What can I say?
2024年我还能说什么?
Mamba out!
曼巴出来了!

原文链接:
[2312.00752] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (arxiv.org)
原文笔记:
What:
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
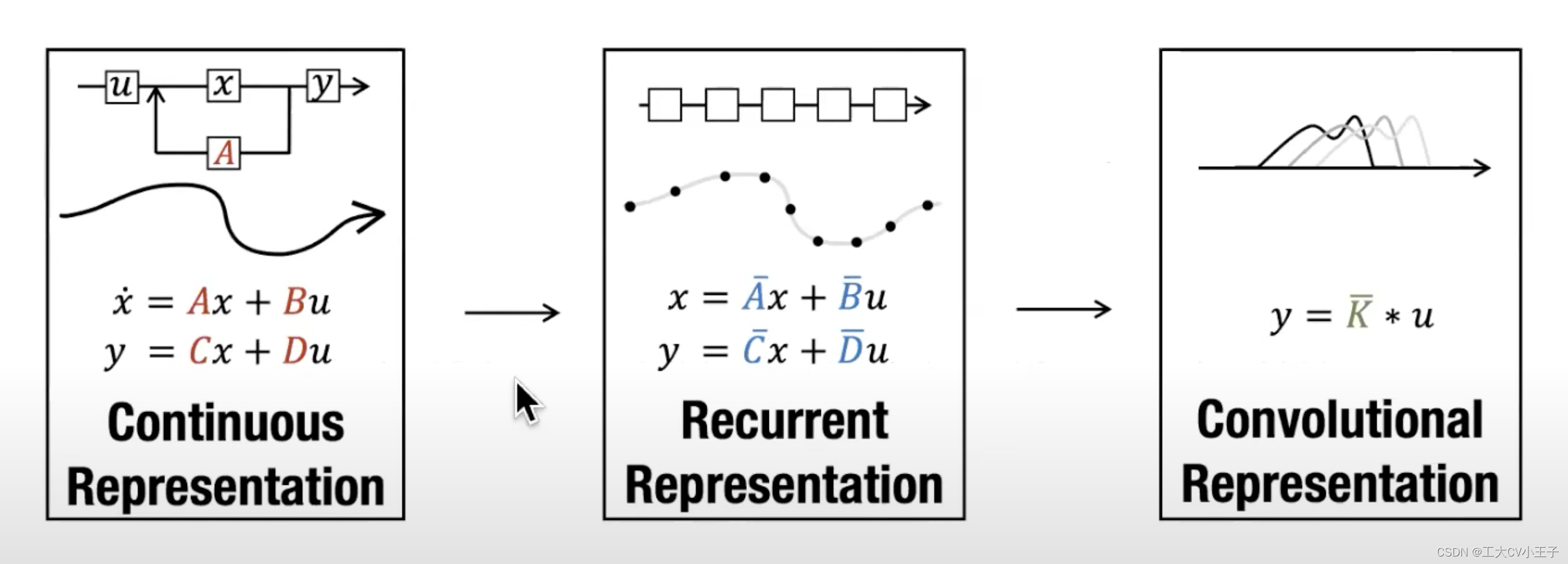
SSM——>S4——>S6——>Mamba
SSM:(不能处理离散序列,不能有选择地处理信息A,B,C,D的值都是固定不变的)
一般SSMs包括以下组成
- 映射输入序列x(t),比如在迷宫中向左和向下移动
- 到潜在状态表示h(t),比如距离出口距离和 x/y 坐标
- 并导出预测输出序列y(t),比如再次向左移动以更快到达出口
然而,它不使用离散序列(如向左移动一次),而是将连续序列作为输入并预测输出序列

这里的h'(t)不是h(t)导数,是新的状态。SSM 假设系统(例如在 3D 空间中移动的物体)可以通过两个方程从其在时间 时的状态进行预测「 当然,其实上面第一个方程表示成这样可能更好:
,不然容易引发歧义 」
RNN本身就可以理解乘一个SSM
参数A春初这之前所有历史信息的浓缩精华(可以通过一系列系数组成的矩阵表示之),以基于A更新下一个时刻的空间状态hidden state
总之,通过求解这些方程,可以根据观察到的数据:输入序列和先前状态,去预测系统的未来状态
建立两个方程的统一视角:
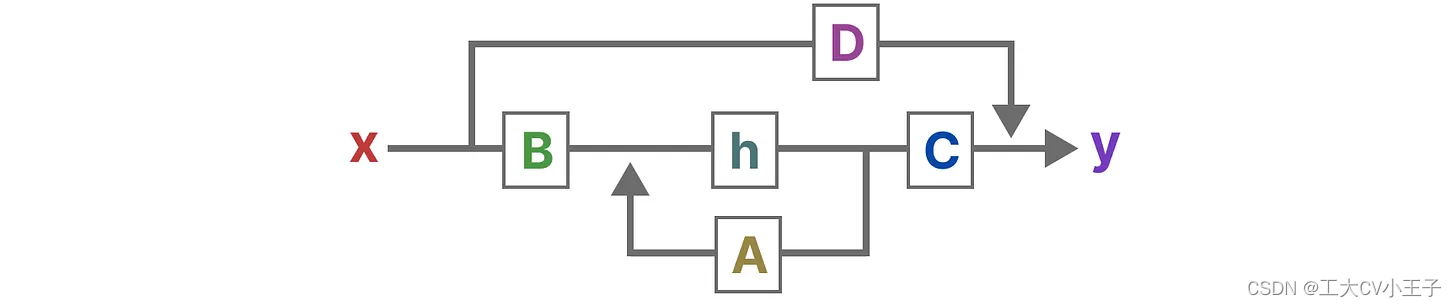
S4:(离散化SSM、循环/卷积表示,基于HiPPO处理长序列,不能有选择的处理信息,A,B,C,D的值都是固定不变的)详见参考1

S6:SSM+Selection(可以处理离散数据,有选择地处理信息,训练效率降低)
在Mamaba中,作者让矩阵、
矩阵、
成为输入的函数(即可学习或可训练的),让模型能够根据输入内容自适应地调整其行为
Mamba: (可以处理离散数据+有选择地处理信息+硬件感知算法+更简单的SSM架构)
Why:
1、Transformer在处理长序列时存在着计算效率低下的问题,无法对有限窗口之外的任何信息进行建模,以及相对于窗口长度的二次缩放。
2、用于解决问题一的方法如线性注意力,门控卷积和循环模型以及结构化状态空间模型在表现上(在语言等重要模态上)不如注意力,他们无法执行基于内容的推理。(效果差的原因:不能像attention机制那样全局感知;缺乏对离散数据的的建模能力(SSM))
3、传统的SSM模型在建模离散和信息密集数据(例如文本)方面效果较差。S4能离散建模泵选择处理,S6能离散建模和选择处理又遇到了新的问题:无法将高效的卷积应用于训练以通过并行的方式提高训练效率,之后作者也提出了优化方法(idea3))
4、鉴于1,2,3,我们要寻求一种在计算效率和模型效果之间的平衡,找到同时在这两个方面表现都很优秀的模型
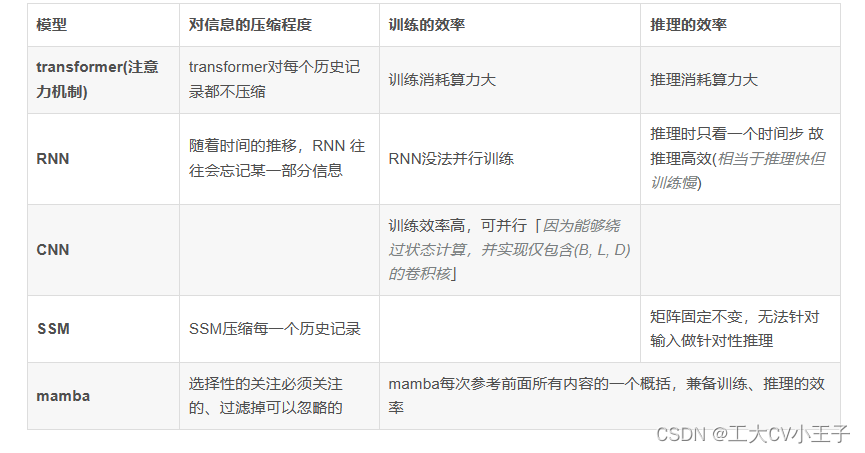
总之,序列模型的效率与效果的权衡点在于它们对状态的压缩程度:
- 高效的模型必须有一个小的状态(比如RNN或S4)
- 而有效的模型必须有一个包含来自上下文的所有必要信息的状态(比如transformer)
而mamba为了兼顾效率和效果,选择性的关注必须关注的、过滤掉可以忽略的
Challenge:
1、基于内容的长时记忆以及推理(应该包含上下文所有的必要信息),能够以依赖于输入的方式有效地选择数据(即专注于或忽略特定输入)
2、较短的处理时间(训练时间以及测试时间)
Idea:Mamba: (可以处理离散数据+有选择地处理信息+硬件感知算法+更简单的SSM架构)
1、通过离散化操作解决了传统SSM的弱点(准确率上)
2、为了解决Challenge1,作者提出:让SSM参数成为输入的函数,允许模型根据当前token有选择地沿序列长度维度传播或忘记信息。(准确率上)
3、idea1和2 阻碍了将高效卷积应用于训练以通过并行的方式提高训练效率,为此作者在循环模式下设计了一个硬件感知的并行算法。(性能上)
4、作者将所涉及的ssm集成到简化的端到端神经网络架构中,而无需注意力模块甚至MLP块
(模型原创性,泛化性)
张量具体怎么对齐的等我研究明白再更新
Model:

原文翻译:
(红字:出现的问题,黄字:想法重点,绿字:效果,篮字:看参考)
Abstract
现在为深度学习中大多数令人兴奋的应用程序提供动力的基础模型,几乎普遍基于Transformer架构及其核心的注意力模块。许多subquadratic-time(次二次时间)架构,如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(ssm)已经被开发出来,以解决Transformer在长序列上的计算效率低下问题,但它们在语言等重要模态上的表现不如注意力。我们发现这些模型的一个关键弱点是它们无法执行基于内容的推理,并进行了一些改进。首先,简单地让SSM参数成为输入的函数,通过离散模态解决了它们的弱点,允许模型根据当前令牌有选择地沿序列长度维度传播或忘记信息。其次,尽管这种变化阻碍了高效卷积的使用,但我们在循环模式下设计了一个硬件感知的并行算法。我们将这些选择性ssm集成到简化的端到端神经网络架构中,而无需注意力模块甚至MLP块。Mamba具有快速推理(比Transformers高5倍的吞吐量)和序列长度的线性缩放,并且其性能在真实数据高达百万长度的序列上有所提高。作为一个通用的序列模型主干,Mamba在语言、音频和基因组学等多种模式上实现了最先进的性能。在语言建模方面,我们的Mamba-3B模型在预训练和下游评估方面都优于同等大小的变形金刚,并且与变形金刚的两倍大小相匹配。
1 Introduction
基础模型 (FM) 或在大量数据上预训练的大型模型,然后适应下游任务,已成为现代机器学习的有效范式。这些FM的主干通常是序列模型,对来自语言、图像、语音、音频、时间序列和基因组学等多个领域的任意输入序列进行操作(Brown等人,2020;Dosovitskiy等人,2020;Ismail Fawaz等人,2019;Oord等人,2016;Poli等人2023;Sutskever, Vinyals和Quoc V Le 2014)。虽然这个概念与模型架构的特定选择无关,但现代 FM 主要基于一种类型的序列模型:Transformer (Vaswani et al. 2017) 及其核心注意力层 (Bahdanau, Cho, and Bengio 2015) 自注意力的功效归因于它能够在上下文窗口中密集地路由信息,使其能够对复杂的数据进行建模。然而,此属性带来了根本的缺点:无法对有限窗口之外的任何信息进行建模,以及相对于窗口长度的二次缩放。大量研究似乎在更有效的注意力变体上来克服这些缺点(Tay、Dehghani、Bahri 等 2022),但通常以牺牲使其有效的重要属性为代价。然而,这些变体都没有被证明在跨领域的规模上在经验上是有效的。
最近,结构化状态空间模型 (SSM) (Gu, Goel and Ré 2022; Gu, Johnson, Goel, et al. 2021) 已成为序列建模的一种有前途的架构。这些模型可以解释为循环神经网络 (RNN) 和卷积神经网络 (CNN) 的组合,灵感来自经典状态空间模型 (Kalman 1960)。此类模型可以非常有效地计算为递归或卷积,序列长度具有线性或接近线性缩放。此外,它们具有在某些数据模式下对远程依赖关系建模的原则机制(Gu, Dao, et al. 2020),并主导了远程竞技场等基准(Tay, Dehghani, Abnar等人,2021年)。许多风格的SSMs(Gu,Goel和Ré 2022;Gu,Gupta等人。2022;Gupta,Gu和Berant 2022;Y。李等人。 2023;马等人。 2023;奥维托等人。 2023;史密斯、华灵顿和林德曼 2023)在涉及音频和视觉等连续信号数据的领域取得了成功(Goel 等人 2022;Nguyen、Goel 等人,2022;Saon、Gupta 和 Cui 2023)。然而,它们在建模离散和信息密集数据(例如文本)方面效果较差。
我们提出了一类新的选择性状态空间模型,它在几个轴上改进了先前的工作,以实现 Transformer 的建模能力,同时在序列长度上线性缩放。
选择机制。首先,我们确定了先前模型的一个关键限制:能够以依赖于输入的方式有效地选择数据(即专注于或忽略特定输入)。基于基于重要合成任务(选择性复制和诱导头等)的直觉,我们设计了一种简单的选择机制:根据输入参数化SSM参数。这允许模型过滤掉不相关的信息并无限地记住相关信息。(长时记忆并且能正确选择)
硬件感知算法。这种简单的改变对模型的计算提出了技术挑战;事实上,为了提高计算效率,所有先前的ssm模型都必须是时间和输入不变的。我们使用硬件感知算法克服了这一点,该算法使用扫描而不是卷积来循环计算模型,但不实现扩展状态,以避免在GPU内存层次结构的不同级别之间进行IO访问。由此产生的实现在理论上(序列长度线性缩放,与所有基于卷积的ssm的伪线性相比)和现代硬件上(在A100 gpu上快3倍)都比以前的方法快。
体系结构。我们通过将先前的SSM架构(Dao, Fu, Saab, et al. 2023)的设计与transformer的MLP块合并为一个块来简化先前的深度序列模型架构,从而得到一个包含选择性状态空间的简单且同质的架构设计(Mamba)。
选择性ssm,以及扩展的Mamba架构,是具有关键属性的完全循环的模型,这些属性使它们适合作为在序列上操作的一般基础模型的特征提取网络。这些属性有(i)高质量:选择性使语言和基因组学等密集模式的表现强劲。(ii)快速训练和推理:在训练期间,计算和内存在序列长度上呈线性扩展,并且在推理期间自回归展开模型只需要每步恒定的时间,因为它不需要先前元素的缓存(因为只需要先前状态)。(iii)长上下文:质量和效率共同提高了实际数据的性能,最长可达1M序列长度。
在以下几种类型的模式和设置下,我们通过经验验证了曼巴在预训练质量和特定领域任务性能方面作为一般序列FM骨干的潜力:
- 合成。在复制和诱导头等重要的合成任务中,作为大型语言模型的关键,Mamba不仅很容易解决它们,而且可以无限长地推断解决方案(>1M令牌)。
- 音频和基因组学。Mamba 在预训练质量和下游指标(例如,在具有挑战性的语音生成数据集上将 FID 减少一半以上)建模音频波形和 DNA 序列的先前最先进模型(例如,在具有挑战性的语音生成数据集上减少 FID 一半以上)。在这两种情况下,它的性能都随着更长的上下文而提高,最高可达百万长序列。
- 语言建模。Mamba 是第一个真正实现 Transformer 质量性能的线性时间序列模型,无论是在预训练困惑度还是下游评估中。通过高达 1B 参数的缩放定律,我们表明 Mamba 超过了大量基线的性能,包括基于 LlaMa 的非常强大的现代 Transformer 训练配方(Touvron 等人 2023)。与大小相似的 Transformer 相比,我们的 Mamba 语言模型具有 5 倍的生成吞吐量,而 Mamba-3B 的质量与其大小的两倍匹配(例如,在常识推理方面,与Pythia-3B相比平均高出4分,甚至超过了Pythia-7B)。
模型代码和预训练的检查点是开源的在https://github.com/state-spaces/mamba
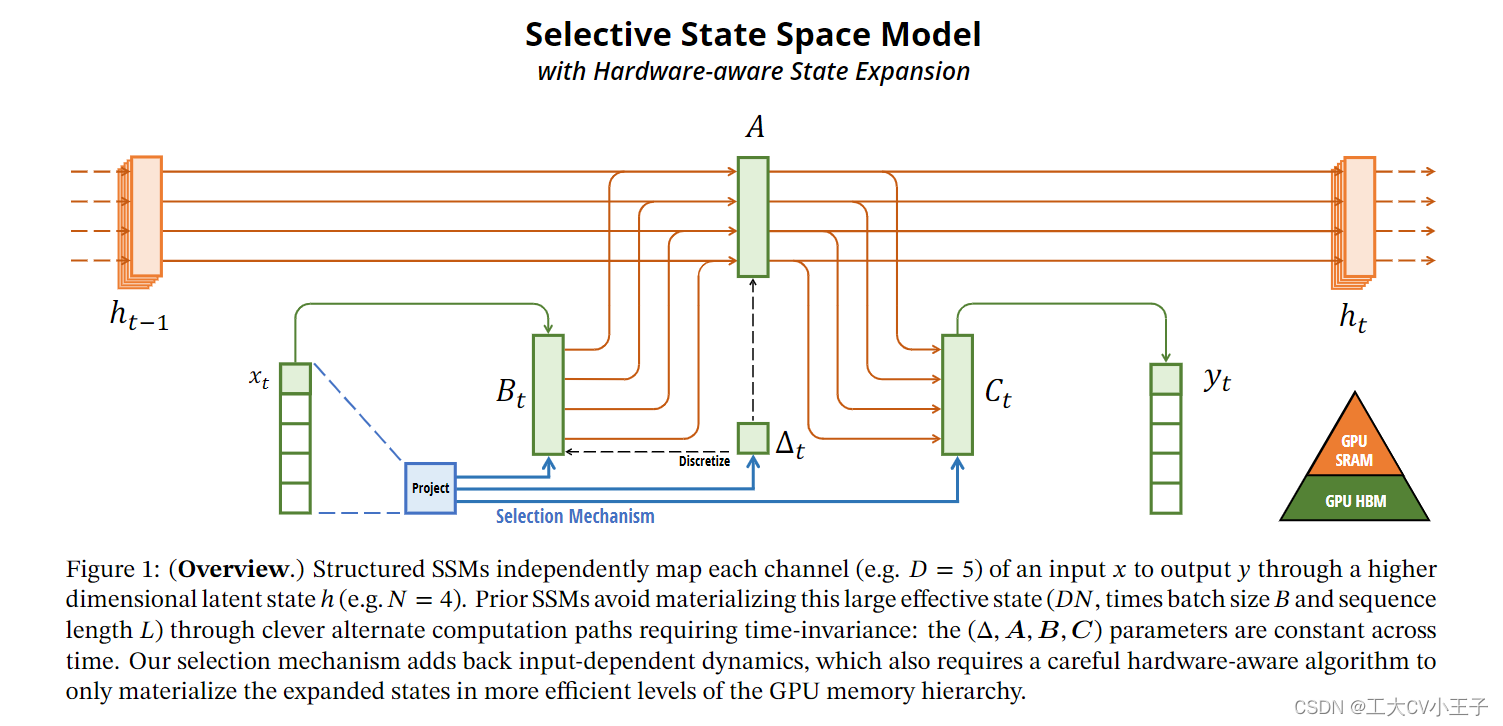
图1:(概述)结构化的SSMs独立的将输入x的每个channel通过高维的潜在状态h映射到输出y,先前的 SSM 通过巧妙的替代计算路径避免通过需要时间不变性来具体化这种大有效状态(DN,乘以批量大小 B 和序列长度 L):(Δ, A, B, C) 参数在时间上是恒定的。我们的选择机制添加了依赖于输入的动态,这也需要仔细的硬件感知算法,以在更高效的 GPU 内存层次结构级别上仅具体化扩展状态。
2 状态空间模型
结构化状态空间模型 (S4) 是最近一类深度学习序列模型,与 RNN 和 CNN 以及经典状态空间模型广泛相关。它们受到一个特定的连续系统 (1) 的启发,该系统通过隐式潜在状态 ℎ(t) ∈ ℝ^N将一个一维函数或序列x(t) ∈ ℝ 映射到y(t)∈ℝ。
具体来说,S4 模型由四个参数(Δ、A、B、C)定义,这些参数分两个阶段定义序列到序列的转换。

离散化。(这段看下原文吧)第一阶段通过固定公式A拔=𝑓A(∆,A) B拔=𝑓B(∆,A, B)将“连续参数”(∆,A, B)转换为“离散参数”(A拔, B拔),其中这对变量(𝑓A,𝑓B)称为离散化规则。可以使用各种规则,如公式(4)中定义的零阶保持器(ZOH) A拔 = exp(∆A) B拔 =(∆A)−1(exp(∆A)−I)·∆B(4)
离散化与连续时间系统有很深的联系,可以赋予它们额外的属性,如分辨率不变性(Nguyen, Goel, et al. 2022),并自动确保模型正确归一化(Gu, Johnson, Timalsina, et al. 2023;Orvieto et al. 2023)。它还与rnn的门控机制有关(Gu, Gulcehre, et al. 2020;Tallec和Ollivier 2018),我们将在3.5节中重新讨论。然而,从力学的角度来看,离散化可以简单地看作是SSM向前传递计算图的第一步。ssm的替代风格可以绕过离散化步骤,直接参数化(A, B) (Zhang et al. 2023),这可能更容易推理。
计算。在参数已经从 (Δ, A, B, C) ↦ (A, B, C) 转换后,模型可以通过两种方式计算,无论是线性递归 (2) 还是全局卷积 (3)。3 通常,该模型使用卷积模式 (3) 进行有效的并行训练(整个输入序列提前看到),并切换到循环模式 (2) 以实现有效的自回归推理(其中输入一次看到一个时间步)。
线性时间不变性(LTI)。等式 (1) 到 (3) 的一个重要特性是模型的动力学随时间是恒定的。换句话说(Δ、A、B、C),以及(A、B)对于所有时间步长都是固定的。此属性称为线性时间不变性 (LTI),它与递归和卷积密切相关。非正式地,我们认为 LTI SSM 等价于任何线性递归 (2a) 或卷积 (3b),并使用 LTI 作为这些类别模型的总称。到目前为止,由于基本效率约束,所有结构化SSM都是线性时不变的(例如计算为卷积),如第3.3节所讨论的。然而,这项工作的核心见解是,LTI模型在建模某些类型的数据方面有根本的局限性,我们的技术贡献涉及在克服效率瓶颈的同时去除LTI约束。(局限性来源于LTI,这使得不能有分别地提取序列中的重要信息,去除LTI约束的方法是参数化SSM,但这又会造成无法使用卷积进行高效的并行训练,带来了效率瓶颈,因此作者又引入了硬件感知算法来解决效率瓶颈问题)
结构和维度。最后,我们注意到结构化 SSM 之所以如此命名,是因为有效地计算它们也需要对 A 矩阵施加结构。最流行的结构形式是对角线(Gu、Gupta 等人 2022;Gupta、Gu 和 Berant 2022;Smith、Warington 和 Linderman 2023),我们也使用。在这种情况下,A ∈ ℝ푡×푡 , B ∈ ℝ푡×1, C ∈ ℝ1×푡 矩阵都可以用 푡 数字表示。为了在批量大小为 푡 的输入序列 푡 和长度为 푡 且具有 푡 通道的长度为 푡 上运行,SSM 独立应用于每个通道。请注意,在这种情况下,总隐藏状态每个输入的维度为 푡,并且在序列长度上计算它需要 푡(¢) 时间和内存;这是 3.3 节中解决的基本效率瓶颈的根。
一般状态空间模型。我们注意到术语状态空间模型具有非常广泛的含义,它只是用潜在状态表示任何循环过程的概念。它已被用于指代不同学科中的许多不同概念,包括马尔可夫决策过程 (MDP) (强化学习 (Hafner et al. 2020))、动态因果建模 (DCM) (计算神经科学 (Friston, Harrison and Penny 2003))、卡尔曼滤波器 (controls (Kalman 1960)、隐马尔可夫模型 (HMM) 和线性动力系统 (LDS)(机器学习)以及大型(深度学习)的循环(有时是卷积)模型。在整篇论文中,我们使用术语“SSM”来仅指结构化SSMs或S4模型的类别(Gu, Goel和Ré 2022;Gu, Gupta, et al. 2022;Gupta, Gu,和Berant 2022;Hasani等人2023;Ma等人2023;Smith, Warrington和Linderman 2023),并交替使用这些术语。为方便起见,我们还包括此类模型的导数,例如那些专注于线性递归或全局卷积视点(Y.Li et al. 2023; Orvieto et al. 2023; Poli et al. 2023),在必要时澄清细微差别。
SSM 架构。SSM是独立的序列转换,可以合并到端到端的神经网络架构中。(我们有时也称SSM架构为SSNNs, SSNNs之于SSM层,就像CNNs之于线性卷积层一样。)我们将讨论一些最著名的SSM体系结构,其中许多也将作为我们的主要基准。
- 线性注意(Katharopoulos et al. 2020)是一种近似的自我注意,涉及递归,可视为退化的线性SSM。
- H3 (Dao, Fu, Saab, et . 2023)将这一递归推广到使用S4;它可以被看作是一个SSM被两个门通连接夹在中间的架构(图3)。H3还在主SSM层之前插入了一个标准的局部卷积,它们将其框架为移位SSM。
- Hyena (Poli et al. 2023)使用与H3相同的架构,但用mlp参数化的全局卷积取代了S4层(Romero et al. 2021)。
- RetNet (Y. Sun et al. 2023)在架构中添加了一个额外的门,并使用更简单的SSM,允许另一种可并行计算路径,使用多头注意(MHA)的变体而不是卷积。
- RWKV (B. Peng et al. 2023)是最近设计的基于另一种线性注意力近似(无注意力变压器(S. Zhai et al. 2021))的语言建模的RNN。其主要的“WKV”机制涉及LTI复发,可以看作是两个ssm的比率。
其他密切相关的SSM和架构将在扩展的相关工作中进一步讨论(附录B)。我们特别强调S5 (Smith, Warrington, and Linderman 2023), QRNN (Bradbury et al. 2016)和SRU (Lei et al. 2017),我们认为这些方法与我们的核心选择性SSM最密切相关。
3 选择性状态空间模型
我们的选择机制的灵感来源于合成任务(第 3.1 节),然后解释如何将这种机制合并到状态空间模型中(第 3.2 节)。如此生成的时变 SSM 不能使用卷积,这对如何有效地计算它们提出了技术挑战。我们使用硬件感知算法来克服这一点,该算法利用了现代硬件上的内存层次结构(第 3.3 节)。然后,我们描述了一个简单的 SSM 架构,没有注意力甚至 MLP 块(第 3.4 节)。最后,我们讨论了选择机制的一些额外属性(第 3.5 节)。
3.1动机:选择作为压缩的一种手段
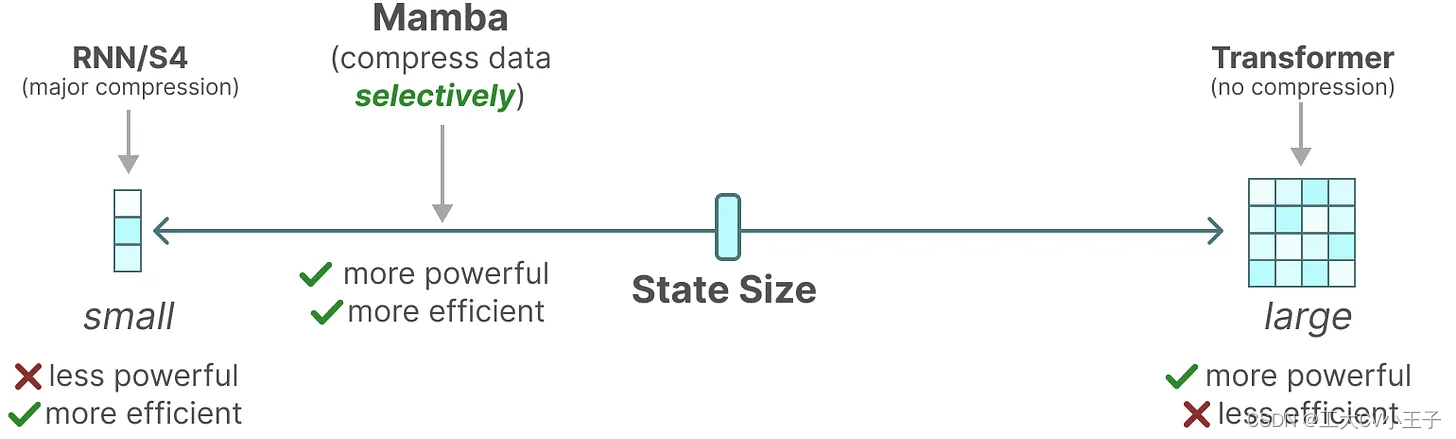
我们认为序列建模的一个基本问题是将上下文压缩成一个更小的状态。事实上,我们可以从这个角度来看待流行序列模型的权衡。例如,注意力既有效又低效,因为它根本不压缩上下文。这可以从自回归推理需要显式存储整个上下文(即KV缓存)这一事实中看出,这直接导致了变压器的线性时间推理和二次时间训练缓慢。另一方面,循环模型是有效的,因为它们有一个有限的状态,意味着常数时间推理和线性时间训练。然而,它们的有效性受到这种状态对上下文的压缩程度的限制。为了理解这一原理,我们关注两个正在运行的合成任务示例(图2)。
- 选择性复制任务通过改变要记忆的标记的位置来修改流行的复制任务(Arjovsky, Shah, and Bengio 2016)。它需要内容感知推理,以便能够记住相关的标记(彩色)并过滤掉不相关的标记(白色)。
- 诱导头任务是一个众所周知的机制,假设可以解释大语言模型的大部分上下文学习能力(Olsson et al. 2022)。它需要上下文感知推理来知道何时在适当的上下文中(黑色)产生正确的输出。
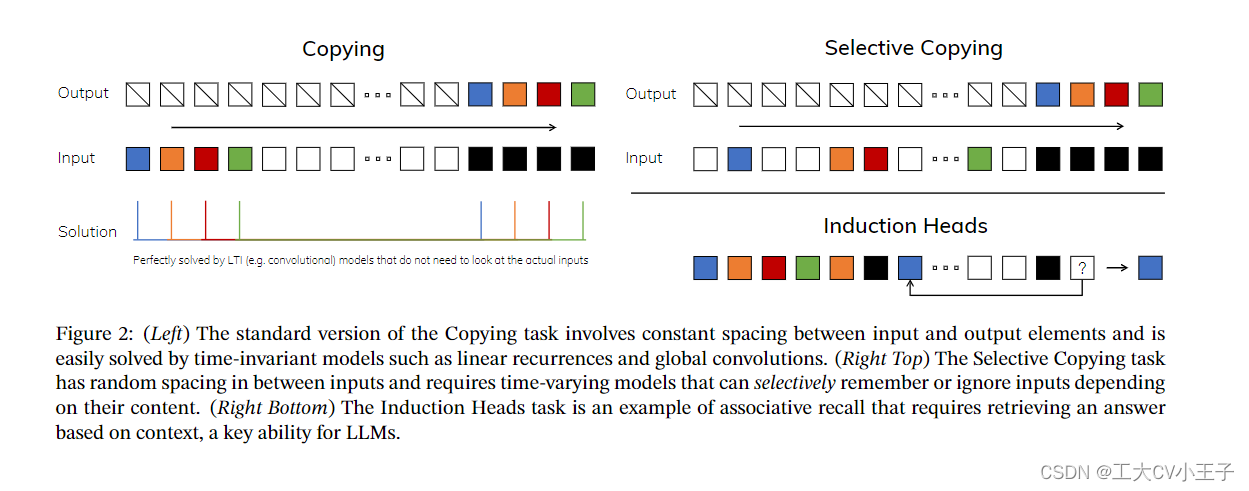
这些任务揭示了 LTI 模型的失效模式。从循环的角度来看,它们的恒定动态(例如(2)中的(A、B)转换)不能让它们从上下文中选择正确的信息,或者以依赖于输入的方式影响沿序列 a 传递的隐藏状态。从卷积的角度来看,众所周知,全局卷积可以解决普通的复制任务(Romero et al. 2021),因为它只需要时间意识,但由于内容意识不足,它们很难选择性复制任务(图2)。更具体地说,输入到输出之间的间距是不同的,不能用静态卷积核来建模。
总之,序列模型的效率和有效性权衡的特点是它们压缩状态的程度:有效的模型必须具有较小的状态(SSM),而有效的模型必须具有包含来自上下文的所有必要信息的状态。(Attention)反过来,我们建议构建序列模型的基本原理是选择性的:或者上下文感知能力专注于或过滤掉输入顺序状态。特别是,选择机制控制信息如何沿序列维度传播或交互(有关更多讨论,请参见第 3.5 节)。
3.2 使用 Selection 改进 SSMs
将选择机制合并到模型中的一种方法是让它们沿序列影响交互的参数(例如 RNN 的循环动态或 CNN 的卷积核)与输入相关。

算法 1 和 2 说明了我们使用的主要选择机制。主要区别在于简单地对输入进行几个参数 Δ、B、C 函数,以及整个张量形状的相关变化。特别是,我们强调这些参数现在具有长度维度L,这意味着模型已经从时间不变更改为时变。(请注意,形状注释在第 2 节中描述)。这失去了与卷积 (3) 的等价性,对其效率有影响,如下所述。

至于这个具体张量怎么对齐的,我看的还不太透彻,等到我跑明白代码再更新,可以先看参考文献
3.3 选择性SSM的高效实现
卷积 (Krizhevsky, Sutskever, and Hinton 2012) 和 Transformers (Vaswani et al. 2017) 等硬件友好架构具有广泛的应用。在这里,我们的目标是在现代硬件 (GPU) 上也使选择性 SSM 高效。选择机制非常自然,早期的工作试图结合选择的特殊情况,例如让 Δ 在循环 SSM 中随时间变化(Gu、Dao 等,2020)。然而,如前所述,SSM 使用的核心限制是它们的计算效率,这就是为什么 S4 和所有导数都使用 LTI(非选择性)模型,最常见的是全局卷积的形式。
3.3.1 先前模型的动机
我们首先重新审视这个动机并概述我们的方法来克服现有方法的局限性。
- 在较高的层次上,SSMs等循环模型总是平衡表达能力和速度之间的权衡:如第3.1节所讨论的,隐藏状态维数较大的模型应该更有效但更慢。因此,我们希望在不支付速度和内存成本的情况下最大化隐藏状态维度。
- 注意,循环模式比卷积模式更灵活,因为后(3)来自扩展前(2)(Gu, Goel和Ré 2022;Gu, Johnson, Goel等人,2021年)。但是,这需要计算和具体化潜在状态 ℎ 的形状 (B, L, D, N),比输入x和输出y的形状(B,L,D)大得多(SSM 状态维度N)因此,引入了更有效的卷积模式,可以绕过状态计算,并使卷积核(3a)仅(B,L,D)具体化。
- 先前的LTI SSM利用双递归卷积形式将有效状态维度增加约(≈10−100)倍,比传统的RNN大得多,没有效率惩罚。
3.3.2选择性扫描概述:硬件感知状态扩展
选择机制旨在克服 LTI 模型的局限性;同时,我们需要重新审视 SSM 的计算问题。我们通过三种经典技术来解决这个问题:内核融合、并行扫描和重新计算。我们有两个主要观察结果:
·朴素递归计算使用표O(BLDN)Flops,而卷积计算使用O(BLDlog(L)Flops,前者具有更低的常量因子。因此,对于长序列和非太大的状态维度,循环模式实际上可以使用更少的FLOPs。
•这两个挑战是递归的顺序性质,以及大量的内存使用。为了解决后者,就像卷积模式一样,我们可以尝试实际上不会使完整状态 ℎ 具体化。
主要思想是利用现代加速器 (GPU) 的属性仅在更有效的内存层次结构级别对状态 ℎ 进行具体化。特别是,大多数操作(矩阵乘法除外)受内存带宽的限制(Dao, Fu, Ermon, et al. 2022;Ivanov等人,2021;Williams, Waterman和Patterson 2009)。这包括我们的扫描操作,我们使用内核融合来减少内存 IO 的数量,与标准实现相比,这导致了显着的加速。
具体来说,我们不是在 GPU HBM(高带宽内存)中的扫描输入 (A拔, B拔)大小为 (B,L,D,N) ,而是将 SSM 参数 (Δ, A, B, C) 直接从慢 HBM 加载到快速 SRAM 中,在 SRAM 中执行离散化和递归,然后将大小为 (B,L,D) 的最终输出写回 HBM。
为了避免顺序递归,我们观察到尽管不是线性的,但它仍然可以与工作高效的并行扫描算法并行化(Blelloch 1990;Martin 和 Cundy 2018;Smith、Warington 和 Linderman 2023)。最后,我们还必须避免保存反向传播所必需的中间状态。我们仔细应用经典的重新计算技术来减少内存需求:当输入从 HBM 加载到 SRAM 时,中间状态不存储,而是在后向传递中重新计算。因此,融合的选择性扫描层具有与带有FlashAttention的优化变压器实现相同的内存需求。融合内核和重新计算的详细信息在附录 D 中。完整的选择性SSM层和算法如图1所示。
3.4 一种简化的SSM结构
与结构化 SSM 一样,选择性 SSM 是独立序列转换,可以灵活地合并到神经网络中。H3 架构是最著名的 SSM 架构的基础(第 2 节),它通常由一个受线性注意力启发的块组成,该块与 MLP(多层感知器)块交错。我们通过将这两个组件组合成一个同质堆叠的组件来简化这种架构(图 3)。这受到门控注意力单元 (GAU) (Hua et al. 2022) 的启发,该单元对注意力做类似的事情。
该架构涉及通过可控的扩展因子 E 扩展模型维度 D。对于每个块,大部分参数 (3ED^2) 在线性投影中(输入投影为 2ED^2,输出投影为ED^2),而内部 SSM 的参数贡献量较小。SSM参数的数量(∆、B、C的投影和矩阵A)的参数量相比于线性投射层来说小的多,我们重复这个块,与标准归一化和残差连接交织在一起,形成 Mamba 架构。在我们的实验中,我们总是固定为 E = 2,并使用两个块堆栈来匹配 Transformer 的交错 MHA(多头注意力)和 MLP 块的 12D^2 参数。我们使用 SiLU / Swish 激活函数(Hendrycks 和 Gimpel 2016;Ramachandran、Zoph 和 Quoc V Le 2017),其动机是门控 MLP 成为流行的“SwigLU”变体(Chowdhery 等人 2023;Shazeer 2020;Touvron 等人 2023)。最后,我们还使用了可选的归一化层(我们选择 LayerNorm (J.L.Ba、Kiros 和 Hinton 2016)),其动机是 RetNet 在相似位置使用的归一化层(Y.Sun 等人。 2023)。

3.5选择机制的性质
选择机制是一个更广泛的概念,可以以不同的方式应用,例如应用于更传统的RNN或CNN,应用于不同的参数(例如算法2中的A),或使用不同的转换𝑠(x)。
3.5.1与门控机制的联系
我们强调了最重要的联系:RNN 的经典门控机制是我们 SSM 选择机制的一个实例。我们注意到 RNN 门控与连续时间系统的离散化之间的联系得到了很好的建立(Funahashi 和 Nakamura 1993; Tallec 和 Ollivier 2018)。事实上,定理 1 是 Gu、Johnson、Goel 等人的改进。 (2021,引理 3.1)推广到 ZOH 离散化和输入相关门(附录 C 中的证明)。更广泛地说,SSM 中的 Δ 可以看作是 RNN 门控机制的广义作用。与之前的工作一致,我们采用 ssm 的离散化是启发式门控机制的原则基础的观点。

3.5.2选择机制的解释
我们详细阐述了选择的两个特殊机制效应。
可变间距。选择性允许过滤掉在感兴趣的输入之间可能出现的不相关的噪声标记。选择性复制任务就是一个例子,但是在常见的数据模式中无处不在,特别是对于离散数据——例如语言填充符(如“um”)的存在。这个特性的出现是因为模型可以机械地过滤掉任何特定的输入≥𝑡,例如在门通RNN的情况下(定理1)𝑔𝑡→0。
过滤背景。根据经验观察,许多序列模型在更长的上下文下并没有得到改善(F. Shi et al. 2023),尽管有更多上下文应该导致严格更好的性能的原则。一种解释是,许多序列模型在必要时不能有效地忽略无关的上下文;一个直观的例子是全局卷积(和一般LTI模型)。另一方面,选择性模型可以在任何时候简单地重置它们的状态以删除无关的历史,因此它们的性能原则上随着上下文长度单调地提高(例如第4.3.2节)。
边界重置。在多个独立序列拼接在一起的情况下,变形金刚可以通过实例化一个特定的注意掩码来保持它们的分离,而LTI模型将在序列之间传递信息。选择性ssm还可以在边界处重置其状态(例如,𝑔𝑡→1时∆𝑡→∞或定理1)。这些设置可以人为地发生(例如,将文档打包在一起以提高硬件利用率)或自然地发生(例如,强化学习中的情节边界(Lu et al. 2023))。此外,我们详细说明了每个选择参数的影响。
∆的解释。一般来说,∆控制着关注或忽略当前输入的程度(𝑡)之间的平衡。它概括了RNN门(例如定理1中的𝑔𝑡),机械地,一个大的∆重置状态<e:1>并专注于当前的输入,而一个小的∆保持状态并忽略当前的输入。ssm(1)-(2)可以被解释为一个被时间步长∆离散的连续系统,在这种情况下,直观的感觉是大∆→∞代表系统更长时间地关注当前输入(因此“选择”它并忘记它的当前状态),而小∆→0代表被忽略的瞬态输入。
A的解释。我们注意到,虽然 A 参数也可能是选择性的,但它最终仅通过与 Δ 通过 A = exp(ΔA) 的交互来影响模型(离散化 (4))。因此,Δ 中的选择性足以确保 (A, B) 中的选择性,并且是改进的主要来源。我们假设除了(或而不是)Δ 之外,使 A 选择具有相似的性能,为简单起见将其排除。
B 和 C 的解释。如第 3.1 节所述,选择性最重要的特性是过滤掉不相关的信息,以便序列模型的上下文可以压缩成有效的状态。在 SSM 中,将 B 和 C 修改为对选择性允许对是否让输入 xt 进入状态 ℎt 或状态放入输出 yt 进行更细粒度的控制。这些可以解释为允许模型分别基于内容(输入)和上下文(隐藏状态)来调节循环动态。
3.6额外的模型细节
实数与复数。大多数先前的 SSM 在状态 ℎ 中使用复数,这对于许多任务的强大性能是必要的(Gu、Goel 和 Ré 2022)。然而,根据经验观察到,在某些情况下,完全实值 SSM 似乎效果很好,甚至可能更好(Ma et al. 2023)。我们使用实值作为默认值,它适用于除一项任务之外的所有任务;我们假设复杂的真实权衡与数据模态中的连续离散谱有关,其中复数有助于连续模态(例如音频、视频)而不是离散(例如文本、DNA)。
初始化。大多数先前的 SSM 也提出了特殊的初始化,特别是在复值情况下,这有助于几种设置,例如低数据机制。我们对复杂情况的默认初始化是 S4D-Lin,对于实际情况是 S4D-Real (Gu, Gupta, et al. 2022),它基于 HIPPO 理论 (Gu, Dao, et al. 2020)。这些将 A 的第 ¢ 个元素分别定义为 -1∕2 + 푥 和 -(¢ + 1)。然而,我们预计许多初始化效果很好,尤其是在大数据和实值 SSM 机制中;第 4.6 节考虑了一些消融。
参数化∆。我们定义了选择性调整∆𝑠∆(𝑥)=𝖡𝗋𝗈𝖺𝖽𝖼𝖺𝗌𝗍𝐷(𝖫𝗂𝗇𝖾𝖺𝗋1(𝑥)),这是出于∆的机制(3.5节)。我们观察到它可以从1维推广到更大的维度𝚁。我们将其设置为𝙳的一小部分,与块中的主要线性投影相比,它使用的参数数量可以忽略不计。我们还注意到,广播操作可以被视为另一个线性投影,初始化为1和0的特定模式;如果这个投影是可训练的,这就会得到另一种选择𝑠∆(显性显性)=𝖫𝗂𝗇𝖾𝖺𝗋𝐷(显性显性𝖫𝗂𝗇𝖾𝖺𝗋𝑅(显性显性)),它可以被看作是一个低秩投影。在我们的实验中,根据之前对ssm的研究(Gu, Johnson, Timalsina, et al. 2023),将∆参数(可视为偏差项)初始化为1∆(𝖴𝗇𝗂𝗋𝗆([0.001,0.1])。
备注 3.1。为简洁起见,我们有时会将选择性 SSM 缩写为 S6 模型,因为它们是具有选择机制的 S4 模型,并使用扫描计算。
4 实证评估
略
参考文献
一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba_mamba模型-CSDN博客
SSM(Mamba)学习笔记 - 知乎 (zhihu.com)








![[幻灯片]软件需求设计方法学全程实例剖析-03-业务用例图和业务序列图](https://img-blog.csdnimg.cn/img_convert/aeeeab97c3506b11e47cc8761e13d480.jpeg)