前言:在我们练习编程的时候,我们只需要将代码写入、运行,就可以得到计算之后的结果了,但是你有没有想过,为什么就可以得到计算之后的结果呢,它的底层又到底是什么呢?
✨✨✨这里是秋刀鱼不做梦的BLOG
✨✨✨想要了解更多内容可以访问我的主页秋刀鱼不做梦-CSDN博客

那么废话不多说,我们直接开始讲解,先来看一下讲解内容:
目录
1.翻译环境
(1)编译
[ 1 ]预处理阶段
[ 2 ]编译阶段
[ 3 ]汇编阶段
(2)链接
2.运行环境
1.翻译环境
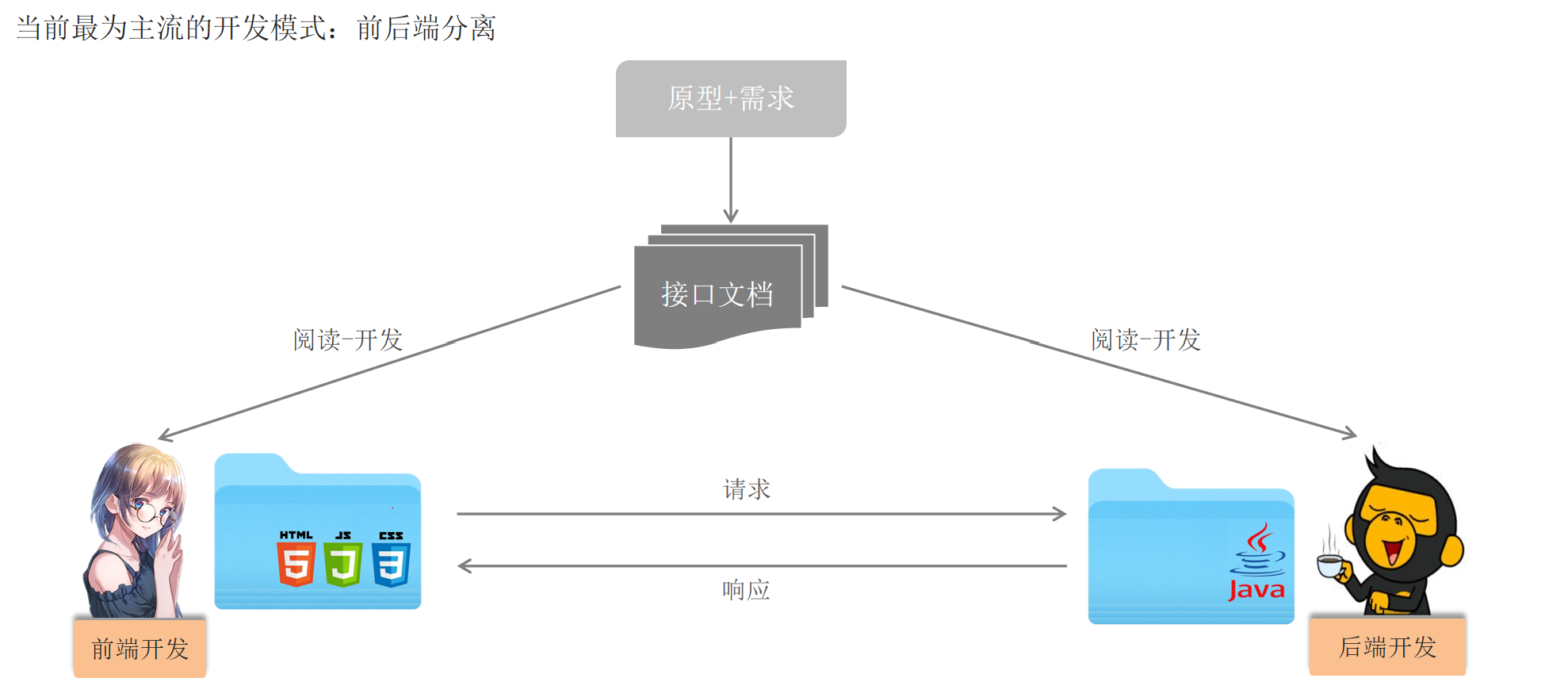
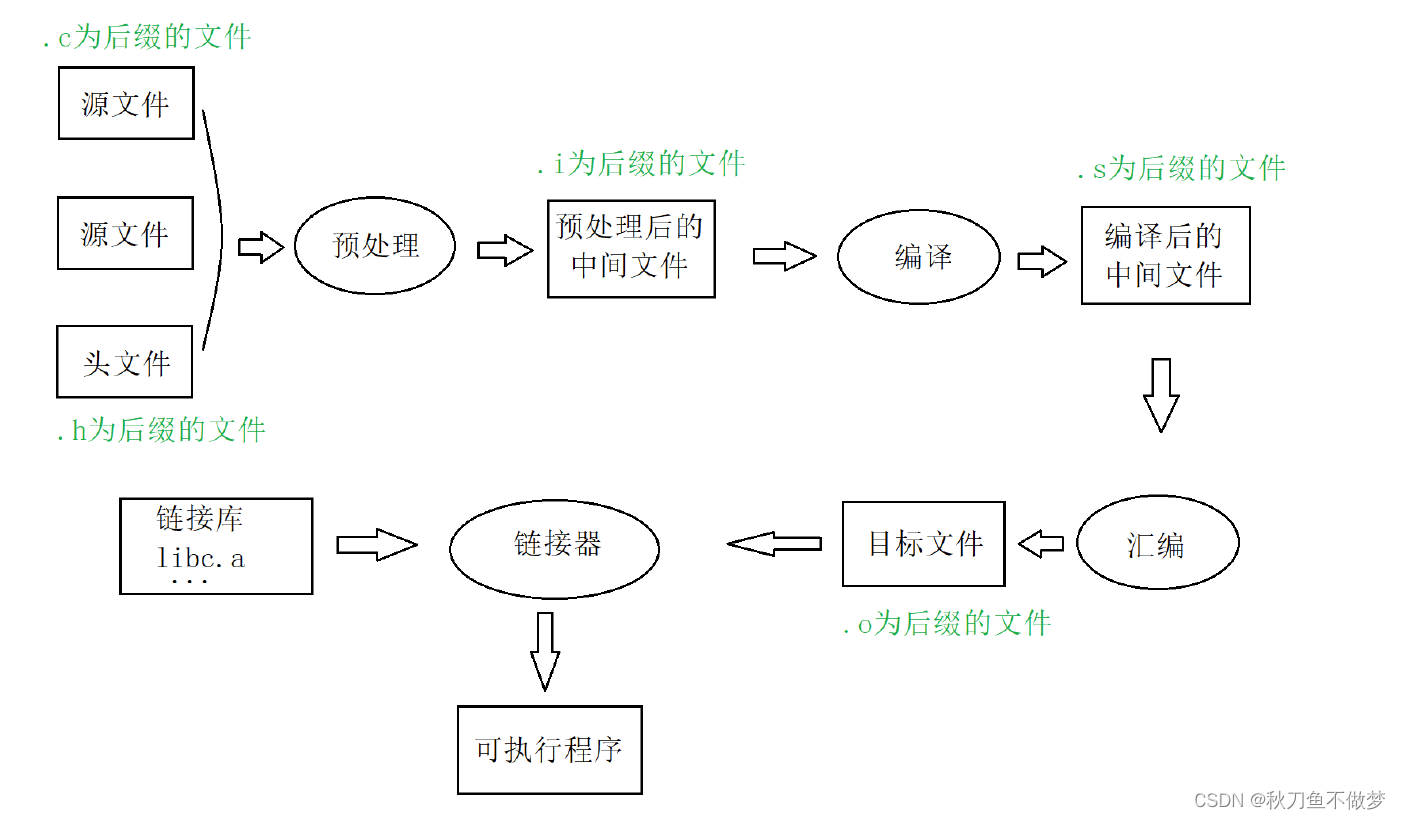
由于操作系统只能执行机器指令(二进制指令),所以翻译环境阶段要做的就是将写入的代码转化为二进制指令,而翻译环境是由编译和链接两个大的过程组成,编译又可以分解成:预处理、编译、汇编三个过程。
大致如图:

接下来让我们一个一个来讲解:
(1)编译
编译流程大致分为了四个步骤:

[ 1 ]预处理阶段
预处理阶段主要处理那些源文件中#开始的预编译指令,比如:#include,#define,处理的规则如下:
• 将所有的 #define 删除,并展开所有的宏定义
• 处理所有的条件编译指令,如: #if、#ifdef、#elif、#else、#endif
• 处理#include 预编译指令,将包含的头文件的内容插入到该预编译指令的位置,这个过程是递归进
行的,也就是说被包含的头文件也可能包含其他文件
• 删除所有的注释
• 添加行号和文件名标识,方便后续编译器生成调试信息等
• 或保留所有的#pragma的编译器指令,编译器后续会使用
经过预处理后的.i文件中不再包含宏定义,因为宏已经被展开,并且包含的头文件都被插入到.i文件
中,所以当我们无法知道宏定义或者头文件是否包含正确的时候,可以查看预处理后的.i文件来确认。
[ 2 ]编译阶段
编译过程就是将预处理后的文件进行一系列从而生成相应的汇编代码文件,编译过程可分为6步:扫描(词法分析)、语法分析、语义分析、源代码优化、代码生成、目标代码优化。
1. 词法分析:扫描器将源代的字符序列分割成一系列的记号。
2. 语法分析:语法分析器将记号产生语法树。
3. 语义分析:静态语义(在编译器可以确定的语义),动态语义(只能在运行期才能确定的语义)。
4. 源代码优化:源代码优化器,将整个语法书转化为中间代码(中间代码是与目标机器和运行环境无关的),中间代码使得编译器被分为前端和后端,编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转化为目标机器代码。
5. 目标代码生成:代码生成器。
6. 目标代码优化:目标代码优化器。
[ 3 ]汇编阶段
在此阶段汇编器将汇编代码转转变成机器可执行的指令,每一个汇编语句几乎都对应一条机器指令。就是根据汇编指令和机器指令的对照表一一的进行翻译,也不做指令优化。
所以编译阶段大致可以使用以下方式描述:
(2)链接
链接的简介:
链接(linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可以执行于编译时(compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时(load time),也就是在程序被加载器(loader)加载到内存并执行时;甚至执行于运行时(run time),也就是由应用程序来执行。链接是由叫链接器(linker)的程序自动执行的
链接过程主要包括:地址和空间分配,符号决议和重定位等这些步骤,其解决的是一个项目中多文件、多模块之间互相调用的问题。
那么为什么要有链接过程呢:因为编译只是将我们写的代码变成了二进制形式,它还要需要和系统组件(比如标准库、动态链接库等)结合起来,这些组件都是程序运行所必须的。
所以链接简而言之就是一个 “封装打包” 的过程,它将所有二进制形式的目标文件和系统组件合成一个可执行文件,当然完成链接的过程也需要一个特殊的软件——链接器。
以上我们就大致了解了程序是如何将源文件转化为可执行程序的了。
2.运行环境
我们知道程序必须载入内存中,在有操作系统的环境中:一般这个由操作系统完成。而在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
那么运行的流程是什么样的呢?以下为程序运行的大致流程:
1. 程序的执行时便开始,接着便调用main函数。
2. 开始执行程序代码,这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
3. 终止程序,正常终止main函数;也有可能是意外终止。
那么这样我们也就大致了解了程序是如何运行的了。
以上就是所有关于编译与链接的全部内容了~~~