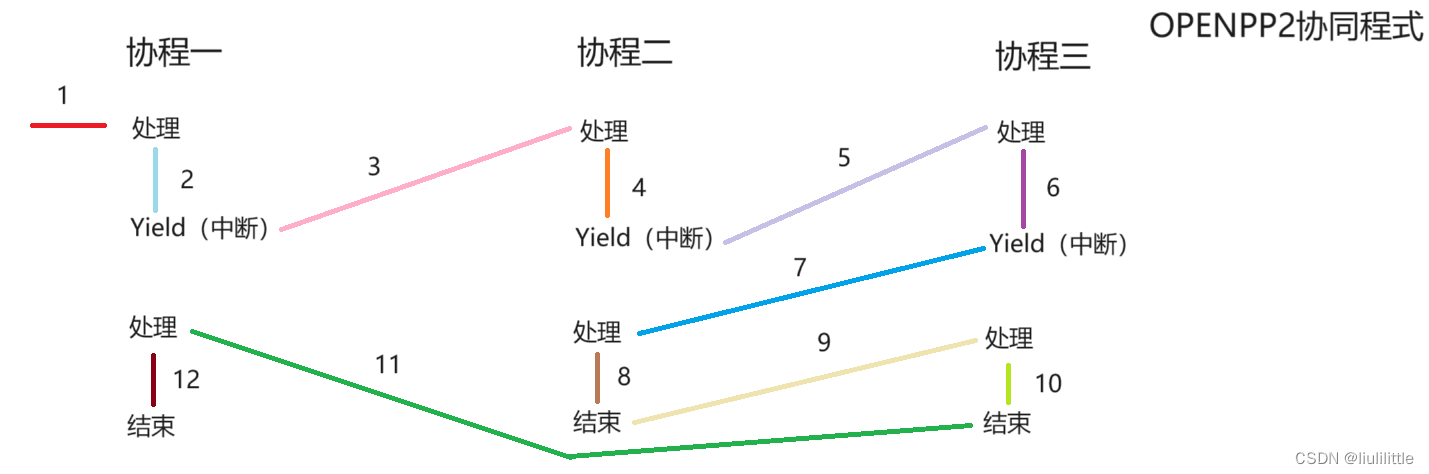
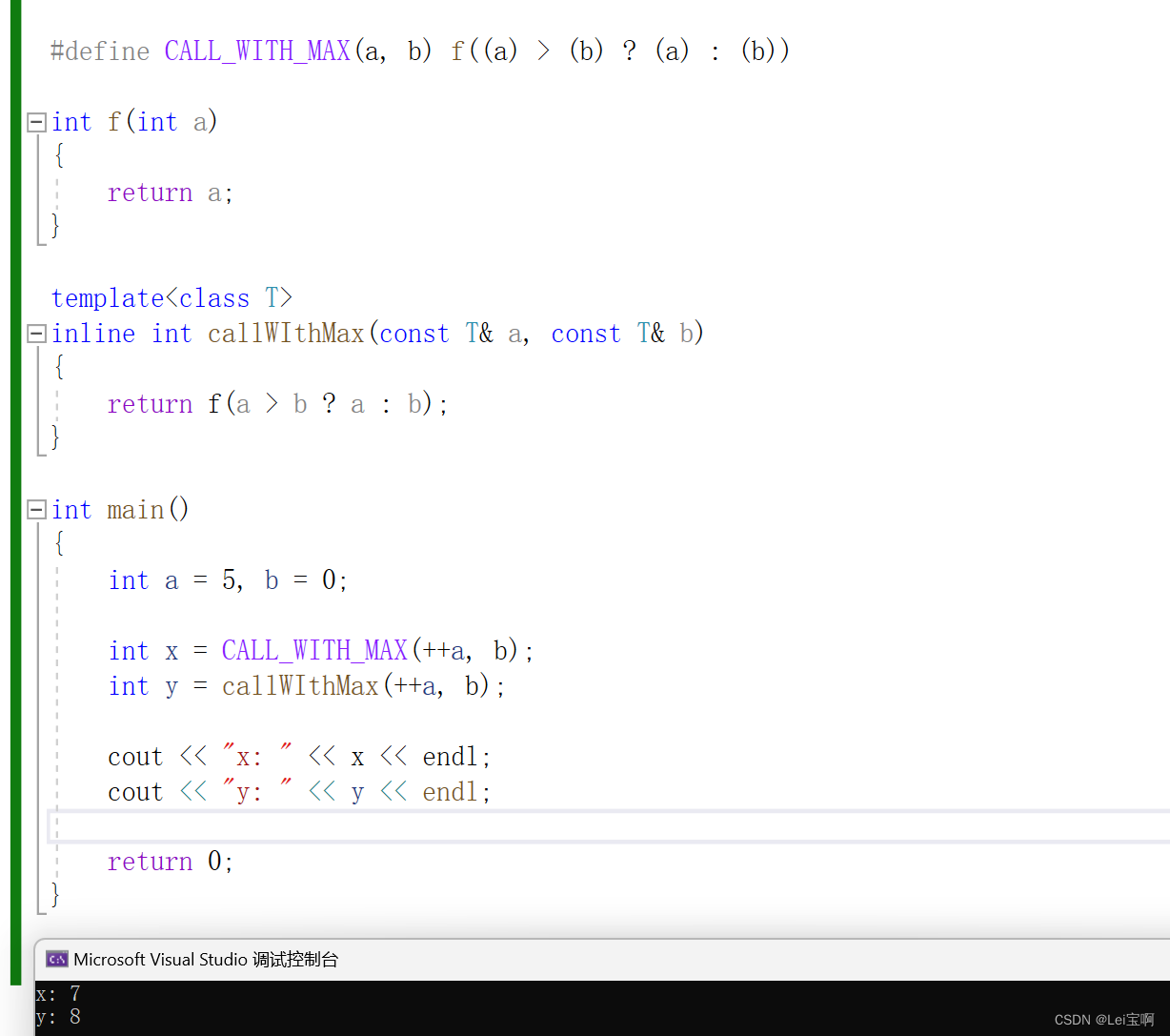
现有的所有模型都无法做到在线学习,能力有限,而让大模型拥有一个tools工具库,则可以使大模型变成一个交互式的工具去协调调用API完成任务,同时GPT4还联网了,可以不断地更新自己的知识库
多模态模型,接受文本、图像的输入
由于GPT4论文展现的技术细节较少,安全性展示较少,所以不做精读,而是读一篇openai官网对GPT4的一份调查报告
GPT-4 (openai.com)
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less capable than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks. For example, it passes a simulated bar exam with a score around the top 10% of test takers; in contrast, GPT-3.5’s score was around the bottom 10%. We’ve spent 6 months iteratively aligning GPT-4 using lessons from our adversarial testing program as well as ChatGPT, resulting in our best-ever results (though far from perfect) on factuality, steerability, and refusing to go outside of guardrails.
翻译:
我们创建了GPT-4,这是开放AI在深度学习规模化方面的最新里程碑。GPT-4是一个大型多模态模型(接受图像和文本输入,输出文本),虽然在许多现实场景中不如人类那样具有高超的能力,但在各种专业和学术基准测试中表现出人类水平的性能。例如,它在模拟的律师资格考试中的得分约为测试者中前10%;相比之下,GPT-3.5的得分约为测试者中最后10%。我们花费了6个月的时间,通过从我们的对抗测试计划和ChatGPT中得到的经验教训,迭代地调整GPT-4,从而取得了我们有史以来在事实性、可操纵性和拒绝超出范围方面的最佳结果(尽管还远非完美)。
总结:
效果好;从去年8月以来做了很多安全性测试
Over the past two years, we rebuilt our entire deep learning stack and, together with Azure, co-designed a supercomputer from the ground up for our workload. A year ago, we trained GPT-3.5 as a first “test run” of the system. We found and fixed some bugs and improved our theoretical foundations. As a result, our GPT-4 training run was (for us at least!) unprecedentedly stable, becoming our first large model whose training performance we were able to accurately predict ahead of time. As we continue to focus on reliable scaling, we aim to hone our methodology to help us predict and prepare for future capabilities increasingly far in advance—something we view as critical for safety.
翻译:
在过去的两年里,我们重新构建了整个深度学习堆栈,并与Azure合作,从头开始设计了一台超级计算机以适应我们的工作负载。一年前,我们训练了GPT-3.5作为系统的第一个“测试运行”。我们发现并修复了一些错误,并改进了我们的理论基础。结果,我们的GPT-4训练运行(至少对我们来说)是前所未有的稳定,成为我们能够提前准确预测其训练性能的第一个大型模型。随着我们继续专注于可靠的扩展,我们的目标是完善我们的方法论,以帮助我们预测和准备未来能力,这对安全至关重要。
总结:
GPT4可以准确预测本次训练的预期结果,不必等到模型完全训练完成才能知道这组参数有没有用,想法有没有work
可以精准预测在小模型上做的消融实验放到大模型上的结果,而不会受到涌现的影响
Capabilities
In a casual conversation, the distinction between GPT-3.5 and GPT-4 can be subtle. The difference comes out when the complexity of the task reaches a sufficient threshold—GPT-4 is more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5.
To understand the difference between the two models, we tested on a variety of benchmarks, including simulating exams that were originally designed for humans. We proceeded by using the most recent publicly-available tests (in the case of the Olympiads and AP free response questions) or by purchasing 2022–2023 editions of practice exams. We did no specific training for these exams. A minority of the problems in the exams were seen by the model during training, but we believe the results to be representative—see our technical report for details.
翻译:
在非正式的对话中,GPT-3.5和GPT-4之间的区别可能是微妙的。当任务的复杂性达到足够的阈值时,这种区别就会显现出来——相比于GPT-3.5,GPT-4更可靠、更具创造力,能够处理比较微妙的指令。
为了理解这两个模型之间的区别,我们在各种基准测试中进行了测试,包括模拟最初设计给人类的考试。我们首先使用最近公开可用的测试(在奥林匹克和AP自由回答问题的情况下),或购买了2022-2023年版的练习考试。我们并未为这些考试进行特定的训练。在考试中,只有少数问题是模型在训练期间见过的,但我们相信结果是具有代表性的——详细信息请参阅我们的技术报告。
总结:
找了些bechmark来比较3.5和4的能力
深绿色是加上了图片输入,效果提升了
GPT系列在数学方面还是不行

We also evaluated GPT-4 on traditional benchmarks designed for machine learning models. GPT-4 considerably outperforms existing large language models, alongside most state-of-the-art (SOTA) models which may include benchmark-specific crafting or additional training protocols:
翻译:
我们还在为机器学习模型设计的传统基准测试上评估了GPT-4。与现有的大型语言模型以及大多数最先进的模型相比,GPT-4表现出了显著的优势,这些模型可能包括特定于基准测试的设计或额外的训练协议:
总结:

刷一刷之前文本领域的bechmark,全面超过LM的SOTA
Many existing ML benchmarks are written in English. To get an initial sense of capability in other languages, we translated the MMLU benchmark—a suite of 14,000 multiple-choice problems spanning 57 subjects—into a variety of languages using Azure Translate (see Appendix). In the 24 of 26 languages tested, GPT-4 outperforms the English-language performance of GPT-3.5 and other LLMs (Chinchilla, PaLM), including for low-resource languages such as Latvian, Welsh, and Swahili:
翻译:
许多现有的机器学习基准测试都是用英文编写的。为了初步了解在其他语言中的能力,我们使用Azure翻译将MMLU基准测试(包含14,000个跨越57个学科的多选题)翻译成了多种语言(详见附录)。在测试的26种语言中的24种语言中,GPT-4在性能上优于GPT-3.5和其他大型语言模型(如Chinchilla、PaLM)的英文表现,包括对拉脱维亚语、威尔士语和斯瓦希里语等资源匮乏的语言:
总结:

Visual inputs
GPT-4 can accept a prompt of text and images, which—parallel to the text-only setting—lets the user specify any vision or language task. Specifically, it generates text outputs (natural language, code, etc.) given inputs consisting of interspersed text and images. Over a range of domains—including documents with text and photographs, diagrams, or screenshots—GPT-4 exhibits similar capabilities as it does on text-only inputs. Furthermore, it can be augmented with test-time techniques that were developed for text-only language models, including few-shot and chain-of-thought prompting. Image inputs are still a research preview and not publicly available.
翻译:
GPT-4可以接受包含文本和图像的提示,这与仅文本设置相对应,使用户能够指定任何视觉或语言任务。具体而言,它能够生成文本输出(自然语言、代码等),给定由交错的文本和图像组成的输入。在包括文本和照片、图表或屏幕截图在内的一系列领域中,GPT-4表现出与仅文本输入相似的能力。此外,它还可以利用针对仅文本语言模型开发的测试时间技术进行增强,包括少样本学习和思维链提示。图像输入仍处于研究预览阶段,尚未公开提供。
总结:

让GPT4说出图片搞笑的点

先对图片做OCR,然后讲法语翻译成英文,然后解题

让GPT读论文,并总结
We preview GPT-4’s performance by evaluating it on a narrow suite of standard academic vision benchmarks. However, these numbers do not fully represent the extent of its capabilities as we are constantly discovering new and exciting tasks that the model is able to tackle. We plan to release further analyses and evaluation numbers as well as thorough investigation of the effect of test-time techniques soon.
翻译:
在评估GPT-4时,我们使用了一系列标准学术视觉基准测试,但这些数据并不能完全代表其能力的广泛程度,因为我们不断发现模型能够处理新的、令人兴奋的任务。我们计划很快发布更多的分析和评估数据,以及对测试时间技术效果的彻底调查。
总结:

在视觉多模态领域比较
Steerability
We’ve been working on each aspect of the plan outlined in our post about defining the behavior of AIs, including steerability. Rather than the classic ChatGPT personality with a fixed verbosity, tone, and style, developers (and soon ChatGPT users) can now prescribe their AI’s style and task by describing those directions in the “system” message. System messages allow API users to significantly customize their users’ experience within bounds. We will keep making improvements here (and particularly know that system messages are the easiest way to “jailbreak” the current model, i.e., the adherence to the bounds is not perfect), but we encourage you to try it out and let us know what you think.
翻译:
我们一直在执行我们在关于定义AI行为的帖子中概述的计划的每个方面,包括可操控性。与固定的冗长度、语气和风格的经典ChatGPT个性不同,开发人员(以及很快会是ChatGPT用户)现在可以通过在“系统”消息中描述这些方向来指定他们的AI的风格和任务。系统消息允许API用户在一定范围内显着自定义他们用户的体验。我们将继续在这方面进行改进(特别是要知道系统消息是“越狱”当前模型的最简单方式,即,对边界的遵守并不完美),但我们鼓励您尝试一下,并告诉我们您的想法。
总结:
System Message可以定义AI用什么样的语气和你说话

Limitations
Despite its capabilities, GPT-4 has similar limitations as earlier GPT models. Most importantly, it still is not fully reliable (it “hallucinates” facts and makes reasoning errors). Great care should be taken when using language model outputs, particularly in high-stakes contexts, with the exact protocol (such as human review, grounding with additional context, or avoiding high-stakes uses altogether) matching the needs of a specific use-case.
While still a real issue, GPT-4 significantly reduces hallucinations relative to previous models (which have themselves been improving with each iteration). GPT-4 scores 40% higher than our latest GPT-3.5 on our internal adversarial factuality evaluations:
翻译:
尽管具备了强大的功能,但GPT-4仍然存在着与之前的GPT模型类似的局限性。最重要的是,它仍然不能完全可靠(会“幻想”事实并产生推理错误)。在使用语言模型输出时应该格外小心,特别是在高风险的情境中,确切的协议(如人工审查、使用额外的上下文来进行确认,或者完全避免高风险的使用)应该根据特定用例的需求来确定。
尽管这仍然是一个真正的问题,但相对于以往的模型(它们自身在每次迭代中都有所改进),GPT-4显著减少了幻觉现象。在我们内部对抗性事实性评估中,GPT-4的得分比我们最新的GPT-3.5高出40%:
总结:
幻觉
The model can have various biases in its outputs—we have made progress on these but there’s still more to do. Per our recent blog post, we aim to make AI systems we build have reasonable default behaviors that reflect a wide swathe of users’ values, allow those systems to be customized within broad bounds, and get public input on what those bounds should be.
GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its data cuts off (September 2021), and does not learn from its experience. It can sometimes make simple reasoning errors which do not seem to comport with competence across so many domains, or be overly gullible in accepting obvious false statements from a user. And sometimes it can fail at hard problems the same way humans do, such as introducing security vulnerabilities into code it produces.
GPT-4 can also be confidently wrong in its predictions, not taking care to double-check work when it’s likely to make a mistake. Interestingly, the base pre-trained model is highly calibrated (its predicted confidence in an answer generally matches the probability of being correct). However, through our current post-training process, the calibration is reduced.
翻译:
模型在输出中可能存在各种偏见——我们在这方面已经取得了进展,但还有更多工作要做。根据我们最近的博客文章,我们的目标是使我们构建的AI系统具有合理的默认行为,反映了广泛用户价值观的范围,允许在广泛范围内定制这些系统,并征求公众对这些边界应该是什么的意见。
GPT-4通常缺乏对其数据大部分截止时间(2021年9月)之后发生的事件的了解,并且不从其经验中学习。它有时会产生简单的推理错误,这与在如此多的领域中表现出的能力不一致,或者在接受用户明显错误的陈述时过于轻信。有时它会以与人类相同的方式在难题上失败,比如在生成的代码中引入安全漏洞。
GPT-4在预测中也可能会自信满满地犯错,在可能犯错时不进行仔细检查。有趣的是,基础的预训练模型是高度校准的(它对答案的预测置信度通常与正确的概率相匹配)。然而,通过我们目前的后训练过程,校准程度会降低。
总结:
偏见
训练数据有时限性
对人服从,过于轻信

模型对其预测的信心与正确概率密切匹配。虚线对角线代表完美的校准。
经过RLHF后反而不行了,更有主观性了
Risks & mitigations
We’ve been iterating on GPT-4 to make it safer and more aligned from the beginning of training, with efforts including selection and filtering of the pretraining data, evaluations and expert engagement, model safety improvements, and monitoring and enforcement.
GPT-4 poses similar risks as previous models, such as generating harmful advice, buggy code, or inaccurate information. However, the additional capabilities of GPT-4 lead to new risk surfaces. To understand the extent of these risks, we engaged over 50 experts from domains such as AI alignment risks, cybersecurity, biorisk, trust and safety, and international security to adversarially test the model. Their findings specifically enabled us to test model behavior in high-risk areas which require expertise to evaluate. Feedback and data from these experts fed into our mitigations and improvements for the model; for example, we’ve collected additional data to improve GPT-4’s ability to refuse requests on how to synthesize dangerous chemicals.
GPT-4 incorporates an additional safety reward signal during RLHF training to reduce harmful outputs (as defined by our usage guidelines) by training the model to refuse requests for such content. The reward is provided by a GPT-4 zero-shot classifier judging safety boundaries and completion style on safety-related prompts. To prevent the model from refusing valid requests, we collect a diverse dataset from various sources (e.g., labeled production data, human red-teaming, model-generated prompts) and apply the safety reward signal (with a positive or negative value) on both allowed and disallowed categories.
Our mitigations have significantly improved many of GPT-4’s safety properties compared to GPT-3.5. We’ve decreased the model’s tendency to respond to requests for disallowed content by 82% compared to GPT-3.5, and GPT-4 responds to sensitive requests (e.g., medical advice and self-harm) in accordance with our policies 29% more often.
翻译:
我们一直在对GPT-4进行迭代,从训练开始就使其更安全和更对齐,包括对预训练数据的选择和过滤、评估和专家参与、模型安全改进以及监控和执行等方面的努力。
GPT-4存在与之前模型类似的风险,例如生成有害建议、错误的代码或不准确的信息。然而,GPT-4的额外功能导致了新的风险面。为了了解这些风险的程度,我们与来自AI对齐风险、网络安全、生物风险、信任与安全以及国际安全等领域的50多位专家进行了对抗性测试。他们的发现特别让我们能够测试模型在需要专业知识评估的高风险领域中的行为。这些专家的反馈和数据为我们的模型缓解和改进提供了支持;例如,我们收集了额外的数据以提高GPT-4拒绝合成危险化学物质的能力。
在RLHF训练期间,GPT-4集成了一个额外的安全奖励信号,以减少有害输出(根据我们的使用准则定义),通过训练模型拒绝对此类内容的请求。奖励由一个GPT-4零样分类器提供,用于判断安全边界和安全相关提示的完成样式。为了防止模型拒绝有效请求,我们从各种来源收集了多样化的数据集(例如,标记的生产数据、人类红队测试、模型生成的提示)并在允许和不允许的类别上应用安全奖励信号(具有正值或负值)。
我们的缓解措施相比于GPT-3.5显著改善了GPT-4的许多安全属性。与GPT-3.5相比,我们将模型对不允许内容的请求的反应倾向减少了82%,而GPT-4对敏感请求(例如医疗建议和自伤行为)的回应频率根据我们的政策提高了29%。
总结:
(1)人力收集数据提高安全性
(2)利用自己,做了个reward signal,是从预训练好的gpt4中拿出来对prompt进行sensitive检测
Overall, our model-level interventions increase the difficulty of eliciting bad behavior but doing so is still possible. Additionally, there still exist “jailbreaks” to generate content which violate our usage guidelines. As the “risk per token” of AI systems increases, it will become critical to achieve extremely high degrees of reliability in these interventions; for now it’s important to complement these limitations with deployment-time safety techniques like monitoring for abuse.
GPT-4 and successor models have the potential to significantly influence society in both beneficial and harmful ways. We are collaborating with external researchers to improve how we understand and assess potential impacts, as well as to build evaluations for dangerous capabilities that may emerge in future systems. We will soon share more of our thinking on the potential social and economic impacts of GPT-4 and other AI systems.
翻译:
总体而言,我们在模型层面的干预措施增加了引发不良行为的难度,但这仍然是可能的。此外,仍然存在“越狱”的方法来生成违反我们使用准则的内容。随着AI系统的“风险每个令牌”的增加,在这些干预措施中实现极高的可靠性将变得至关重要;目前,将这些限制与部署时的安全技术相结合,例如监控滥用情况,是非常重要的。
GPT-4和后续模型有潜力在社会上产生显着的积极和消极影响。我们正在与外部研究人员合作,改进我们对潜在影响的理解和评估方法,以及为可能在未来系统中出现的危险功能构建评估方法。我们很快将分享更多关于GPT-4和其他AI系统潜在社会和经济影响的思考。
Training process
Like previous GPT models, the GPT-4 base model was trained to predict the next word in a document, and was trained using publicly available data (such as internet data) as well as data we’ve licensed. The data is a web-scale corpus of data including correct and incorrect solutions to math problems, weak and strong reasoning, self-contradictory and consistent statements, and representing a great variety of ideologies and ideas.
翻译:
与先前的GPT模型一样,GPT-4基础模型被训练以预测文档中的下一个词,并且使用了公开可用的数据(如互联网数据)以及我们许可的数据进行训练。这些数据是一个网络规模的数据语料库,包括数学问题的正确和错误解决方案,弱和强的推理,自相矛盾和一致的陈述,代表了各种意识形态和观念。
So when prompted with a question, the base model can respond in a wide variety of ways that might be far from a user’s intent. To align it with the user’s intent within guardrails, we fine-tune the model’s behavior using reinforcement learning with human feedback (RLHF).
翻译:
在面对问题时,基础模型可能会以多种与用户意图相距甚远的方式进行回应。为了使其在用户意图的框架内对齐,我们使用强化学习与人类反馈(RLHF)对模型的行为进行微调。
总结:
基础模型有的时候的回答会和人想要的回答相差很远,所以用RLHF的技术微调了一下
Note that the model’s capabilities seem to come primarily from the pre-training process—RLHF does not improve exam performance (without active effort, it actually degrades it). But steering of the model comes from the post-training process—the base model requires prompt engineering to even know that it should answer the questions.
翻译:
请注意,模型的能力似乎主要来自预训练过程——强化学习与人类反馈并未改善考试表现(没有主动的努力,实际上它会降低考试表现)。但是,对模型的引导来自于后训练过程——基础模型需要及时的工程处理,甚至知道它应该回答这些问题。
总结:
虽然RLHF并没有带来很好的提分,但RLHF还是控制了模型生成人更愿意接受的回答方式
Predictable scaling
A large focus of the GPT-4 project has been building a deep learning stack that scales predictably. The primary reason is that, for very large training runs like GPT-4, it is not feasible to do extensive model-specific tuning. We developed infrastructure and optimization that have very predictable behavior across multiple scales. To verify this scalability, we accurately predicted in advance GPT-4’s final loss on our internal codebase (not part of the training set) by extrapolating from models trained using the same methodology but using 10,000x less compute:
翻译:
GPT-4项目的一个主要关注点是构建一个可预测扩展的深度学习堆栈。主要原因是,对于像GPT-4这样的非常大的训练运行,进行大量的模型特定调整是不可行的。我们开发了基础设施和优化,这些基础设施和优化在多个规模上表现出非常可预测的行为。为了验证这种可扩展性,我们通过从使用相同方法论进行训练但计算量减少了10,000倍的模型进行外推,准确预测了GPT-4在我们的内部代码库(不属于训练集)上的最终损失:
总结:
这么大的模型不可能去做大规模的调参
就算有大量的机器并行去跑,loss也容易跑飞
OpenAI研发了一套infra和优化方法,在多个尺度上实现了训练的稳定性,刚开始训练的时候就已经能预测出最终的loss了

这里可以看出GPT4确实很好地拟合出了loss的曲线
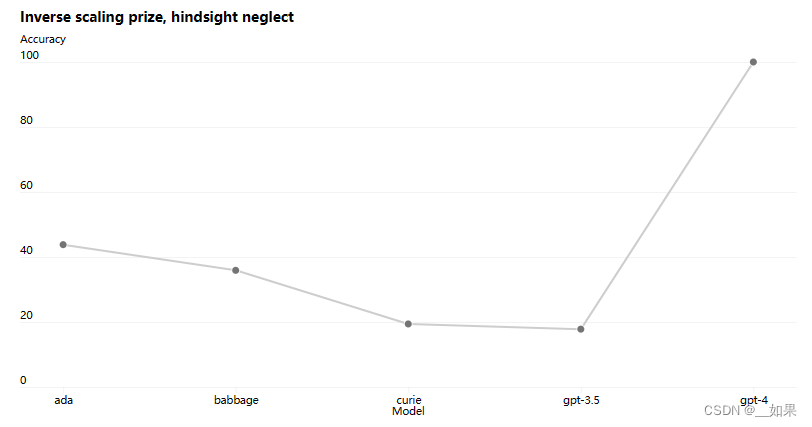
Some capabilities are still hard to predict. For example, the Inverse Scaling Prize was a competition to find a metric that gets worse as model compute increases, and hindsight neglect was one of the winners. Just like with another recent result, GPT-4 reverses the trend:
翻译:
一些能力仍然很难预测。例如,反比例缩放奖是一个竞赛,旨在找到一个随着模型计算增加而变差的指标,而事后忽视就是其中之一的获奖者。就像另一个最近的结果一样,GPT-4扭转了这一趋势:
总结:
这个competition是GPT3出的时候故意找的,用来证明大模型不是所有任务都比小模型要好
牛头不对马嘴的任务中GPT4反而出现了非理性的选择,跳出了逻辑,为结果服务
API
gpt-4 has a context length of 8,192 tokens. We are also providing limited access to our 32,768–context (about 50 pages of text) version, gpt-4-32k, which will also be updated automatically over time (current version gpt-4-32k-0314, also supported until June 14). Pricing is $0.06 per 1K prompt tokens and $0.12 per 1k completion tokens. We are still improving model quality for long context and would love feedback on how it performs for your use-case. We are processing requests for the 8K and 32K engines at different rates based on capacity, so you may receive access to them at different times.
翻译:
GPT-4的上下文长度为8,192个标记。我们还提供对我们的32,768个标记(约50页文本)版本gpt-4-32k的有限访问权限,该版本也将随时间自动更新(当前版本为gpt-4-32k-0314,支持至6月14日)。定价为每1,000个提示标记0.06美元,每1,000个完成标记0.12美元。我们仍在改进长上下文的模型质量,并希望了解它在您的使用案例中的表现。我们根据容量以不同的速度处理对8K和32K引擎的请求,因此您可能会在不同的时间收到对它们的访问权限。
Conclusion
We look forward to GPT-4 becoming a valuable tool in improving people’s lives by powering many applications. There’s still a lot of work to do, and we look forward to improving this model through the collective efforts of the community building on top of, exploring, and contributing to the model.
翻译:
我们期待着GPT-4成为一个有价值的工具,通过为许多应用程序提供支持来改善人们的生活。还有很多工作要做,我们期待着通过社区的集体努力,不断改进这个模型,探索和为模型做出贡献。