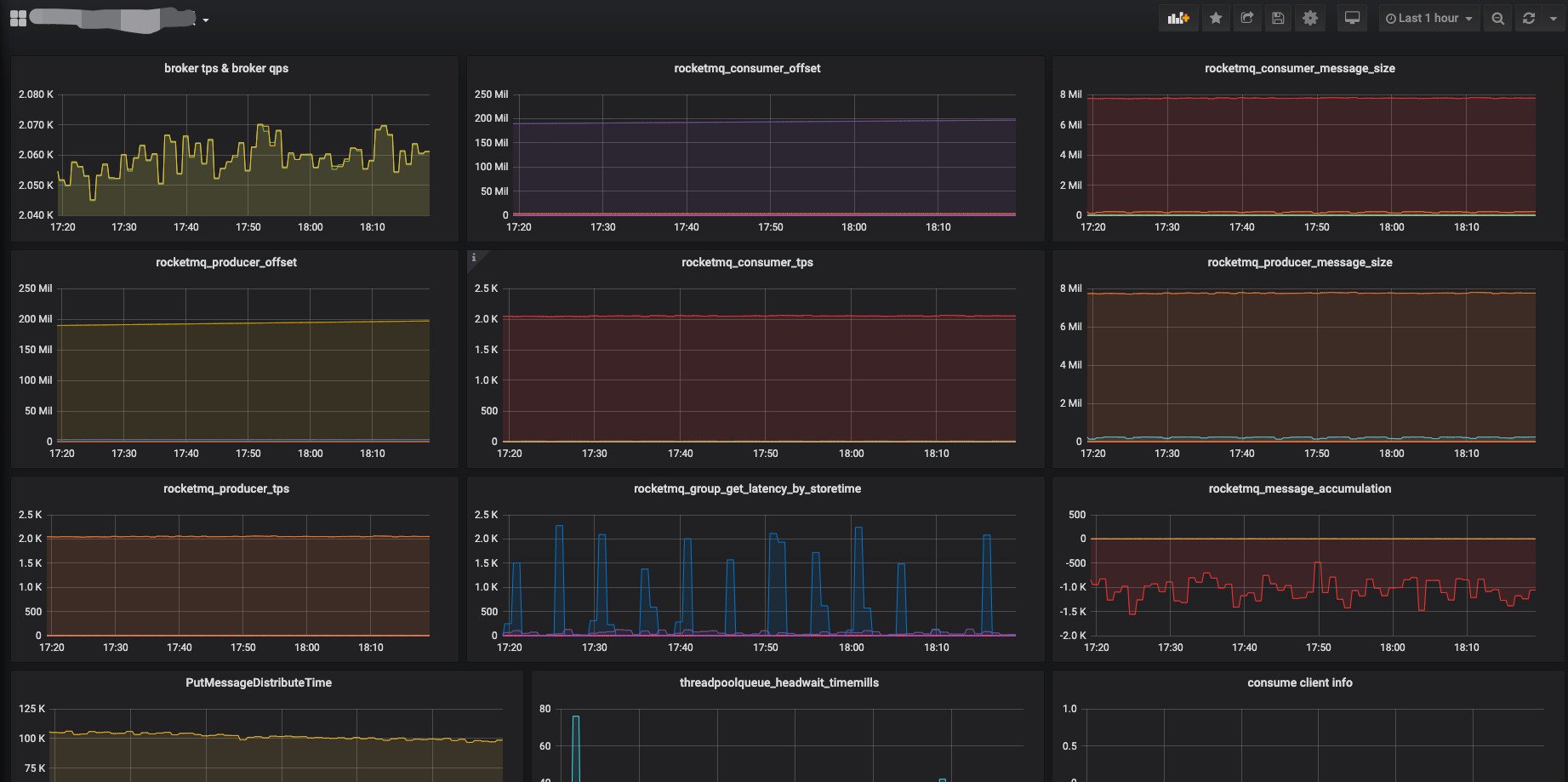
背景
最近排查用户现场环境,查看日志出现大量的“send: Resource temporarily unavailable”错误,UDP设置NO_BLOCK模式,send又发生在进程上下文,并且还设置了SO_SNDBUF 为8M,在此情况下为什么还会出现发送队列满的情况,由此产生几个问题?
- send 在什么情况下会报“Resource temporarily unavailable”错误?
- send工作在进程上下文中,发送的SKB报文在什么时机进行释放?
- /proc/net/softnet_stat 第三列数不停的再增加?
- SO_SNDBUF的设置真的生效了么,netstat -napu 接收队列并没有达到阈值8M?
内核源码分析
send 在什么情况下会报“Resource temporarily unavailable”错误?
我们跟踪kernel 源码,用户态调用系统调用send,内核跟踪路径
/* trace-cmd record -p function_graph -g __sys_sendto */
__sys_sendto() {__sock_sendmsg() {inet_sendmsg() {udp_sendmsg() {/* 查找路由,经历了策略路由 */ip_route_output_flow() {ip_route_output_key_hash() {ip_route_output_key_hash_rcu() {__fib_lookup() {fib4_rule_match();fib4_rule_action() {fib_get_table();fib_table_lookup();}fib4_rule_suppress();}}}}}/* 生成skb 结构 */ip_make_skb() {__ip_append_data.isra.0() {sock_alloc_send_skb() {/* 这个函数特别分析 */sock_alloc_send_pskb() {alloc_skb_with_frags() {__alloc_skb() {skb_set_owner_w();}}}}}}udp_send_skb.isra.0() {ip_send_skb() {ip_local_out() {__ip_local_out() {/* 进入netfilter 框架 */nf_hook_slow() {ipv4_conntrack_local() {nf_conntrack_in() {}}}ip_output() {nf_hook_slow() {iptable_mangle_hook() {ipt_do_table() {}}nf_nat_ipv4_out() {nf_nat_ipv4_fn() {}}ipv4_confirm() {nf_confirm() {}}}/* IP 层处理完毕 */ip_finish_output() {__ip_finish_output() {ip_finish_output2() {dev_queue_xmit() {__dev_queue_xmit() {netdev_core_pick_tx() {netdev_pick_tx() {}}}_raw_spin_lock();sch_direct_xmit() {}/* 发送到网卡,这里使用的vmxnet3 虚拟网卡 */_raw_spin_lock();dev_hard_start_xmit() {vmxnet3_xmit_frame() {vmxnet3_tq_xmit.isra.0() {_raw_spin_lock_irqsave();vmxnet3_map_pkt.isra.0();_raw_spin_unlock_irqrestore();}}}}__qdisc_run() {}}}}}}}}}}}
}根据调用栈信息看到整个sendto,处于一个进程上下文中,经历了socket层,ip层,netfilter, qdisc, driver 层,我们特别注意到sock_alloc_send_pskb() 函数
struct sk_buff *sock_alloc_send_pskb(struct sock *sk, unsigned long header_len,unsigned long data_len, int noblock,int *errcode, int max_page_order)
{struct sk_buff *skb;long timeo;int err;/* 这里我们设置的noblock, timeo=0 */timeo = sock_sndtimeo(sk, noblock);for (;;) {err = sock_error(sk);if (err != 0)goto failure;err = -EPIPE;if (sk->sk_shutdown & SEND_SHUTDOWN)goto failure;/*static inline int sk_wmem_alloc_get(const struct sock *sk){return refcount_read(&sk->sk_wmem_alloc) - 1;}sk->sk_wmem_alloc 和 sk->sk_sndbuf 进行对比,当大于时进行等待或者返回-EAGAIN, */if (sk_wmem_alloc_get(sk) < READ_ONCE(sk->sk_sndbuf))break;/* alloc wmem(write memory) 大于sk->sk_sndbuf,并且timeo 为0,返回-EAGIN*/ sk_set_bit(SOCKWQ_ASYNC_NOSPACE, sk);set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);err = -EAGAIN;if (!timeo)goto failure;if (signal_pending(current))goto interrupted;timeo = sock_wait_for_wmem(sk, timeo);}skb = alloc_skb_with_frags(header_len, data_len, max_page_order,errcode, sk->sk_allocation);/*skb_set_owner_w() {skb->destructor = sock_wfree;/* 成功申请写内存后,增加sk_wmem_alloc 变量 */refcount_add(skb->truesize, &sk->sk_wmem_alloc);}*/if (skb)skb_set_owner_w(skb, sk);return skb;interrupted:err = sock_intr_errno(timeo);
failure:*errcode = err;return NULL;
}void skb_set_owner_w(struct sk_buff *skb, struct sock *sk)
{/* 设置skb 为孤儿状态 */skb_orphan(skb);skb->sk = sk;
#ifdef CONFIG_INETif (unlikely(!sk_fullsock(sk))) {skb->destructor = sock_edemux;sock_hold(sk);return;}
#endif/* 注意这个回调函数,sock_wfree() 什么时机调用?*/skb->destructor = sock_wfree;skb_set_hash_from_sk(skb, sk);/** We used to take a refcount on sk, but following operation* is enough to guarantee sk_free() wont free this sock until* all in-flight packets are completed*//* 注释已经解释很清楚了,我们释放内存,直到报文处理完成 */refcount_add(skb->truesize, &sk->sk_wmem_alloc);
}void sock_wfree(struct sk_buff *skb)
{struct sock *sk = skb->sk;unsigned int len = skb->truesize;if (!sock_flag(sk, SOCK_USE_WRITE_QUEUE)) {/** Keep a reference on sk_wmem_alloc, this will be released* after sk_write_space() call*/WARN_ON(refcount_sub_and_test(len - 1, &sk->sk_wmem_alloc));sk->sk_write_space(sk);len = 1;}/** if sk_wmem_alloc reaches 0, we must finish what sk_free()* could not do because of in-flight packets*/if (refcount_sub_and_test(len, &sk->sk_wmem_alloc))__sk_free(sk);
}到这里我们可以看到,当我们申请sk_wmem_alloc大于我们设置的sk_sndbuf时,系统调用直接返回给我们-EAGAIN错误码,sk_wmem_alloc 什么时机增加和减少?整个发送的进程上下文暂未找到减少的流程,从代码可以看出,在什么时机调用sock_wfree(),就是更新sk_wmem_alloc。
send工作在进程上下文中,发送的SKB报文在什么时机进行释放?
# bpftrace -e 'kprobe:sock_wfree {printf ("%s\n", kstack());}'sock_wfree+1skb_release_all+19kfree_skb+50__dev_kfree_skb_any+59vmxnet3_tq_tx_complete+254vmxnet3_poll_rx_only+121net_rx_action+322__softirqentry_text_start+209irq_exit+174do_IRQ+90ret_from_intr+0native_safe_halt+14arch_cpu_idle+21default_idle_call+35do_idle+507cpu_startup_entry+32start_secondary+376secondary_startup_64+164
这里可以看到,在中断上下文中do_IRQ() 触发了软中net_rx_action(),调用了vmxnet3_poll_rx_only() 和 vmxnet3_tq_tx_complete() 中kfree_skb() 函数回调 sock_wfree(),其发送过skb后,并没有立刻释放skb,借用飞哥《理解了实现再谈性能》的一张图第6,7步骤。这部分内容书中有详细的介绍,可以详细看下此书。
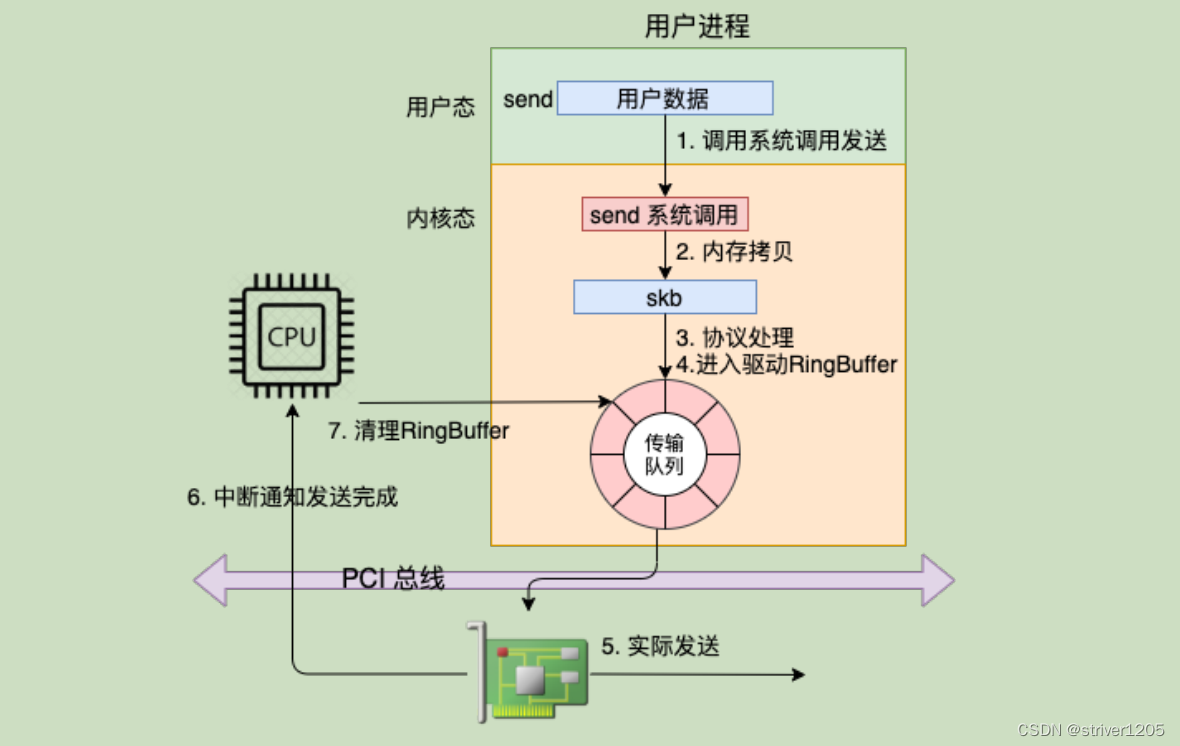
至此我们也可以理解为什么send() 时会报-EAGAIN,因为发送申请内存和释放内存是异步操作的,当CPU比较繁忙,send发送比回收快时,很快将sk_sndbuf 占满,会发生EAGAIN情况,这里需要注意 /proc/net/softnet_stat 文件的第三列 的数据变化。
/proc/net/softnet_stat 第三列数不停的再增加?
static __latent_entropy void net_rx_action(struct softirq_action *h)
{struct softnet_data *sd = this_cpu_ptr(&softnet_data);unsigned long time_limit = jiffies +usecs_to_jiffies(netdev_budget_usecs);int budget = netdev_budget;LIST_HEAD(list);LIST_HEAD(repoll);local_irq_disable();list_splice_init(&sd->poll_list, &list);local_irq_enable();for (;;) {struct napi_struct *n;if (list_empty(&list)) {if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))goto out;break;}n = list_first_entry(&list, struct napi_struct, poll_list);budget -= napi_poll(n, &repoll);/* If softirq window is exhausted then punt.* Allow this to run for 2 jiffies since which will allow* an average latency of 1.5/HZ.*//*这里影响单词softirq 处理报文个数有两个参数决定:netdev_budget 和 netdev_budget_usecs*/if (unlikely(budget <= 0 ||time_after_eq(jiffies, time_limit))) {/* percpu squeeze 对应 /proc/net/softnet_stat 第三列 */sd->time_squeeze++;break;}}local_irq_disable();list_splice_tail_init(&sd->poll_list, &list);list_splice_tail(&repoll, &list);list_splice(&list, &sd->poll_list);if (!list_empty(&sd->poll_list))__raise_softirq_irqoff(NET_RX_SOFTIRQ);net_rps_action_and_irq_enable(sd);
out:__kfree_skb_flush();
}第三列的变化是取值于time_squeeze变量,也就表明单次软中处理已经无法处理完,需要唤醒ksoftirqd 内核线程协助处理,此时未处理的软中断事务,比如释放skb将由内核线程ksoftirqd处理,这将延后到内核线程ksoftirqd 何时得到调度,在我们客户现场环境是关闭内核抢占的。
我们在看下处理软中断函数
asmlinkage __visible void do_softirq(void)
{__u32 pending;unsigned long flags;if (in_interrupt())return;local_irq_save(flags);pending = local_softirq_pending();/* 当 ksofirqd 已经启动的时候,我们不会再继续调用do_softirq,注释也能 明确说明*/if (pending && !ksoftirqd_running(pending))do_softirq_own_stack();local_irq_restore(flags);
}/** If ksoftirqd is scheduled, we do not want to process pending softirqs* right now. Let ksoftirqd handle this at its own rate, to get fairness,* unless we're doing some of the synchronous softirqs.*/
#define SOFTIRQ_NOW_MASK ((1 << HI_SOFTIRQ) | (1 << TASKLET_SOFTIRQ))
static bool ksoftirqd_running(unsigned long pending)
{struct task_struct *tsk = __this_cpu_read(ksoftirqd);if (pending & SOFTIRQ_NOW_MASK)return false;return tsk && (tsk->state == TASK_RUNNING) &&!__kthread_should_park(tsk);
}
看代码逻辑,当有新的软中断事件发生时,会检测ksoftirqd的运行情况,已经是运行状态时,不会调用do_softirq(),对应网卡软中断事件来说就是不处理发送后的SKB回收,由ksoftirqd 来处理,这样就加剧了SKB回收的工作,增加send 出现EAGAIN的可能性。
SO_SNDBUF的设置真的生效了么,netstat -napu 接收队列并没有达到阈值8M?
明明我们程序设置了8M的snd_buf,但是netstat -napu 确始终未发现超过8M的大小,这个需要从源码分析
int sock_setsockopt(struct socket *sock, int level, int optname,char __user *optval, unsigned int optlen)
{switch (optname) {case SO_SNDBUF:/* Don't error on this BSD doesn't and if you think* about it this is right. Otherwise apps have to* play 'guess the biggest size' games. RCVBUF/SNDBUF* are treated in BSD as hints*/val = min_t(u32, val, sysctl_wmem_max);
set_sndbuf:/* Ensure val * 2 fits into an int, to prevent max_t()* from treating it as a negative value.*/val = min_t(int, val, INT_MAX / 2);sk->sk_userlocks |= SOCK_SNDBUF_LOCK;WRITE_ONCE(sk->sk_sndbuf,max_t(int, val * 2, SOCK_MIN_SNDBUF));/* Wake up sending tasks if we upped the value. */sk->sk_write_space(sk);break;case SO_SNDBUFFORCE:if (!capable(CAP_NET_ADMIN)) {ret = -EPERM;break;}/* No negative values (to prevent underflow, as val will be* multiplied by 2).*/if (val < 0)val = 0;goto set_sndbuf;case SO_RCVBUF:/* Don't error on this BSD doesn't and if you think* about it this is right. Otherwise apps have to* play 'guess the biggest size' games. RCVBUF/SNDBUF* are treated in BSD as hints*/val = min_t(u32, val, sysctl_rmem_max);
set_rcvbuf:/* Ensure val * 2 fits into an int, to prevent max_t()* from treating it as a negative value.*/val = min_t(int, val, INT_MAX / 2);sk->sk_userlocks |= SOCK_RCVBUF_LOCK;/** We double it on the way in to account for* "struct sk_buff" etc. overhead. Applications* assume that the SO_RCVBUF setting they make will* allow that much actual data to be received on that* socket.** Applications are unaware that "struct sk_buff" and* other overheads allocate from the receive buffer* during socket buffer allocation.** And after considering the possible alternatives,* returning the value we actually used in getsockopt* is the most desirable behavior.*/WRITE_ONCE(sk->sk_rcvbuf,max_t(int, val * 2, SOCK_MIN_RCVBUF));break;case SO_RCVBUFFORCE:if (!capable(CAP_NET_ADMIN)) {ret = -EPERM;break;}/* No negative values (to prevent underflow, as val will be* multiplied by 2).*/if (val < 0)val = 0;goto set_rcvbuf;
}从代码可以看出当我们使用SO_SNDBUF时候,会强制 min_t(u32, val, sysctl_wmem_max)取小,也就是上限为sysctl_wmem_max的大小,查看系统cat /proc/sys/net/core/wmem_max,最大为229376,也就是说我们应用层所有设置SO_SNDBUF都有这个问题,此时查看了man 手册有这段话
SO_SNDBUF
Sets or gets the maximum socket send buffer in bytes. The kernel doubles this value
(to allow space for bookkeeping overhead) when it is set using setsockopt(2), and this
doubled value is returned by getsockopt(2). The default value is set by the
/proc/sys/net/core/wmem_default file and the maximum allowed value is set by the
/proc/sys/net/core/wmem_max file. The minimum (doubled) value for this option is
2048.SO_SNDBUFFORCE (since Linux 2.6.14)
Using this socket option, a privileged (CAP_NET_ADMIN) process can perform the same
task as SO_SNDBUF, but the wmem_max limit can be overridden.
这里已经给出了答案,当我们使用SO_SNDBUF时,会有wmem_max 的上限,如果我们想改变限制,就使用SO_SNDBUFFORCE强制更新写缓存区大小。
解决方案
之前的领导有句话,“发现问题,并解决问题”,根据上面分析为缓解send 出现EAGIN的情况,有以下优化方案
- 通过设置setsockopt 使用SO_SNDBUFFORCE类型,强制修改系统限制
- 适当增加 netdev_budget 和 netdev_budget_usecs 数值,增加单次软中断处理能力
- 优化应用软件,出现这种情况应用软件100%占用CPU,导致ksoftirqd 处理变慢
总结
至此,我们已经分析开头所说困惑,一个小小的“Resource temporarily unavailable”错误,背后蕴藏着太多技术细节,如果得过且过将来必成后患。
工作中遇到的每个小问题,背后都蕴藏着大量知识,只有平时多积累总结,才能游刃有余解决所面对的问题。