文章目录
- 前言
- 数据库的创建和删除
- 集合的创建和删除
- 文档的插入和查询
- 异常处理
- 更新数据
- 局部修改
- 符合条件的批量更新
- 加操作
- 删除文档
- 删除全部数据
- 删除符合条件的数据
- 统计count
- 统计有多少条数据
- 统计特定条件有多少条数据
- 分页查询
- 排序查询
- 正则查询
- 比较查询
- 包含查询
- 条件连接查询
- 索引
- 查看索引
- 创建索引
- 删除索引
前言
我们这里使用的mongosh,mongodb shell。因为mongo7.0本体没有mongo命令了。
数据库的创建和删除
创建数据库
use 数据库名称
mongodb 如果没有这个数据库就会直接创建
删除数据库
db.dropDatabase()
显示全部的数据库
show databases
show dbs
集合的创建和删除
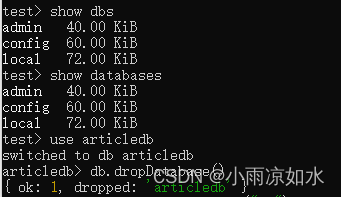
创建集合
db.createCollection(“集合的名称”)
集合的删除
db.集合的名称.drop()
显示全部的集合
show collections
文档的插入和查询
文档(document)的数据结构和JSON基本一样。所有存储在集合中的数据都是BSON格式。
单个插入内容
db.comment.insert({“articleid”:“100000”,“content”:“今天天气真好,阳光明媚”,“userid”:“1001”,“nickname”:“Rose”,“createdatetime”:new Date(),“likenum”:NumberInt(10),“state”:null})
请注意,我们这里使用了comment,这个是集合的名字,我们这样使用,如果没有这个集合,就会创建一个集合
批量插入,注意!!!,如果某条插入失败了,mongodb不会回滚!!!
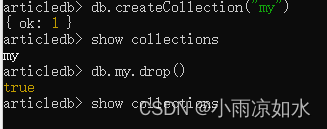
db.comment.insertMany([ {“_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。”,“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-08 05T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”}, {“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔 悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”}, {“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船 长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”}, {“_id”:“4”,“articleid”:“100001”,“content”:“专家说不能空腹吃饭,影响健康。”,“userid”:“1003”,“nickname”:“凯 撒”,“createdatetime”:new Date(“2019-08-06T08:18:35.288Z”),“likenum”:NumberInt(2000),“state”:“1”}, {“_id”:“5”,“articleid”:“100001”,“content”:“研究表明,刚烧开的水千万不能喝,因为烫 嘴。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08 06T11:01:02.521Z”),“likenum”:NumberInt(3000),“state”:“1”} ]);
查询全部数据,如果没有数据就是空
db.comment.find()
条件查询,注意这里会返回全部的符合条件的数据
db.comment.find({articleid:“100001”})
条件查询+limit
只返回第一条数据
db.comment.findOne({article:“100001”})
查询部分显示
db.comment.find({articleid:“100001”},{articleid:1})
异常处理
try {
db.comment.insertMany([ {“_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。”,“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-0805T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”},
{“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”},
{“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”},{“_id”:“4”,“articleid”:“100001”,“content”:“专家说不能空腹吃饭,影响健康。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08-06T08:18:35.288Z”),“likenum”:NumberInt(2000),“state”:“1”},
{“_id”:“5”,“articleid”:“100001”,“content”:“研究表明,刚烧开的水千万不能喝,因为烫嘴。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-0806T11:01:02.521Z”),“likenum”:NumberInt(3000),“state”:“1”}]);} catch (e) {print (e)}
更新数据
注意!!!我自己测试,mongodb7所有的更新操作必须要有院子操作符,也就是$set,$inc 这些东西,不然会报错
局部修改
db.comment.update({_id:“1”},{$set:{likenum:NumberInt(1001)}})
符合条件的批量更新
我们的凯撒有两条数据,我们想一起修改
db.comment.update({userid:“1003”},{$set:{nickname:“凯撒大帝”}},{multi:true})
加操作
db.comment.update({_id:“3”},{$inc:{likenum:NumberInt(1)}})
后面可以写你想加的数字
删除文档
注意!!!remove在未来会被弃用!!!
DeprecationWarning: Collection.remove() is deprecated. Use deleteOne, deleteMany, findOneAndDelete, or bulkWrite.
删除全部数据
db.comment.remove({})
删除符合条件的数据
db.comment.remove({_id:“1”})
统计count
注意!!!count在未来会被弃用!!!
DeprecationWarning: Collection.count() is deprecated. Use countDocuments or estimatedDocumentCount.
统计有多少条数据
db.comment.count()
统计特定条件有多少条数据
db.comment.count({userid:“1003”})
分页查询
分页查询就是MySQL里的limit和offset,
limit 就是只要几条数据,offset就是跳过几条数据
在mongodb里面limit还是limit,offset变成了skip。
这个作用就是用于把数据进行分页的
db.comment.find().skip(0).limit(2)
db.comment.find().skip(2).limit(2)
db.comment.find().skip(4).limit(2)
排序查询
对userid降序排列,并对访问量进行升序排列
db.comment.find().sort({userid:-1,likenum:1})
正则查询
mongodb也支持正则表达式的查询,格式为
db.集合.find({字段:/正则表达式/})
关于正则表达式,正则表达式我是觉得很反人类的,会用就行了,现在也有gpt了,也可以让gpt去写正则表达式
比较查询
比较查询就是大于,大于等于,小于,小于等于,不等于,等于,这些是比较常用的
db.集合名称.find({ “field” : { $gt: value }}) // 大于: field > value
db.集合名称.find({ “field” : { $lt: value }}) // 小于: field < value
db.集合名称.find({ “field” : { $gte: value }}) // 大于等于: field >= value
db.集合名称.find({ “field” : { $lte: value }}) // 小于等于: field <= value
db.集合名称.find({ “field” : { $ne: value }}) // 不等于: field != value
db.集合名称.find({ “field” : { $eq: value }}) // 等于: field == value
比如,查询评论点赞数量大于700的记录
这里想说明一下,我用的mongodb7版本写不写NumberInt都可以运行,前面也是这样的
db.comment.find({likenum:{$gt:NumberInt(700)}})
包含查询
包含查询就是使用in(在里面),nin(不在里面)
学过python的朋友应该很熟悉吧
查询评论的集合中userid字段包含1003或1004的文档
db.comment.find({userid:{$in:[“1003”,“1004”]}})
查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:[“1003”,“1004”]}})
条件连接查询
这里就是使用and和or
格式为
$and:[ { },{ },{ } ]
$or:[ { },{ },{ } ]
查询评论集合中likenum大于等于700 并且小于2000的文档
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[ {userid:“1003”} ,{likenum:{$lt:1000} }]})
索引
索引简单来说,就是为了加速查询的,你们可以下载一个软件叫everything,它的查询速度就不是win能比的。
查看索引
db.comment.getIndexes()
创建索引
按照升序,将userid创建为索引
db.comment.createIndex({userid:1})
复合索引,对userid和nickname同时建立复合索引
db.comment.createIndex({userid:1,nickname:-1})
删除索引
db.comment.dropIndex({userid:1})
db.comment.dropIndex(“userid_1_nickname_-1”)
删除所有的索引,注意!!!默认的索引是不会删除的
db.comment.dropIndexes()





![[C/C++] -- 二叉树](https://img-blog.csdnimg.cn/direct/40d3967febde4c3486c9e53cbfcc084d.jpeg)