一、前言
刚开始接触AI时,您可能会感到困惑,因为面对众多开源模型的选择,不知道应该选择哪个模型,也不知道如何调用最基本的模型。但是不用担心,我将陪伴您一起逐步入门,解决这些问题。
在信息时代,我们可以轻松地通过互联网获取大量的理论知识和概念。然而,仅仅掌握理论知识并不能真正帮助我们成长和进步。实践是将理论知识转化为实际技能和经验的关键。
我将引导您以最低的成本运行ChatGLM3-6b模型,让您体验到它带来的美妙特性。
qwen模型教程入口:
开源模型应用落地-qwen模型小试-入门篇(一)_qwen文本分类-CSDN博客
baichuan模型教程入口:
开源模型应用落地-baichuan模型小试-入门篇(一)-CSDN博客
二、术语
2.1. 智谱AI
是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型GLM-130B,并构建了高精度通用知识图谱,形成数据与知识双轮驱动的认知引擎,基于此模型打造了ChatGLM(chatglm.cn)。此外,智谱AI还推出了认知大模型平台Bigmodel.ai,包括CodeGeeX和CogView等产品,提供智能API服务,链接物理世界的亿级用户、赋能元宇宙数字人、成为具身机器人的基座,赋予机器像人一样“思考”的能力。
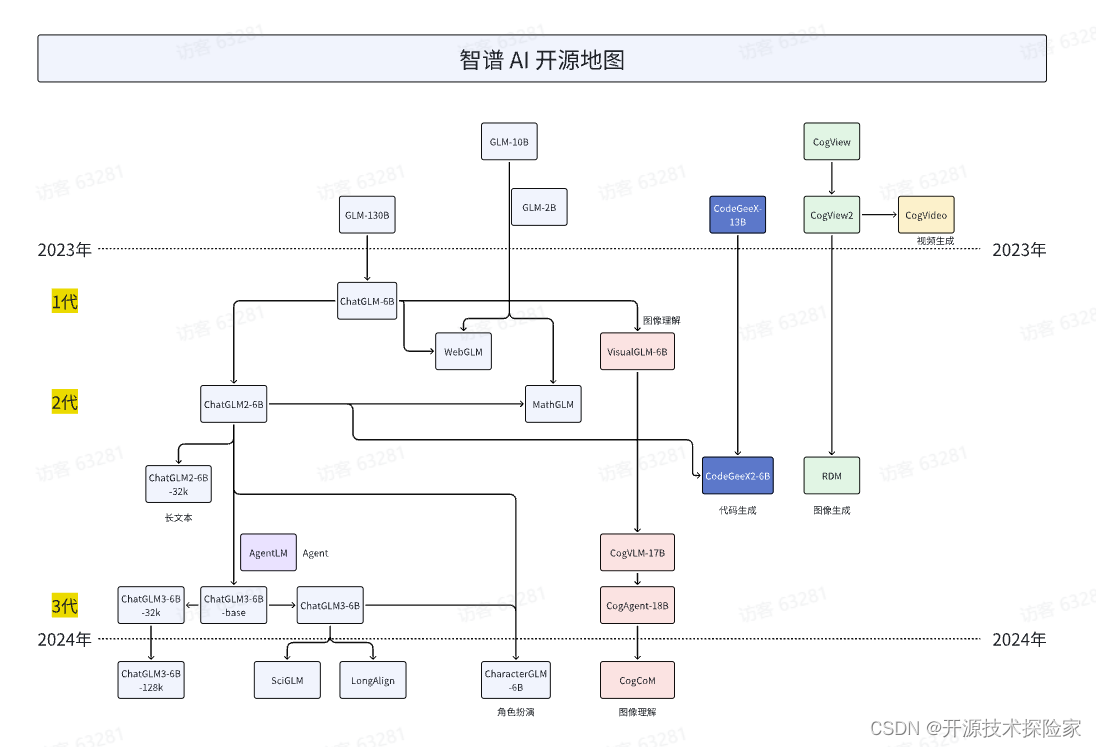
2.2. ChatGLM3
是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
三、前置条件
3.1. windows操作系统
3.2. 下载chatglm3-6b模型
从huggingface下载:https://huggingface.co/THUDM/chatglm3-6b/tree/main
从魔搭下载:魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/files![]() https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/files
https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/files
3.3. 创建虚拟环境&安装依赖
conda create --name chatglm3 python=3.10
conda activate chatglm3
pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 sentencepiece accelerate四、技术实现
4.1. 本地推理
#Tokenizer加载
def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)return tokenizer#Model加载
def loadModel():model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).eval()print(model)return model#推理执行结果如下:
def chat(model, tokenizer, message):try:for response in model.stream_chat(tokenizer, message):_answer,_history = responseyield _answerexcept Exception:traceback.print_exc()4.2. 完整代码
# -*- coding = utf-8 -*-
from transformers import AutoTokenizer, AutoModelForCausalLM
import time
import tracebackmodelPath = "E:\\model\\chatglm3-6b"def chat(model, tokenizer, message):try:for response in model.stream_chat(tokenizer, message):_answer,_history = responseyield _answerexcept Exception:traceback.print_exc()def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)return tokenizerdef loadModel():model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).eval()#print(model)return modelif __name__ == '__main__':model = loadModel()tokenizer = loadTokenizer()message = "你是谁?"response = chat(model, tokenizer, message)for answer in response:print(answer)
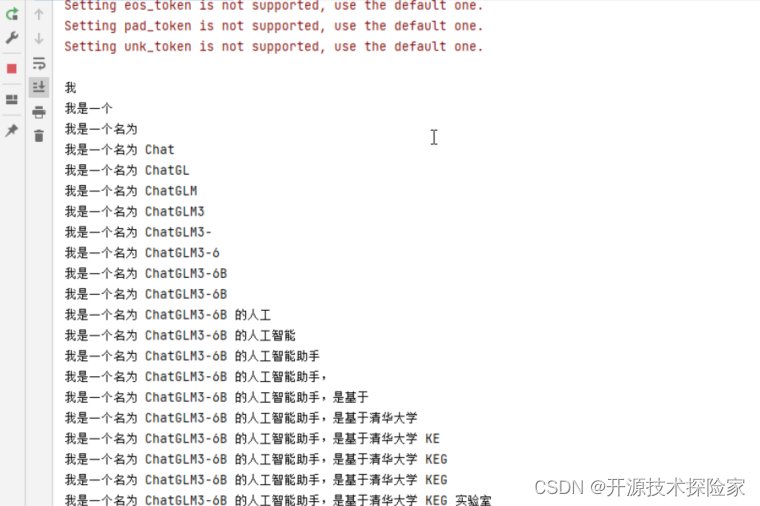
运行结果:
五、附带说明
5.1.ChatGLM3-6B vs Qwen1.5-7B-Chat
1) 推理实现的代码差异
ChatGLM3:
for response in model.stream_chat(tokenizer,message, history)
......
QWen1.5:
generation_kwargs = dict(inputs=model_inputs.input_ids, streamer=streamer)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
for response in streamer:
......
2) 对话格式差异
ChatGLM3:
<|system|>
You are a helpful assistant.
<|user|>
我家在广州,很好玩哦
<|assistant|>
广州是一个美丽的城市,有很多有趣的地方可以去。QWen1.5:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
我家在广州,很好玩哦<|im_end|>
<|im_start|>assistant
广州是一个美丽的城市,有很多有趣的地方可以去。<|im_end|>3) 模型参数
| ChatGLM3-6B | QWen1.5-7B-Chat | |
| n_layers | 28 | 32 |
| n_heads | 32 | 32 |
| vocab size | 65,024 | 151,851 |
| sequence length | 8192 | 8192 |



![[力扣]根据前中序构造二叉树--详细解析](https://img-blog.csdnimg.cn/direct/a8139b163a7549d5bc97c50ea2eab80d.png)