前情提要
前面我们实现了内存管理系统,内存管理系统可以实现进程与进程之间的隔离。
Linux中高1GB是操作系统内核的地址,低3GB是用户的地址,高1GB对于所有用户都是一致的,低3GB才是用户自己的自留地。
既然已经实现了内存管理,这一节我们来实现线程,目前只实现内核级线程。
一、什么是线程
线程是一套机制,这种机制可以为一般的代码块创造他依赖的上下文环境,从而使代码块具有独立性,因此在原理上线程能使一段函数成为调度单元(或称为执行流),使函数能被调度器“认可”,从而能够被专门调度到处理器上执行。
线程是操作系统能够进行运算调度的最小单位。在一个进程中可以包含多个线程,每个线程可以独立执行不同的任务,但它们共享进程的资源,如内存空间、文件描述符等。
与进程相比,线程更加轻量级,因为它们共享了许多进程级别的资源。由于多个线程可以并行执行,所以线程是实现并发性的一种重要方式。在多核处理器上,不同的线程可以被分配到不同的核心上并行执行,从而提高计算机系统的整体性能。
二、进程线程的关系
程序是指静态的、存储在文件系统上、尚未运行的指令代码,它是实际运行时程序的映像。进程是指正在运行的程序,即进行中的程序,程序必须在获得运行所需要的各类资源后才能成为进程,资源包括进程所使用的栈,使用的寄存器等。
对于处理器来说,进程是一种控制流集合,集合中至少包含一条执行流,执行流之间是相互独立的,但它们共享进程的所有资源,它们是处理器的执行单位,或者称为调度单位,它们就是线程。可以认为,线程是在进程基础之上的二次并发。
按照进程中线程数量划分,进程分为单线程进程和多线程进程两种。我们平时所写的程序,如果其中未“显式”创建线程,它就属于单线程进程,这就是我们平时所指的“传统型”的进程,否则就属于多线程进程。
线程是资源调度的基本单位,也是程序执行的基本单位,是轻量级的进程。每个进程中都有唯一的主线程,且只能有一个,主线程和进程是相互依存的关系,主线程结束进程也会结束。
2.1、多线程如何提高并发性
首先是线程是调度器调度的最小单元,那么如果调度器的调度列表中全都是我的线程,我的任务,那么处理器就会多执行我的计算任务
其次是现在的CPU都是多核的,一个线程最多部署在一个核心上,即使占有了这个核心的全部时间也不够,多线程就可以占有全部的核心
2.2、多线程的缺点
- 资源占用:每个线程都需要一定的内存和CPU时间来维护,当线程数量过多时,会增加系统资源消耗。
- 死锁(Deadlocks):当多个线程相互等待对方释放资源时,可能导致死锁,使得所有线程都无法继续执行。
- 上下文切换开销:线程之间的频繁切换会导致上下文切换开销增加,影响系统性能。
- 性能下降:虽然多线程可以提高程序的并发性能,但线程间的同步和通信也会带来一定的性能损失。
- 复杂性增加:多线程程序的设计和实现相对复杂,需要考虑线程同步、死锁避免等问题,增加了开发和维护的难度。
2.3、进程的生命周期
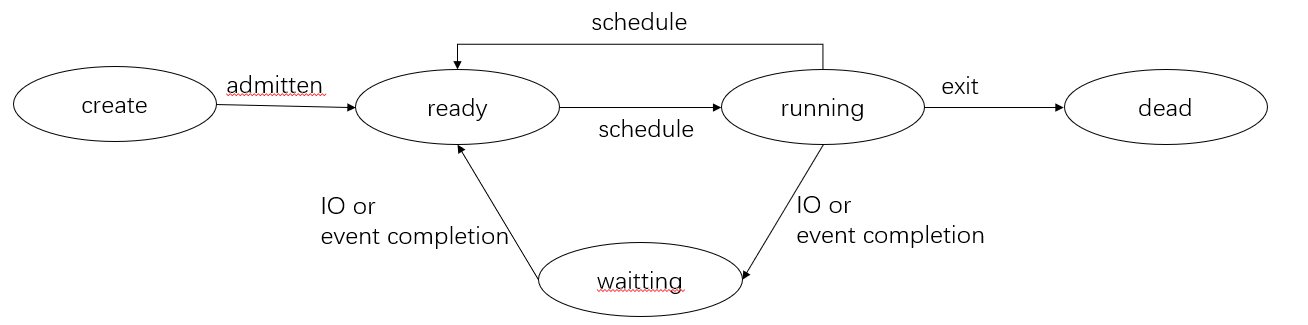
进程大概分为三个状态,就绪态,运行态,阻塞态
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
三、调度算法
我们这里使用多级反馈队列,我在github上提交了两个程序,其中一个是优先级调度,另一个是多级反馈队列
3.1、先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
3.2、短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
3.3、最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。
如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
3.4、时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。
当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
然而,时间片过长会导致线程的实时性得不到保证,时间片过短会导致线程一直在切换。
3.5、优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
3.6、多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,…。进程在第一个队列没执行完,就会被移到下一个队列。
这种方式下,之前的进程只需要交换 7 次。每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
我们实现了一个多级反馈队列算法,接口如下
/* 多级反馈优先队列新插入一个线程 */
void mlfq_new(struct task_struct* pthread);
/* 多级反馈优先队列插入一个线程, 优先级降低,时间片变多*/
void mlfq_push(struct task_struct* pthread);
/* 多级反馈优先队列插入一个线程, 优先级不变,时间片不变*/
void mlfq_push_wspt(struct task_struct* pthread);
/* 所有线程队列插入一个线程 */
void all_push_back(struct task_struct* pthread);
/* 多级反馈优先队列弹出一个线程 */
struct task_struct* mlfq_pop(void);
/* 多级反馈优先队列判断是否为空,是返回true */
bool mlfq_is_empty(void);
/* 多级返回优先队列查找,找到返回true */
bool mlfq_find(struct task_struct* pthread);
/* 多级返回优先队列长度 */
uint32_t mlfq_len(void);
/* 多级反馈优先队列刷新,将低优先级线程往上提 */
void mlfq_flash(void);
/* 多级反馈优先队列初始化 */
void mlfq_init(void);
实现如下,我们只实现了四级的队列
struct list thread_ready_list4; // 就绪队列4
struct list thread_ready_list8; // 就绪队列8
struct list thread_ready_list16; // 就绪队列16
struct list thread_ready_list32; // 就绪队列32
struct list thread_all_list; // 所有任务队列/* 多级反馈优先队列新插入一个线程 */
void mlfq_new(struct task_struct* pthread) {// 关闭中断enum intr_status pop = intr_disable();// 修改线程可用时间片pthread->ticks = 4;// 修改线程优先级pthread->priority = 4;// 最低层队列插入list_append(&thread_ready_list4, &pthread->general_tag);// 所有任务队列插入list_append(&thread_all_list, &pthread->all_tag);// 开启中断intr_set_status(pop);
}/* 所有线程队列插入一个线程 */
void all_push_back(struct task_struct* pthread) {// 关闭中断enum intr_status pop = intr_disable();// 所有线程队列中没有新插入的线程if (!elem_find(&thread_all_list, &pthread->all_tag)) {// 所有任务队列插入list_append(&thread_all_list, &pthread->all_tag);}// 开启中断intr_set_status(pop);
}/* 多级反馈优先队列插入一个线程, 优先级降低,时间片变多*/
void mlfq_push(struct task_struct* pthread) {if (pthread == NULL) return;if (mlfq_find(pthread)) return;// 关闭中断enum intr_status mlqf = intr_disable();// 线程优先级,高优先级的先降级,但是时间片变多// 不知道什么优先级的,就先按照4来。if (pthread->priority == 4) {pthread->priority = 8;pthread->ticks = 8;list_append(&thread_ready_list8, &pthread->general_tag);}else if (pthread->priority == 8) {pthread->priority = 16;pthread->ticks = 16;list_append(&thread_ready_list16, &pthread->general_tag);}else if (pthread->priority == 16) {pthread->priority = 32;pthread->ticks = 32;list_append(&thread_ready_list32, &pthread->general_tag);}else if (pthread->priority == 32) {pthread->priority = 32;pthread->ticks = 32;list_append(&thread_ready_list32, &pthread->general_tag);}else {pthread->priority = 4;pthread->ticks = 4;list_append(&thread_ready_list4, &pthread->general_tag);}// 开启中断intr_set_status(mlqf);
}/* 多级反馈优先队列插入一个线程, 优先级不变,时间片不变,with same priority and timeslice*/
void mlfq_push_wspt(struct task_struct* pthread) {if (pthread == NULL) return;if (mlfq_find(pthread)) return;// 关闭中断enum intr_status mlqf = intr_disable();// 线程优先级,高优先级的先降级,但是时间片变多// 不知道什么优先级的,就先按照4来。if (pthread->priority == 4) {pthread->priority = 4;pthread->ticks = 4;list_append(&thread_ready_list8, &pthread->general_tag);}else if (pthread->priority == 8) {pthread->priority = 8;pthread->ticks = 8;list_append(&thread_ready_list16, &pthread->general_tag);}else if (pthread->priority == 16) {pthread->priority = 16;pthread->ticks = 16;list_append(&thread_ready_list32, &pthread->general_tag);}else if (pthread->priority == 32) {pthread->priority = 32;pthread->ticks = 32;list_append(&thread_ready_list32, &pthread->general_tag);}else {pthread->priority = 4;pthread->ticks = 4;list_append(&thread_ready_list4, &pthread->general_tag);}// 开启中断intr_set_status(mlqf);
}/* 多级反馈优先队列弹出一个线程,队列全为空则返回NULL */
struct task_struct* mlfq_pop(void) {if (mlfq_is_empty()) return NULL;// 关闭中断enum intr_status mlfq = intr_disable();struct task_struct* pthread = NULL;struct list_elem* pelem = NULL;if (!list_empty(&thread_ready_list4)) {pelem = list_pop(&thread_ready_list4);}else if (!list_empty(&thread_ready_list8)) {pelem = list_pop(&thread_ready_list8);}else if (!list_empty(&thread_ready_list16)) {pelem = list_pop(&thread_ready_list16);}else if (!list_empty(&thread_ready_list32)) {pelem = list_pop(&thread_ready_list32);}pthread = elem2entry(struct task_struct, general_tag, pelem);// 开启中断intr_set_status(mlfq);return pthread;
}/* 多级反馈优先队列判断是否为空,是返回true */
bool mlfq_is_empty(void) {return (list_empty(&thread_ready_list4) && list_empty(&thread_ready_list8) \&& list_empty(&thread_ready_list16) && list_empty(&thread_ready_list32));
}/* 多级返回优先队列查找,找到返回true */
bool mlfq_find(struct task_struct* pthread) {if (elem_find(&thread_ready_list4, &pthread->general_tag)) return true;else if (elem_find(&thread_ready_list4, &pthread->general_tag)) return true;else if (elem_find(&thread_ready_list4, &pthread->general_tag)) return true;else if (elem_find(&thread_ready_list4, &pthread->general_tag)) return true;return false;
}/* 多级返回优先队列长度 */
uint32_t mlfq_len(void) {return list_len(&thread_ready_list4) + list_len(&thread_ready_list8) \+ list_len(&thread_ready_list16) + list_len(&thread_ready_list32);
}/* 多级反馈优先队列刷新,将低优先级线程往上提 */
void mlfq_flash(void) {// 关闭中断enum intr_status mlfq = intr_disable();struct list_elem* temp = NULL;while (!list_empty(&thread_ready_list8)) {temp = list_pop(&thread_ready_list8);list_append(&thread_ready_list8, temp);}while (!list_empty(&thread_ready_list16)) {temp = list_pop(&thread_ready_list16);list_append(&thread_ready_list16, temp);}while (!list_empty(&thread_ready_list32)) {temp = list_pop(&thread_ready_list32);list_append(&thread_ready_list32, temp);}// 开启中断intr_set_status(mlfq);
}/* 多级反馈优先队列初始化 */
void mlfq_init(void) {put_str("mlfq_init start!\n");list_init(&thread_ready_list4);list_init(&thread_ready_list8);list_init(&thread_ready_list16);list_init(&thread_ready_list32);list_init(&thread_all_list);put_str("mlfq_init done!\n");
}
四、程序控制块PCB结构
一个线程一定是有一个结构去管理的,这就是程序控制块(Pcb),可以看一下他的结构
/*********** 中断栈intr_stack ***********
* 中断栈用于中断发生时保护程序(线程或进程)的上下文环境:
* 进程或线程被中断打断时,会按照此结构压入上下文寄存器,
* intr_exit中的出栈操作是此结构的逆操作
* 此栈在线程自己的内核栈中位置固定,所在页的最顶端
********************************************/
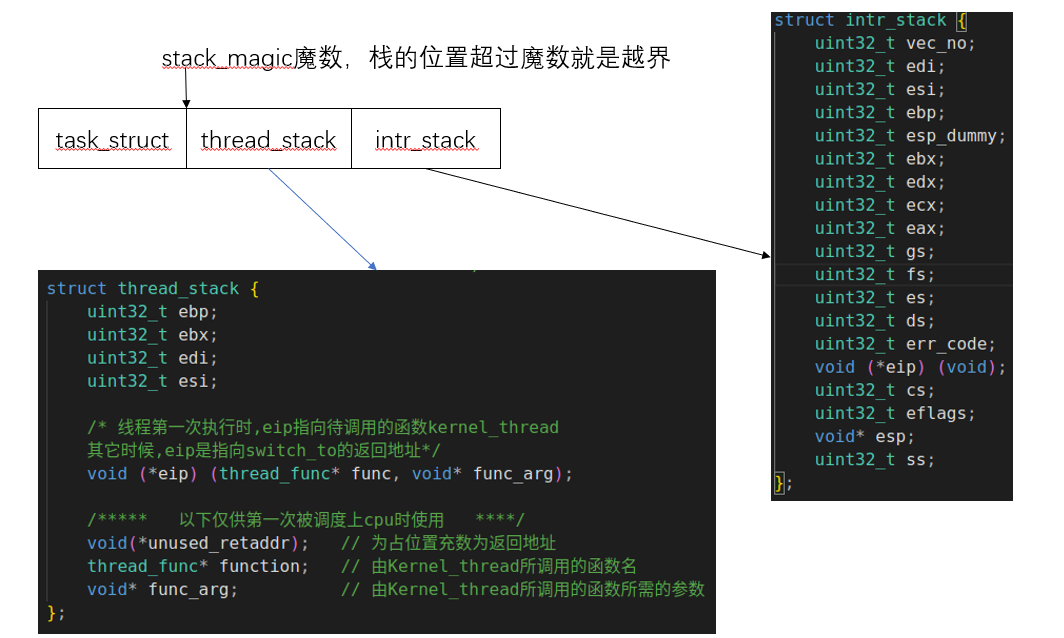
struct intr_stack {uint32_t vec_no; // kernel.S 宏VECTOR中push %1压入的中断号uint32_t edi;uint32_t esi;uint32_t ebp;uint32_t esp_dummy; // 虽然pushad把esp也压入,但esp是不断变化的,所以会被popad忽略uint32_t ebx;uint32_t edx;uint32_t ecx;uint32_t eax;uint32_t gs;uint32_t fs;uint32_t es;uint32_t ds;/* 以下由cpu从低特权级进入高特权级时压入,* 低特权级进入高特权级需要使用中断,所以这里有中断栈 */uint32_t err_code;void (*eip) (void); // 无参数无返回值的函数指针uint32_t cs;uint32_t eflags;void* esp;uint32_t ss;
};/*********** 线程栈thread_stack ***********
* 线程自己的栈,用于存储线程中待执行的函数
* 此结构在线程自己的内核栈中位置不固定,
* 用在switch_to时保存线程环境。
* 实际位置取决于实际运行情况。
******************************************/
struct thread_stack {uint32_t ebp;uint32_t ebx;uint32_t edi;uint32_t esi;/* 线程第一次执行时,eip指向待调用的函数kernel_thread其它时候,eip是指向switch_to的返回地址*/void (*eip) (thread_func* func, void* func_arg);/***** 以下仅供第一次被调度上cpu时使用 ****/void(*unused_retaddr); // 为占位置充数为返回地址thread_func* function; // 由Kernel_thread所调用的函数名void* func_arg; // 由Kernel_thread所调用的函数所需的参数
};/* 进程或线程的pcb,程序控制块 */
struct task_struct {uint32_t* self_kstack; // 线程或者进程内核栈的栈顶,就是pcb的高位enum task_status status; // 线程的运行状态char name[16]; // 线程名,最多16个字母uint8_t priority; // 线程优先级uint8_t ticks; // 每次在处理器上的执行时间的滴答数uint32_t elapsed_ticks; // 这个任务总的滴答数struct list_elem general_tag; // 线程在一段队列中的节点struct list_elem all_tag;// 线程在所有任务队列中的节点uint32_t* pgdir; // 进程自己页表的虚拟地址uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
进程的pcb占一个页,也就是4KB,可以看到这里放了三个结构体,
第三个是进程的pcb,但是这也不够4kB啊,是这样的,后面我们初始化的时候,是把 task_struct 放在了这个页的最前面,后面是栈,其实前面也讲过了,后面是一个中断栈,中断栈是中断发生的时候进行的压栈,这个不用说,中断发生就会自动压栈。
中断栈前面还有一个栈,线程栈。
他们在内存中的位置如下
五、线程之间的切换
线程的切换用到了一个函数
extern void switch_to(struct task_struct* cur, struct task_struct* next);
这个函数是用汇编写的,我们看一下汇编
[bits 32]
section .text
global switch_to
switch_to:push esipush edipush ebxpush ebpmov eax, [esp + 20]mov [eax], espmov eax, [esp + 24]mov esp, [eax]pop ebppop ebxpop edipop esiret
汇编写有点不明觉厉,压栈出栈就可以了?????
我们一行一行来解释,首先我们需要明白,C语言函数调用会从右到左压入参数,参数压完会压入返回地址,所以在push寄存器之前,栈中已经是这个样子了,其中返回地址指向执行 switch_to 的地址
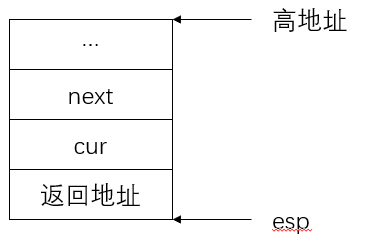
然后我们压入四个寄存器的值,这四个寄存器的值是遵循ABI接口,保护好esi、edi、ebx、ebp寄存器是指在函数调用期间,应该按照ABI规范来处理这些寄存器,以确保函数的正确性和稳定性。具体来说:
- esi、edi寄存器:在ABI规范中,esi和edi寄存器通常被认为是被调用者保存的寄存器,也就是说,在函数调用前后,函数内部不应该修改这两个寄存器的值,而应该在函数调用前将它们保存起来,并在函数结束后恢复原始值。
- ebx、ebp寄存器:ebx和ebp寄存器在一些ABI规范中被用作基地址寄存器和基址指针寄存器,它们也需要被谨慎处理。在函数调用期间,应该遵循ABI规范对它们的使用方式,确保在函数执行过程中不会意外修改这些寄存器的值。
我们压入这四个值,内存中变成了

那么 mov eax, [esp + 20] 这一句就相当于将 cur 的指针给了eax寄存器,也就是当前线程的pcb
mov [eax], esp,这一句是将当前的栈指针 esp 给了pcb,给pcb干嘛,实际上是给了pcb结构体中的第一个值,也就是保存栈指针。
mov eax, [esp + 24], 这一句是将 next 线程的栈指针保存的值给 eax
mov esp, [eax],这四句汇编,就实现了从cur的栈变为next的栈
然后我们弹出四个寄存器的值,注意!注意!注意!现在的栈已经变了,变成了 next 中的栈,所以最后一句话
ret 返回时,返回的是线程 next 栈中保存的地址。所以next栈中长什么样子呢?
假设现在next是第一次被调度,那么他就会被初始化,我们看一下他的初始化函数
/* 由kernel_thread去执行function(func_arg) */
static void kernel_thread(thread_func* function, void* func_arg) {function(func_arg);
}/* 初始化线程栈thread_stack,将待执行的函数和参数放到thread_stack中相应的位置 */
void thread_create(struct task_struct* pthread, thread_func function, void* func_arg) {/* 先预留中断使用栈的空间*/pthread->self_kstack -= sizeof(struct intr_stack);/* 再留出线程栈空间 */pthread->self_kstack -= sizeof(struct thread_stack);/* 拿到线程栈,并初始化 */struct thread_stack* kthread_stack = (struct thread_stack*)pthread->self_kstack;/* 这些内容是设置线程栈,eip指向要执行的程序*/kthread_stack->eip = kernel_thread;kthread_stack->function = function;kthread_stack->func_arg = func_arg;kthread_stack->ebp = 0;kthread_stack->ebx = 0;kthread_stack->edi = 0;kthread_stack->esi = 0;
}
function 是要执行的函数
func_arg 是要执行的函数的参数
eip 指向的是kernel_thread这个函数,最难理解的来了,中间有一个
void(*unused_retaddr);
占了一个位置,这涉及到一点函数调用规约
ret 返回,直接弹出了函数地址,也就是到函数的地方执行,正常的执行函数会先压栈,首先压入参数,然后压入返回地址,执行完函数,最后ret弹出返回地址返回,但是我们是直接ret返回的,所以我们需要自己压入参数,压入返回地址,由于 kernel_thread 这个函数需要一直执行到线程结束,所以这里直接没有返回地址。我们用 void(*unused_retaddr) 占了一个返回地址的位置。
假设next不是第一次被调度,那么就好说了,next是执行schedule()函数被换下cpu的。这里压入的返回地址就是schedule执行中的地址,此时栈顶的值是由调用函数switch_to的主调函数schedule留下的,还会继续执行schedule后面的流程。
六、调度结束,中断完成
而switch_to是schedule最后一句代码,因此执行流程马上回到schedule的调用者intr_timer_handler中。schedule同样也是intr_timer_handler中最后一句代码,因此会完成intr_timer_handler,回到kernel.s中的jmp intr_exit,从而恢复任务的全部寄存器映像,之后通过iretd指令退出中断,任务被完全彻底地恢复。
这里也要注意一点,我们还在中断呢,hhhh
看一下仿真结果
可以看到,这个结果是有点问题的,打印并不是一个接着一个的,很多同学应该能想到了,数据开始抢占临界区资源了,导致了数据不一致。
结束语
本节完成了内核线程的编写,以及调度算法,可是我们能发现,打印的东西并不对,其实可能也想到了,因为线程之间对控制台的操作出现了抢夺,导致数据发生了不一致。下一节课我们针对这个问题实现锁和信号量。
老规矩,本节的代码地址:https://github.com/lyajpunov/os
![[flink 实时流基础] flink组件栈以及任务执行与资源划分](https://img-blog.csdnimg.cn/img_convert/ea5ddc3582cd097dd41eaeefff4c3d32.png)