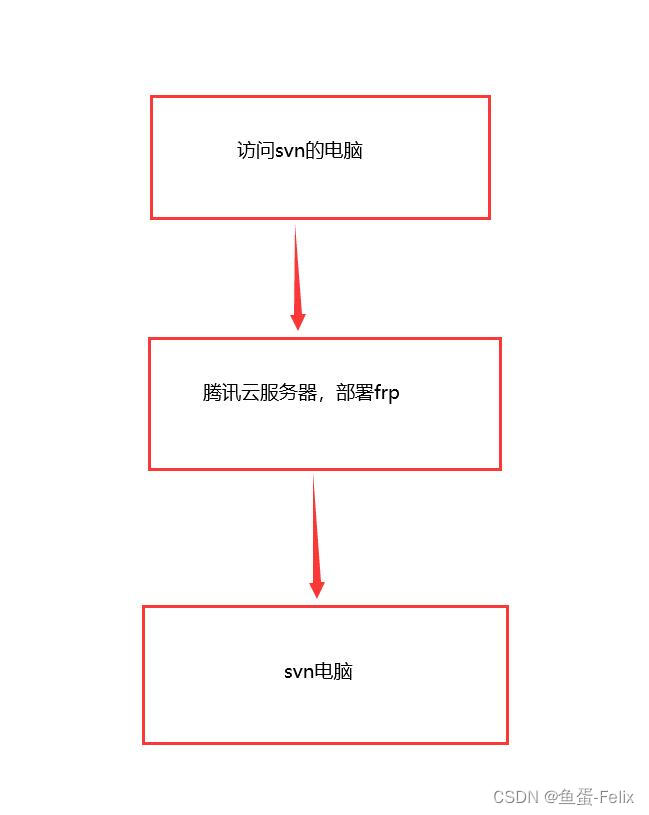
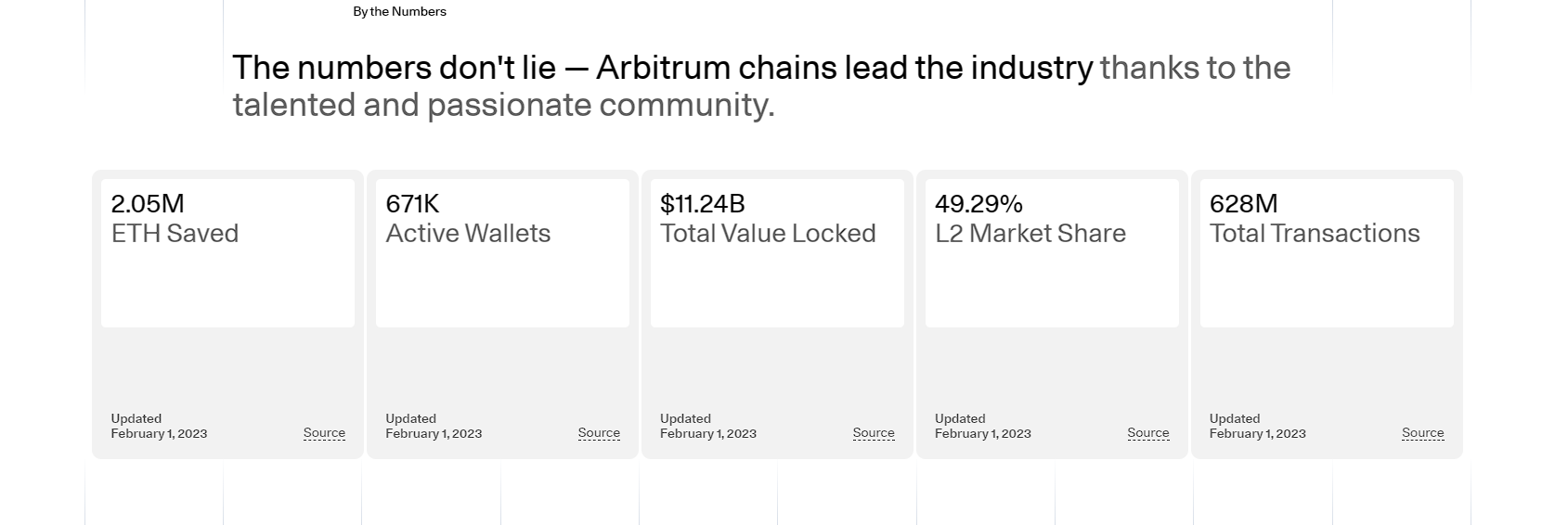
我们在基础IO(一)主要讲述了fd,一切皆文件,文件的系统调用与语言文件库函数的关系,
今天主要进行对重定向与缓冲区的理解与应用。另外,对系统调用的read进行一下使用。
read的使用:
再使用read之前我们先了解一下

我们知道 文件 = 内容 + 属性,那么我们无非是对文件的内容或属性进行操作,这三个函数就是对文件的属性进行操作,获取对应的文件信息,可以更精细的控制read系统调用函数。
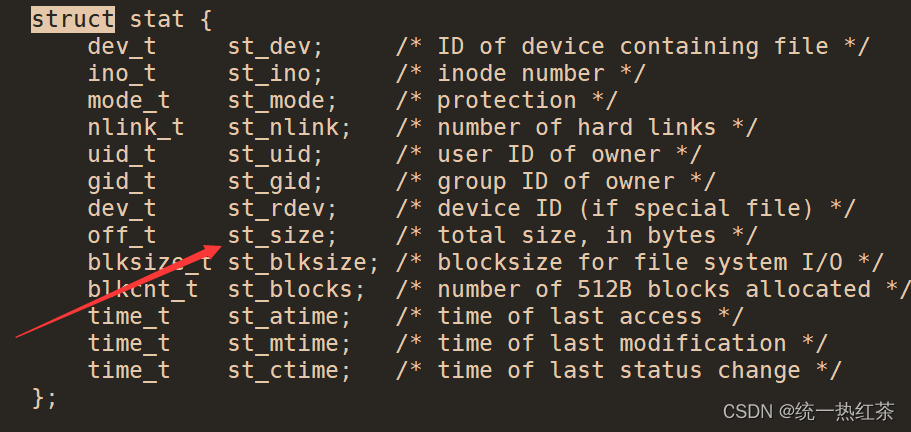
此函数是输出型函数,我们就从可以传入的这个结构体中获得需要的信息(我们在这只需要文件大小)。
我们写个代码验证一下
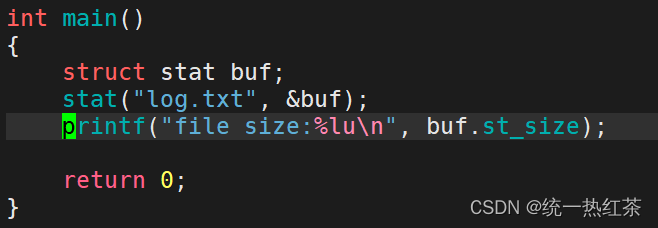
实验结果:
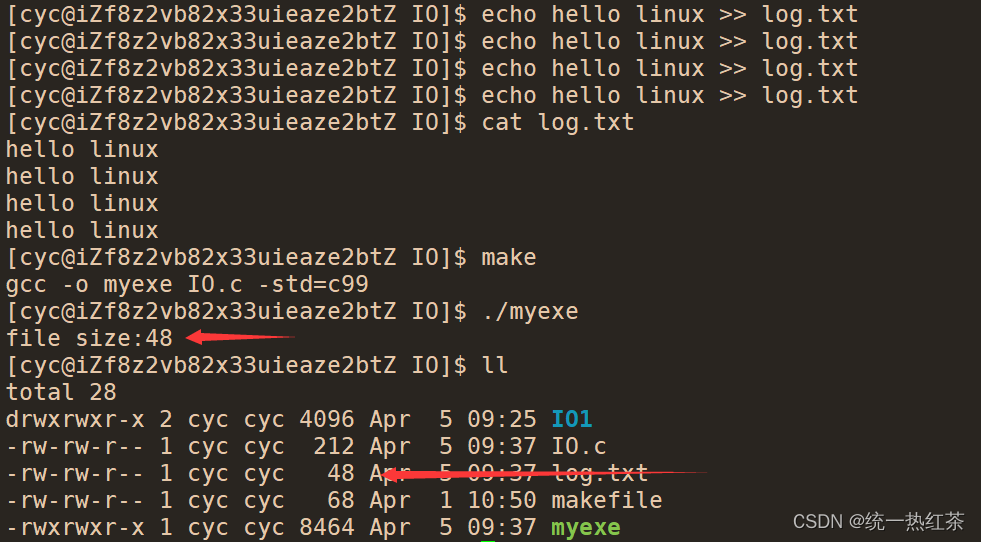
故我们就初步了解了这个函数的用法,接下来我们使用read函数。
先来简单看一下read函数的使用方法:

实验代码:
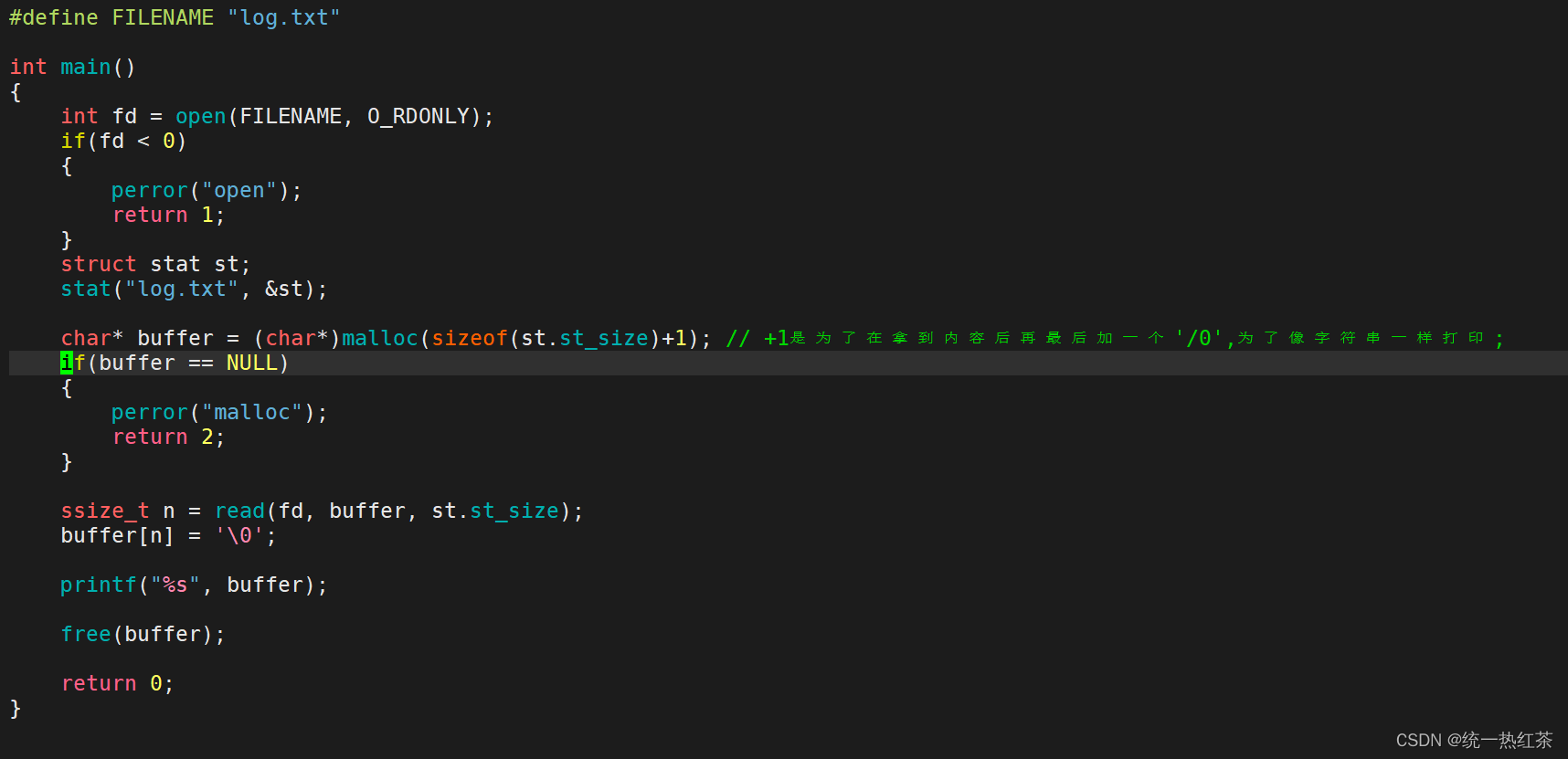
注意:read的返回值是返回读入字符的个数。
初步理解重定向与文件缓冲区
今天的硬菜就来了。
我们先来探讨一下fd的分配规则
先关闭标准输入
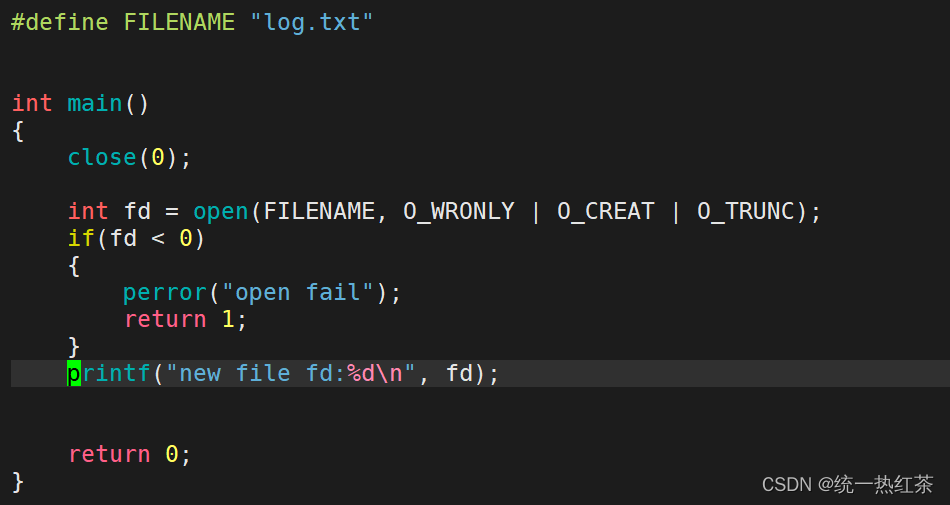
实验结果:

将标准错误关闭的结果:

将标准输出关闭的结果:
什么都没有打印。

于是我们得到一个结论:
文件标识符总是从最小的开始分配。
但是我们肯定困惑一个点,为什么关闭了1之后就不会打印了呢?
我们在代码中多加几行(fprintf与ffulsh)。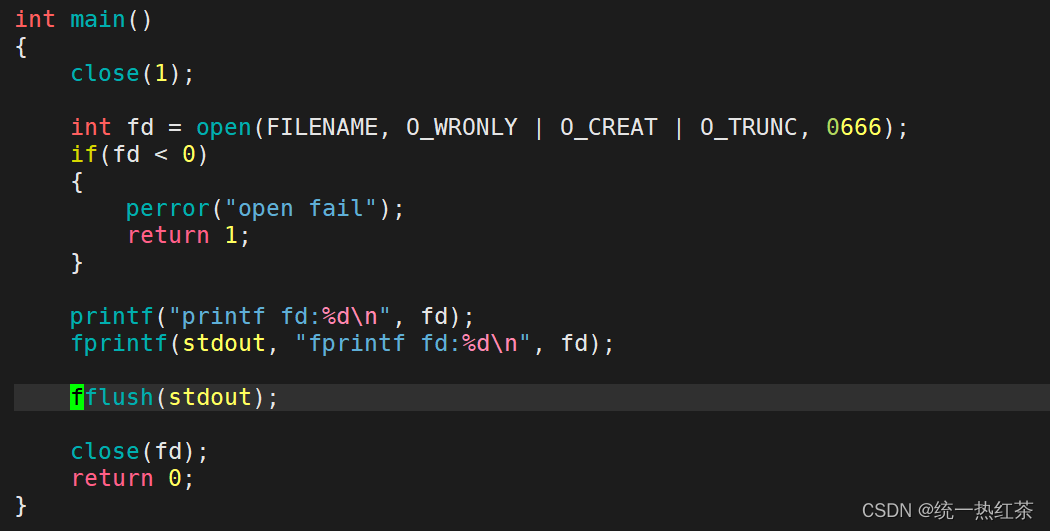

我们运行程序还是没有打印,
但是我们在创建的文件中发现了原本打印在显示器中的文件打印到了文件中。这是为什么呢?
而注释掉fflush,log.txt文件中也什么都没有了,这就涉及到了两个知识点
重定向:
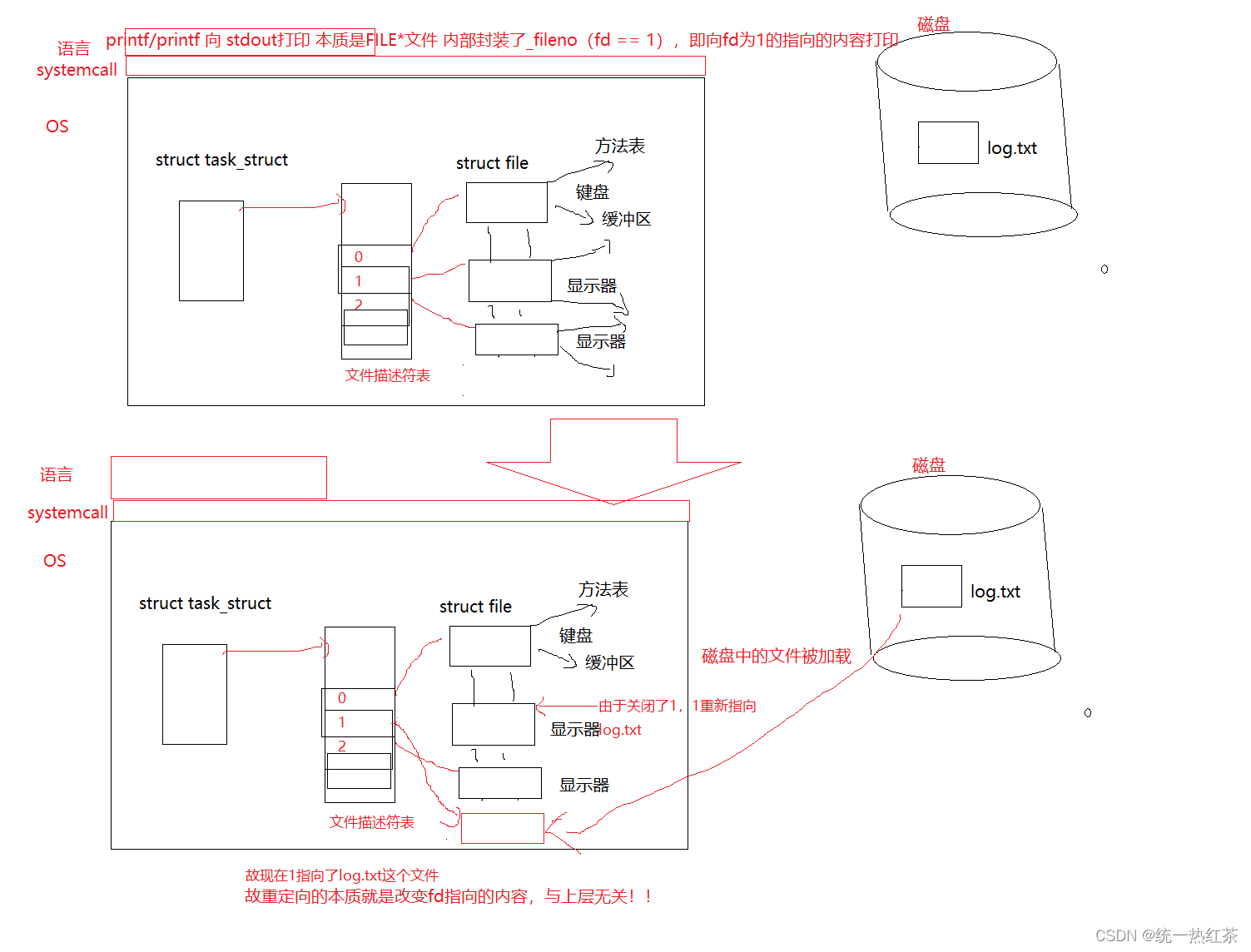
于是我们对重定向有了大概得认识、
缓冲区:
那么FILE内除了_fileno外还有别的吗
答案是还有,还有缓冲区的存在!
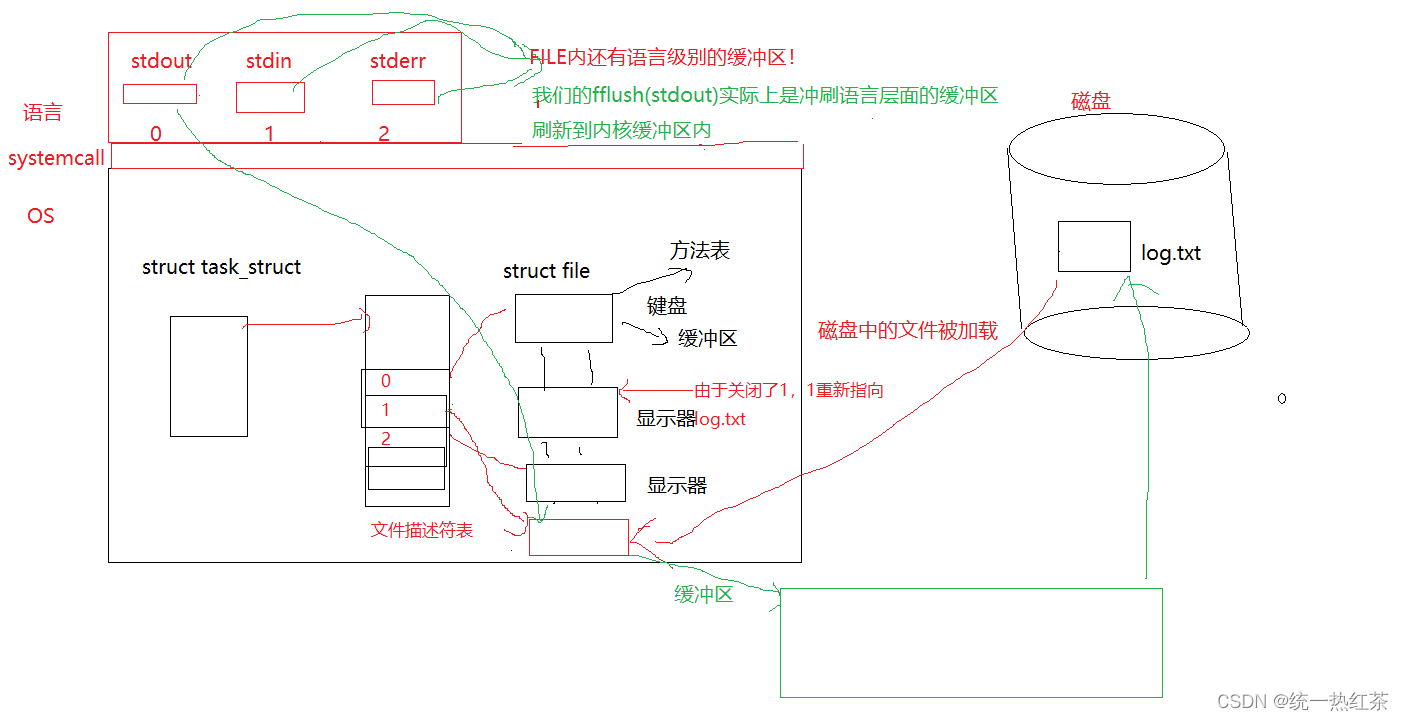
于是我们就可以理解上面的问题了
close(1)后向stdout(1)写入,再fflush,不会打印到显示器而是会打印到新打开的文件中,原因是因为重定向,再刷新语言层的缓冲区。
而如果我们不加fflush就不会刷新是因为,我们的进程在return的时候会先刷新缓冲区等清理工作,而我们在进程return之前先close(1),导致无法向1的内容中写入,缓冲区的内容就会丢失。
再理解重定向与文件缓冲区
重定向
我们上述进行的重定向操作实在是比较粗糙,还要先关闭一个文件再打开一个新的。
那我们不想这样做怎么办?
利用系统调用dup2


这个函数就是进行重定向的函数。经过学习我们也知道并不是两个fd之间的拷贝,而是他们指向的内容进行拷贝。
经过man的描述,我们也知道了dup2的使用方法。
那我们进行使用一下
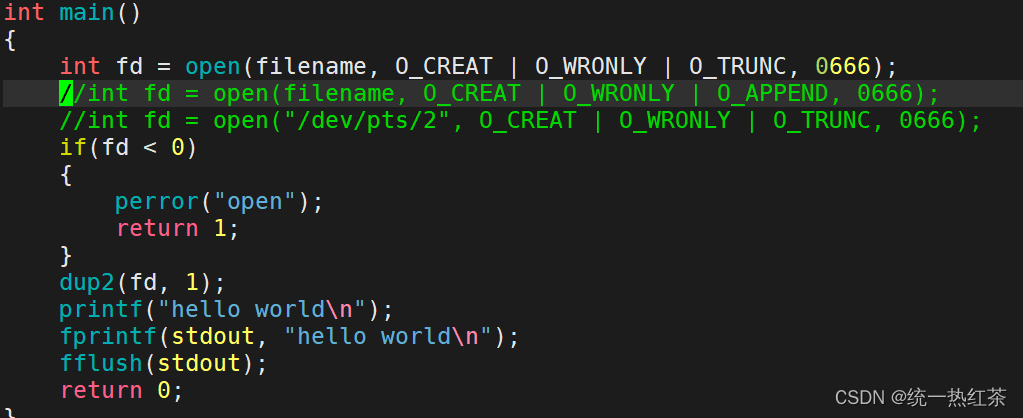
上述操作进行了重定向,因此是向log.txt中进行写入。

事实也确实如此。
缓冲区:
我们现在已经知道两个缓冲区
- 用户级缓冲区
- 内核级缓冲区
那么说了这么久,缓冲区到底有什么存在的意义?
- 解耦
- 提高效率
解耦我们暂时先不谈。
主要谈谈第二点:
我们知道,文件的写入读出本质都是拷贝,那么我们多了一个缓冲区,多拷贝一次效率快岂不是在扯淡?
答案并不是:
- 他可以提高我们使用者的效率,就像你要送一个物品给你的朋友(你在海南他在东北),你是开车去送还是直接顺丰?答案是我们当然选择直接快递,这样提高了我们的效率
- 提高IO效率,我们先输出一个结论,调用系统调用是有成本的,OS这么忙还要配合你,无疑是要加重负担。就像我们寄快递,但是只有你一件快递就要求快递员给你送,还是再多囤一囤再一块送?无疑第二种效率更高
我们总结一下:
缓冲区是什么?
- 一段内存空间。
为什么存在?
- 给上层提供良好的IO体验,提高整体效率
怎么做?
- 刷新策略(针对用户层面):
a.
- 立即刷新,fflush(stdout),fsync(fd)我们暂时还没有用到,刷新内核缓冲区到硬件
- 行刷新,针对显示器
- 全缓冲,缓冲区写满才刷新,普通文件。
b.特殊情况
- 进程退出
- 强制刷新,类似a1
练习
那么我们现在写一段奇怪的代码。
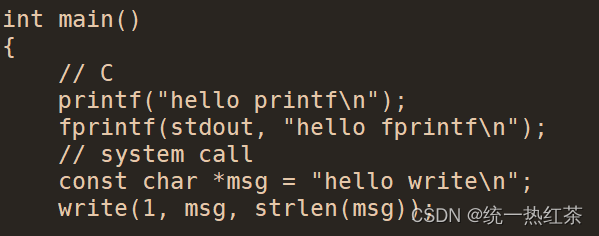
这段代码的现象显而易见。

重定向到log.txt

OK,都没问题
那么我们加一个fork?
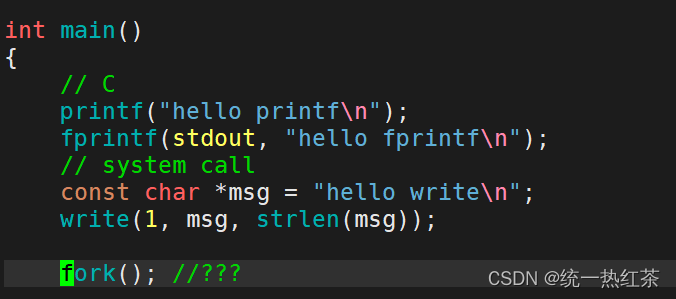

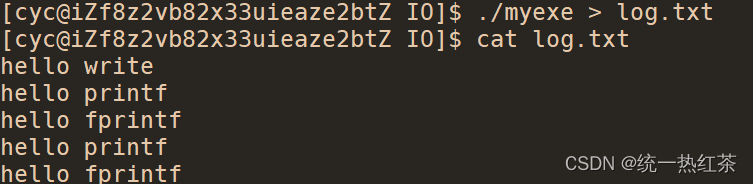
为什么重定向到普通文件中时printf与fprintf会多打印一次?
我们这里要用到刚刚讲过的知识点,
首先我们知道一切的罪魁祸首一定是fork。
其次我们显示器的刷新策略是行刷新,而普通文件是全缓冲。

所以我们就知道了这样的原因:由于策略发生改变,fork后,语言层的缓冲区会写时拷贝,因此多打印一次,而内核的缓冲区再执行刷新操作时不会写时拷贝。
注意的细节:
fork对文件缓冲区的影响:

刷新操作不会发生写时拷贝。

今日IO分享完毕~