在之前的文章中,我们学习了如何在spark中使用键值对中的keys和values,reduceByKey,groupByKey三种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(12)-CSDN博客文章浏览阅读722次,点赞19次,收藏15次。今天开始的文章,我会带给大家如何在spark的中使用我们的键值对方法,今天学习键值对方法中的keys和values,reduceByKey,groupByKey三种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137385224今天的文章开始,我会继续带着大家如何在spark的中使用我们的键值对里的方法。今天学习键值对方法中的fullOuterJoin,zip,combineByKey三种方法。
目录
一、知识回顾
二、键值对方法
1.fullOuterJoin
2.zip
3.combineByKey
拓展-方法参数设置
一、知识回顾
上一篇文章中我们学习了键值对的三种方法,分别是keys和values,reduceByKey,groupByKey。
keys和values分别对应了我们的键与值。
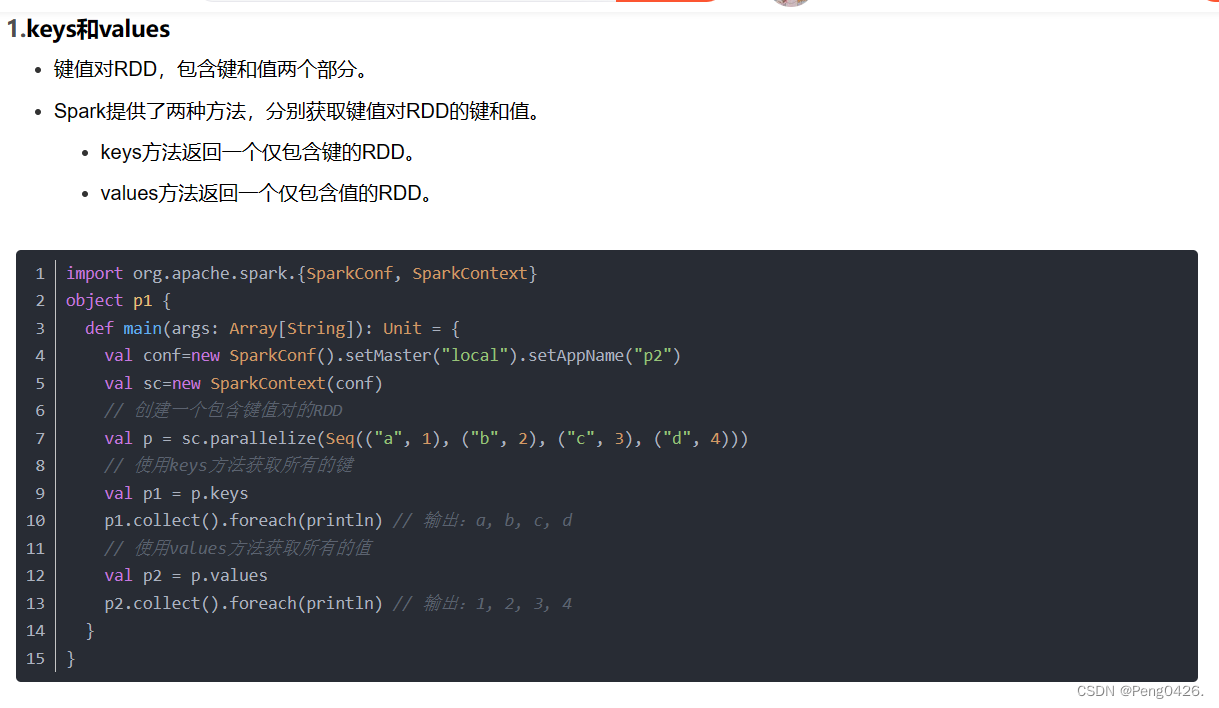
我们可以用它们来创建我们的RDD
reduceByKey可以进行统计,将有相同键的值进行相加,统一输出。
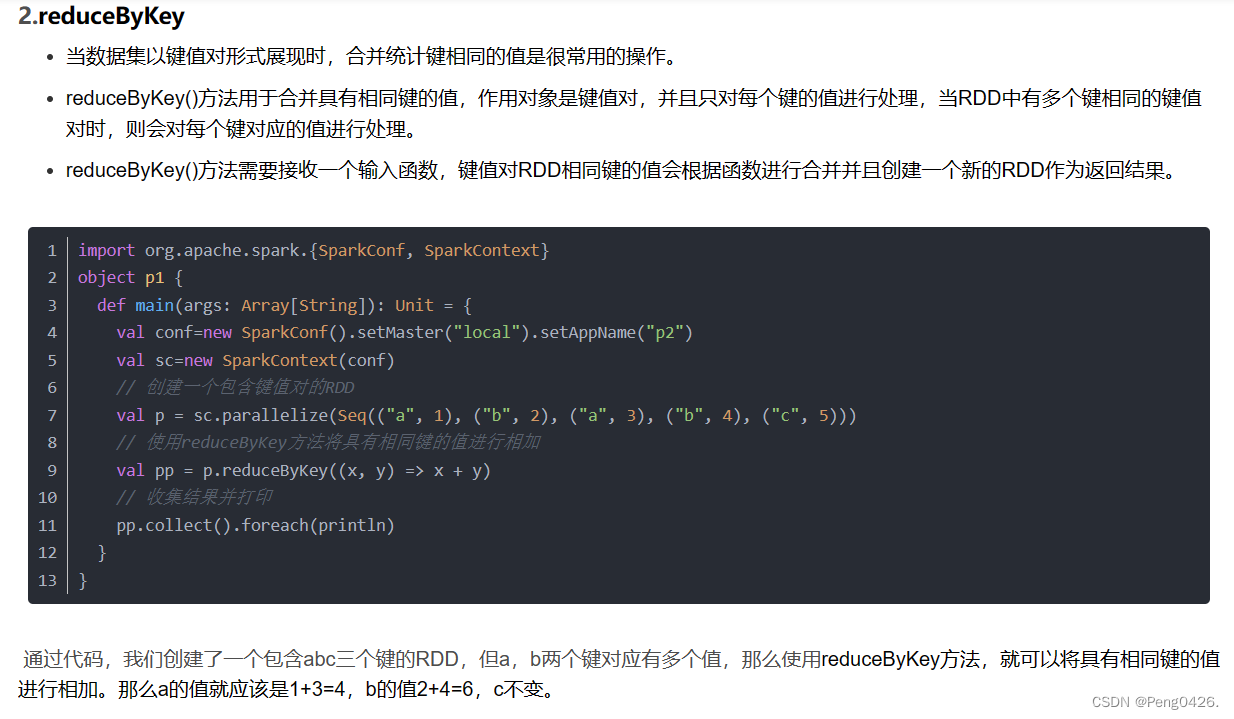
而 groupByKey方法就是对我们的键值对RDD进行分组了
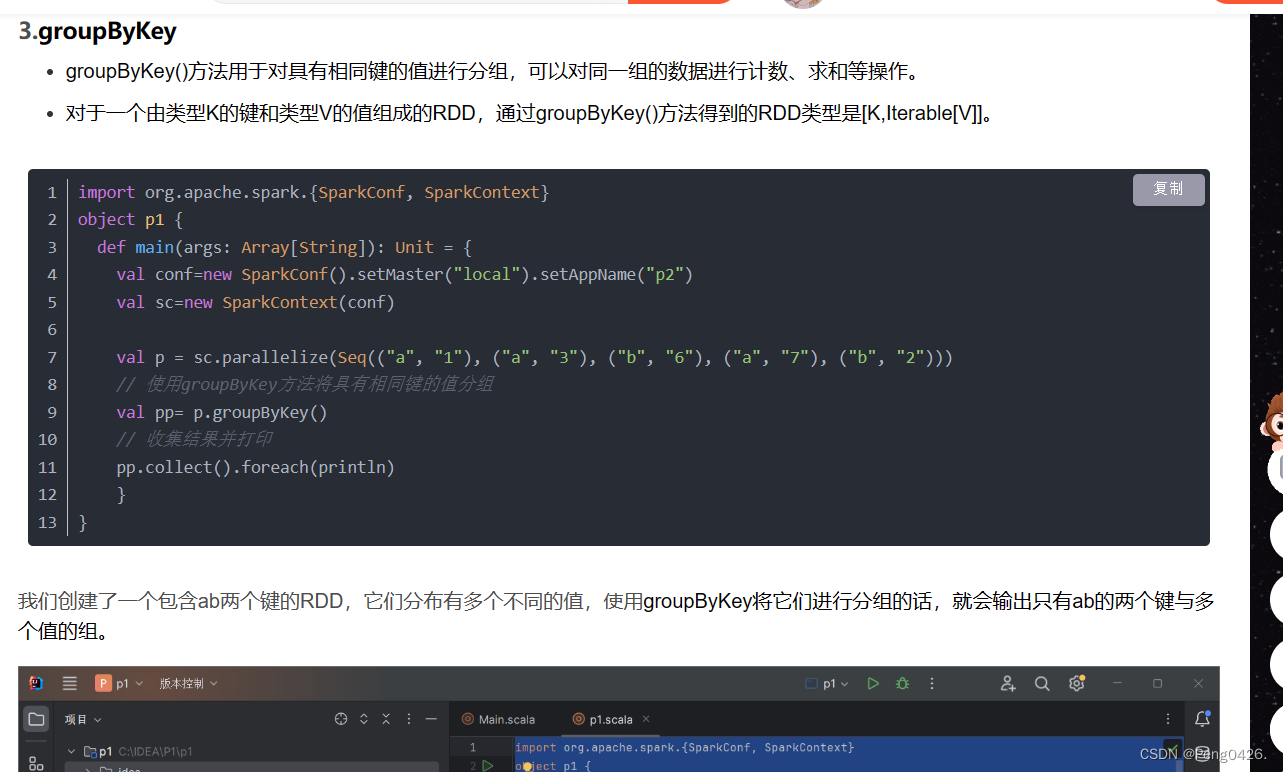
它可以将我们的相同的键,不同的值组合成一个组。
那么,开始今天的学习吧~
二、键值对方法
1.fullOuterJoin
- fullOuterJoin()方法用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)// 创建两个RDD(弹性分布式数据集)val p1 = sc.parallelize(Seq(("a1", "1"), ("a2", "2"), ("a3", "3")))val p2 = sc.parallelize(Seq(("a2", "A"), ("a3", "B"), ("a4", "C")))// 将RDD转换为键值对val pp1 = p1.map { case (key, value) => (key, value) }val pp2 = p2.map { case (key, value) => (key, value) }// 执行fullOuterJoin操作val ppp = pp1.fullOuterJoin(pp2)// 收集结果并打印ppp.collect().foreach(println)}
}我们的代码创建了两个键值对RDD,那么使用 fullOuterJoin方法全外连接那么两个键值对都会连接。
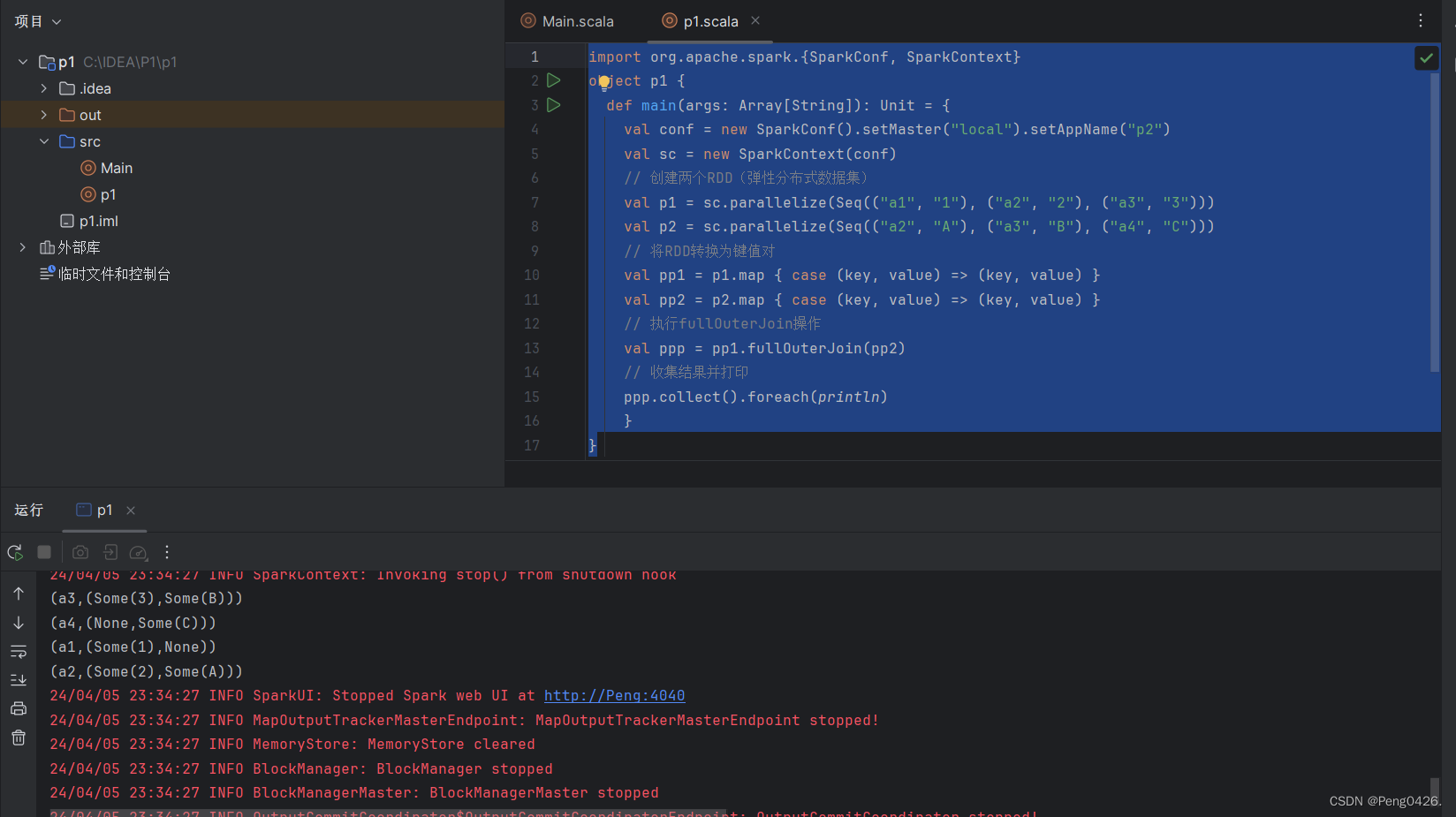
可以看到两个键值对里的键与值都连接上了,互相没有的值即显示None值。
2.zip
- zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。
- 将两个RDD组合成Key/Value形式的RDD,这里要求两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)// 创建两个RDDval p1 = sc.parallelize(Seq(1, 2, 3))val p2 = sc.parallelize(Seq("a", "b", "c"))// 使用zip方法将两个RDD组合在一起val pp1 = p1.zip(p2)val pp2 = p2.zip(p1)// 收集结果并打印pp1.collect().foreach(println)pp2.collect().foreach(println)}
}代码创建了两个不同的RDD键值对,分别使用p1zip方法p2与p2zip方法p1,那么它们输出的结果会是一样的吗?
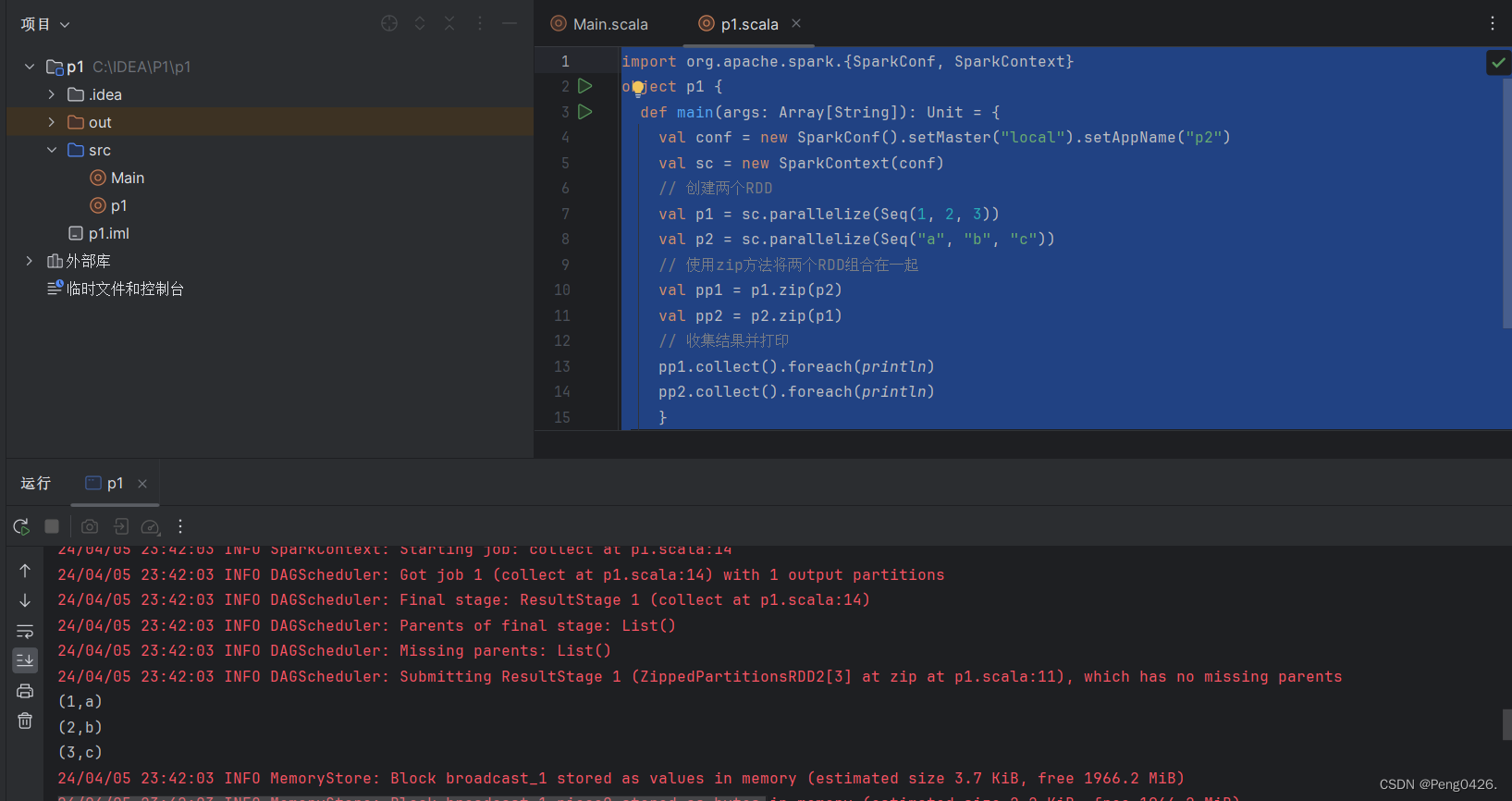
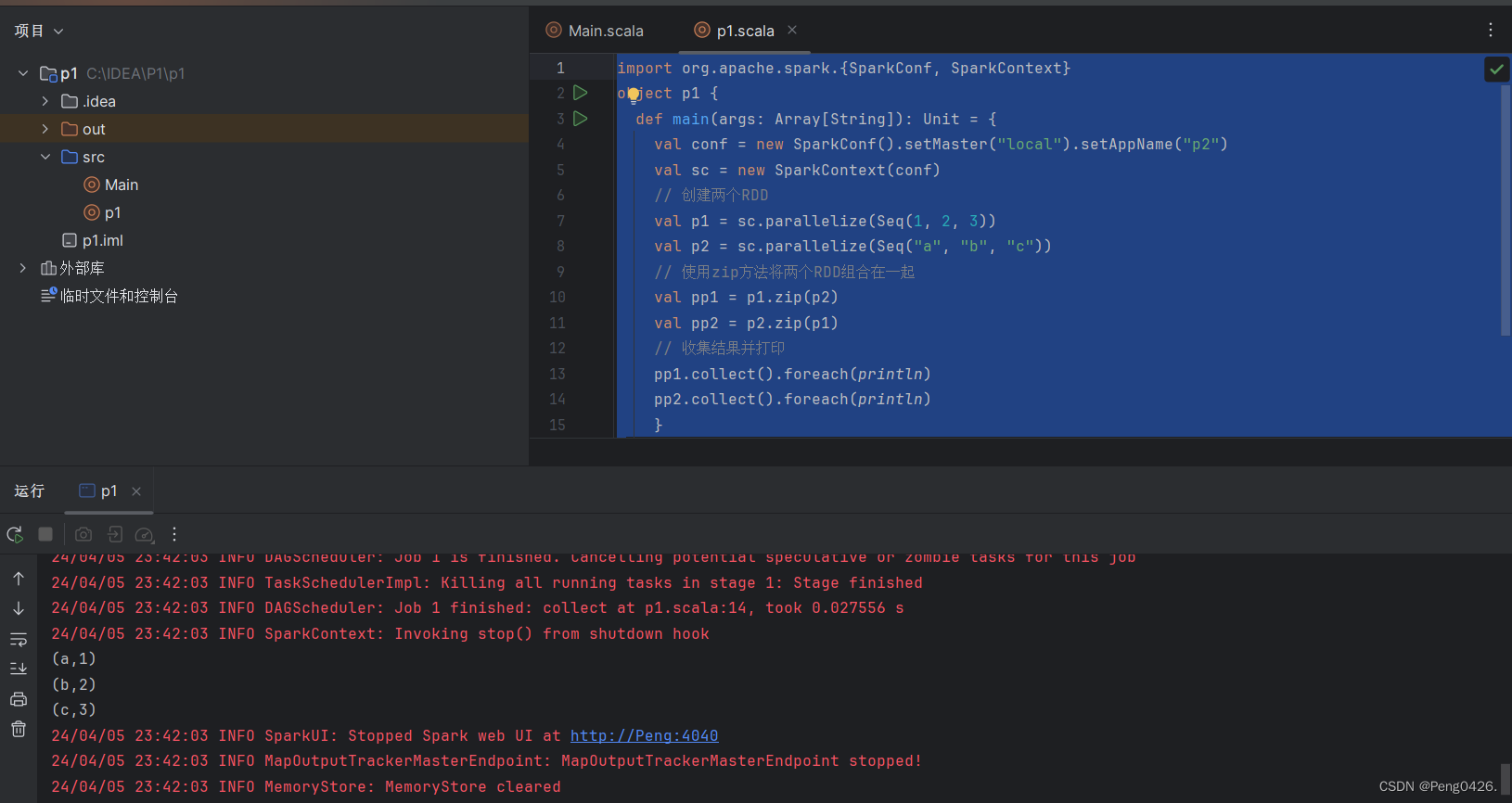
可以看到是不一样的,谁在前面谁就是键,反之是值。
3.combineByKey
- combineByKey()方法是Spark中一个比较核心的高级方法,键值对的其他一些高级方法底层均是使用combineByKey()方法实现的,如groupByKey()方法、reduceByKey()方法等。
- combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。
- combineByKey()方法的使用方式如下。
- combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)
import org.apache.spark.{SparkConf, SparkContext}
object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("p2")val sc = new SparkContext(conf)val p1 = sc.parallelize(Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4), ("c", 5)))val p2 = p1.combineByKey(// createCombiner: 将第一个值转换为累加器(v: Int) => v,// mergeValue: 将新的值加到累加器上(c: Int, v: Int) => c + v,// mergeCombiners: 合并两个累加器(c1: Int, c2: Int) => c1 + c2)p2.collect().foreach { case (key, value) =>println(s"Key: $key, Value: $value")}}
}我的代码中:
createCombiner: 这个函数定义了如何将每个键的第一个值转换为初始的累加器值。
代表着每个键,第一个出现的值将作为累加器的初始值。
mergeValue: 这个函数定义了如何将新值与当前的累加器值合并。在我的代码中,我将新值与累加器相加。
代表着每个键的后续值,它们都会被加到当前的累加器值上。
mergeCombiners: 这个函数定义了当两个累加器(对应于同一个键但可能来自不同的分区)需要合并时应该执行的操作。在我的代码中,也是将两个累加器值相加
这确保了无论数据如何在分区之间分布,最终每个键都会得到正确的累加结果。
看看输出效果
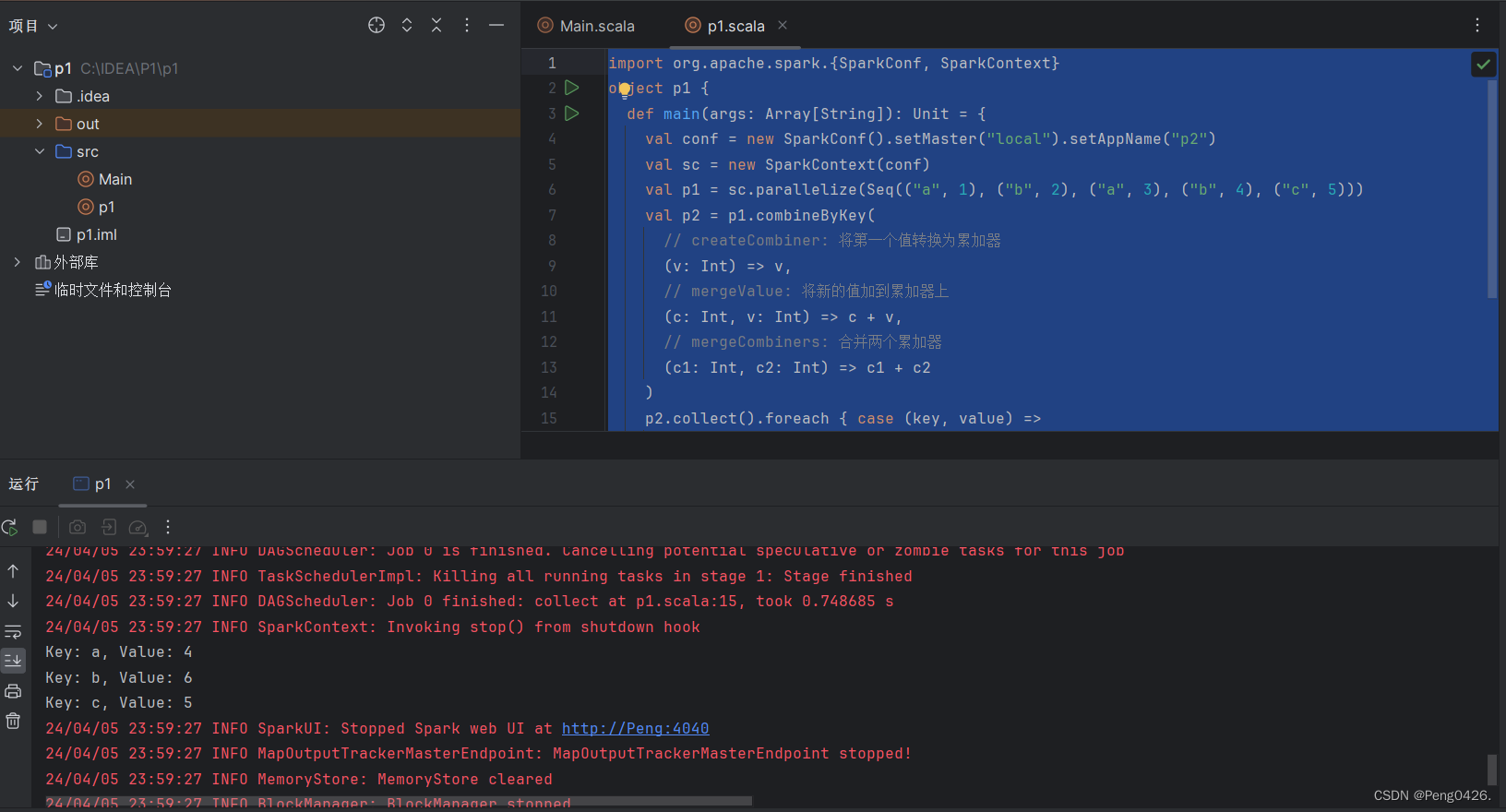
可以看到我们的键值对成功累加。
快去试试吧~
拓展-方法参数设置
| 方法 | 参数 | 描述 | 例子 |
|---|---|---|---|
| fullOuterJoin | otherRDD | 另一个要与之进行全外连接的RDD | rdd1.fullOuterJoin(rdd2) |
| fullOuterJoin | numPartitions | 结果RDD的分区数(可选) | rdd1.fullOuterJoin(rdd2, numPartitions=10) |
| zip | otherRDD | 要与之进行zip操作的另一个RDD | rdd1.zip(rdd2) |
| combineByKey | createCombiner | 处理第一个出现的每个键的值的函数 | lambda v: (v, 1) |
| combineByKey | mergeValue | 合并具有相同键的值的函数 | lambda acc, v: (acc[0] + v, acc[1] + 1) |
| combineByKey | mergeCombiners | 合并两个累积器的函数 | lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]) |
| combineByKey | numPartitions | 结果RDD的分区数(可选) | rdd.combineByKey(createCombiner, mergeValue, mergeCombiners, numPartitions=5) |