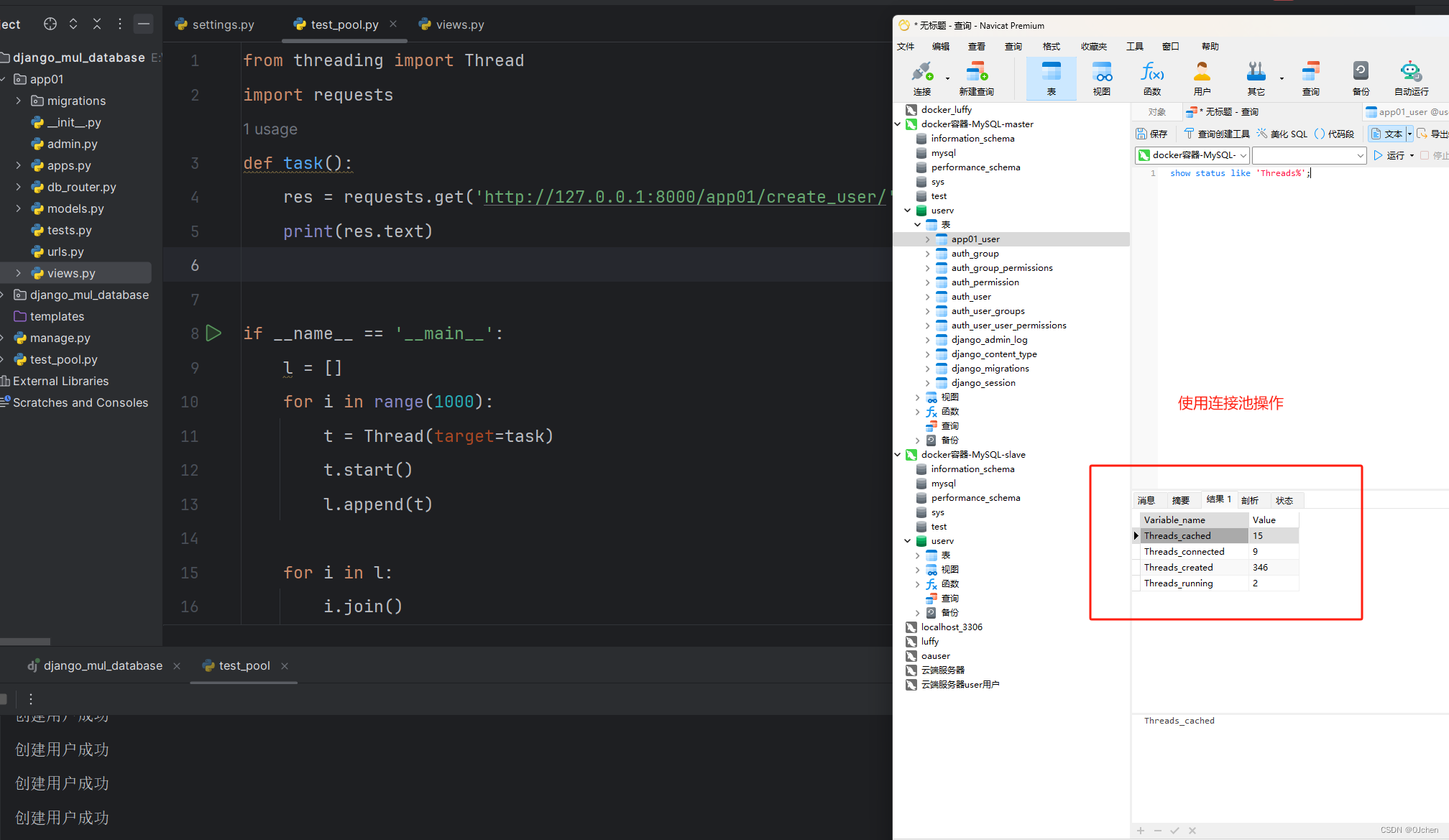
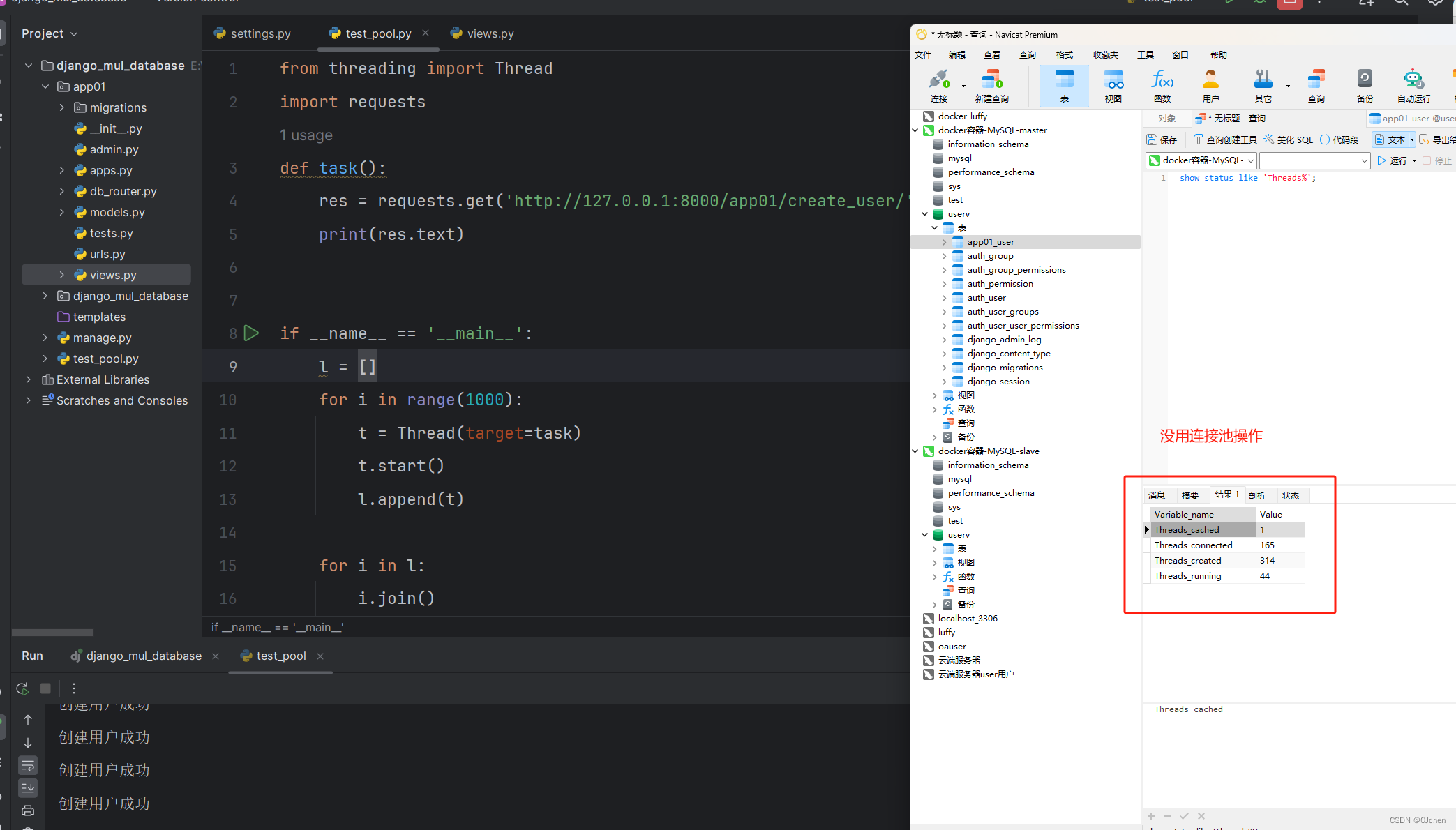








![PASSL代码解读[01] readme](https://img-blog.csdnimg.cn/direct/a9a92ca718344ed5a2bf63a7de5540df.png)