线程_信号量
互斥锁使用后,一个资源同时只有一个线程访问。如果某个资源,我们同时想让N个(指定数值)线程访问?这时候,可以使用信号量。
信号量控制同时访问资源的数量。信号量和锁相似,锁同一时间只允许一个对象(进程)通过,信号量同一时间允许多个对象(进程)通过。
应用场景
- 在读写文件的时候,一般只能只有一个线程在写,而读可以有多个线程同时进行,如果需要限制同时读文件的线程个数,这时候就可以用到信号量了(如果用互斥锁,就是限制同一时刻只能有一个线程读取文件)。
- 在做爬虫抓取数据时。
底层原理
信号量底层就是一个内置的计数器。每当资源获取时(调用acquire)计数器-1,资源释放时(调用release)计数器+1。
#coding=utf-8
from threading import Thread, Lock
from time import sleep
from multiprocessing import Semaphore
"""
一个房间一次只允许两个人通过
若不使用信号量,会造成所有人都进入这个房子
若只允许一人通过可以用锁-Lock()
"""
def home(name, se):se.acquire() # 拿到一把钥匙print(f'{name}进入了房间')sleep(3)print(f'******************{name}走出来房间')se.release() # 还回一把钥匙
if __name__ == '__main__':se = Semaphore(2) # 创建信号量的对象,有两把钥匙for i in range(7):p = Thread(target=home, args=(f'tom{i}', se))p.start()
'''
执行结果:
tom0进入了房间
tom1进入了房间
******************tom1走出来房间
tom2进入了房间
******************tom0走出来房间
tom3进入了房间
******************tom2走出来房间******************tom3走出来房间
tom4进入了房间
tom5进入了房间
******************tom5走出来房间******************tom4走出来房间
tom6进入了房间
******************tom6走出来房间
Process finished with exit code 0
'''
线程_事件Event对象
事件Event主要用于唤醒正在阻塞等待状态的线程;
原理
Event 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,event 对象中的信号标志被设置假。如果有线程等待一个 event 对象,而这个 event 对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个 event 对象的信号标志设置为真,它将唤醒所有等待个 event 对象的线程。如果一个线程等待一个已经被设置为真的 event 对象,那么它将忽略这个事件,继续执行
Event()可以创建一个事件管理标志,该标志(event)默认为False,event对象主要有四种方法可以调用:
| 方法名 | 说明 |
|---|---|
event.wait(timeout=None) | 调用该方法的线程会被阻塞,如果设置了timeout参数,超时后,线程会停止阻塞继续执行; |
event.set() | 将event的标志设置为True,调用wait方法的所有线程将被唤醒 |
event.clear() | 将event的标志设置为False,调用wait方法的所有线程将被阻塞 |
event.is_set() | 判断event的标志是否为True |
【示例】Event事件对象经典用法
#coding:utf-8
#小伙伴们,围着吃火锅,当菜上齐了,请客的主人说:开吃!
#于是小伙伴一起动筷子,这种场景如何实现
import threading
import time
def chihuoguo(name):#等待事件,进入等待阻塞状态print(f'{name}已经启动')print(f'小伙伴{name}已经进入就餐状态!')time.sleep(1)event.wait()# 收到事件后进入运行状态print(f'{name}收到通知了.' )print(f'小伙伴{name}开始吃咯!')
if __name__ == '__main__':event = threading.Event()# 创建新线程thread1 = threading.Thread(target=chihuoguo, args=("tom", ))thread2 = threading.Thread(target=chihuoguo, args=("cherry", ))# 开启线程thread1.start()thread2.start()
time.sleep(10)# 发送事件通知print('---->>>主线程通知小伙伴开吃咯!')event.set()
'''
执行结果:
tom已经启动
小伙伴tom已经进入就餐状态!
cherry已经启动
小伙伴cherry已经进入就餐状态!
---->>>主线程通知小伙伴开吃咯!
tom收到通知了.
小伙伴tom开始吃咯!
cherry收到通知了.
小伙伴cherry开始吃咯!
'''
线程_生产者消费者模式
多线程环境下,我们经常需要多个线程的并发和协作。这个时候,就需要了解一个重要的多线程并发协作模型“生产者/消费者模式”。
什么是生产者?
生产者指的是负责生产数据的模块(这里模块可能是:方法、对象、线程、进程)。
什么是消费者?
消费者指的是负责处理数据的模块(这里模块可能是:方法、对象、线程、进程)
什么是缓冲区?
消费者不能直接使用生产者的数据,它们之间有个“缓冲区”。生产者将生产好的数据放入“缓冲区”,消费者从“缓冲区”拿要处理的数据。
缓冲区是实现并发的核心,缓冲区的设置有3个好处:
- 实现线程的并发协作
有了缓冲区以后,生产者线程只需要往缓冲区里面放置数据,而不需要管消费者消费的情况;同样,消费者只需要从缓冲区拿数据处理即可,也不需要管生产者生产的情况。 这样,就从逻辑上实现了“生产者线程”和“消费者线程”的分离。
- 解耦了生产者和消费者
生产者不需要和消费者直接打交道
- 解决忙闲不均,提高效率
生产者生产数据慢时,缓冲区仍有数据,不影响消费者消费;消费者处理数据慢时,生产者仍然可以继续往缓冲区里面放置数据
缓冲区和queue对象
从一个线程向另一个线程发送数据最安全的方式可能就是使用 queue 库中的队列了。创建一个被多个线程共享的 Queue 对象,这些线程通过使用 put() 和 get()操作来向队列中添加或者删除元素。Queue 对象已经包含了必要的锁,所以你可以通过它在多个线程间多安全地共享数据。
【示例】生产者消费者模式典型代码
#coding=utf-8
from queue import Queue
from threading import Thread
from time import sleep
def producer():num = 1while True:if queue.qsize() < 5:print(f'生产:{num}号,大馒头')queue.put(f'大馒头:{num}号')num += 1else:print('馒头框满了,等待来人消费啊!')sleep(1)
def consumer():while True:print(f'获取馒头:{queue.get()}')sleep(1)
if __name__ == '__main__':queue = Queue()t = Thread(target=producer)t.start()c = Thread(target=consumer)c.start()c2 = Thread(target=consumer)c2.start()
'''
执行结果:
生产:1号,大馒头
获取馒头:大馒头:1号
生产:2号,大馒头
获取馒头:大馒头:2号
生产:3号,大馒头
获取馒头:大馒头:3号
生产:4号,大馒头
获取馒头:大馒头:4号
...
'''
进程_方法模式创建进程_windows多进程的一个bug
进程Process
进程(Process):拥有自己独立的堆和栈,既不共享堆,也不共享栈,进程由操作系统调度;进程切换需要的资源很最大,效率低。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
进程的优缺点
进程的优点:
- 可以使用计算机多核,进行任务的并行执行,提高执行效率
- 运行不受其他进程影响,创建方便
- 空间独立,数据安全
进程的缺点:
- 进程的创建和删除消耗的系统资源较多
进程的创建方式(方法模式)
Python的标准库提供了个模块:multiprocessing
进程的创建可以通过分为两种方式:
1. 方法包装
2. 类包装
创建进程后,使用start()启动进程
【示例】方法模式创建进程
#coding=utf-8
# 方法包装-多进程实现
from multiprocessing import Process
import os
from time import sleep
def func1(name):print("当前进程ID:",os.getpid())print("父进程ID:",os.getppid())print(f"Process:{name} start")sleep(3)print(f"Process:{name} end")
'''
这是一个关于windows上多进程实现的bug。
在windows上,子进程会自动import启动它的这个文件,而在import的时候是会自动执行这些语句的。
如果不加__main__限制的话,就会无限递归创建子进程,进而报错。
于是import的时候使用 __name__ =="__main__" 保护起来就可以了。
'''
if __name__ =="__main__":print("当前进程ID:",os.getpid())# 创建进程p1 = Process(target=func1, args=('p1',))p2 = Process(target=func1, args=('p2',))p1.start()p2.start()
进程_类模式创建进程
进程的创建方式(继承Process类)
和使用Thread 类创建子线程的方式非常类似,使用 Process 类创建实例化对象,其本质是调用该类的构造方法创建新进程。Process 类的构造方法格式如下:
def __init__(self,group=None,target=None,name=None,args=(),kwargs={})
其中,各个参数的含义为:
group:该参数未进行实现,不需要传参;
target:为新建进程指定执行任务,也就是指定一个函数;
name:为新建进程设置名称;
args:为 target 参数指定的参数传递非关键字参数;
kwargs:为 target 参数指定的参数传递关键字参数。
【示例】类的方式创建进程
# 类的方式-多进程实现
from multiprocessing import Process
from time import sleep
class MyProcess(Process):def __init__(self, name):Process.__init__(self)self.name = name
def run(self):print(f"Process:{self.name} start")sleep(3)print(f"Process:{self.name} end")
if __name__ == "__main__":#创建进程p1 = MyProcess("p1")p2 = MyProcess("p2")p1.start()p2.start()
进程_Queue实现进程通信
前面讲解了使用 Queue 模块中的 Queue 类实现线程间通信,但要实现进程间通信,需要使用 multiprocessing 模块中的 Queue 类。
简单的理解 Queue 实现进程间通信的方式,就是使用了操作系统给开辟的一个队列空间,各个进程可以把数据放到该队列中,当然也可以从队列中把自己需要的信息取走。
【示例】使用Queue实现进程间通信的经典代码
from multiprocessing import Process,Queue
class MyProcess(Process):def __init__(self,name,mq):Process.__init__(self)self.name = nameself.mq = mqdef run(self):print("Process:{} start".format(self.name))print('--------------',self.mq.get(),'-------------')self.mq.put(self.name)print("Process:{} end".format(self.name))
if __name__ == '__main__':# 创建进程列表t_list = []mq = Queue()mq.put('1')mq.put('2')mq.put('3')# 循环创建进程for i in range(3):t = MyProcess('p{}'.format(i),mq)t.start()t_list.append(t)# 等待进程结束for t in t_list:t.join()print(mq.get())print(mq.get())print(mq.get())
进程_Pipe管道实现进程通信
Pipe实现进程间通信
Pipe 直译过来的意思是“管”或“管道”,和实际生活中的管(管道)是非常类似的。
Pipe方法返回(conn1, conn2)代表一个管道的两个端。
Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个参数是全双工模式,也就是说conn1和conn2均可收发。若duplex为False,conn1只负责接收消息,conn2只负责发送消息。send和recv方法分别是发送和接受消息的方法。例如,在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。如果管道已经被关闭,那么recv方法会抛出EOFError。
【示例】使用Pipe管道实现进程间通信
#coding=utf-8
import multiprocessing
from time import sleep
def func1(conn1):sub_info = "Hello!"print(f"进程1--{multiprocessing.current_process().pid}发送数据:{sub_info}")sleep(1)conn1.send(sub_info)print(f"来自进程2:{conn1.recv()}")sleep(1)
def func2(conn2):sub_info = "你好!"print(f"进程2--{multiprocessing.current_process().pid}发送数据:{sub_info}")sleep(1)conn2.send(sub_info)print(f"来自进程1:{conn2.recv()}")sleep(1)
if __name__ == '__main__':#创建管道conn1,conn2 = multiprocessing.Pipe()# 创建子进程process1 = multiprocessing.Process(target=func1,args=(conn1,))process2 = multiprocessing.Process(target=func2,args=(conn2,))# 启动子进程process1.start()process2.start()
'''
执行结果:
进程1--14828发送数据:Hello!
进程2--19300发送数据:你好!
来自进程1:Hello!
来自进程2:你好!
'''
进程_Manager管理器实现进程通信
管理器提供了一种创建共享数据的方法,从而可以在不同进程中共享。
【示例】管理器Manager实现进程通信
#coding=utf-8
from multiprocessing import Process,current_process
from multiprocessing import Manager
def func(name,m_list,m_dict):m_dict['name'] = '尚学堂'm_list.append('你好')
if __name__ == "__main__":with Manager() as mgr:m_list = mgr.list()m_dict = mgr.dict()m_list.append('Hello!!')#两个进程不能直接互相使用对象,需要互相传递p1 = Process(target=func,args=('p1',m_list,m_dict))p1.start()p1.join() #等p1进程结束,主进程继续执行print(m_list)print(m_dict)
进程_进程池管理进程
进程池(Pool)
Python提供了更好的管理多个进程的方式,就是使用进程池。
进程池可以提供指定数量的进程给用户使用,即当有新的请求提交到进程池中时,如果池未满,则会创建一个新的进程用来执行该请求;反之,如果池中的进程数已经达到规定最大值,那么该请求就会等待,只要池中有进程空闲下来,该请求就能得到执行。
使用进程池的优点:
- 提高效率,节省开辟进程和开辟内存空间的时间及销毁进程的时间
- 节省内存空间
| 类/方法 | 功能 | 参数 |
|---|---|---|
Pool(processes) | 创建进程池对象 | processes表示进程池中有多少进程 |
pool.apply_async(func,args,kwds) | 异步执行 ;将事件放入到进程池队列 | func 事件函数 args 以元组形式给func传参kwds 以字典形式给func传参 返回值:返回一个代表进程池事件的对象,通过返回值的get方法可以得到事件函数的返回值 |
pool.apply(func,args,kwds) | 同步执行;将事件放入到进程池队列 | func 事件函数 args 以元组形式给func传参 kwds 以字典形式给func传参 |
pool.close() | 关闭进程池 | |
pool.join() | 回收进程池 | |
pool.map(func,iter) | 类似于python的map函数,将要做的事件放入进程池 | func 要执行的函数 iter 迭代对象 |
【示例】进程池使用案例
#coding=utf-8
from multiprocessing import Pool
import os
from time import sleep
def func1(name):print(f"当前进程的ID:{os.getpid()},{name}")sleep(2)return name
def func2(args):print(args)
if __name__ == "__main__":pool = Pool(5)
pool.apply_async(func = func1,args=('qxy1',),callback=func2)pool.apply_async(func = func1,args=('qxy2',),callback=func2)pool.apply_async(func = func1,args=('qxy3',),callback=func2)pool.apply_async(func = func1,args=('qxy4',))pool.apply_async(func = func1,args=('qxy5',))pool.apply_async(func = func1,args=('qxy6',))pool.apply_async(func = func1,args=('qxy7',))pool.apply_async(func = func1,args=('qxy8',))
pool.close()pool.join()
【示例】使用with管理进程池
#coding=utf-8
from multiprocessing import Pool
import os
from time import sleep
def func1(name):print(f"当前进程的ID:{os.getpid()},{name}")sleep(2)return name
if __name__ == "__main__":with Pool(5) as pool:args = pool.map(func1,('qxy1,','qxy2,','qxy3,','qxy4,','qxy5,','qxy6,','qxy7,','qxy8,'))for a in args:print(a)
协程_核心概念_面试
协程,Coroutines,也叫作纤程(Fiber)
协程,全称是“协同程序”,用来实现任务协作。是一种在线程中,比线程更加轻量级的存在,由程序员自己写程序来管理。
当出现IO阻塞时,CPU一直等待IO返回,处于空转状态。这时候用协程,可以执行其他任务。当IO返回结果后,再回来处理数据。充分利用了IO等待的时间,提高了效率。
协程的核心(控制流的让出和恢复)
- 每个协程有自己的执行栈,可以保存自己的执行现场
- 可以由用户程序按需创建协程(比如:遇到io操作)
- 协程“主动让出(yield)”执行权时候,会保存执行现场(保存中断时的寄存器上下文和栈),然后切换到其他协程
- 协程恢复执行(resume)时,根据之前保存的执行现场恢复到中断前的状态,继续执行,这样就通过协程实现了轻量的由用户态调度的多任务模型
协程和多线程比较
比如,有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
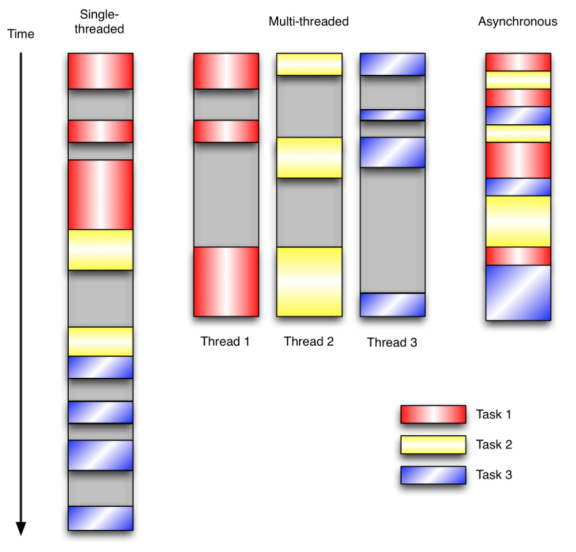
- 在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。
- 多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。
- 协程版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。
协程的优点
- 由于自身带有上下文和栈,无需线程上下文切换的开销,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级;
- 无需原子操作的锁定及同步的开销;
- 方便切换控制流,简化编程模型
- 单线程内就可以实现并发的效果,最大限度地利用cpu,且可扩展性高,成本低(注:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理)
asyncio协程是写爬虫比较好的方式。比多线程和多进程都好. 开辟新的线程和进程是非常耗时的。
协程的缺点
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上。
- 当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
协程_yield方式实现(此方式已经淘汰)
Python中的协程经历了很长的一段发展历程。其大概经历了如下三个阶段:
- 最初的生成器变形
yield/send - 引入
@asyncio.coroutine和yield from - Python3.5版本后,引入
async/await关键字
【示例】不使用协程执行多个任务
#coding=utf-8
import time
def func1():for i in range(3):print(f'北京:第{i}次打印啦')time.sleep(1)return "func1执行完毕"
def func2():for k in range(3):print(f'上海:第{k}次打印了' )time.sleep(1)return "func2执行完毕"
def main():func1()func2()
if __name__ == '__main__':start_time = time.time()main()end_time = time.time()print(f"耗时{end_time-start_time}") #不使用协程,耗时6秒
【示例】使用yield协程,实现任务切换
#coding=utf-8
import time
def func1():for i in range(3):print(f'北京:第{i}次打印啦')yield # 只要方法包含了yield,就变成一个生成器time.sleep(1)
def func2():g = func1() #func1是一个生成器,func1()就不会直接调用,需要通过next()或for循环调用print(type(g))for k in range(3):print(f'上海:第{k}次打印了' )next(g) #继续执行func1的代码time.sleep(1)
#有了yield,我们实现了两个任务的切换+保存状态
start_time = time.time()
func2()
end_time = time.time()
print(f"耗时{end_time-start_time}") #耗时5.0秒,效率差别不大
基于yield并发执行,多任务之间来回切换,这就是个简单的协程的体现,但是他能够节省I/O时间吗?不能。
协程_syncio异步IO实现协程
- 正常的函数执行时是不会中断的,所以你要写一个能够中断的函数,就需要加
async async用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是sleep(5))消失后,也就是5秒到了再回来执行await用来用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序。asyncio是python3.5之后的协程模块,是python实现并发重要的包,这个包使用事件循环驱动实现并发。
【示例】不使用asncio的任务切换
#coding=utf-8
import time
def func1():for i in range(3):print(f'北京:第{i}次打印啦')time.sleep(1)return "func1执行完毕"
def func2():for k in range(3):print(f'上海:第{k}次打印了' )time.sleep(1)return "func2执行完毕"
def main():func1()func2()
if __name__ == '__main__':start_time = time.time()main()end_time = time.time()print(f"耗时{end_time-start_time}") #不使用协程,耗时6秒使用asyncio,整体执行完,耗时3秒,效率极大提高。
【示例】asyncio异步IO的典型使用方式
#coding=utf-8
import asyncio
import time
async def func1(): #async表示方法是异步的for i in range(3):print(f'北京:第{i}次打印啦')await asyncio.sleep(1)return "func1执行完毕"
async def func2():for k in range(3):print(f'上海:第{k}次打印了' )await asyncio.sleep(1)return "func2执行完毕"
async def main():res = await asyncio.gather(func1(), func2())#await异步执行func1方法#返回值为函数的返回值列表,本例为["func1执行完毕", "func2执行完毕"]print(res)
if __name__ == '__main__':start_time = time.time()asyncio.run(main())end_time = time.time()print(f"耗时{end_time-start_time}") #耗时3秒,效率极大提高



![[实验报告]--基于端口安全](https://img-blog.csdnimg.cn/direct/3b30119c7ac04c6998694267ad8441fd.png)