手把手教你从零开始实现一个基于Pytorch的卷积神经网络CNN(新手适用)一: model.py:创建模块-CSDN博客
从零开始实现一个基于Pytorch的卷积神经网络 - 知乎
目录
1 设备device定义
2 训练模型定义
3 开始训练
3.1 step、batchsize和数据集中图片数的关系
3.2 关于类型转换
4 保存模型
5 训练过程可视化
5.1 损失
5.1.1 损失的计算
5.1.2 平均损失的计算
5.2 准确率
5.2.1 准确率计算
5.2.2 平均准确率计算
6. train.py完整代码
7. 训练结果
1 设备device定义
通过torch.device()来指定使用的设备device,然后通过.to()方法将模型和数据放到指定的设备上,这样我们就可以通过定义device来指定是在cpu还是显卡上进行训练了,而且在多显卡的情况下也可以指定使用其中的某一张显卡进行训练。
torch.cuda.is_available()可以判断本设备是否支持CUDA,如果支持就返回True,不支持就返回False。这个函数可以让其自动判断是否支持CUDA加速并自动选择设备。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)2 训练模型定义
- 初始化和导入模型
- 定义超参数、数据集和DataLoader
- 定义损失函数loss function和优化器optimizer
- 启用梯度:torch.set_grad_enabled(True)
代码如下,其中的具体解释可看知乎原文。
# 训练数据
import torch
import torchvision
import torch.nn as nn
import torch.utils.data as Data# 1. 导入模型文件并且定义
from model import LeNet
model = LeNet()
# 2. 定义参数:轮数,批次和学习率
Epoch = 5
batch_size = 64
lr = 0.001
# 3. 获取训练数据
train_data = torchvision.datasets.MNIST(root='./data',train=True,transform=torchvision.transforms.ToTensor(),download=False)
#定义train data的数据集
train_loader = Data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=True)
# 4. 定义损失函数、优化器
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 5. 梯度计算
torch.set_grad_enabled(True)
#启用Batch Normalization层和Dropout层
model.train()
model.train()方法:该方法用于启用Batch Normalization层和Dropout层。虽然模型中并没有这两层,但是我们不妨将其加上,并作为一个习惯,以免在真正需要时忘记。
3 开始训练
1) 获得DataLoader中的数据x和标签y
2) 将优化器的梯度清零
3) 将数据送入模型中获得预测的结果y_pred
4) 将标签和预测结果送入损失函数获得损失
5) 将损失值反向传播
6) 使用优化器对模型的参数进行更新
# 训练
for epoch in range(Epoch):for step,data in enumerate(train_data):# 取出data中的数据和标签x,y=data# 优化器梯度清零optimizer.zero_grad()# 计算预测值y_pred = model(x.to(device,torch.float))# 计算损失loss = loss_function(y_pred, y.to(device, torch.long))# 梯度更新loss.backward()# 优化器更新模型参数optimizer.step()3.1 step、batchsize和数据集中图片数的关系
一个 epoch 表示将训练数据集中的所有样本都用于训练一次。步数(steps)表示在一个 epoch 中所执行的批次数量。
- step的计算方法:将总样本数除以批次大小。
我们在前面定义的batchsize是64且丢弃最后一批,手写数字数据集中有6万张图片,60000/64=937.5,故每个epoch中有step=937。
3.2 关于类型转换
# 计算预测值y_pred = model(x.to(device,torch.float))# 计算损失loss = loss_function(y_pred, y.to(device, torch.long))两行中都涉及到了类型转换。在深度学习中,通常希望输入数据和模型参数的数据类型是一致的,这样可以避免类型不匹配的错误,并且可以更有效地利用硬件加速器(如 GPU)进行计算。
- 第一行把y_pred输入数据转换为
torch.float类型的目的是确保模型接收到的数据类型与模型参数的数据类型匹配。在很多情况下,神经网络模型的参数通常是浮点数类型(float),因此将输入数据转换为torch.float类型可以确保与模型参数的类型匹配。 -
在深度学习中,通常使用整数类型(如
torch.long)来表示类别标签或离散值。许多损失函数(例如交叉熵损失函数)在计算损失时需要模型输出的预测值和真实标签值具有相同的数据类型。
4 保存模型
把模型的定义和参数全保存在一个文件中,后面可以直接使用训练好的权重文件。
torch.save(model, './LeNet.pkl')5 训练过程可视化
- 查看训练过程中的损失和准确率等等过程参数。
可以在每隔一定的step后输出当前损失和准确率的平均值。MNIST的训练集共有六万张图像,而我们的batch_size是64且丢弃最后一批,因此在每个Epoch中有937个step,实际训练59968张图像。可以每迭代100次后输出当前Epoch的损失和准确率的平均值,并输出当前处在哪一次Epoch和step。
5.1 损失
5.1.1 损失的计算
对每次计算产生的损失进行相加,把结果放在running_loss中,因此,我们需要在反向传播后添加一个累加操作。由于loss在我们之前定义的设备上,因此我们需要获得loss的值,然后将其传回cpu并转换为float类型,即:
# 计算损失loss = loss_function(y_pred, y.to(device, torch.long))# 梯度更新loss.backward()# 累加梯度running_loss += float(loss.data.cpu())5.1.2 平均损失的计算
如果当前step是100次,则计算一次平均损失。由于step从0开始,所以需要+1.
loss_avg = running_loss / (step + 1)5.2 准确率
5.2.1 准确率计算
acc = 预测正确的数目 / 总数目
y_pred是一个二维的张量,其形状为[batch_size, num_classes],在这边channel是10,即十个数字。如果我们将batch中的任意一行提取出来就获得了一个10维的向量,向量里的每个数代表与其下标所对应的标签的相关性,相关性越大则代表越有可能是这个数字。
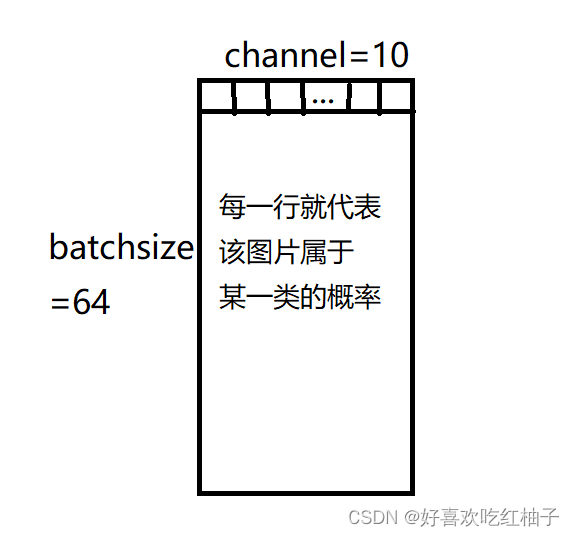
因此,我们需要获得这个向量中最大数的下标,在pytorch中,我们可以用.argmax(dim)方法实现,输入维度dim,即可返回这个维度下最大值的下标,即pred = y_pred.argmax(dim=1)。在此基础上,我们就可以计算其预测正确的数量了;
先获取pred的值,即模型预测的图片的类别,然后传回cpu,用==筛选模型预测的标签和图片标注的标签相等的个数,然后使用.sum()相加统计预测正确的个数。
acc保存的即是模型预测正确的个数。
acc += (pred.data.cpu()==y.data).sum()5.2.2 平均准确率计算
接下来先对steps进行统计,设置每轮数中的每100个steps计算一次平均损失、准确率等。
平均损失值 = 损失值 / steps
平均准确率 = 预测正确的个数 / 总个数
# 判断该step是不是该epoch中的第100步if step%100==99:# 平均损失 = 损失值/stepsloss_avg = running_loss / (step+1)# 平均准确率 = 预测正确的数量/总个数acc_avg = float(acc / ((step + 1) * batch_size))# 输出print('Epoch', epoch + 1, ',step', step + 1, '| Loss_avg: %.4f' % loss_avg, '|Acc_avg:%.4f' % acc_avg)6. train.py完整代码
# 训练数据
import torch
import torchvision
import torch.nn as nn
import torch.utils.data as Data
# 导入模型文件并且定义
from model import LeNetmodel = LeNet()
# 定义参数:轮数,批次和学习率
Epoch = 5
batch_size = 64
lr = 0.001# 获取训练数据
train_data = torchvision.datasets.MNIST(root='./data',train=True,transform=torchvision.transforms.ToTensor(),download=False)
#定义train data的数据集
train_loader = Data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=True)
# 定义损失函数、优化器
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
#梯度计算
torch.set_grad_enabled(True)
#启用Batch Normalization层和Dropout层
model.train()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)# 训练
for epoch in range(Epoch):# 定义损失值和准确率running_loss = 0.0acc = 0.0for step,data in enumerate(train_loader):# 取出data中的数据和标签,x为数据y为标签x,y=data# 优化器梯度清零optimizer.zero_grad()# 计算预测值y_pred = model(x.to(device,torch.float))# 计算损失loss = loss_function(y_pred, y.to(device, torch.long))# 梯度更新loss.backward()# 累加梯度running_loss += float(loss.data.cpu())# 取出预测的最大值pred = y_pred.argmax(dim=1)# 统计预测正确的个数acc += (pred.data.cpu()==y.data).sum()# 优化器更新模型参数optimizer.step()# 判断该step是不是该epoch中的第100步if step%100==99:# 平均损失 = 损失值/stepsloss_avg = running_loss / (step+1)# 平均准确率 = 预测正确的数量/总个数acc_avg = float(acc / ((step + 1) * batch_size))# 输出print('Epoch', epoch + 1, ',step', step + 1, '| Loss_avg: %.4f' % loss_avg, '|Acc_avg:%.4f' % acc_avg)# 保存模型
torch.save(model, './LeNet.pkl')7. 训练结果
可以看到loss呈下降趋势,acc提升。