论文笔记✍MonoLSS: Learnable Sample Selection For Monocular 3D Detection
📜 Abstract
🔨 主流做法+限制 :
以前的工作以启发式的方式使用特征来学习 3D 属性,没有考虑到不适当的特征可能会产生不利影响。
🔨 本文做法:
本文引入了样本选择,即只训练合适的样本来回归 3D 属性。
-
为了自适应地选择样本,我们提出了可学习样本选择(LSS)模块,该模块基于 Gumbel-Softmax 和相对距离样本划分器。 LSS 模块在预热策略下工作,从而提高训练稳定性。
-
此外,由于专用于3D属性样本选择的LSS模块依赖于对象级特征,因此我们进一步开发了一种名为MixUp3D的数据增强方法来丰富3D属性样本,该方法符合成像原理而不引入歧义。
-
作为两种正交方法,LSS 模块和 MixUp3D 可以独立使用,也可以结合使用。足够的实验表明,它们的组合使用可以产生协同效应,产生的改进超越了它们单独应用的简单总和。
🔨 结果 :
利用 LSS 模块和 MixUp3D,在没有任何额外数据的情况下,我们名为 MonoLSS 的方法在 KITTI 3D 对象检测基准测试的所有三个类别(汽车、骑行者和行人)中排名第一,并且在 Waymo 数据集和 KITTI 上都取得了有竞争力的结果 - nuScenes 跨数据集评估。该代码包含在补充材料中,并将发布以促进相关学术和工业研究。
🔨问题前置 :
问题: 看完摘要有以下几点问题,带着这些问题看论文。
- 作者说不适当的特征指的是什么?
解答:遮挡问题导致b物体特征点在A物体上面。导致预测B物体的特征不合适。
- 针对作者的motivation,作者是如何解决问题的?为什么提出的方案是有效地?
解答:从问题出发,选择合适的特征。进而引入了怎么选择合适的特征,采样+数据增强。
-
根据什么条件来制定可学习样本挑选策略?
-
如何进行数据增强mixup3D?怎么代码实现的?
-
如何联合使用保证效果最优?
✨ 一、Introduction
🔨 1.1 Motivation :
- 为了实现准确的 3D 属性估计,许多方法将 3D 属性预测分支添加到 2D 检测器中 [43, 61]。利用特征进行3D属性输出。
设计动机来自于2D检测的标签分配。人们很少需要IOU小于0.3的anchor作为目标检测的正样本(在anchor free方法中,这意味着远离目标中心)。使用不当可能会导致歧义,甚至产生不利影响。我们将这些知识转移到 3D 属性学习中。
SMOKE [32]仅使用位于对象3D中心的尺寸为1 * 1 * C的一个固定位置特征来回归3D属性。
当发生遮挡时,该特征可能位于另一个对象上。尽管感受野不限于特征的位置,但网络可能无法接收最佳信息作为输入。
由于受到前景和背景干扰等无用信息的影响,这种方法仍然存在问题
2. 在这项工作中,我们引入样本选择来识别有利于学习 3D 属性的特征并将其作为正样本,而忽略其余特征并将其视为负样本。 挑战在于如何划分它们。一种直观的方法是关注目标对象本身的特征(图1(c)),但这些方法需要引入额外的数据,例如深度图[40]或分割标签,并且仍然无法在不同的样本中选择合适的样本。物体的内部组件,例如轮子、灯光或身体。
-
为了解决 3D 属性样本选择问题,我们提出了一种新颖的可学习样本选择(LSS)模块。 LSS 模块使用 Gumbel-Softmax [13] 实现概率采样。
-
此外,采用top-k GumbelSoftmax [22]来实现多样本采样,将抽取的样本数量从1扩展到k。
-
此外,为了取代所有对象使用相同的k值,我们开发了一种基于相对距离的无超参数样本划分器,实现了每个对象采样值的自适应确定。
-
此外,受 HTL 方法 [34] 的启发,LSS 模块采用预热策略来稳定训练过程。
采样->每个物体自适应采样->HTL方法稳定训练过程
3. 此外,专用于 3D 属性样本选择的 LSS 模块依赖于对象级特征。然而,训练数据中的对象数量总是有限的。同时,大多数3D单目数据增强方法,例如随机裁剪扩展、随机翻转、复制粘贴等,都不会改变物体本身的特征。其中一些甚至由于违反成像原理而引入模糊的特征。
所以呢,为了提高3D属性样本的丰富度,我们提出MixUp3D,它在传统2D MixUp [57]的基础上添加物理约束来模拟物理世界中的空间重叠。空间重叠不会改变对象的 3D 属性,例如汽车重叠自行车,但我们仍然可以判断它们的深度、尺寸和方向。
-
作为空间重叠的模拟,MixUp3D 使物体能够符合成像原理,而不会引入模糊性。
-
可以丰富训练样本,缓解过拟合。此外,MixUp3D 可以用作任何单目 3D 检测方法中的基本数据增强方法。
🔨 1.2 本文方法+贡献 :
总而言之,这项工作的主要贡献如下:
• 我们强调并非所有特征对于学习 3D 属性都同样有效,并首先将其重新表述为样本选择问题。相应地,开发了一种新颖的可学习样本选择(LSS)模块,可以自适应地选择样本。
• 为了丰富3D 属性样本,我们设计了MixUp3D 数据增强,它可以模拟空间重叠并显着提高3D 检测性能。
- SOTA
通过阅读Introduction,作者首先从3D属性预测特征问题出发,认为特征没选好;其次,提出了解决方案,第一,自适应的选择样本,进行特征提取,更加适应于属性预测;第二,数据增强来丰富样本。最后,大量实验验证设计思路的有效性。
🔁 二、Related Work
🔨 2.1 常见做法:
1 Monocular 3D Object Detection
根据是否使用额外数据,单目 3D 目标检测算法可主要分为两类。
-
第一种方法仅使用单个图像作为输入,没有任何额外信息
-
第二种方法使用额外的数据,例如深度图、LIDAR点云和CAD模型,来获取附加信息并增强检测。
由于信息的增加,利用额外数据的方法总是表现出卓越的性能。然而,复杂的传感器配置和计算开销限制了它们在工业中的实际应用。
2 Sample Selection in 2D/3D Detection.
3 Data Augmentation in Monocular 3D Detection.
由于违反几何约束,随机水平翻转 [5, 28, 63] 和光度畸变 [3, 50] 是单目 3D 检测中唯一最常使用的两种数据增强方法。
一些方法[40](DID-M3D) 使用随机裁剪和扩展来模拟深度的比例变化。然而,根据成像原理,一幅图像上的所有深度具有相同的比例变化是不切实际的。
一些方法 [29, 53] 使用额外的深度图来模拟相机沿 z 轴的前后移动。
然而,由于视差和深度图误差,该方法引入了大量噪声和扭曲的外观特征。
实例级复制粘贴[29]也被用作3D数据增强方法,但受限于复杂的手动处理逻辑,仍然不够现实。 [Exploring Geometric Consistency for Monocular 3D Object Detection]
💻 三、Approach
🔨 3.1 FrameWork:
单目 3D 对象检测从单个 RGB 图像中提取特征,估计图像中每个对象的类别和 3D 边界框。 3D 边界框可以进一步分为 3D 中心位置(x、y、z)、尺寸(h、w、l)和方向(偏航角)θ。物体的横滚角和俯仰角设置为 0。
在这项工作中,我们提出了一种新颖的可学习样本选择(LSS)模块来优化单目 3D 对象检测过程。 MonoLS的整体架构如图2所示,主要包括2D检测器、ROI-Align、3D检测头和LSS模块。
2D检测

与仅根据对象特征预测单个 3D 边界框的其他方法不同,我们的方法使用对象特征中的每个样本点来预测 3D 边界框和对数概率。(每个对象会经过采样,每个采样点都用来预测)
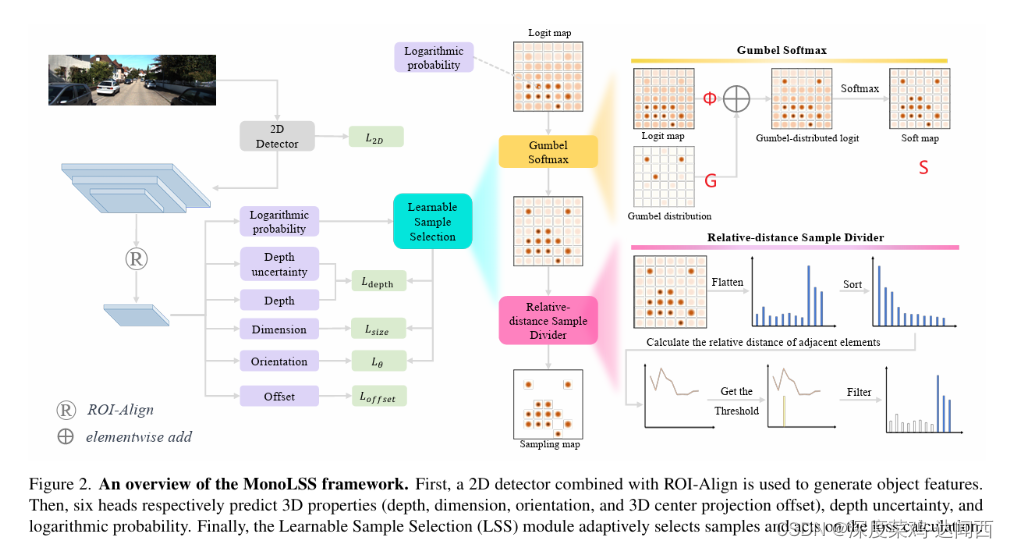
此外,我们遵循多仓设计来预测方向并预测深度的不确定性,这与 GUPNet [34] 相同。

基于网络预测的logit图,LSS模块可以在训练时自适应地选择3D属性的正样本。
在推理过程中,LSS模块根据logit图中的最高对数概率选择最佳3D属性。
Learnable Sample Selection (LSS)
假设U ∼ U niform(0, 1),那么我们可以使用逆变换采样,通过计算 G = −log(−log(U )) 来生成 Gumbel 分布 G。通过用 Gumbel 分布独立扰动对数概率并使用 argmax 函数找到最大元素,Gumbel-Max 技巧 [10] 实现了无需随机选择的概率采样。基于这项工作,Gumbel-Softmax [13]使用softmax函数作为argmax的连续、可微的近似,并借助重新参数化实现整体可微性。 GumbelTop-k [22]通过无放回地绘制大小为 k 的有序采样,将样本点的数量从 Top-1 扩展到 Top-k,其中 k 是超参数。
-
然而,相同的 k 并不适合所有对象,例如,被遮挡的对象应该比正常对象具有更少的正样本。
-
为此,我们设计了一个基于无超参数相对距离的模块来自适应地划分样本。
-
总之,我们提出了一个可学习样本选择(LSS)模块来解决 3D 属性学习中的样本选择问题,该模块由 Gumbel-Softmax 和相对距离样本划分器组成。
通过U–>G = −log(−log(U ))–>ˆ Φ = (G + Φ) -->softmax -->S
depth uncertainty U logit map Φ
Gumbel distribution G
Gumbel-distributed logit ˆ Φ
soft map S

之后,采用相对距离样本分配器代替Gumbel-Top-k中的固定k,实现自适应样本分配。我们使用软映射的元素之间的最大间隔来区分正样本和负样本。一般用绝对距离(Abs dis = |a − b|)来表示间隔。但由于softmax函数的放大效应,使用绝对距离来划分样本可能会导致正样本数量不足。我们利用相对距离(Rel dis = a b )来增加正样本的数量。例如,如果softmax函数的输入向量为[20, 18, 17, 7],则输出将为[0.84, 0.12, 0.04, 0],使用绝对距离将仅分配一个正样本,而相对距离将分配三
首先,我们将软映射S展平为一维向量Sof t S,并对其进行排序,得到排序向量Sort S。其次,我们通过以下公式计算向量Sort S的相邻元素之间的相对距离:
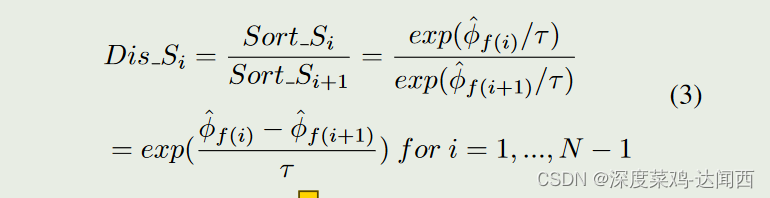
其中,f()表示Sort S到Sof t S的映射关系。假设Dis Si为Dis S中的最大值,由于指数函数是单调递增函数,因此 ˆ φf(i) − ˆ φf(i+ 1) 是 ˆ Φ 中的最大间隔。本质上,我们正在寻找 Gumbel 分布 logit 中最具辨别力的值来区分正样本和负样本。我们选择Dis Si对应的Sort Si作为阈值来过滤负样本。具体地,将软映射S中小于Sort Si的值设置为0,得到最终的采样映射Sample S。
2. Loss Function and Training Strategy
整体损失L由2D损失L2d和3D损失L3d组成,其中2D损失L2d遵循CenterNet[61]中的设计,3D损失L3d采用基于LSS模块的多任务损失函数来监督3D损失的学习特性.

在计算出每个属性的损失后,我们将深度、方向和维度属性的损失图乘以LSS的最终采样图Sample S,以防止负样本的损失反向传播。
采用 HTL [34] 训练策略来减少不稳定性(出自 GUPNet)。此外,由于3D属性损失的不稳定性会干扰正样本点的选择,因此我们在训练LSS模块时使用预热策略。具体来说,在训练的早期阶段,所有样本都将用于学习3D属性,直到深度损失稳定。我们认为深度损失稳定是启动 LSS 模块的必要条件,因为深度是影响 3D 边界框精度的最重要属性 [29, 36]。
3. MixUp3D for Spatial Overlap Simulation
由于LSS模块专注于对象级特征,因此不修改对象本身特征的方法对于LSS模块来说预计不会足够有效.
由于 MixUp [57, 58] 的优点,可以增强对象的像素级特征。**我们提出了 MixUp3D,它为 2D MixUp 添加了物理约束,**使得新生成的图像本质上是空间重叠的合理成像。具体来说,MixUp3D 仅违反物理世界中物体的碰撞约束,同时确保生成的图像遵循成像原理,从而避免任何歧义。
🔤在本文中,我们对 MixUp 图像施加严格的约束,以确保它们具有相同的焦距、主点、分辨率和相机视图(俯仰角和滚动角)。🔤🔤一般来说,焦距相同的图像总是意味着**它们的主点和分辨率也相同**🔤🔤因此,MixUp3D只需要考虑保证图像焦距相同即可。🔤

其中 n, m ∈ [1, N ] 且 n ̸= m。 λ表示混合比例。
所提出的MixUp3D可以在不引入歧义的情况下丰富训练样本,并有效缓解过拟合问题。作为一种重要的数据增强方法,它可以方便地应用于任何单目 3D 检测任务。
mixup3D:遵循mixup2D,先找出相同的焦距的图片进行分组,然后组内进行mixup。保证了成像原理。
💻 四、Experiments
🔨 4.1 Implementation details:
Waymo 根据 3D 框中存在的 LiDAR 点的数量,在两个级别评估对象:级别 1 和级别 2。评估在三个距离进行:[0, 30)、[30, 50) 和 [50, ∞) 米。 Waymo 利用 AP H3D 百分比指标(其中包含 AP3D 中的航向信息)作为评估基准。
nuScenes 包含从前置摄像头捕获的 28,130 个训练图像和 6,019 个验证图像。我们使用验证分割进行跨数据集评估。
Implementation details.。我们提出的 MonoLSS 在 4 个 Tesla V100 GPU 上进行训练,批量大小为 16。在没有 MixUp3D 的情况下,我们将模型训练 150 个周期,之后发生过拟合。使用 MixUp3D 时,模型可以训练 600 个 epoch,而不会出现过拟合。我们使用 Adam [19] 作为优化器,初始学习率为 1e − 3。学习调度器在前 5 个时期具有线性预热策略。按照[40],ROI-Align 大小 d × d 设置为 7 × 7。LSS 在 0.3 × 总历次(实验参数)后开始进行预热。
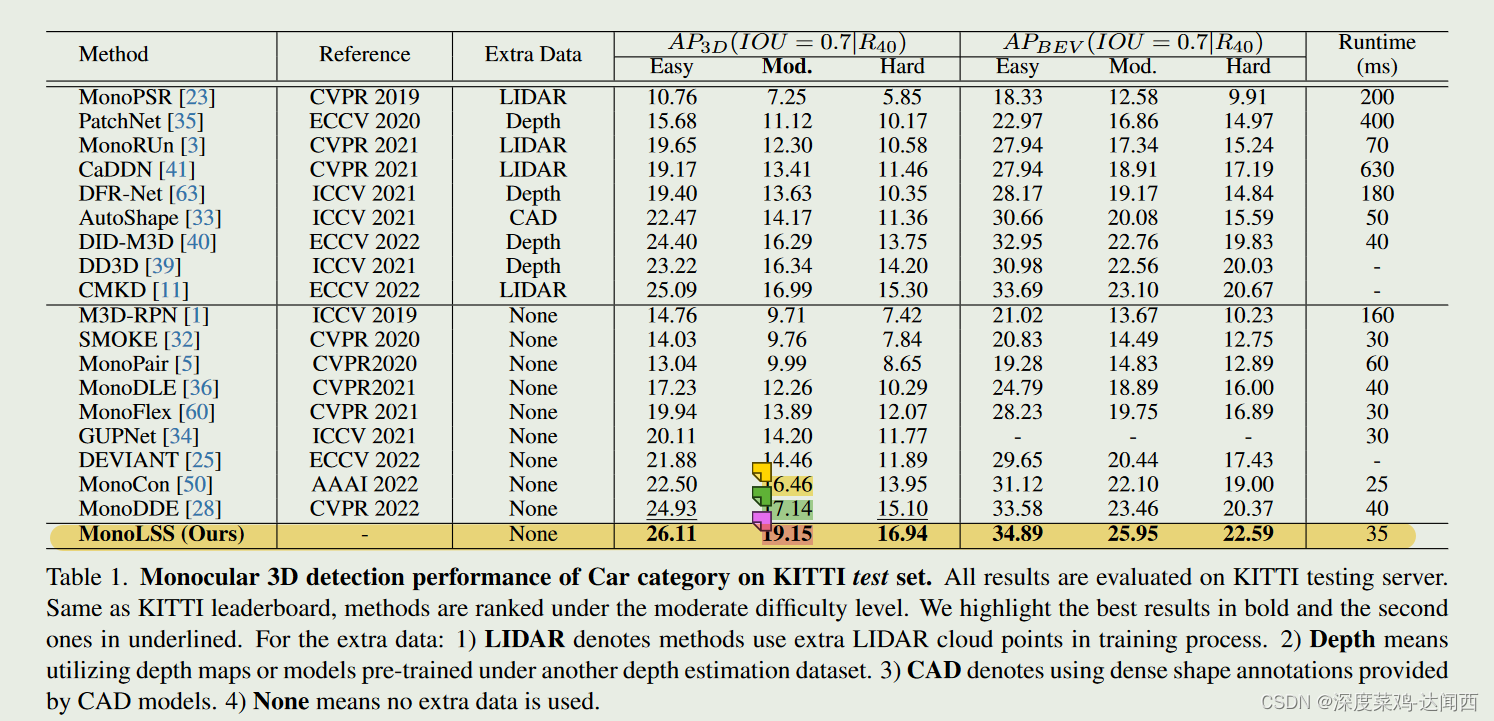
🔨 4.2 Results quantitative(定量)
🔨 4.3 Ablation Study:
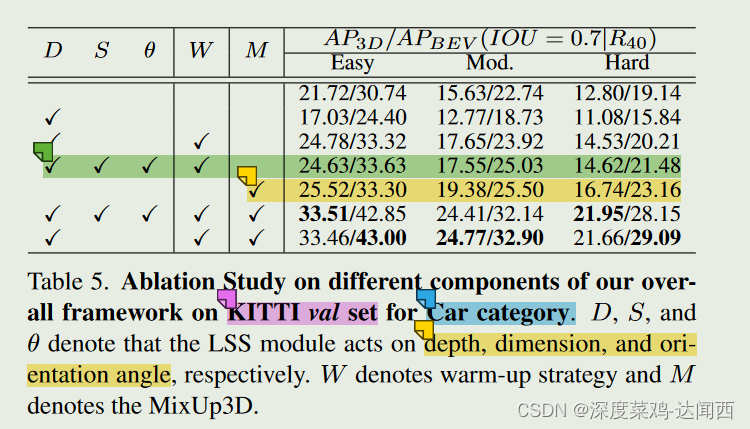
LSS 模块的有效性:
如表 5 前 4 行所示,LSS 模块可以显着改善 AP。**而作用于方向和尺寸属性时,改进相对较小。这是因为深度估计误差是单目 3D 检测中最关键的限制因素,**这一点已在 GeoAug [29] 和 MonoDLE [36] 中得到证实。因此,为了便于比较,在下面的消融实验中,LSS模块仅作用于深度属性。
Warm-up的必要性:
表 5 前 3 行的结果显示了预热策略的重要性。如果没有预热(第2行),LSS将在训练开始时开始随机采样,导致真正的负样本可能被迫学习属性,而真正的正样本则被丢弃,这会显着降低性能(简单级别为 21.72 至 17.03)。
由于3D属性损失的不稳定性会干扰正样本点的选择,因此我们在训练LSS模块时使用预热策略。具体来说,在训练的早期阶段,所有样本都将用于学习3D属性,直到深度损失稳定。(前边介绍的)
LSS 和 MixUp3D 之间的协同效应。
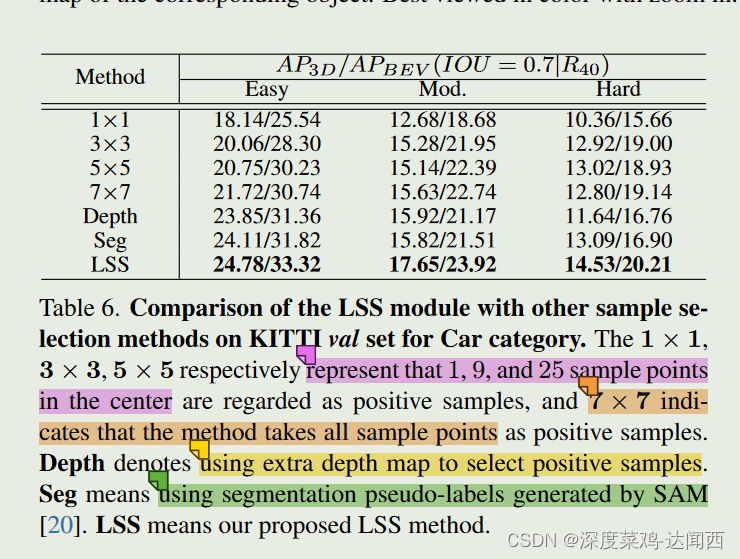
样本选择策略的比较:
我们将LSS模块与其他样本分配策略进行对比,结果如表6所示。LSS模块根据对象特征自适应地选择正样本,使得AP相对于将固定位置样本点视为正样本的方法有显着改进那些。此外,我们的方法还优于使用额外的深度或分割图来选择正样本的方法。
🔨 4.4 实验-好词好句:
“Specifically, compared with MonoDDE [28] which is the recent top1-ranked image-only method, MonoLSS gains significant improvement of 4.73%/11.73%/12.19% in AP3D and 3.90%/10.61%/10.90% in APBEV relatively on the easy, moderate, and hard levels while IOU = 0.7.
问题解答
根据 3.1节,进行样本点选择;
对原始数据集进行分组。随机整合;
预热训练的方式,保证两者发挥最大的效果。