解决:Word 保存文档失败,重启电脑后,Word 在试图打开文件时遇到错误

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/29207.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

【LeetCode 热题 100】3. 无重复字符的最长子串 | python 【中等】
美美超过管解
题目:
3. 无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长的长度。
示例 1:
输入: s "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
注…

weblogic部署报错汇总
weblogic部署报错汇总 Weblogic部署遇到的问题 1.部署完weblogic,进入weblogic控制台,后提示无资源可访问。
解决方法: 权限问题,检查weblogic应用的启动用户和所属用户是否一致。
2. 安装weblogic,创建域的时候特别…

如何在后端服务发布过程中使用蓝绿部署
一、概念
蓝绿部署(Blue-Green Deployment)是一种常用的零停机发布策略,旨在减少发布过程中的风险和系统停机时间。它通过在同一环境中并行维护两个相似的环境(蓝色环境和绿色环境)来实现无缝的应用发布。以下是蓝绿部署策略在后端服务发布中的应用流程以及一些注意事项。…

辛格迪客户案例 | 深圳善康医药科技GMP培训管理(TMS)项目
01 善康医药:创新药领域的探索者
深圳善康医药科技股份有限公司自2017年创立以来,便扎根于创新药研发领域,专注于成瘾治疗药物的研究、生产与销售。公司坐落于深圳,凭借自身独特的技术优势与研发实力,在行业内逐渐崭露…

ArcGIS Pro:轻松制作地震动画,洞察灾害动态
在当今的信息展示领域,动画因其直观、生动的特点,逐渐成为各类汇报、研究展示中的重要元素。
尤其是在地理信息领域,通过动画来展示动态的地理现象,能够让观众更清晰地理解数据背后所蕴含的信息。
地震作为一种突发性的自然灾害…

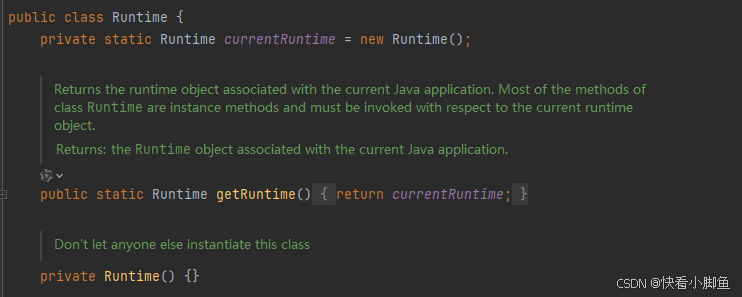
单例模式的五种实现方式
1、饿汉式 ①实现:在类加载的时候就初始化实例 ②优点:线程安全 ③缺点:实例在类加载的时候创建,可能会浪费资源
//饿汉式
public class EagerSingleton{private EagerSingleton(){} //私有构造方法private static EagerSingle…

2025-03-04 学习记录--C/C++-C语言 判断是否是素数
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 C语言 判断是否是素数
一、代码 ⭐️
#include <stdio.h>
#include <stdbool.h> // 使用 bool 类型// 判断是否是…

MR的环形缓冲区(底层)
MapReduce的大致流程:
1、HDFS读取数据;
2、按照规则进行分片,形成若干个spilt;
3、进行Map
4、打上分区标签(patition)
5、数据入环形缓冲区(KVbuffer)
6、原地排序ÿ…
LeetCode hot 100—二叉树的中序遍历
题目
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 示例 1: 输入:root [1,null,2,3]
输出:[1,3,2]示例 2: 输入:root []
输出:[]示例 3: 输入:root […

aws(学习笔记第三十一课) aws cdk深入学习(batch-arm64-instance-type)
aws(学习笔记第三十一课) aws cdk深入学习
学习内容:
深入练习aws cdk下部署batch-arm64-instance-type 1. 深入练习aws cdk下部署batch-arm64-instance-type 代码链接 代码链接 代码链接 -> batch-arm64-instance-type之前代码学习 之前学习代码链接 -> aw…

C语言基础之【指针】(下)
C语言基础之【指针】(下) 指针和字符串字符指针字符指针做函数参数const修饰的指针变量指针数组做为main函数的形参项目开发常用字符串应用模型while和do-while模型两头堵模型字符串反转模型 字符串处理函数strchr()strrchr()strstr()strtok()strcpy()st…

【够用就好006】如何从零开发游戏上架steam面向AI编程的godot独立游戏制作实录001流程
记录工作实践 这是全新的系列,一直有个游戏制作梦 感谢AI时代,让这一切变得可行 长欢迎共同见证,期更新,欢迎保持关注,待到游戏上架那一天,一起玩
面向AI编程的godot独立游戏制作流程实录001
本期是第…

java 重点知识 — JVM存储模块与类加载器
1 jvm主要模块 方法区 存储了由类加载器从.class文件中解析的类的元数据(类型信息、域信息、方法信息)及运行时常量池(引用符号及字面量)。 所有线程共享;内存不要求连续,可扩展,可能发生垃圾回…

Docker基础篇——什么是Docker与Docker的仓库、镜像、容器三大概念
大家好我是木木,在当今快速发展的云计算与云原生时代,容器化技术蓬勃兴起,Docker 作为实现容器化的主流工具之一,为开发者和运维人员带来了极大的便捷 。下面我们一起了解下什么是Docker与与Docker的仓库、镜像、容器三大概念。
…

网页制作11-html,css,javascript初认识のCCS样式列表(下)
六、外边距,内边距,边框属性
盒子模型: 1、外边距:margin img{ margin:40px 30px 10px 20px; }/*外边距复合属性:上右下左*/ 2、内边距 body{ padding:10px 20px 40px 30px; }/*内边距复合属性:上右下左*/ 3、边框
1)边框样式 取…

爬虫Incapsula reese84加密案例:Etihad航空
声明: 该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关
一、找出需要加密的参数
1.js运行 atob(‘aHR0cHM6Ly93d3cuZXRpaGFkLmNvbS96aC1jbi8=’) 拿到网址,F12打开调试工具,随便搜索航班,切换到network搜索一个时间点可以找…

Unity 适用Canvas 为任一渲染模式的UI 拖拽
RectTransformUtility-ScreenPointToWorldPointInRectangle - Unity 脚本 API
将一个屏幕空间点转换为世界空间中位于给定RectTransform 平面上的一个位置。
实现 获取平面位置。
parentRT transform.parent as RectTransform;
继承IPointerDownHandler 和IDragHandler …

【HDLbits--FSM续(二)】
HDLbits--FSM-2 本篇文章接续介绍Verilog中FSM典型案例; 题目:Lemmings3 module top_module(input clk,input areset, // Freshly brainwashed Lemmings walk left.input bump_left,input bump_right,input ground,input dig,output walk_left,outpu…

安装与配置 STK-MATLAB 接口
STK版本为11.6 Matlab版本为R2018a STK 提供 Connect 和 Object Model (COM) 两种接口与 MATLAB 交互,推荐使用 COM接口进行二次开发。 确保安装了 STK,并且 MATLAB 可以访问 STK Object Model。 在 MATLAB 中运行:
% 添加 STK COM 库&#…
推荐文章
- .NET 9 微软官方推荐使用 Scalar 替代传统的 Swagger
- (2)STM32 USB设备开发-USB虚拟串口
- @LoadBalanced注解的实现原理
- [创业之路-270]:《向流程设计要效率》-2-企业流程架构模式 POS架构(规划、业务运营、支撑)、OES架构(业务运营、使能、支撑)
- [德州扑克]
- [微服务]redis数据结构
- 《JavaWeb开发-javascript基础》
- 【0001】初识Java
- 【2】好未来JAVA开发工程师部分笔试题解析
- 【Flink银行反欺诈系统设计方案】3.欺诈的7种场景和架构方案、核心表设计
- 【Git版本控制器】:第一弹——Git初识,Git安装,创建本地仓库,初始化本地仓库,配置config用户名,邮箱信息
- 【IoTDB 线上小课 11】为什么 DeepSeek 要选择开源?