🎬慕斯主页:修仙—别有洞天
♈️今日夜电波:ヒステリックナイトガール
1:03━━━━━━️💟──────── 5:06
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
什么是HTTP协议?
URL
什么是URL?
urlencode和urldecode
HTTP请求和响应的格式
HTTP请求格式
HTTP的方法
HTTP响应格式
HTTP的状态码
HTTP常见Header
请求头(Request Header)
响应头(Request Header)
设计一个简单的HTTP服务器
解析HTTP请求格式
根据上面解析出来的数据创建服务器
一些细节的知识
重定向
Cookie
什么是HTTP协议?
HTTP协议,全称Hypertext Transfer Protocol,即超文本传输协议,是互联网上应用最为广泛的一种网络传输协议。它定义了客户端(如浏览器)与服务器之间的通信规范,以实现对各种资源(如HTML页面、图像、音频、视频等)的传输和访问。HTTP协议基于请求响应模式,客户端向服务器发送请求消息,请求消息中包含请求方法、URL、协议版本以及请求头等信息。服务器接收到请求消息后,根据请求消息的URL和相应的处理逻辑,生成服务器响应消息,并将其发送给客户端。响应消息中包含协议版本、状态码、响应头和响应体等信息。客户端接收到响应消息之后,会根据自身的处理方式进行处理,例如如果是网页,客户端会解析响应体中的HTML代码并渲染出网页。
URL
什么是URL?
平时我们俗称的 "网址" 其实就是说的 URL,如下图所示:

需要注意的是:http默认绑定的端口号是80、https默认绑定的端口号是443。而其中的服务器地址实际上就是我们的ip地址,如下的地址是相同的:我们可以指定端口来访问。如果不指定则会使用默认的端口。
http://www.qq.com:80 == 61.241.54.232:80实际上我们看到服务器网址后带的文件路径我们这个时候就很清楚了,这不就是我们在Linux中常用的文件目录结构吗?实际上也的确是这样的,我们通过URL请求服务,可以带上指定的路径,将该路径下的资源文件返回给用户。
对于带层次的文件路径来说,第一个 / 表示为web根目录,第二个 / 开始表示为路径分隔符。 // 通常被当作单个斜杠来处理。
?表示为查询字符串的开头,参数和数值使用键值对的形式(KV结构)进行表示,多个键值对之间使用与号(&)分隔。例如,?param1=value1¶m2=value2。
# 表示为片段标识的开头,后面跟着资源的特定部分或ID。它主要用于客户端的导航,不会被发送到服务器。
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。如下:

HTTP请求和响应的格式
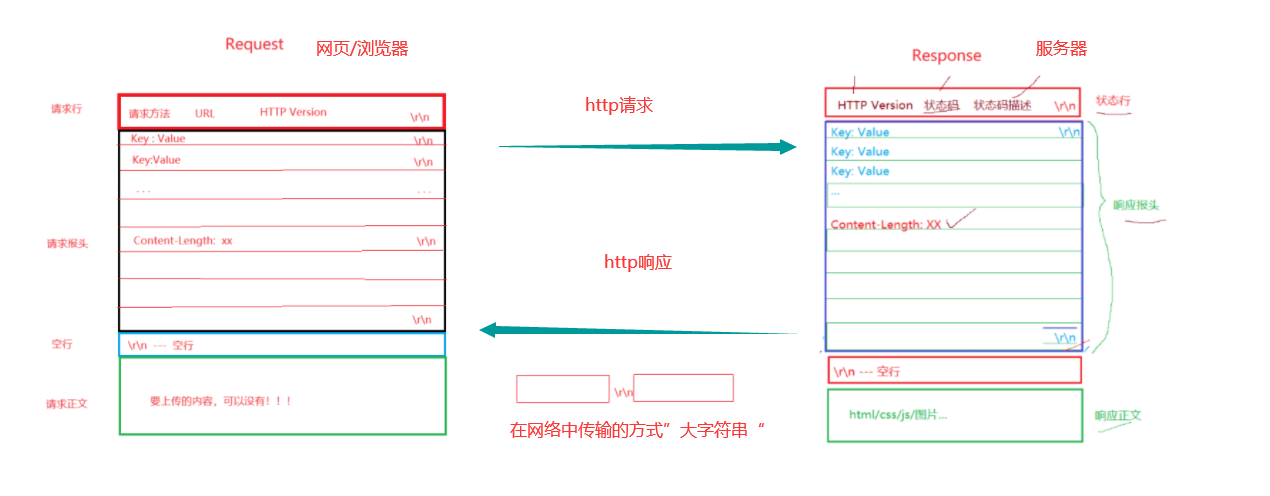
下面是对上述图解的解释:
HTTP请求和响应的格式在Web开发中非常重要,它们定义了客户端(通常是浏览器)和服务器之间如何通信。以下是关于HTTP请求和响应格式的简要概述:(需要注意的是:他们通常使用\r\n进行分隔)
HTTP请求格式
HTTP请求通常由以下部分组成:
- 请求行(Request Line):包含HTTP方法(如GET、POST等)、请求的URL和HTTP版本(如HTTP/1.1)。
GET /example.html HTTP/1.1- 请求头部(Request Headers):包含关于请求的各种元数据,如浏览器类型、请求来源、内容类型等。
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
...- 空行:请求头部之后是一个空行,用于分隔请求头部和请求体。
- 请求体(Request Body):对于某些HTTP方法(如POST或PUT),请求体包含发送到服务器的数据。这通常用于提交表单或上传文件。
下面对于其中的细节进行详细的叙述:
HTTP的方法

我们比较常用的就是GET和POST方法,下面详细介绍:
GET方法主要用于请求获取指定的资源。当客户端(如Web浏览器)使用GET方法向服务器发起请求时,它会将请求的参数附加到URL的末尾,并以明文形式发送。这些参数通常是以键值对的形式存在,并且在URL中可见。由于GET请求的参数直接暴露在URL中,因此它不适合处理敏感数据,如密码或金额等。此外,GET请求只产生一个TCP数据包,且浏览器会缓存GET请求的结果,这意味着如果用户回退或刷新页面,浏览器不会再次发送请求,而是从缓存中获取结果。GET请求还具有幂等性,即多次执行相同的GET请求,服务器返回的结果都是一样的。
与GET方法不同,POST方法主要用于向指定资源提交数据进行处理,如提交表单或上传文件。当使用POST方法时,提交的数据会放置在HTTP请求的主体中,而不是附加到URL上。这意味着POST请求可以提交大量的数据,且数据在传输过程中不会明文显示,从而提高了安全性。然而,由于POST请求不会缓存,每次用户回退或刷新页面时,浏览器都需要重新发送请求。此外,POST请求是非幂等的,即多次执行相同的POST请求可能会导致不同的结果。
HTTP响应格式
HTTP响应同样由几个部分组成:
- 状态行(Status Line):包含HTTP版本、状态码和状态消息。状态码用于表示请求的处理结果,如200表示成功,404表示未找到资源等。
HTTP/1.1 200 OK- 响应头部(Response Headers):包含关于响应的各种元数据,如内容类型、内容长度、服务器类型等。
Content-Type: text/html; charset=UTF-8
Content-Length: 12345
Server: Apache/2.4.46 (Unix)
...- 空行:响应头部之后同样是一个空行,用于分隔响应头部和响应体。
- 响应体(Response Body):这是服务器返回给客户端的实际数据,可以是HTML、JSON、XML等任何格式。
请注意,不是所有的HTTP请求都包含请求体(例如GET请求),同样也不是所有的HTTP响应都包含响应体(例如某些只包含状态信息的响应)。
下面对于其中的细节进行详细的叙述:
HTTP的状态码
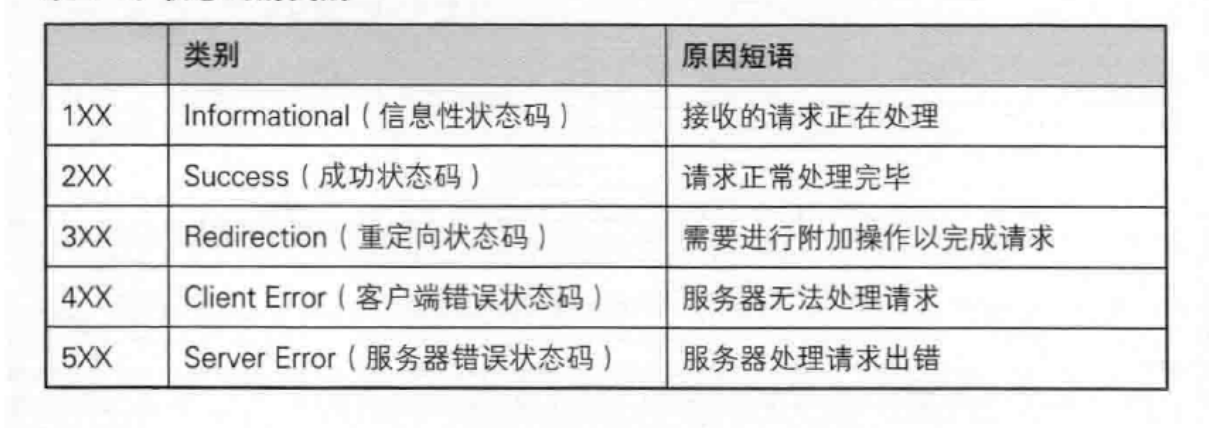
常见的状态码:
200 OK:表示请求已成功处理,并返回了所请求的资源。这是最常见的成功状态码。
302Redirect :表示临时重定向。当服务器返回302状态码时,意味着请求的资源已被临时移动到另一个位置,并且服务器会提供一个新的URL地址,以便客户端能够重新发送请求并获取所需资源。
403 Forbidden:表示服务器拒绝了客户端的请求,因为客户端没有访问权限。这可能是因为客户端未经授权或身份验证失败,或者服务器设置了访问限制。
404 Not Found:表示请求的资源在服务器上不存在。当客户端发起请求时,如果服务器无法找到与请求URL对应的资源,通常会返回这个状态码。
500 Internal Server Error:表示服务器在处理请求时遇到了内部错误。这可能是由于服务器上的代码或配置错误导致的。
504 Bad Gateway :表示网关超时(Gateway Timeout),它是一种服务器端错误响应状态码。当客户端(如浏览器)向服务器发送请求时,如果服务器在一定时间内无法从上游服务器(例如应用程序服务器、数据库服务器)获取到响应,就会返回504错误码给客户端。
HTTP常见Header
请求头(Request Header)
- Host:指定目标服务器的主机名或IP地址。
- Accept:定义客户端能够接受来自服务器的媒体类型,如application/json, text/html等。这允许服务器发送满足客户端需求的资源。
- User-Agent:标识发出请求的Web浏览器或客户端应用程序,使服务器能够根据客户端定制其响应。
- Content-Type:标识请求主体中内容的媒体类型,帮助服务器成功解释和处理有效负载。
- Cache-Control:指定请求或响应的缓存策略,如max-age、no-cache、no-store等。
- 自定义请求头:
- X-Forwarded-Host:在HTTP代理或负载均衡器后面使用。
- X-Forwarded-For:用于记录客户端的IP地址,特别在使用代理服务器时。
- X-Requested-With:用于指示请求的类型,如XMLHttpRequest。
- X-Csrf-Token:用于防止跨站请求伪造攻击。
- X-Content-Type-Options:用于指示浏览器是否应该自动处理响应体的MIME类型,如nosniff。
- X-XSS-Protection:用于启用浏览器内置的跨站脚本攻击防护机制。
响应头(Request Header)
- Content-Type:这个字段指明了响应主体的媒体类型,即客户端可以如何解析响应的内容。例如,对于HTML页面,该字段的值通常是text/html;对于JSON数据,值则是application/json。
- Content-Length:这个字段表示响应主体的长度,以字节为单位。这有助于客户端正确读取整个响应内容。
- Date:这个字段表示响应生成的日期和时间,格式为RFC 7231规定的日期时间格式。
- Cache-Control:这个字段用于指定缓存策略,控制响应内容在客户端和中间缓存中的缓存行为。例如,no-cache表示每次都需要向服务器验证缓存的内容是否仍然有效;max-age则指定了缓存内容的有效期。
- Expires:这个字段用于指定缓存内容的过期时间。与Cache-Control的max-age相比,Expires使用了一个绝对的时间戳来表示过期时间。
- ETag:这个字段用于标识响应内容的一个版本,如果内容未发生变化,服务器可以在后续的请求中通过比较ETag来避免发送相同的内容。
- Last-Modified:这个字段表示资源最后一次被修改的日期和时间,有助于客户端判断是否需要重新获取资源。
- Set-Cookie:这个字段用于设置HTTP cookie,用于会话管理、用户身份验证等目的。
- Location:搭配3XX状态码使用,指定重定向的目标URL。
- Server:这个字段包含了处理请求的服务器软件的名称和版本。
- Connection:这个字段用于控制网络连接的行为,例如是否保持连接(keep-alive)或关闭连接。
- WWW-Authenticate:当服务器需要客户端提供身份验证信息时,这个字段会被包含在401 Unauthorized响应中,以指示客户端如何进行身份验证。
下面我们以浏览器作为客户端,向我们自行编写的一个小程序进行访问,看看是否如我们所叙述的一样:
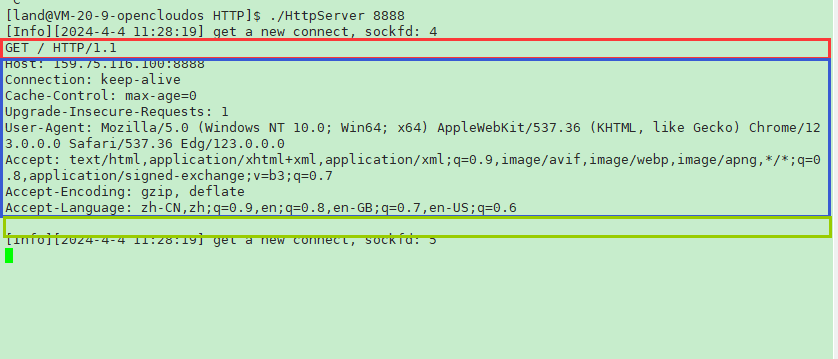
该程序仅仅是将报文给打印出来,并没有做什么特殊的处理,可以看到正如我们上面所说的,结构层次是相同的,由于没有带正文所以在空行后的正文内容是空的。
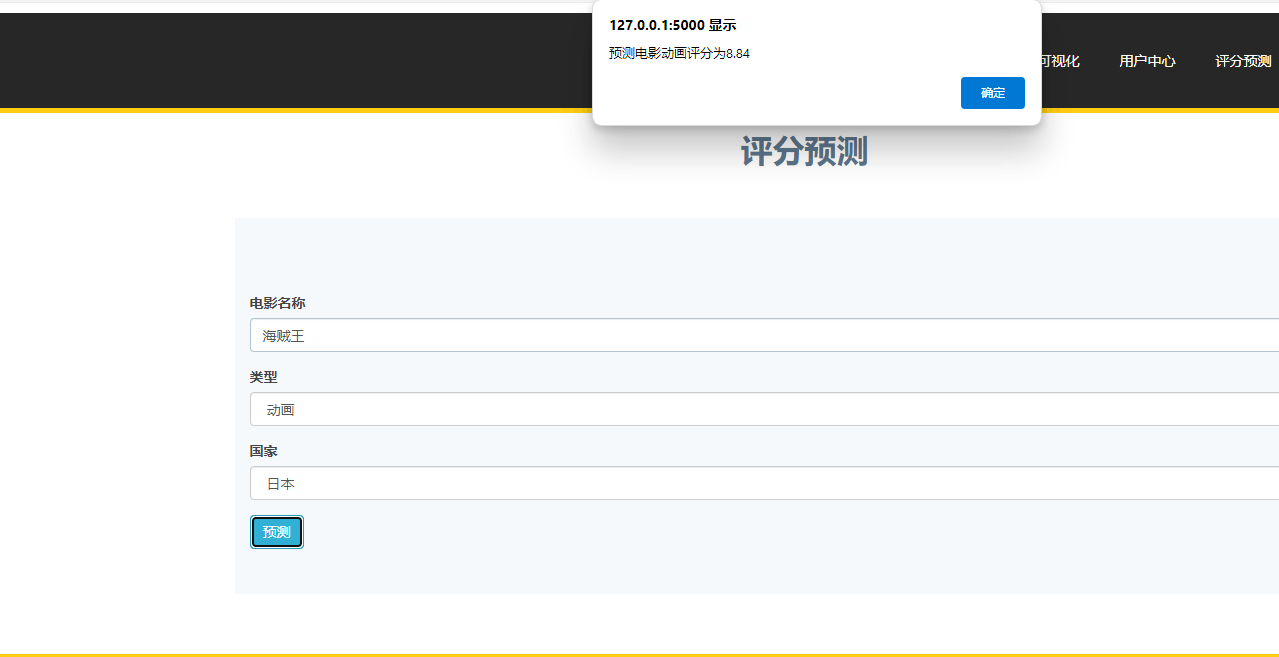
那如果我们想要给客户端返回信息呢?当然也是同上面所叙述的一样,以响应的格式按照HTTP协议的要求给他返回对应的报文,如下,我们按照规则返回一个简单的字符串“hello world!”
//返回响应过程std::string text="Hello world!";std::string response_line="HTTP/1.0 200 OK\r\n";std::string response_header="Content-Length: ";response_header+=std::to_string(text.size());response_header+="\r\n";std::string blank_line="\r\n";std::string response=response_line;response+=response_header;response+=blank_line;response+=text;send(sockfd,response.c_str(),response.size(),0);效果如下:
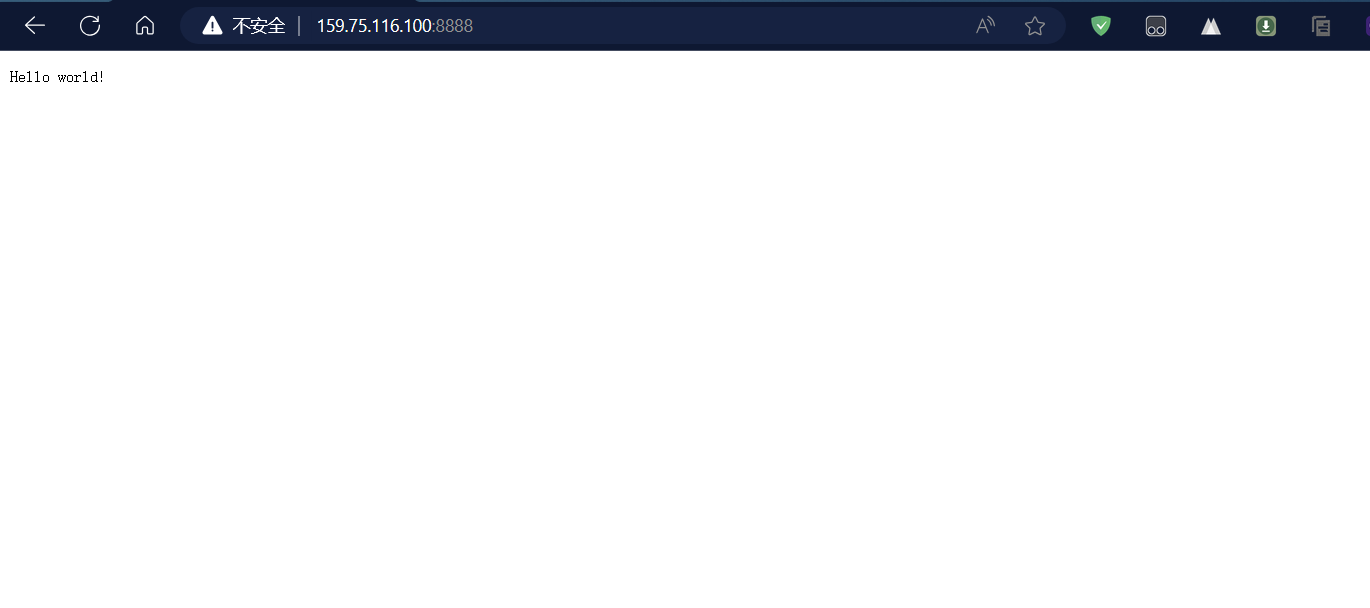
需要特别注意的是:网页必须指明编码格式,也就是Content-Type。否则就会出现乱码。通常根据文件的后缀来区别。比如:如果我们放回的是html格式则按照Content-Type对照表返回text/html,png则是image/png。
设计一个简单的HTTP服务器
解析HTTP请求格式
按照要求我们创建一个Deserialize函数用于解析和处理通过HTTP发送过来的报文,最主要的就是sep=\r\n这个分隔符,根据他我们可以将请求行到Header全部解析,最后根据空行我们可以得到后面的请求正文。创建一个Parse函数用于解析请求方法、URL、http_version,最后分析URL,获得文件路径、要打开的文件类型。

class HttpRequest
{
public:void Deserialize(std::string req){while (true){std::size_t pos = req.find(sep);if (pos == std::string::npos)break;std::string tmp = req.substr(0, pos);if (tmp.empty())break;req_header.push_back(tmp);req.erase(0, pos + sep.size());}text = req;}void Parse(){std::stringstream ss(req_header[0]);ss >> method >> url >> http_version;file_path = wwwroot;if (url == "/" || url == "/index.html"){file_path += "/";file_path += homepage; //./wwwroot/index.html}else{file_path += url;}auto pos = file_path.rfind(".");if (pos == std::string::npos)suffix = ".html";elsesuffix = file_path.substr(pos);}public:std::vector<std::string> req_header;std::string text;// 解析之后的结果std::string method;std::string url;std::string http_version;std::string file_path; // ./wwwroot/a/b/c.html 2.pngstd::string suffix;
};根据上面解析出来的数据创建服务器
这里我们复用了之前实现的socket和日志接口,在初始化的时候仅仅需要传入端口即可,同时我们先自定义仅有两种类型的文件“html”和“png”。这两个分别是给Header中的Content-Type 用的。
这个服务器使用简易的多线程来实现多人链接,调用pthread_create的函数ThreadRun会使用pthread_deatch来让线程无需等待。一些线程的细节不多叙述啦~
最主要的还是其中对于http协议的处理函数HandlerHttp。他会读取建立了tcp链接的http协议发来的报文,接着按照报文进行解析,按照我们制定的要求返回响应过程。具体的响应报文下面仅仅给出一些例子:
class HttpServerclass ThreadData
{
public:ThreadData(int soc, HttpServer *s): sockfd(soc), svr(s){}public:int sockfd;HttpServer *svr;
};class HttpServer
{
public:HttpServer(uint16_t port = defaultport) : port_(port){content_type.insert({".html", "text/html"});content_type.insert({".png", "image/png"});}bool Start(){listensock_.Socket();listensock_.Bind(port_);listensock_.Listen();for (;;){std::string clientip;uint16_t clientport;int sockfd = listensock_.Accept(&clientip, &clientport);lg(Info, "get a new connect, sockfd: %d", sockfd);pthread_t tid;ThreadData *td = new ThreadData(sockfd, this);pthread_create(&tid, nullptr, ThreadRun, td);}}static std::string ReadHtmlContent(const std::string &hemlpath){std::ifstream in(hemlpath, std::ios::binary);if (!in.is_open())return "";//获得文件总大小in.seekg(0, std::ios_base::end);auto len = in.tellg();//回到开头in.seekg(0, std::ios_base::beg);std::string content;content.resize(len);in.read((char*)content.c_str(), content.size());in.close();return content;}std::string SuffixToDesc(const std::string &suffix){auto iter = content_type.find(suffix);if(iter == content_type.end()) return content_type[".html"];else return content_type[suffix];}void HandlerHttp(int sockfd){char buffer[10240];ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);if (n > 0){buffer[n] = 0;std::cout << buffer;HttpRequest req;req.Deserialize(buffer);req.Parse();// 返回响应过程std::string text;bool ok = true;text = ReadHtmlContent(req.file_path);if(text.empty()){ok = false;std::string err_html = wwwroot;err_html += "/";err_html += "err.html";text = ReadHtmlContent(err_html);}std::string response_line;if(ok)response_line = "HTTP/1.0 200 OK\r\n";elseresponse_line = "HTTP/1.0 404 Not Found\r\n";std::string response_header = "Content-Length: ";response_header += std::to_string(text.size());response_header += "\r\n";response_header += "Content-Type: ";response_header += SuffixToDesc(req.suffix);response_header += "\r\n";std::string blank_line = "\r\n";std::string response = response_line;response += response_header;response += blank_line;response += text;send(sockfd, response.c_str(), response.size(), 0);}close(sockfd);}static void *ThreadRun(void *args){pthread_detach(pthread_self());ThreadData *td = static_cast<ThreadData *>(args);td->svr->HandlerHttp(td->sockfd);delete td;return nullptr;}private:Sock listensock_;uint16_t port_;std::unordered_map<std::string, std::string> content_type;
};结合HTML我们可以实现如下的效果:

借用了一位大佬的HTML代码:
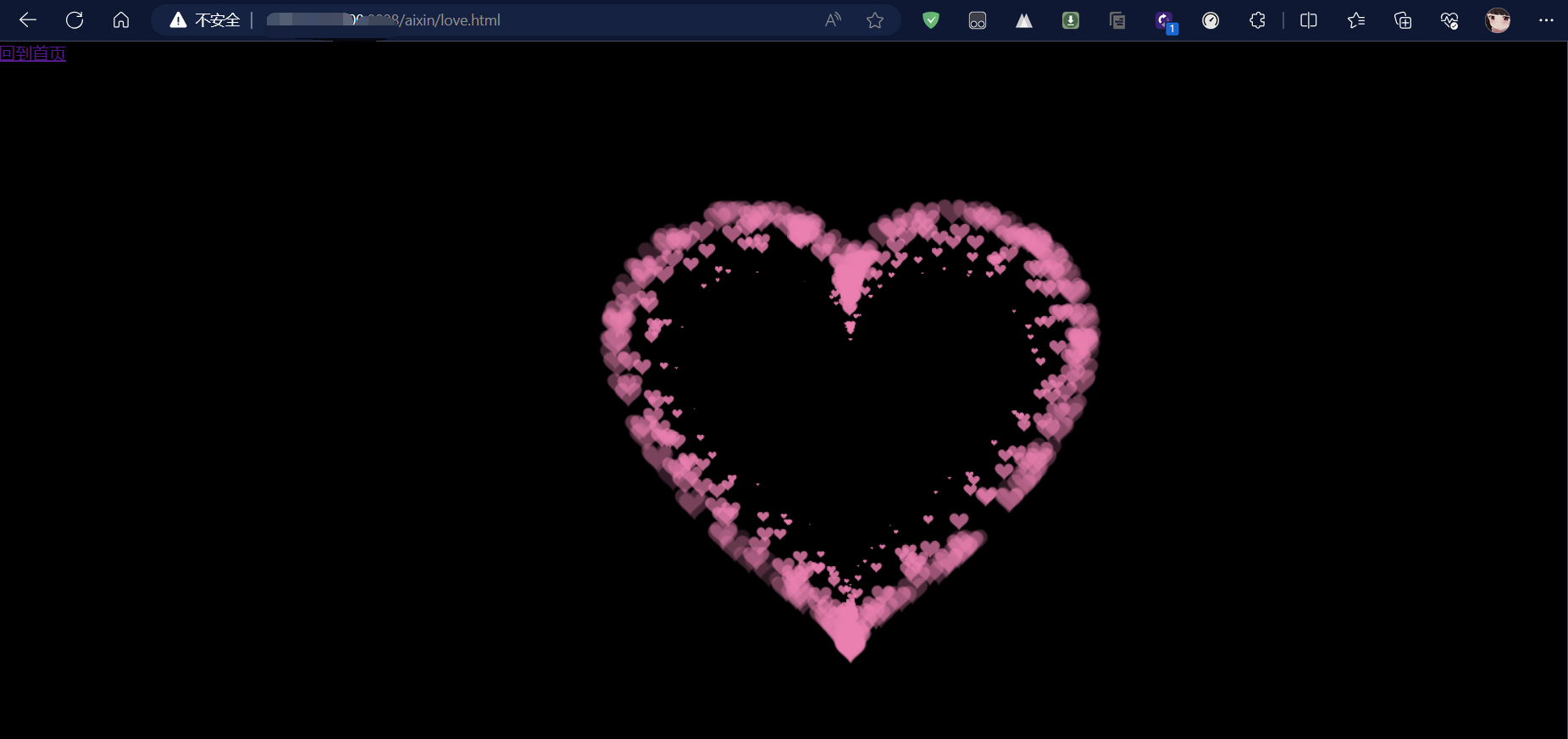
当遇到访问错误的路径时可以合理的处理:

一些细节的知识
在了解完上面的知识后,相信对于http已经有了一定的认识。下面讲讲细节的东西:
重定向
前面提到有3开头的状态码,这是重定向状态码。这里要详细介绍一下永久重定向和临时重定向的区别:
永久重定向(HTTP状态码301)表示原URL不应再被使用,而新的URL应替换它。这通常发生在站点更改其URL结构后,以确保旧的链接或书签能够继续有效。这种重定向是永久性的,一旦实施,搜索引擎和其他客户端应更新其索引和缓存,以反映新的URL。
临时重定向(HTTP状态码302)则意味着请求的资源已被临时移动到其他位置,并且服务器已经提供了新的URL,以便客户端可以重新发送请求。这种重定向是暂时的,可能由于资源暂时不可用或正在进行维护等原因而发生。当资源恢复其原始位置或维护完成后,客户端应继续使用原始URL。
在搜索引擎优化的角度,永久重定向对于确保网站的排名和流量至关重要,因为它告诉搜索引擎旧的URL已被新的URL永久替代。而临时重定向则不会对搜索引擎的排名产生长期影响,因为搜索引擎知道这只是暂时的变化。
需要注意的是:上述的重定向都是会搭配header中介绍过的Location(搭配3XX状态码使用,指定重定向的目标URL)使用。
我们要重定向则可以在响应行和header中添加对应的状态码和header和kv结构即可。如下:
std::string response_line="HTTP/1.0 301 Moved Permanently\r\n";//永久重定向//std::string response_line="HTTP/1.0 302 Found\r\n";//临时重定向std::string response_header = "Location: http://www.qq.com";response_header += "\r\n";Cookie
Cookie 是一种在 Web 开发中广泛使用的技术,用于在客户端(通常是用户的浏览器)存储信息。这些信息可以是用户偏好、会话状态或其他任何需要在多次请求和页面加载之间保持的数据。
以下是关于 Cookie 的详细解释:
1. 基本概念
- 定义:Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器后续向同一服务器发送请求时被携带上,用于实现用户跟踪和会话管理等功能。
- 作用:通过 Cookie,服务器可以识别特定的用户,并根据之前保存的信息为用户提供个性化的内容或服务。
2. 工作原理
- 设置 Cookie:当服务器响应一个 HTTP 请求时,它可以通过在 HTTP 响应头中设置
Set-Cookie字段来发送一个或多个 Cookie 到客户端。这样客户端就可以使用这些数据,一些操作如:验证身份操作就不用重复的进行了。- 接收和存储 Cookie:浏览器在接收到含有
Set-Cookie的响应后,会将这些 Cookie 存储在本地。- 发送 Cookie:在后续的 HTTP 请求中,浏览器会自动将之前存储的 Cookie 通过
Cookie请求头发送到服务器。3.Cookie的分类
- 内存Cookie:也被称为非持久Cookie或会话Cookie。这种Cookie是由浏览器维护并保存在内存中的,因此其存在时间是短暂的。当电脑关机或浏览器关闭后,内存Cookie就会自动消失。
- 硬盘Cookie:也被称为持久Cookie。这种Cookie保存在硬盘中,一般是在浏览器的目录下有一个文件单独存放。硬盘Cookie有一个过期时间,除非用户手动删除或者cookie过期,否则cookie不会被删除,其存在时间是长期的。
如下便是一个网站的例子:
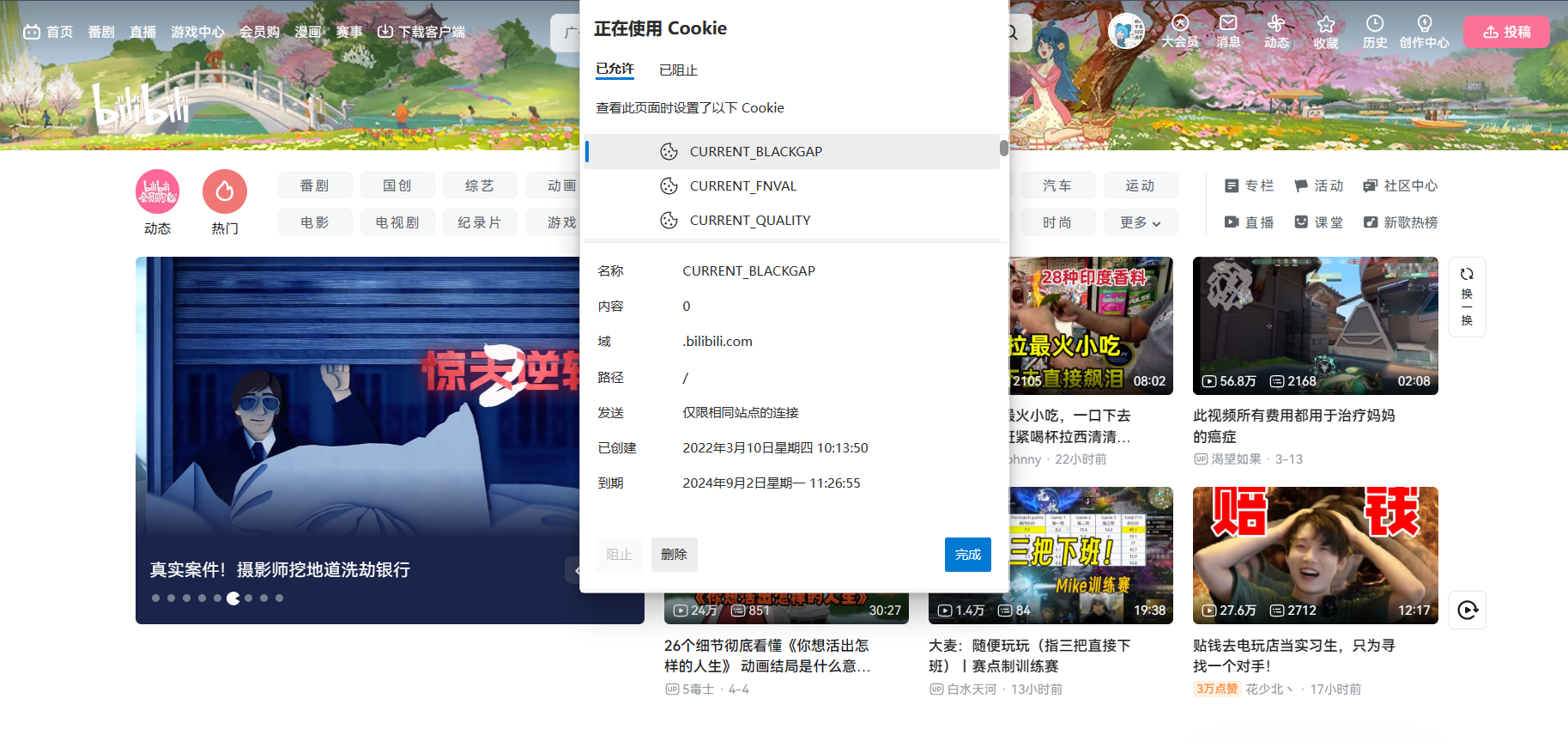
大致的代码理解:
std::string response_line="HTTP/1.0 200 OK\r\n";response_header += "Set-Cookie: name=XIXI";response_header += "\r\n";response_header += "Set-Cookie: password=12345678";response_header += "\r\n";4、Cookie安全问题
Cookie的安全性是一个重要的议题,因为它们包含了用户的个人信息和会话状态,如果这些信息被恶意利用,可能会导致隐私泄露、身份冒用等安全问题。
5、Session ID
Session ID是编程中用于跟踪和管理用户会话的重要概念。在Web开发中,会话是指用户与应用程序之间的交互过程,它可以跨越多个页面请求,使应用程序能够在多个页面之间保持状态。例如,当用户登录到网站时,会话可以用来跟踪用户的身份验证状态,以便在用户浏览其他页面时保持其登录状态。
为了实现会话跟踪,Web应用程序通常会为每个用户分配一个唯一的会话标识符,即Session ID。这个标识符由应用服务器在用户连接时生成,并用于在服务器端存储与特定用户相关的会话信息。Session ID通常可以保存在客户端的Cookie中,或者在URL中作为参数传递。当客户端提交页面请求时,会将这个Session ID发送回服务器,服务器通过解析这个ID来查找和读取对应的会话数据。
之后访问时,Http 请求都会携带Session id,就可以通过Session id判断是否合法,若合法则可以访问这个资源。虽然仍然可以被窃取,但是一些私人信息还是可以得到保证的。比如:账号密码就不用当心泄露了。
Session ID的生成过程通常发生在浏览器第一次请求服务器时,服务器会生成一个Session ID并返回给浏览器,这个ID会被保存在浏览器的会话Cookie中。Session在服务器上的默认有效时间通常是30分钟,但可以通过编程设置进行更改。
然而,值得注意的是,由于Session ID存储在客户端的Cookie中,因此一旦客户端禁用了Cookie,Session也会失效。因此,在使用Session ID进行会话管理时,需要考虑到Cookie可能不可用的情况,并采取适当的备选方案来维护用户的会话状态。
感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~