一个不知名大学生,江湖人称菜狗
original author: Jacky Li
Email : 3435673055@qq.comTime of completion:2024.03.30
Last edited: 2024.03.30

目录
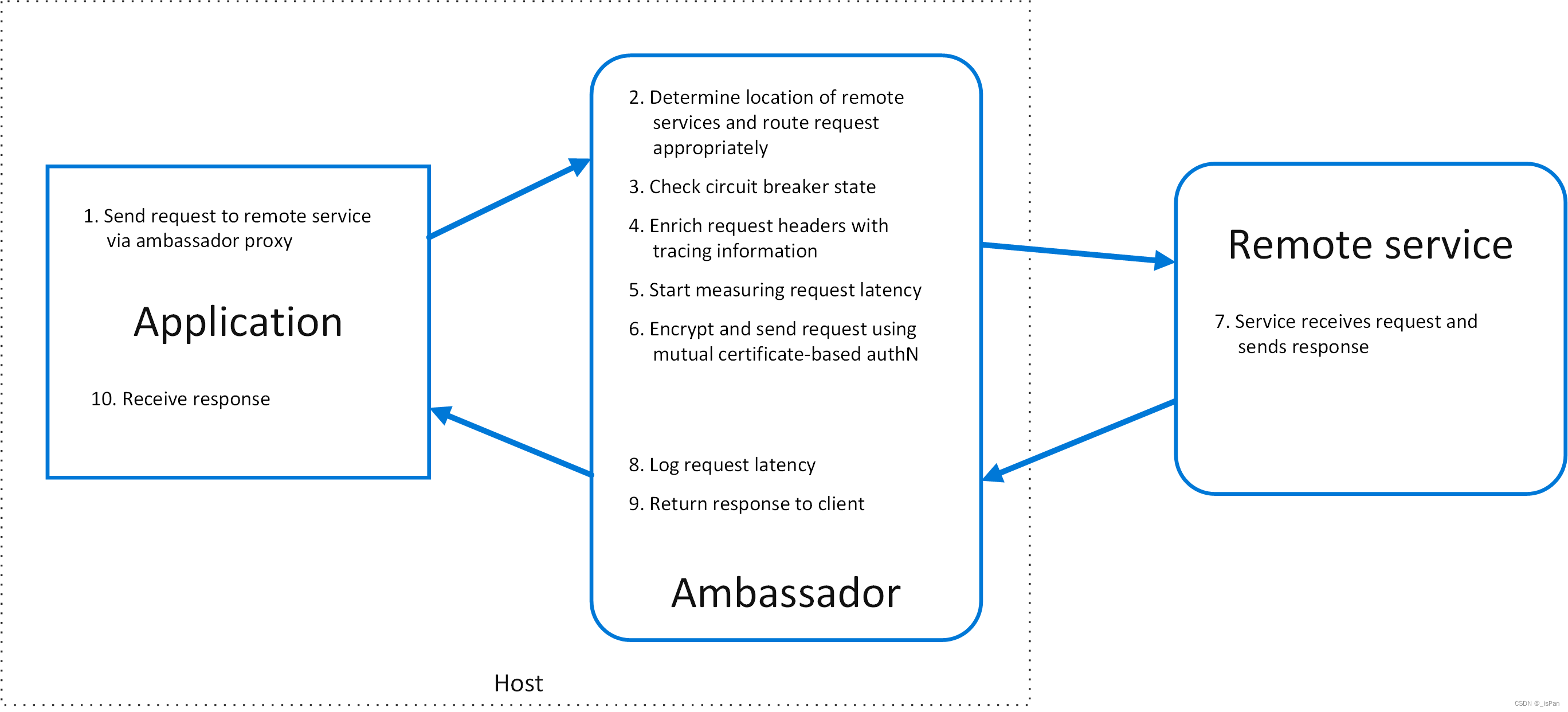
怎样完成票据证件的关键信息抽取任务
基于深度学习的主流方法
关键信息抽取任务流程
训练OCR模型
文本检测
文本识别
训练KIE模型
SER
SER + RE
作者有言
怎样完成票据证件的关键信息抽取任务

文档版面分析是对图片或页面扫描图像上感兴趣的区域进行定位和分类的过程,版面分析的目的是让机器“看懂”文档结构,即将文档图像分割成不同类型内容的区域,并分析区域之间的关系,这是内容识别之前的关键步骤。从广义上讲,大多数方法可以提炼为页面分割和逻辑结构分析。
页面分割方法侧重于外观,并使用视觉线索将页面划分为不同的区域;最常见的是文本、图形、图像和表格。
逻辑结构分析侧重于为这些区域提供更细粒度的语义分类,即识别作为段落的文本区域,并将其与标题或文档标题区分开来。

根据Koichi Kise在2014年提出,如下图所示,印刷文件可分为六种类型:(a)矩形,(b)曼哈顿,©非曼哈顿,(d)多柱曼哈顿,(e)水平重叠,(f)对角线重叠。

其中矩形版面指的是由水平和垂直方向的单列或多列大型矩形版面;每一栏只有一个段落。而类似的具有多个段落的文档来源可以被归类为曼哈顿布局;非曼哈顿版面则指那些具有非矩形形状区域的布局版面;多柱曼哈顿版面则指包含多个垂直或者水平柱子且依然以直角或者直线为主要元素排列而成的版本;水平重叠和对角线重叠都属于一些复杂型格式。
面向文档图像版面分析的实例分割是指在对文档图像进行版面分析时,同时进行实例级别的目标分割,它负责检测和注释文档的物理结构,将文档图像中不同语义类别的物体进行精确、有效地分割,其主要目的是将文本、图片、表格等不同类型的内容从背景中区分出来,以便更好地理解和处理这些信息。大多数在页面分割上的工作可以分为两类:自底向上和自顶向下的方法。
自底向上的方法首先基于局部特征(黑白像素或者连通区域)检测单词,然后顺序地将成群的单词组合成文本行和段落。然而,这种方法在连通区域的识别和组合时十分费时。
自顶向下的方法将一个页面迭代地分割成列、块、文本行和单词。这两种方法都很难正确的分割复杂布局的文档,例如一个有非矩形图片的文档。
一个常见的实例分割算法是Mask R-CNN,它基于深度学习技术并引入了掩码预测模块,在检测任务中可以直接输出每个物体所在位置及其对应的掩码信息。通过训练模型,我们可以获得一个能够自动识别并定位不同物体,并将它们精确提取出来的系统。
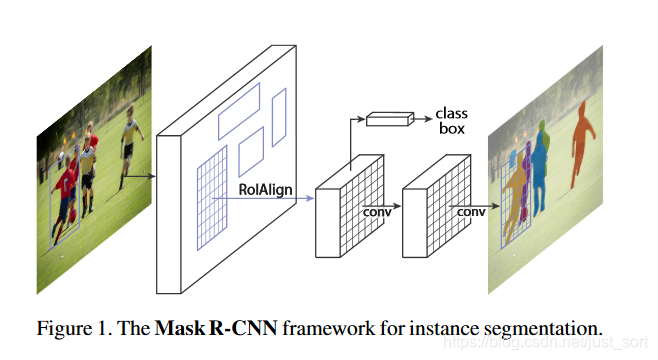
如上图所示:首先输入预处理后的原始图片,并将其送入特征提取网络中,以获得特征图。然后,在每个像素位置设定固定数量的ROI或Anchor,并将这些ROI区域送入RPN网络进行二分类(前景和背景)以及坐标回归,从而获取经过精炼处理的ROI区域。
接下来,需要对这些ROI区域执行论文提出的ROIAlign操作。该操作包括两个主要部分:首先是对应匹配原图和feature map各自在相同位置上的像素点;接着是将feature map与固定的feature进行对应。
最终,在完成前面所有步骤之后,多个经过筛选、匹配和调整过程形成的ROI区域需进行多类别分类、候选框回归并引入FCN生成Mask等措施来完成实际分割任务。
在LayoutLM中,作者描述了一种端到端神经网络,在编码器-解码器架构中同时结合文本和视觉特征,并融入无监督预训练网络,其通过多模态的方式首次将text、layout以及style信息融合在单一模型中进行联合优化与预测,用到了NLP领域中利用大规模无标签数据做模型自监督训练的pretrain范式。在推理过程中,他们的方法使用下采样池化层级联编码视觉信息,然后输入对称上采样级联进行解码。在每个级联水平上,所产生的编码也直接传递到相应的解码块中,连接向下和向上采样表示。这种架构确保了在编码和解码过程中考虑不同分辨率水平处视觉特征信息。
这种编码-解码模型结构简单,效果强大,利用大规模无标注文档数据集进行文本与版面的联合预训练,为后面该系列模型的持续改良优化提供了有力的支撑。
针对版面分析问题,逻辑结构分析从图像的像素分布角度区分解决方案,大致可分为以下几类:
分类定位法:该方法主要通过判断独立像素块的分类归属来对图像中的像素块进行二分类过程。然后再通过二分类的IOU计算确定像素块之间的联通关系,并将具有确定性关系的像素块进行融合,最终从“分->总”的角度对具体联通的像素块进行组合重建。此外,还可以根据Softmax获取组合之后像素块的分类标签信息。
像素级语义分割法:通过对每个像素点进行分类,并最终将所有经过聚合处理后得到所述目标物体区域(即“框”)。
基于内容的图像检索法:该方法主要从内容描述角度出发,利用一些描述性特征(如布局、上下文相关性等),来处理文档或者其他图片中各个区域所包含信息并进行匹配和搜索。
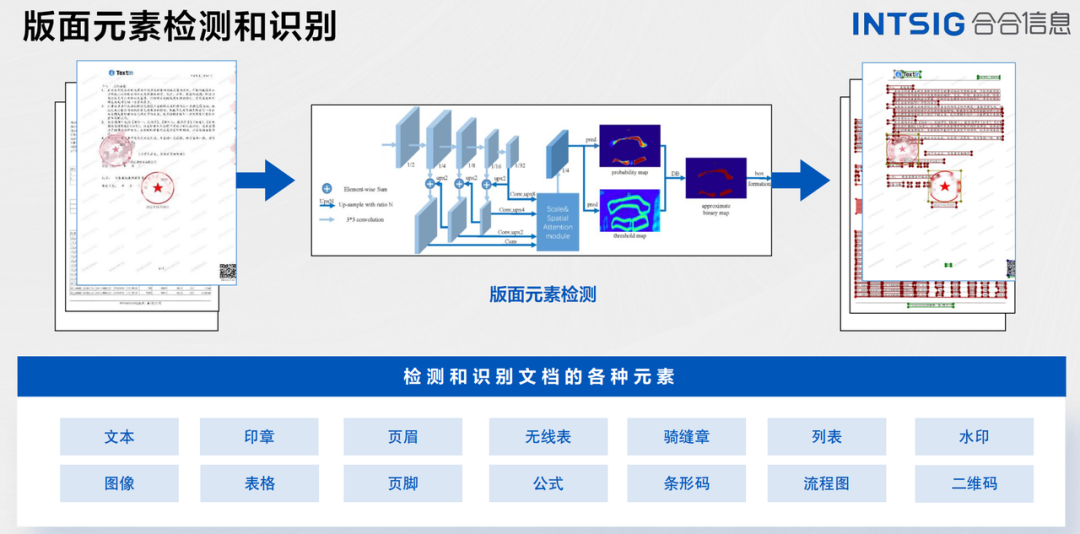
关键信息抽取 (Key Information Extraction, KIE)指的是是从文本或者图像中,抽取出关键的信息。针对文档图像的关键信息抽取任务作为OCR的下游任务,存在非常多的实际应用场景,如表单识别、车票信息抽取、身份证信息抽取等。然而,使用人力从这些文档图像中提取或者收集关键信息耗时费力,怎样自动化融合图像中的视觉、布局、文字等特征并完成关键信息抽取是一个价值与挑战并存的问题。
对于特定场景的文档图像,其中的关键信息位置、版式等较为固定,因此在研究早期有很多基于模板匹配的方法进行关键信息的抽取,考虑到其流程较为简单,该方法仍然被广泛应用在目前的很多场景中。但是这种基于模板匹配的方法在应用到不同的场景中时,需要耗费大量精力去调整与适配模板,迁移成本较高。
文档图像中的KIE一般包含2个子任务,示意图如下图所示。
-
(1)SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
-
(2)RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题 (key) 和答案 (value) 。然后对每一个问题找到对应的答案,相当于完成key-value的匹配过程。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。

基于深度学习的主流方法
一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)来展开研究,但是此类方法仅使用了文本信息而忽略了位置与视觉特征信息,因此精度受限。近几年大多学者开始融合多个模态的输入信息,进行特征融合,并对多模态信息进行处理,从而提升KIE的精度。主要方法有以下几种
-
(1)基于Grid的方法:此类方法主要关注图像层面多模态信息的融合,文本大多大多为字符粒度,对文本与结构结构信息的嵌入方式较为简单,如Chargrid[1]等算法。
-
(2)基于Token的方法:此类方法参考NLP中的BERT等方法,将位置、视觉等特征信息共同编码到多模态模型中,并且在大规模数据集上进行预训练,从而在下游任务中,仅需要少量的标注数据便可以获得很好的效果。如LayoutLM[2], LayoutLMv2[3], LayoutXLM[4], StrucText[5]等算法。
-
(3)基于GCN的方法:此类方法尝试学习图像、文字之间的结构信息,从而可以解决开集信息抽取的问题(训练集中没有见过的模板),如GCN[6]、SDMGR[7]等算法。
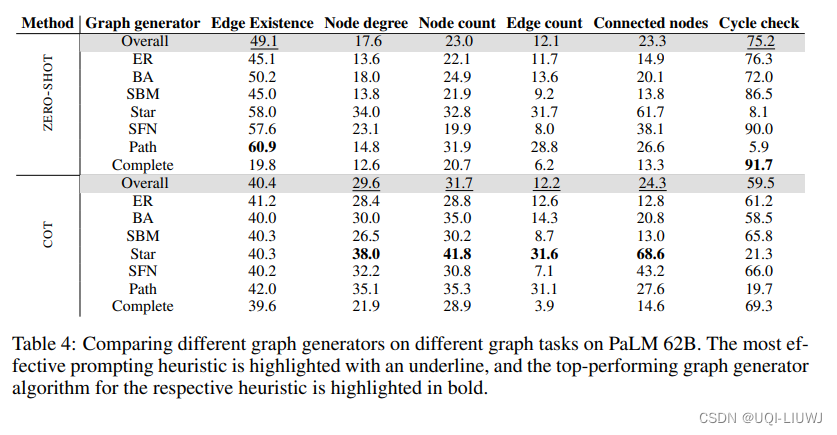
-
(4)基于End-to-end的方法:此类方法将现有的OCR文字识别以及KIE信息抽取2个任务放在一个统一的网络中进行共同学习,并在学习过程中相互加强。如Trie[8]等算法。
关键信息抽取任务流程
PaddleOCR中实现了LayoutXLM等算法(基于Token),同时,在PP-Structurev2中,对LayoutXLM多模态预训练模型的网络结构进行简化,去除了其中的Visual backbone部分,设计了视觉无关的VI-LayoutXLM模型,同时引入符合人类阅读顺序的排序逻辑以及UDML知识蒸馏策略,最终同时提升了关键信息抽取模型的精度与推理速度。
下面介绍怎样基于PaddleOCR完成关键信息抽取任务。
在非End-to-end的KIE方法中,完成关键信息抽取,至少需要2个步骤:首先使用OCR模型,完成文字位置与内容的提取,然后使用KIE模型,根据图像、文字位置以及文字内容,提取出其中的关键信息。
训练OCR模型
文本检测
(1)数据
PaddleOCR中提供的模型大多数为通用模型,在进行文本检测的过程中,相邻文本行的检测一般是根据位置的远近进行区分,如上图,使用PP-OCRv3通用中英文检测模型进行文本检测时,容易将”民族“与“汉”这2个代表不同的字段检测到一起,从而增加后续KIE任务的难度。因此建议在做KIE任务的过程中,首先训练一个针对该文档数据集的检测模型。
在数据标注时,关键信息的标注需要隔开,比上图中的 “民族汉” 3个字相隔较近,此时需要将”民族“与”汉“标注为2个文本检测框,否则会增加后续KIE任务的难度。
对于下游任务,一般来说,200~300张的文本训练数据即可保证基本的训练效果,如果没有太多的先验知识,可以先标注 200~300 张图片,进行后续文本检测模型的训练。
文本识别
相对自然场景,文档图像中的文本内容识别难度一般相对较低(背景相对不太复杂),因此优先建议尝试PaddleOCR中提供的PP-OCRv3通用文本识别模型
数据
然而,在部分文档场景中也会存在一些挑战,如身份证场景中存在着罕见字,在发票等场景中的字体比较特殊,这些问题都会增加文本识别的难度,此时如果希望保证或者进一步提升模型的精度,建议基于特定文档场景的文本识别数据集,加载PP-OCRv3模型进行微调。
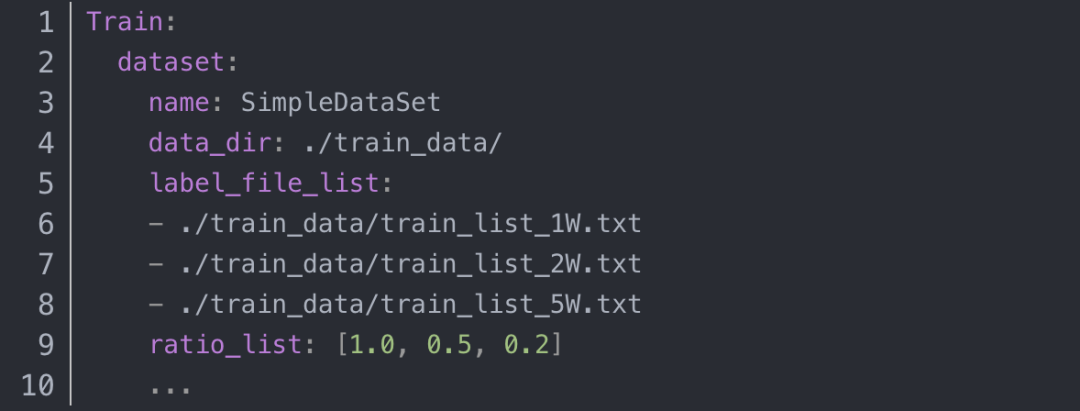
在模型微调的过程中,建议准备至少5000张垂类场景的文本识别图像,可以保证基本的模型微调效果。如果希望提升模型的精度与泛化能力,可以合成更多与该场景类似的文本识别数据,从公开数据集中收集通用真实文本识别数据,一并添加到该场景的文本识别训练任务过程中。在训练过程中,建议每个epoch的真实垂类数据、合成数据、通用数据比例在1:1:1左右,这可以通过设置不同数据源的采样比例进行控制。如有3个训练文本文件,分别包含1W、2W、5W条数据,那么可以在配置文件中设置数据如下:
训练KIE模型
对于识别得到的文字进行关键信息抽取,有2种主要的方法。
(1)直接使用SER,获取关键信息的类别:如身份证场景中,将“姓名“与”张三“分别标记为name_key与name_value。最终识别得到的类别为name_value对应的文本字段即为我们所需要的关键信息。
(2)联合SER与RE进行使用:这种方法中,首先使用SER,获取图像文字内容中所有的key与value,然后使用RE方法,对所有的key与value进行配对,找到映射关系,从而完成关键信息的抽取。
SER
以身份证场景为例, 关键信息一般包含姓名、性别、民族等,我们直接将对应的字段标注为特定的类别即可,如下图所示。

注意:
-
标注过程中,对于无关于KIE关键信息的文本内容,均需要将其标注为
other类别,相当于背景信息。如在身份证场景中,如果我们不关注性别信息,那么可以将“性别”与“男”这2个字段的类别均标注为other。 -
标注过程中,需要以文本行为单位进行标注,无需标注单个字符的位置信息。
数据量方面,一般来说,对于比较固定的场景,50张左右的训练图片即可达到可以接受的效果,可以使用PPOCRLabel完成KIE的标注过程。
模型方面,推荐使用PP-Structurev2中提出的VI-LayoutXLM模型,它基于LayoutXLM模型进行改进,去除其中的视觉特征提取模块,在精度基本无损的情况下,进一步提升了模型推理速度。
SER + RE
该过程主要包含SER与RE 2个过程。SER阶段主要用于识别出文档图像中的所有key与value,RE阶段主要用于对所有的key与value进行匹配。
以身份证场景为例, 关键信息一般包含姓名、性别、民族等关键信息,在SER阶段,我们需要识别所有的question (key) 与answer (value) 。标注如下所示。每个字段的类别信息(label字段)可以是question、answer或者other(与待抽取的关键信息无关的字段)

在RE阶段,需要标注每个字段的的id与连接信息,如下图所示。

每个文本行字段中,需要添加id与linking字段信息,id记录该文本行的唯一标识,同一张图片中的不同文本内容不能重复,linking是一个列表,记录了不同文本之间的连接信息。如字段“出生”的id为0,字段“1996年1月11日”的id为1,那么它们均有[[0, 1]]的linking标注,表示该id=0与id=1的字段构成key-value的关系(姓名、性别等字段类似,此处不再一一赘述)。
注意:
-
标注过程中,如果value是多个字符,那么linking中可以新增一个key-value对,如
[[0, 1], [0, 2]]
数据量方面,一般来说,对于比较固定的场景,50张左右的训练图片即可达到可以接受的效果,可以使用PPOCRLabel完成KIE的标注过程。
模型方面,推荐使用PP-Structurev2中提出的VI-LayoutXLM模型,它基于LayoutXLM模型进行改进,去除其中的视觉特征提取模块,在精度基本无损的情况下,进一步提升了模型推理速度。
作者有言
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……