什么是RAG?
检索增强生成(Retrieval-Augmented Generation,RAG),是指为大模型提供外部知识源的概念。能够让大模型生成准确且符合上下文的答案,同时能够减少模型幻觉。
用最通俗的语言描述:在已有大模型的基础上,外挂一个知识库,让大模型学习这个知识库后,回答的内容与知识库更为相关,与实际业务场景更加贴切,符合我们的需求。
为什么要用RAG?
- 模型知识局限性:现有主流大模型的训练集基本都是基于网络公开的数据,如ChatGPT最新数据截止至2021年。因此,对于一些实时性的、非公开的或离线的最新数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:AI模型的底层原理都是基于概率预测,其模型输出实质上是一系列概率运算,它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
-
数据安全性:对于企业、机关单位等部门来说,数据安全至关重要,没有人愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
上述问题的存在,可以用RAG技术解决。大体结构如图所示。
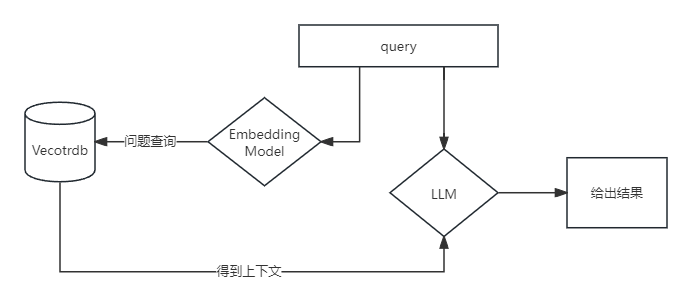
RAG结构大致流程
完整的RAG应用流程主要包含两个阶段:
-
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
-
应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
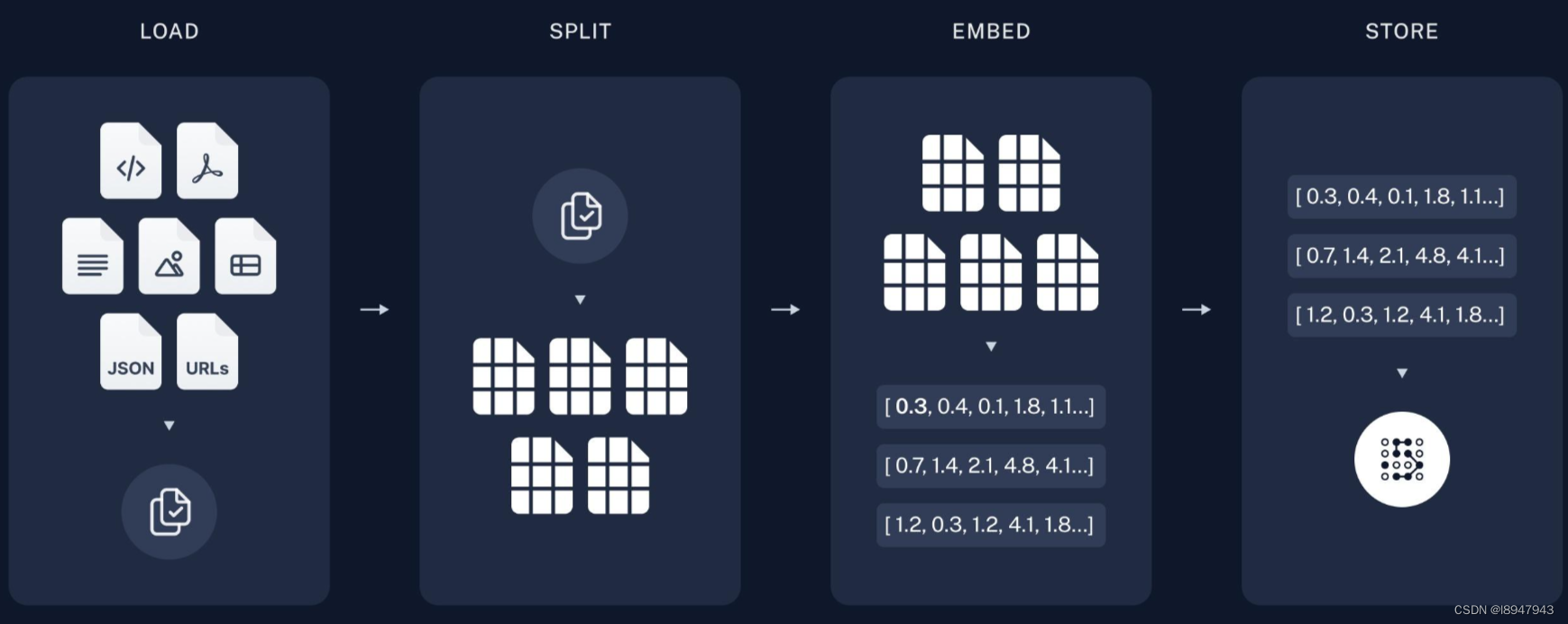
数据准备阶段:
数据提取:
-
数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
-
数据处理:包括数据过滤、压缩、格式化等。
-
元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
文本分割:
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
-
句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
-
固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding):
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
数据入库:
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。一般现有API多以Chromadb为主。
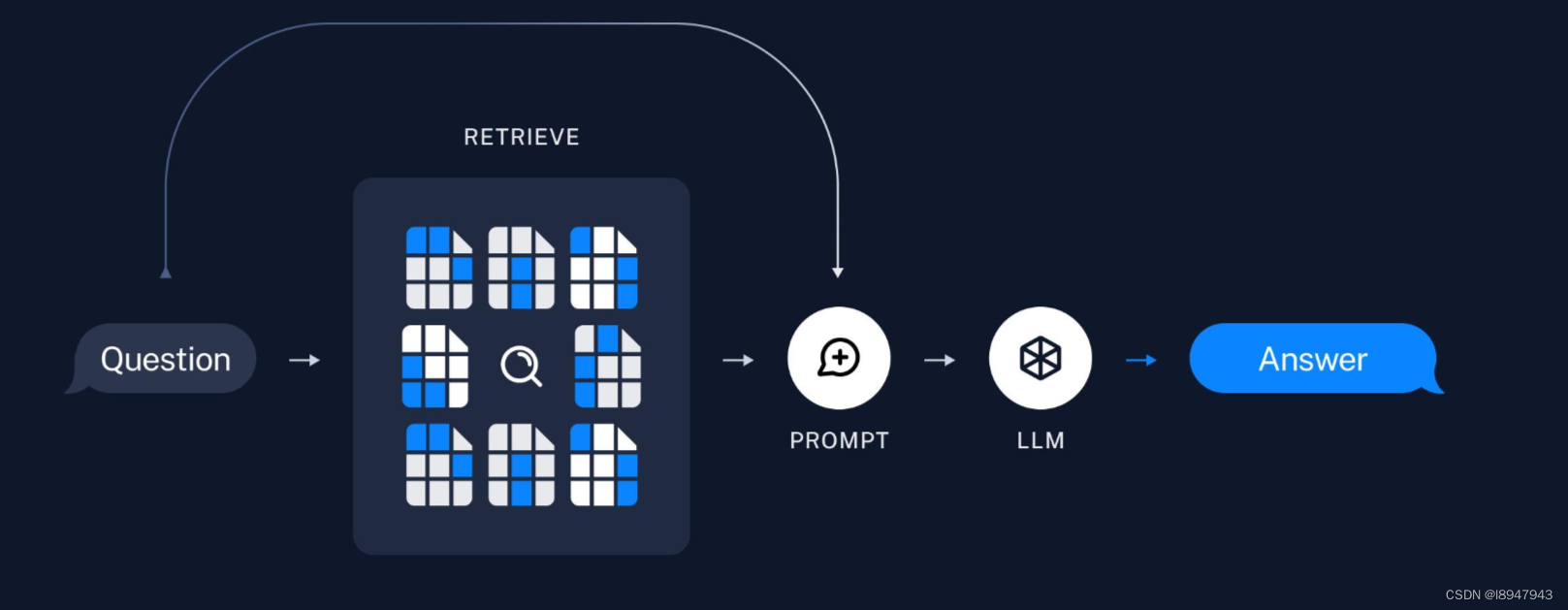
总结如图:
应用阶段
关键环节包括:数据检索、注入Prompt等。
数据检索
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
Prompt注入
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。
参考:
- 一文搞懂大模型RAG应用(附实践案例)
- 一文带你了解大模型的RAG(检索增强生成)



![[Windows]服务注册工具(nssm)](https://img-blog.csdnimg.cn/img_convert/4f07740f4f8970ca1e407fc08683e5d7.png)

![[Android]模拟器登录Google Play失败](https://img-blog.csdnimg.cn/direct/d0ca9bc9e9f44dccbccbd31f9d2bd17e.png)