文章目录
- 1. HTTP协议简介
- 2. Fiddler简介(抓包工具)
- 2.1 安装Fiddler
- 2.2 使用Fiddler进行抓包
- 2.3 Fiddler的工作原理
- 3. HTTP协议的报文格式
- 4. HTTP 请求
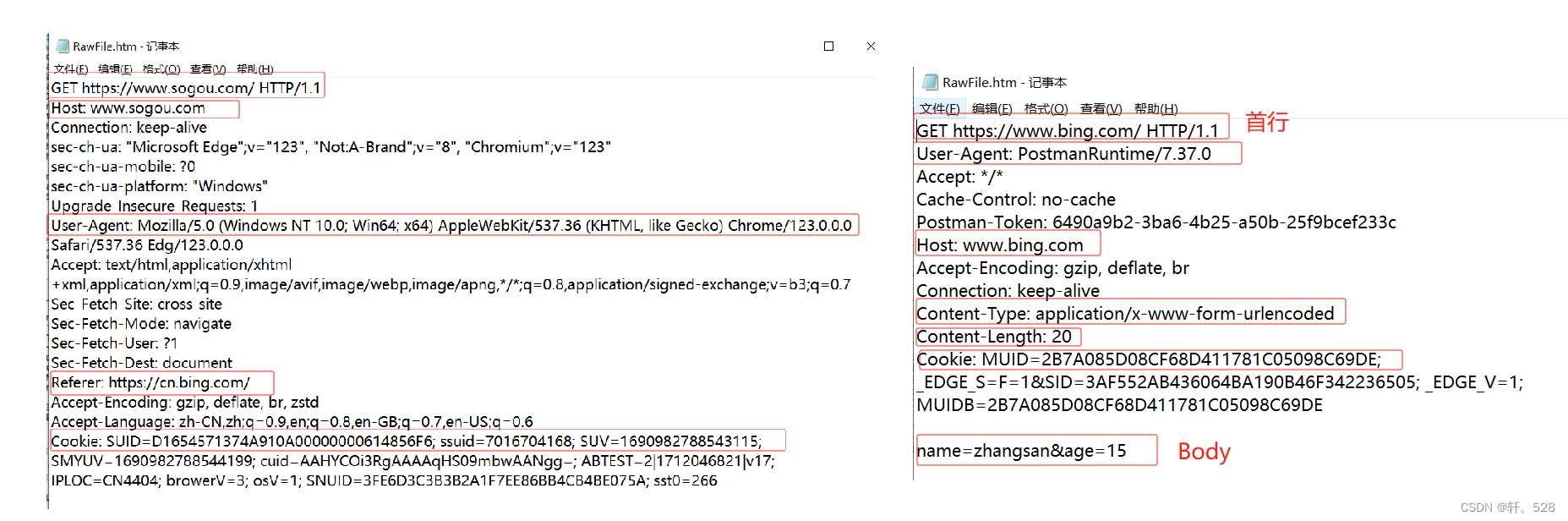
- 4.1 HTTP请求首行
- 4.2 认识 URL
- 关于 URL encoding
- 4.3 认识“方法”
- GET方法
- POST方法
- GET和POST的区别
- 关于 GET 请求传递的数据量有上限,POST 没有上限(×)
- 关于GET请求传递数据不安全,POST请求是安全的(×)
- 关于GET请求只能传输文本数据,POST请求能够传输文本数据和二进制数据(×)
- 关于GET请求是幂等的,POST请求不是幂等的。
- 关于GET请求可以浏览器缓存,POST请求不可以
- 4.4 HTTP请求头部(Header)
- 5. HHTP响应
- 5.1 HTTP响应首行
- 5.2 认识“状态码”
- 5.3 HTTP响应头部(Header)
前言:
本文是对 TCP/IP协议栈中 应用层中的重要协议——HTTP协议的介绍和部分细节的详细说明。
1. HTTP协议简介
什么是 HTTP 协议?
HTTP 协议全称为“超文本传输协议”,超文本传输协议顾名思义即能够传输的数据不仅仅局限于文本内容,还能传输图片、音视频、文档文件等。HTTP协议的应用场景十分广泛,比如:使用浏览器访问网页、通过网络上传/下载文件、视频或音频等多媒体数据的的实时传输等。
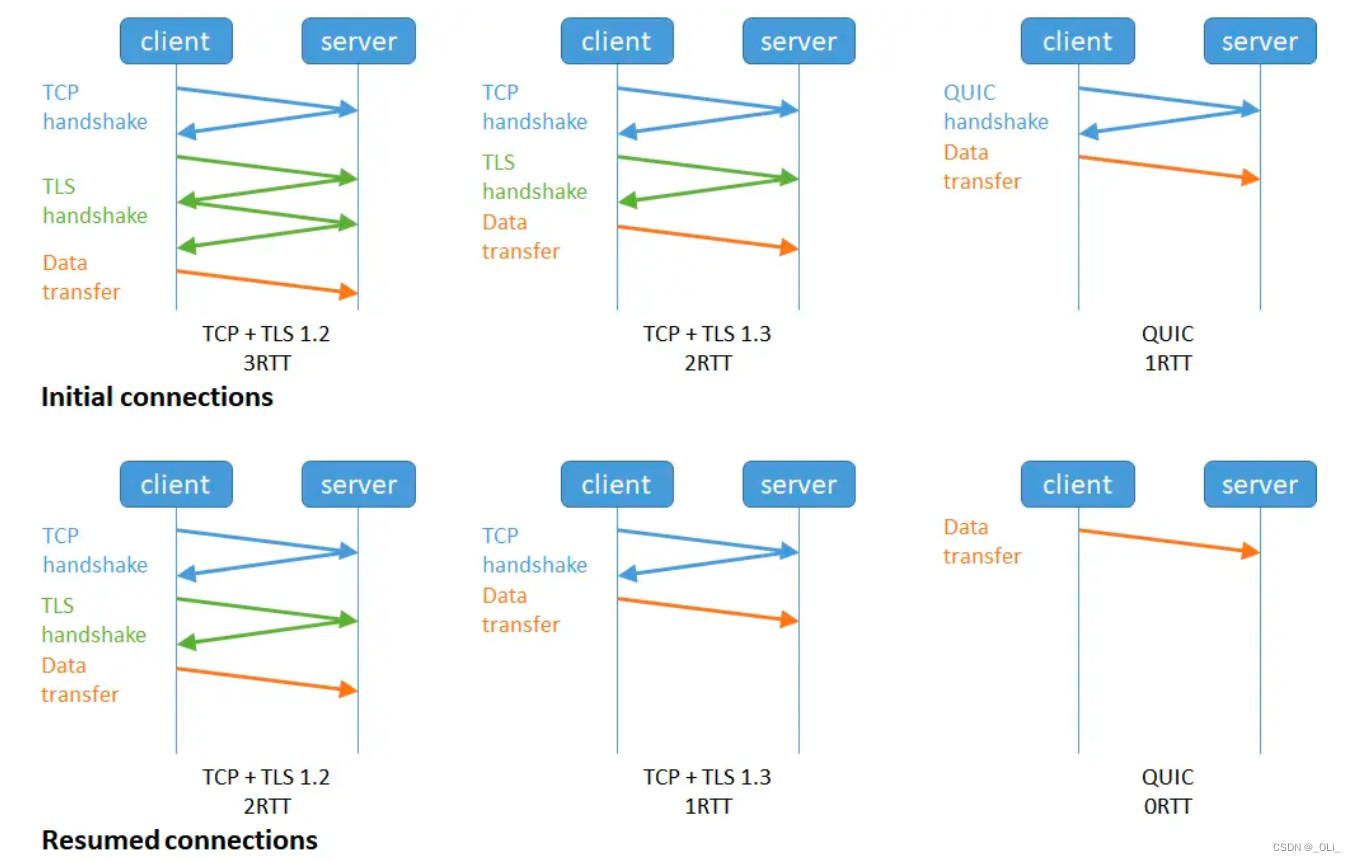
HTTP协议有很多种实现的版本,如:HTTP/0.9、HTTP/1.0和HTTP/1.1、HTTP/2.0、HTTP/3.0。其中HTTP/1.1和HTTP/2.0为目前流行使用的版本,它们是基于 TCP 协议实现的;而 HTTP/3.0 是基于 UDP 协议实现的。
HTTP协议的核心特点:
- 基于请求/响应模型:即客户端和服务器交互都是基于“一问一答”的形式,通常情况下都是客户端向服务器发起 HTTP请求,服务器根据请求返回对应的响应数据。
- 无状态:即 HTTP 协议自身不会保存上一次请求和响应的状态信息
- 无连接:即限制每一次连接只处理一个请求,当服务器处理完请求且客户端收到响应数据后,HTTP连接会自动断开。
HTTP协议的工作过程:
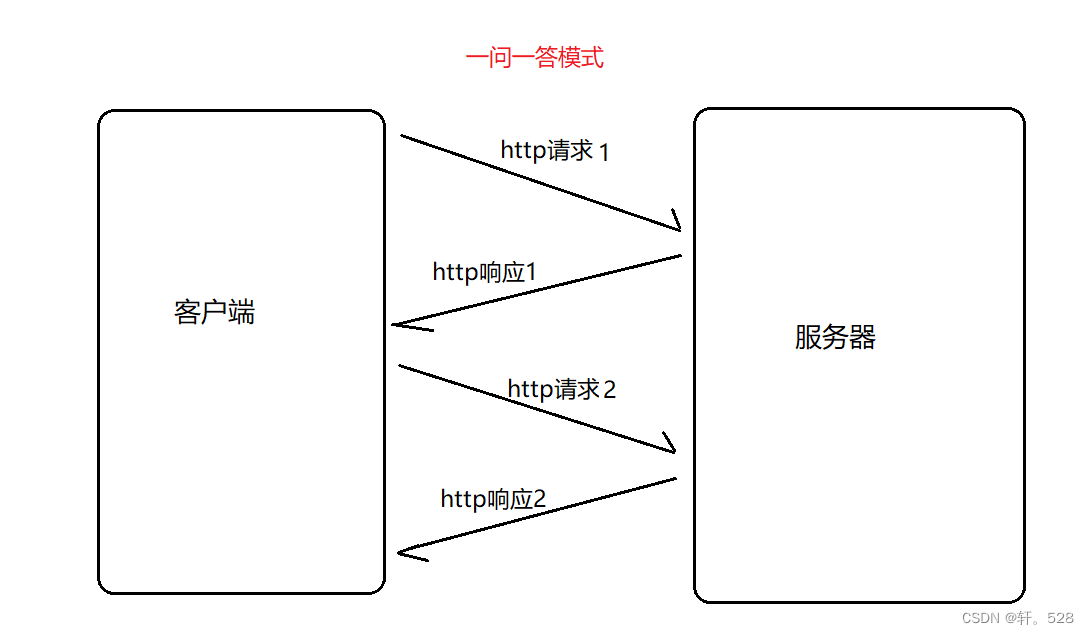
不难发现:HTTP进行数据交互的过程与 TCP 非常相似,都是基于一问一答的形式,但与 TCP 不同的是:作为 HTTP 协议的服务器端只会针对客户端发起的请求作出响应,而不会主动给客户端发送数据。
2. Fiddler简介(抓包工具)
要想真正理解 HTTP 协议,我们需要了解 HTTP 数据包的组成形式的细节;而获取一个 HTTP 数据包也很简单,具体可以分为两个步骤:
(1)通过浏览器发起访问网页(2)使用抓包工具(本质上是一种代理)抓取 HTTP 数据包,常用的抓包工具有:Wireshark、Fiddler等。
2.1 安装Fiddler
相比Fiddler,Wireshark的功能更加强大,能够抓取各种数据包(HTTP、HTTPS、TCP、IP、以太网协议数据包等),但它的使用难度也相对较高;而 Fiddler 只专注于抓取 HTTP或HTTPS 数据包,使用成本也更低。因此,接下来我们都使用 Fiddler 抓取并分析 HTTP数据包。
官网链接:Fiddler官网
安装步骤如下:(一般情况下下载经典版即可)

下载好安装包后,直接安装即可。打开Fiddler后如果出现一个弹窗,直接关闭即可;接下来勾选以下选项,便可抓取 HTTPS 数据包。(HTTPS协议可以理解为对传输数据进行了加密的HTTP协议。)
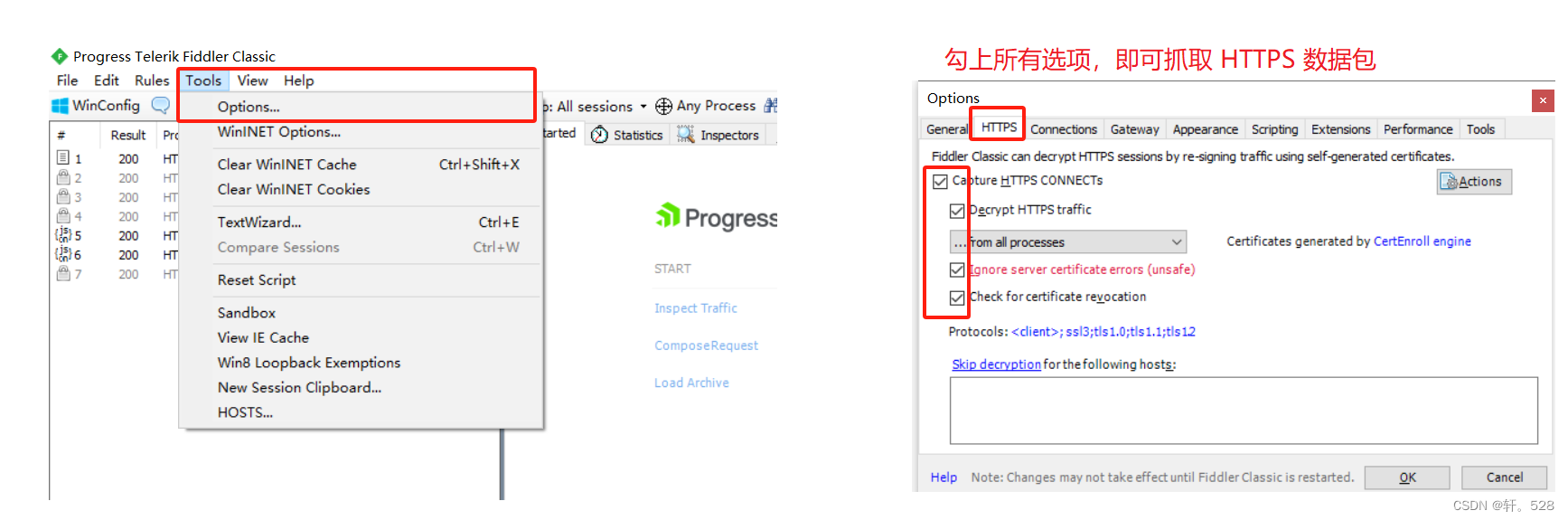
注意:如果在使用过程中出现了以下场景,原因是你的电脑上可能安装了其他的软件,并且它也是一种代理,与Fiddler会产生冲突,如果想要重新抓包,直接点击黄色警告即可。

2.2 使用Fiddler进行抓包
Fiddler使用快捷键:ctrl + a(选中全部数据包),ctrl + x (清理选中的数据包)。
通常情况下,为了快速找到我们想要抓取的特定数据包,会先进行数据包清理,再发起 HTTP 请求进行数据包抓取。
抓包准备工作:(1)确保 Fiddler 的代理功能被开启(2)清除多余数据包(3)访问任一网页(4)根据访问网页的域名查看对应HTTP数据包
这里以访问 https://cn.bing.com/ 为例。
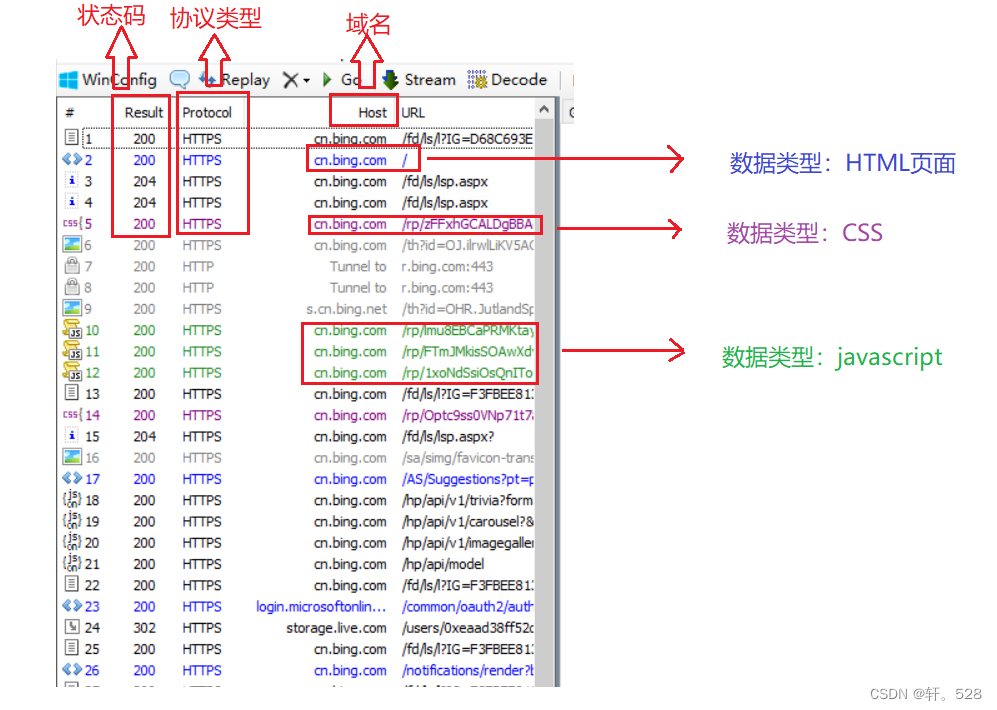
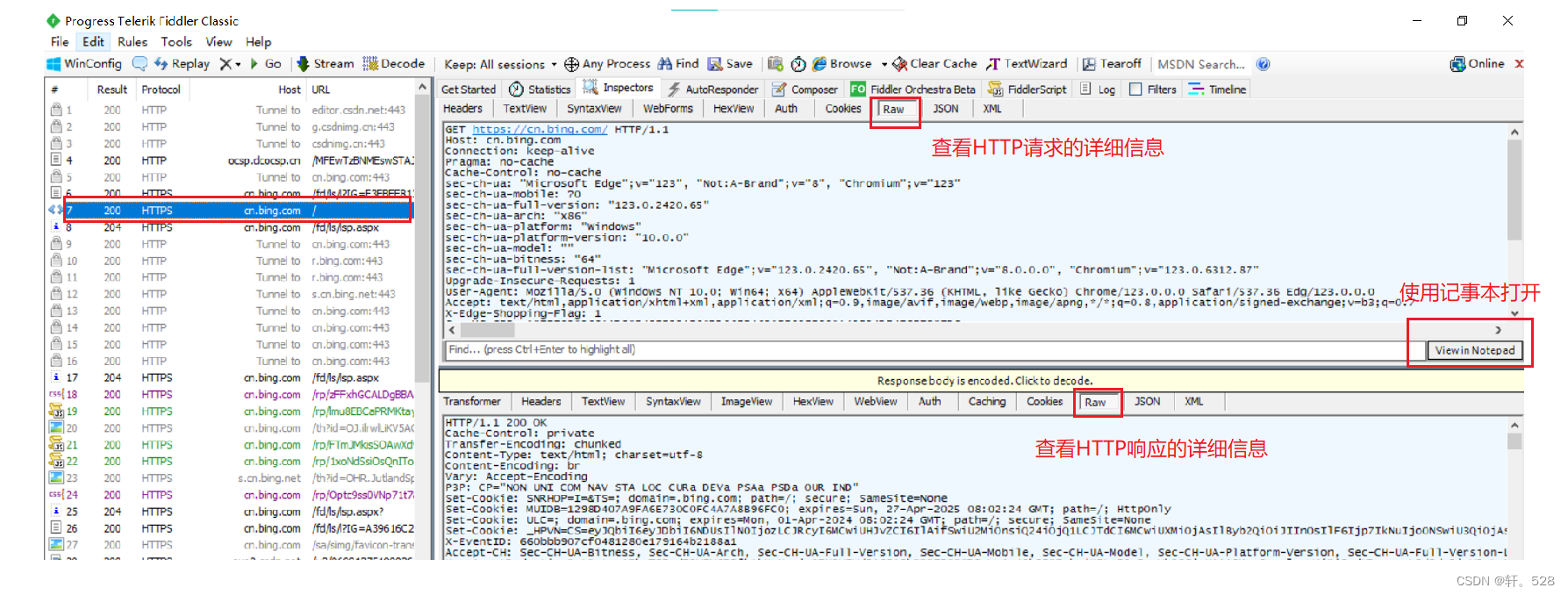
查看 HTTP请求/响应:
2.3 Fiddler的工作原理
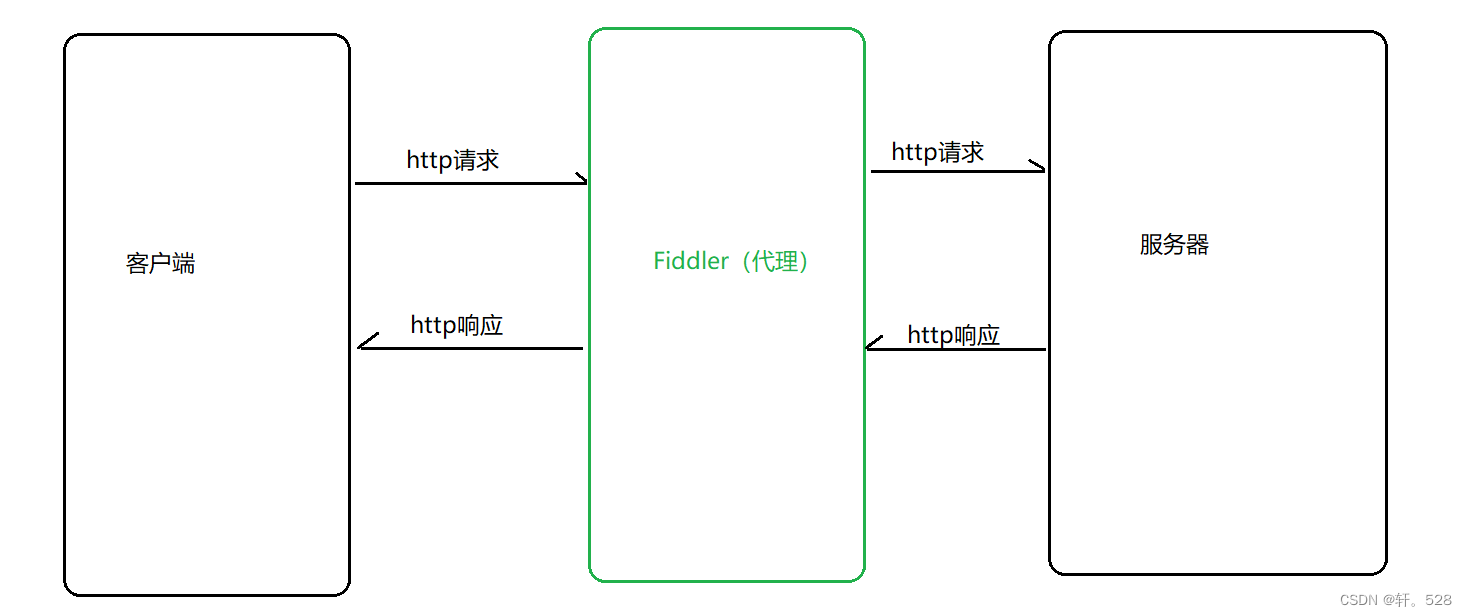
代理:指的是一个服务器(代理服务器),位于客户端与目标服务器之间,为客户端的请求提供中介服务,将客户端的请求转发给目标服务器,再将目标服务器的响应返回给客户端。例如代购,房屋中介等都可视为一个代理。
在上述抓包过程中,Fiddler就充当了一个代理的角色,HTTP请求和响应都由 Fiddler 接收再进行转发,因此它能够获取数据交互的详细信息。
3. HTTP协议的报文格式
通过前面的介绍,我们知道了 HTTP 协议是基于一问一答的方式进行数据的交互,因此了解 HTTP 报文也要站在请求和响应两个角度。
虽然请求和响应的具体内容有一些差别,但它们总体上都由以下几部分构成:
- 首行
- 请求头/响应头(Header,由若干键值对组成)
- 空行(作为header的结束标志)
- 正文(Body)
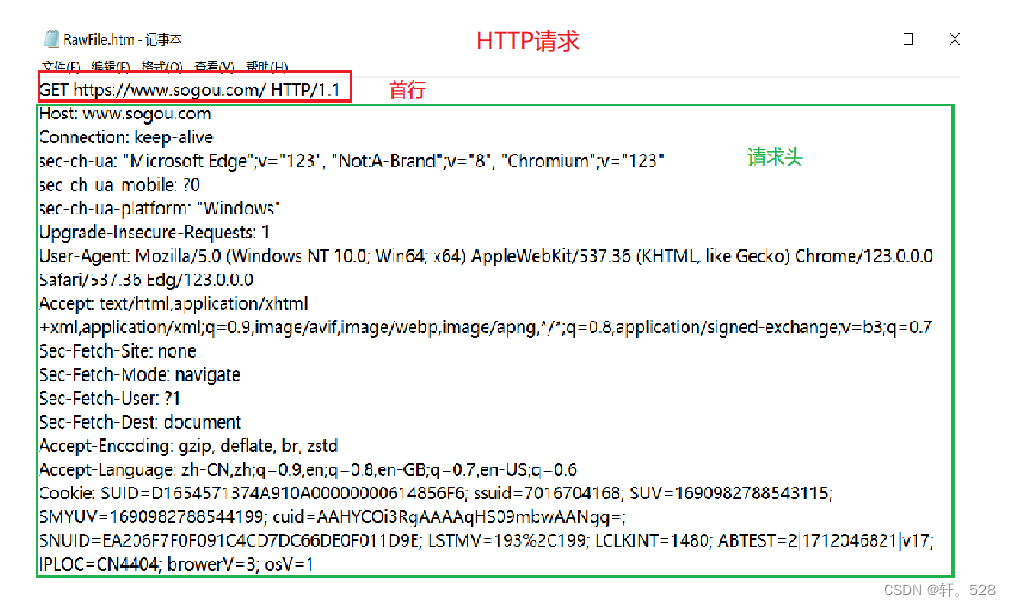
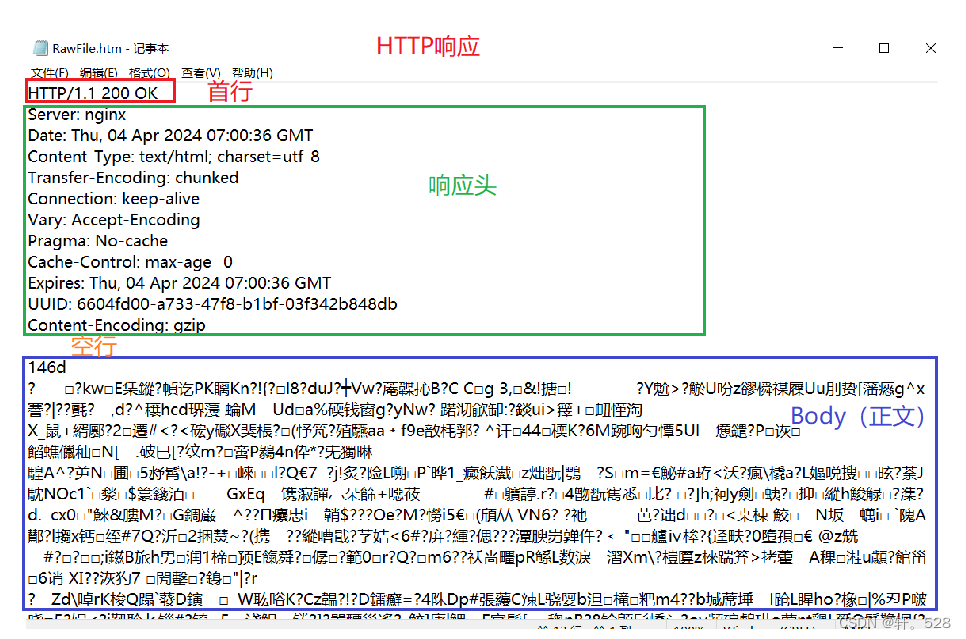
注意:HTTP请求Body部分可能没有数据,而HTTP响应返回的数据通常放在Body中。
4. HTTP 请求
4.1 HTTP请求首行

一个HTTP请求首行通常由以下部分组成:[方法] + [URL] + [http协议版本]
4.2 认识 URL
URL是统一资源定位符(Uniform Resource Locator)的缩写,用于标识和定位互联网上的资源。通俗来讲,URL就是我们平时说的“网址”。
在上面 HTTP 请求的首行中,https://cn.bing.com 即为该 http请求中的URL。(HTTPS 可以理解为将传输数据进行加密后的 HTTP 请求)

注意:
- URL的“登录信息”部分用于验证用户登录状态,现在已基本不再使用,一般可以省略。
- 在某些情况下端口号可以省略,比如一些比较著名的应用层协议都绑定了默认的端口号,如HTTP为80、HTTPS为443端口等。
- 文件路径描述了客户端要访问的服务器的哪个资源。
- 查询字符串(querystring)的作用是对此次请求的细节进行补充,一般由程序员自己定义。
- 在某些情况下,由于网页的内容比较长,可能被分割成为多个片段,而片段标识符就用于完成页面内部的跳转。
关于 URL encoding
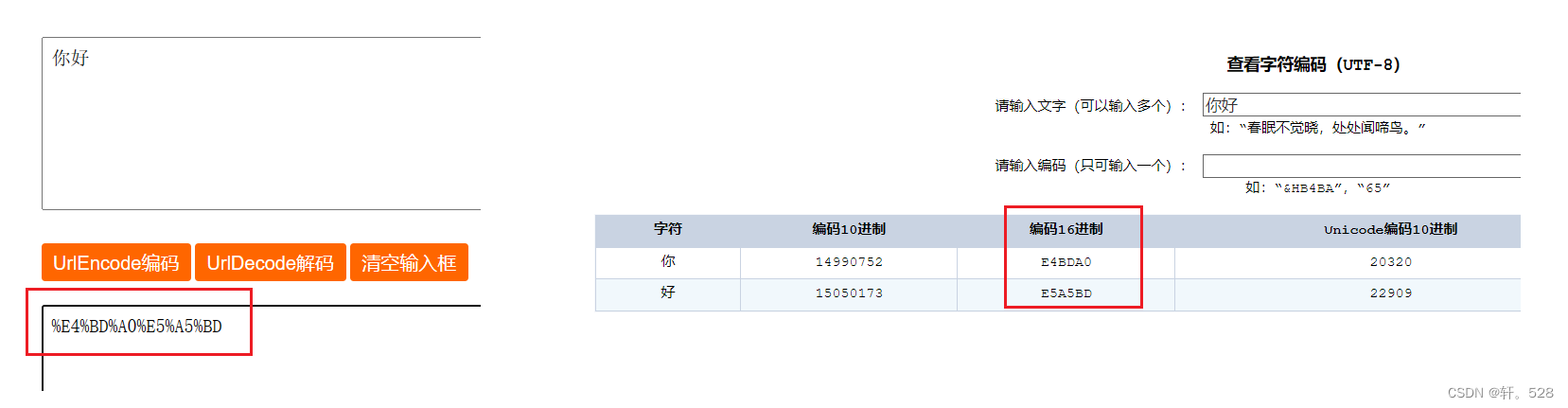
URL encoding(URL编码)又称为百分号编码。它的作用是将某些字符进行转义,使不安全或带有特殊含义的字符在URL中被正确传输。
进行 URL encoding 原因:
- 特殊字符:当querystring中包含中文、空格、或其他特殊符号时,可能会引起解析上的歧义。
- 有特定含义的字符:当querystring中包含 ?# & @ 等在URL中有特定含义的特殊字符时,需要对这些字符进行转义,避免 URL 不能被正确解析。
URL encoding 的规则:
- 对于 ASCII 码字符:将 ASCII 字符转换为 16进制表示,然后后面跟上 %。例如:‘+’ 的 ASCII码10进制表示为32,16进制表示为 20,因此 ‘+’ 在 URL 中被编码为 %20。
- 对于中文等非 ASCII码字符:先将中文转换位 UTF-8 表示的16进制序列,然后在每两位16进制数字前(每个字节)前跟上 %。(如下图)
4.3 认识“方法”
对于每个发起的 HTTP 请求,都带有一个方法用来标识该请求的作用(要想做的事情),常见的方法有 GET、POST、PUT、DELETE等。
需要特别说明的是:HTTP方法只代表了一种约定,并不是一种强制准则,因此现阶段 HTTP 方法的使用早已违背了“设计初心”,基本上由GET 和 POST各占“半壁江山”,其他方法使用的概率非常低。
部分方法说明如下图:

GET方法
GET方法一般用于从指定资源请求数据。触发 HTTP 请求的 GET方法有以下途径:
- 在浏览器地址栏中输入URL或进行相关搜索。
- 点击页面的超链接时。
- HTML页面中引用了图片或Javascript文件等外部资源。
- 通过 From 表单或 Ajax 请求构造 HTTP 请求时,也可以触发 GET 请求。
GET方法的特点:
- GET请求通常被用于获取资源的操作。
- 通常将要传输给服务器的数据放在 URL的 querystring 中,并且 HTTP 请求的 Body 部分一般为空。
- GET请求通常可以被浏览器缓存(即多次访问同一页面时内容可能不变,后续可能不会真正向服务器发起请求)。
- GET请求会被保存浏览器的历史记录中,且可以被收藏为书签。
POST方法
POST方法一般用于发送消息主体。 触发 POST 请求有以下途径:
- 通过 HTML 的From标签发送 POST请求。
- 通过 Javascript的 Ajax 发送POST请求。
POST方法的特点:
- 通过被用于传输消息主体。如提交用户、密码等数据,也可用于上传文件、头像等二进制文件的数据。
- 通常情况下 将要传输的数据放在Body部分,且querystring 为空。
- POST请求不能被缓存。
- POST请求不会被保存在浏览器记录中,且通常情况下不能被收藏为书签(Body部分的数据可能出现丢失)。
GET和POST的区别
先说结论:GET方法和POST方法没有本质上的区别。
原因是 GET和POST方法各自的使用场景理论上是可以互换的,一般谈论GET和POST的区别,可能就是存在使用习惯上的区别。
- 虽然目前 HTTP 协议的方法使用较为混乱,但 GET和POST 这两个方法则是相当明确的。GET一般用来请求数据,POST一般用来提交数据(登录或上传)。
- GET方法一般将传输数据放在querystring中,POST方法一般将数据放在Body中;但这个规则并不是绝对的,在实际操作中,GET方法也可以将数据放在Body中,POST方法也可以将数据放在 querystring中,前提是服务器端也要用对应的方式处理数据。
关于 GET 请求传递的数据量有上限,POST 没有上限(×)
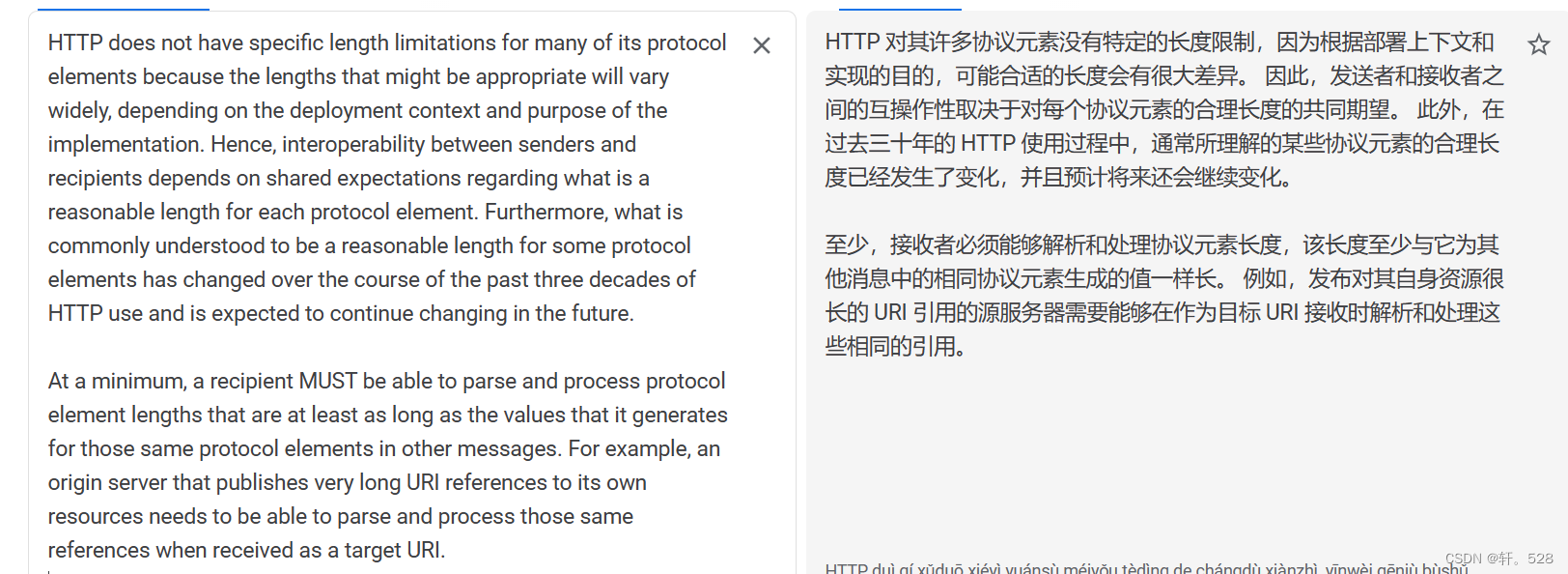
这个说法其实是一个“历史遗留”问题,原因是早期的浏览器硬件资源比较匮乏,因此对 GET 请求中 URL的长度作出了限制,但实际上 RFC标准文档上并没有对 querystring的长度作出明确规定。在目前浏览器和服务器的具体实现中,URL可以非常长,甚至可以传输一张图片这样的数据。

翻译过来的意思如下:
关于GET请求传递数据不安全,POST请求是安全的(×)
这个说法也是错误的。该说法的依据是 GET请求会将数据放在 querystring中,它会将数据暴露在 URL中,可以轻易被别人发现,因此是不安全的;而 POST 请求则将数据放在 Body中,别人不能直接获取到数据内容,因此是安全的。
但在事实上,数据是否被安全传递并不能以数据放在 URL还是 Body作为判断依据。原因是以 POST请求传输的数据虽然在 Body中,但通过前面 Fiddler 抓包可知,HTTP数据包很容易通过代理的方式被他人获取,因此 Body 中的数据也相当是“暴露”的。
在实际网络通信中,数据被安全传输的关键在于对数据进行加密(通过某些加密算法对原始数据进行转换,变成我们肉眼不能直接识别的数据);但即使对数据进行了加密,也不能保证数据一定是安全传输的,原因是再复杂的加密算法存在被破解的可能性,因为网络安全的攻防是一个相对的过程,当可获取的利益大于解密所需的成本时,黑客就可能不惜代价尝试对加密数据进行破解。
关于GET请求只能传输文本数据,POST请求能够传输文本数据和二进制数据(×)
这个说法同样是错误的。原因是 GET请求其实是能够将数据放在 Body中,只是习惯上没有这么使用,因此它也是可以传递二进制数据的。其次,GET请求也可以将二进制数据进行 Base64转码,再将转码后的数据放到 querystring中,同样能够达到传输二进制数据的目的。
关于GET请求是幂等的,POST请求不是幂等的。
幂等:指对同一资源多次连续请求的返回结果与单次请求是相同的。
上述说法前半句的正确性需根据实际情况判断。一般情况下GET请求的实现是幂等的,但也存在非幂等的情况。如在商搜(广告搜索)中,对同一关键词的多次搜索可能返回不同的响应数据。
而对于POST请求,一般用在更新用户信息、验证身份信息、上传文件等场景,这些请求都可能导致资源的状态发生变化,因此POST请求不是幂等的。
关于GET请求可以浏览器缓存,POST请求不可以
能否被浏览器缓存取决于该请求实现是否为幂等的。因此上述说法的正确性也取决于服务器处理请求时的具体实现。
4.4 HTTP请求头部(Header)
HTTP请求header中常见的键值对有:
- Host:表示服务器主机的地址和端口。
- User-Agent:包含了发出请求的客户端的信息,如:客户端操作系统信息,浏览器类型、版本等。
- Content-type:表示HTTP请求Body中的数据格式。常见的数据格式有:application/x-www-form-urlencoded、application/json等。
- Content-Length:表示Body中数据的长度,单位为字节。
- Referer:表示当前页面是从哪个页面跳转过来的。如果页面是通过浏览器直接输入URL或点击收藏夹跳转的,则没有该键值对。
- Cookie:由若干个键值构成,其中cookie可能由服务器生成并返回给客户端,用作下次访问服务器时携带;也可能由客户端生成。
5. HHTP响应
5.1 HTTP响应首行
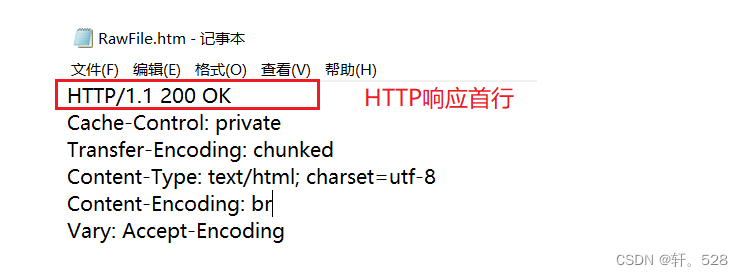
一个HTTP响应首行通常由以下部分组成:[HTTP版本号] + [状态码] + [状态码解释]
5.2 认识“状态码”
状态码:状态码被用来表示访问一个页面的结果。状态码大体上可以分为1xx、2xx、3xx、4xx、5xx这5大类。

常见的状态码有:
1)200(成功)。200是一种最常见的状态码,服务器通常会返回对应请求数据,如一个完整的搜索结果页面。
2)301(资源永久重定向,页面会发生跳转)、302(页面临时重定向)。通常在一个域名过期、资源移动或需进行身份验证时出现。
3)401(要求用户进行身份认证)。当用户进行某些需要登录才被允许的操作时就会返回401,请求通常会在服务器端被拦截。
4)403(资源存在且请求被解析,但被拒绝访问)。出现403的原因可能是权限不足、访问请求被服务器拒绝、IP地址被限制等。
5)404(资源不存在)。出现404也是一种较为常见的错误,出现的常用原因有:URL输入错误、访问资源不存在等。
6)500(服务器内部错误)。
状态码解释:顾名思义,是对当前返回状态码的解释。(各类状态码解释如下,详细原因可参照:菜鸟教程——HTTP状态码)
5.3 HTTP响应头部(Header)
HTTP响应头部大部分内容与请求一致,但响应的Content-type与请求有一些区别,常见的数据格式有:
text/html text/css application/javascript application/json。
以上就是本篇文章的全部内容了,如果这篇文章对你有些许帮助,你的点赞、收藏和评论就是对我最大的支持。
另外,文章可能存在许多不足之处,也希望你可以给我一点小小的建议,我会努力检查并改进。