使用斯坦福分词器进行词性标注
文章目录
- 使用斯坦福分词器进行词性标注
- 前言
- 一、斯坦福分词器是什么?
- 二、使用步骤
- 1.去官网下载工具包
- 2.导入库
- 3.斯坦福模型功能的介绍
- 4.分词结果展示
- 5.分词结果进行分析
- 三、总结
前言
中文分词是中文文本处理的一个基础步骤,同时也是中文人机自然语言交互的基础模块,与英文不同的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性,句法树等模块的效果场景不同,要求也不同。在人机自然语言交互中,成熟的中文分词算法能够达到更好的自然语言处理效果,帮助计算机理解复杂的中文语言。基于统计的机器学习算法stanford,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备良好的学习能力,因此对歧义词和未登录词的识别都具有良好的效果。
一、斯坦福分词器是什么?
Stanford CoreNLP是一个自然语言处理工具包。它集成了很多非常实用的功能,包括分词,词性标注,句法分析等等。这不是一个深度学习框架,而是一个已经训练好的模型,实际上可以类比为一个软件。目前市面上有不少类似的工具,结巴分词、清华、哈工大等等,相比之下我个人认为斯坦福这一款有三个值得选择的理由(也可能是优势,但是我没用过其他工具所以没法比):功能足够多,一站式解决所有主流需求;操作足够方便,放到 Python 里基本上就是一两行代码;
语言支持广泛,目前支持阿拉伯语,中文,英文,法语,德语,西班牙语,做平行语料的对比非常方便。Stanford CoreNLP 本身是 Java 写的,提供了 Server 的方式进行交互,可以很方便地在Python 中使用。使用极少的代码就能实现我们想要的功能。
二、使用步骤
1.去官网下载工具包

包括核心包和中文分包两种,下载完成后,将中文包解压缩到核心包中,形成一个完整的包,方便我们去调用。核心部分已经包括了英语的处理能力,因为我们要处理的内容包括中文,所以还要下载与中文相关的程序包下载成功后,导引根目录即我们下载的核心包中即可完成工具包中相应的操作。
这就是弄完之后的图,形成一个总包,安装成功的工具包中就可以通过python直接调用了,其中要注意的是中文包和我们下载的核心包的版本要对应。要注意的是文件夹不能含有中文,否则会读入不进去。
2.导入库
pip install stanfordcorenlp
3.斯坦福模型功能的介绍
①分词 Tokenization
通过nlp.word_tokenize(sentence)将我们选择的文本内容进行分词,word_tokenize 这个方法的返回值是一个列表,处理起来非常的方便,但要注意一点,如果使用 Pandas,那 list 是无法保存的。一个比较常见的操作是使用一个DataFrame 来装语料,每一句语料对应一行,然后添加一列来装对应句子的tokens,那么在刚刚操作完的时候这一列装的是一列list,但如果接下来把这个DataFrame 保存成文件,比如csv文件,那么下次再重新读取进来的时候这一列DataFrame就变成了字符串格式。
②词性标注 Part-of-speech Tagging
词性标注实际上包含了分词和标注两个部分。标注的含义在第五部分。跟分词结果一样,POS的结果一旦保存再读取也会变成字符串,所以一般还是需要处理一下。
③句法成分分析 Constituency Parsing
句法分析的标注实际上是由两个部分组成的,在最小的一层括号内实际上就是词性标注,而除此之外则是与句子结构相关的标注。句法分析的标注也在第五部分给出。
④标注集 Tagset
CoreNLP 使用的是宾州树库的标注集(Penn Treebank Tagset),无论中英。目前在中文网络上,中文标注集总结的比较全,但英文标注集基本上没有完全正确的,尤其是句法相关的标注。中文的标注集实际上是 Penn Chinese Treebank Tagset。
⑤NER工具
NER往往作为Natural Language applications的基础,比如QA,text summarization,machine translation等的基础,NER是一种序列标注任务,常见的序列标注任务还有分词,词性标注(POS),关键词抽取,词义角色标注等。NER的关键是实体边界的确定和实体类别的判断。NER是多分类问题,对于分类问题的评价标准,常用的评价标准有:Acc,Precision,Recall和F1值 Acc是一种很常见的评价标准,但只是这个又是不够的,因为在数据不均衡的情况下,Acc往往只会给我们带来欺骗性,比如癌症检测 (我们希望关注的是minority class)F1值是综合了precision和recall的一个指标。
代码如下(示例):
from stanfordcorenlp import StanfordCoreNLP
#指明安装路径和语言类型(中文)
nlp = StanfordCoreNLP(r'D:\learn\nlp\stanford-corenlp-full-2018-10-05', lang='zh')
#这里的文件位置就是我们刚才下载的核心包位置
sentence = "今天核酸队长死了"
#进行分词的语句
print(nlp.word_tokenize(sentence))
print(nlp.pos_tag(sentence))
print(nlp.parse(sentence))
print(nlp.ner(sentence))
print(nlp.dependency_parse(sentence))
nlp.close()
4.分词结果展示
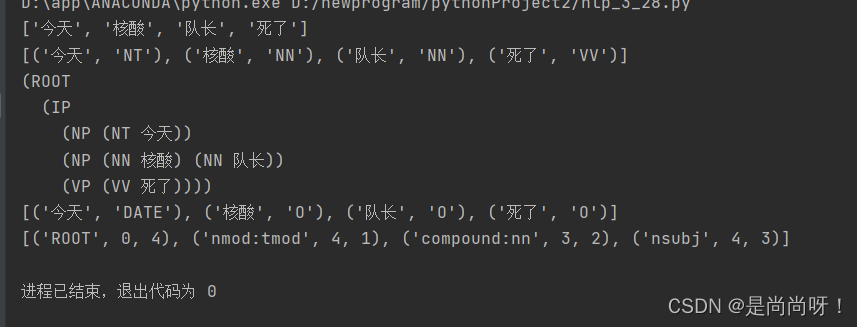
5.分词结果进行分析
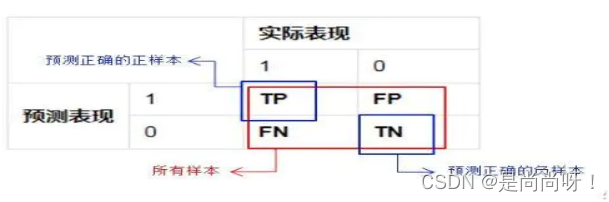
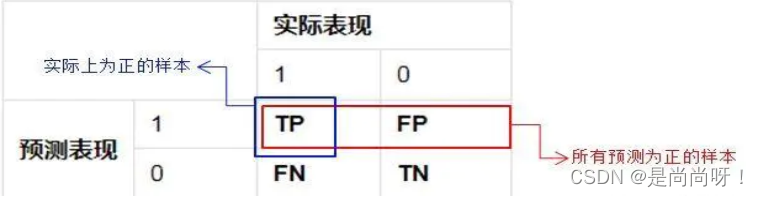
对于一个二分类系统,将实例分为正类(Positive)、负类(Negative)则模式分类器有四种分类果:
TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类
FN(False Negative):错误的反例,漏报,本为正类但判定为假类
FP(False Positive):错误的正例,误报,本为假类但判定为正类
TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类
1)准确率
既然是个分类指标,我们可以很自然的想到准确率,准确率的定义是预测正确的结果占总样本的百分比,其公式如下:
准确率 =(TP+TN)/(TP+TN+FP+FN)
2)精准率
精准率(Precision)又叫查准率,它是针对预测结果 而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确,其公式如下:精准率 =TP/(TP+FP)
3)召回率
召回率(Recall)又叫查全率,它是针对原样本而言的,它的含义是在实际为的样本中被预测为正样本的概率,其公式如下:

4)F1 分数
通过上面的公式,我们发现:精准率和召回率的分子是相同,都是 TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个 P-R 图来展示:

5)带入我们的模型中
分词结果:[“今天”,“核酸”,“队长”,“死了”]
[1,2],[3,4],[5,6],[7,8]
标准分词结果:[“今天”,“核酸”,“队”,“长”,“死”,“了”]
[1,2],[3,4],[5,5],[6,6],[7,7],[8,8]
重合部分有[1,2],[3,4]
计算后的到准确率为
①P=2/4100%=50% ②R=2/6100%=33.3%③F1=2PR/(P+R)≈40.0
三、总结
斯坦福模型功能足够多,一站式解决所有主流需求;操作足够方便,放到 Python 里基本上就是一两行代码;语言支持广泛,目前支持阿拉伯语,中文,英文,法语,德语,西班牙语,做平行语料的对比非常方便。Stanford CoreNLP 本身是 Java 写的,提供了 Server 的方式进行交互,可以很方便地在Python 中使用。使用极少的代码就能实现我们想要的功能。对于不同种类的分词模式都有各自的优缺点,要根据具体问题去应用相对应的中文词性标注。