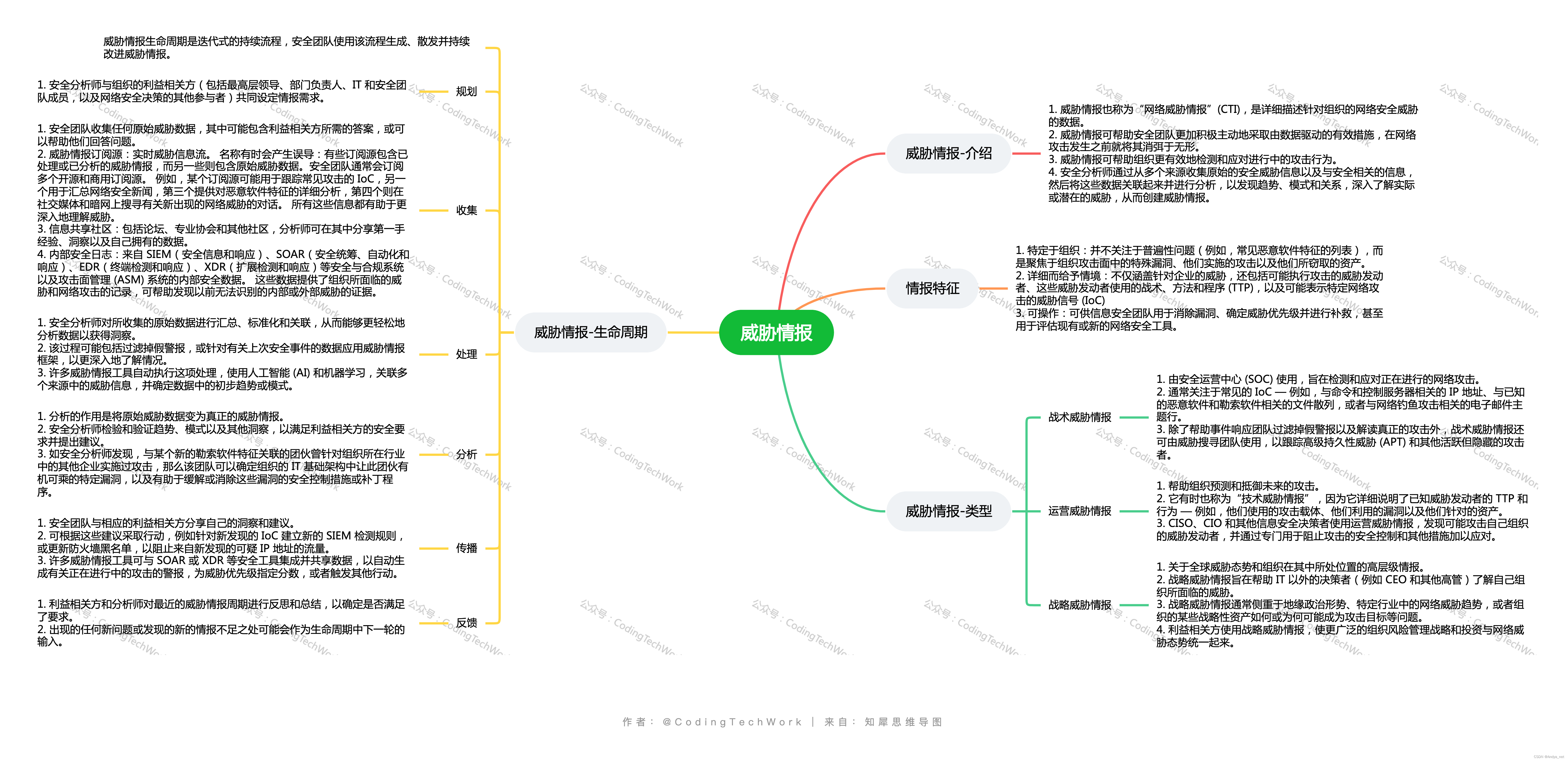
众所周知,数据要素已经列入基本生产要素,同时成立国家数据局进行工作统筹。目前数据要素如何发挥其价值,全国掀起了一浪一浪的热潮。
随着国外大语言模型的袭来,国内在大语言模型领域的应用也大放异彩,与此同时,数据价值在大模型中如何度量也成为了难题。一直以来,区块链被诟病为诈骗工具,在数据要素时代,区块链作为数据流通的权益证据链,可以较好的支撑。得到蔡钰·商业参考3《AIGC会让区块链重焕生机吗?》中提到:
但到了今天,普通人创作的普通内容在预训练AI模型的过程中也可以有了价值,以及各类生成式模型又极大降低了平民创作的门槛,我的观点也开始有了一些改变。未来三年,区块链技术可能会以超乎我们想象的速度成为主流应用。在那之前,你作为普通人,记得好好留言、好好创作,保护好自己的数字版权。
由此可以看出,数据供得出、流得动、用得好需要一种安全机制来保证。对于UGC、PGC而言,因为内容本是公开的,那么通过公开的区块链是可以较好的记录引用、转载的链接,并实现价值链条。
然而,对于政府和企业数据,则问题要复杂得多!且不论复杂情况下的数据如何流动,对于有价值的数据如何发挥价值,也是比较困难的。对于数据提供方而言,首先需要考虑的问题是,是不是真的有价值。这里的价值其实是对收获的价值和所承担的风险+投入成本。
数据“流得动”效用公式
数据收益之和 > 数据供出成本 + 数据交易成本 数据收益之和 > 数据供出成本+数据交易成本 数据收益之和>数据供出成本+数据交易成本
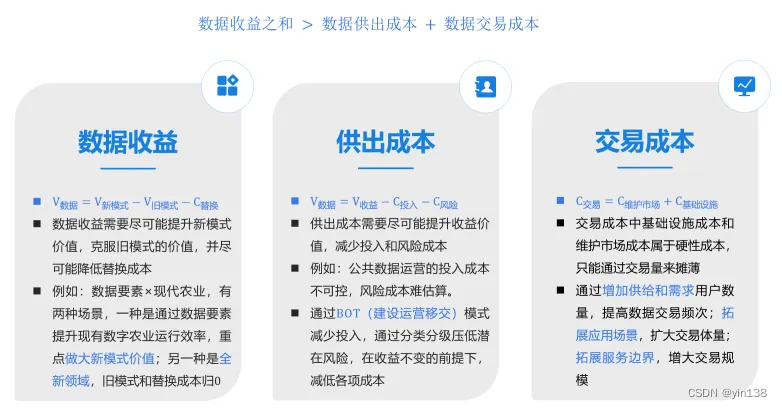
要想数据流动,需要整体流通效益大于成本。数据收益之和大于数据供出成本和数据交易成本之和,数据才能流得动。
数据收益来源于采用数据流通模式获得的价值减去现有旧模式的价值和替换新模式所需成本。要么做大新模式价值,要么探索全新领域。
交易成本由维护市场和基础设施成本构成,只能通过交易量来摊薄成本。一是通过增加供给和需求,二是拓展应用场景,三是拓展服务边界。通过增加数据收益,降低供出成本和交易成本,实现数据流得动。
供得出
数据供得出的条件:
预期收益>预期损失 预期收益>预期损失 预期收益>预期损失
供出成本需要满足数据收益减去投入成本和风险成本。投入成本确定性比较高,风险如果不加分类分级,趋于无穷大。例如:公共数据运营的投入成本不可控,风险成本难估算,需要重点解决。
解决方案:一是通过建设运营移交(BOT)模式减少投入成本,二是通过分类分级压低潜在风险。
供出成本
V 数据 = V 收益 − C 投入 − C 风险 > 0 V_{数据}=V_{收益} - C_{投入}-C_{风险}>0 V数据=V收益−C投入−C风险>0
收益价值
● 确定性收益
● 未来潜在收益
投入成本
● 数据采购成本
● 数据供出的服务器成本
● 数据加工成本
风险成本
● 数据泄露风险()
● 数据安全风险
● 数据隐私风险
交易成本
C 交易 = C 维护市场 + C 基础设施 C_{交易}=C_{维护市场}+C_{基础设施} C交易=C维护市场+C基础设施
交易成本中基础设施成本和维护市场成本属于硬性成本,只能通过交易量来摊薄。
通过增加供给和需求用户数量,提高数据交易频次;拓展应用场景,扩大交易体量;拓展服务边界,增大交易规模
维护市场成本
● 交易所上架费用
● 广告成本
● 人员成本和管理成本
基础设施成本
数据交易机构需要提供承载数据交易发布的建筑和线上交易场所,这些都属于基础设施投入。相对固定,且边际效用递减。
流得动
数据流得动的条件:
V 数据流动收益压差 = ∑ D ∈ P V C i − V D P = V D P → D C > 0 V C i 表示从第 i 位消费者获得的收益 ∑ D ∈ P V C i 则表示所有从生产者 P 的数据 D 获得的所有收益之和 V D P 表示为提供数据 D ,生产者 P 需要付出的成本 \begin{align} V_{数据流动收益压差} & =\sum_{D \in P} V_{C_i} - V_{D_P}=V_{D_P \to D_C}>0 \\ \\ & V_{C_i} 表示从第i位消费者获得的收益 \\ & \sum_{D \in P} V_{C_i} 则表示所有从生产者P的数据D获得的所有收益之和 \\ & V_{D_P} 表示为提供数据D,生产者P需要付出的成本 \end{align} V数据流动收益压差=D∈P∑VCi−VDP=VDP→DC>0VCi表示从第i位消费者获得的收益D∈P∑VCi则表示所有从生产者P的数据D获得的所有收益之和VDP表示为提供数据D,生产者P需要付出的成本
基于上述公式,可以做大消费者的数量,使得总的数据消费收益变大,而生产者付出的成本相对固定,使得数据流通收益压差大于0,这样才能实现数据流得动。
用得好
V 数据价值 = V 新体验 – V 旧体验 – C 替换成本 > 0 V_{数据价值}=V_{新体验}–V_{旧体验}–C_{替换成本}>0 V数据价值=V新体验–V旧体验–C替换成本>0
按照俞军产品体验公式, 用户价值 = 新体验 − 旧体验 − 替换成本,或者效应 − 成本> 0 用户价值 = 新体验 - 旧体验 - 替换成本,或者 效应 - 成本 > 0 用户价值=新体验−旧体验−替换成本,或者效应−成本>0
成本包括:直接成本和间接成本。
(1)直接成本,包括付出的金钱成本、时间成本、隐私数据、态度等;
(2)交易成本,即为了促成交易,付出的搜寻成本(比如为了找到哪个音乐软件最适合自己,甚至尝试用几个付出的时间)、议价成本(为了买到更便宜的西红柿和摊贩讨价还价付出的时间和口舌)、学习使用的成本、保障成本等。
数据能否用得好,关键在于新体验的增量是否足够。数据要素的交易模式,典型属于新体验模式,旧体验模式可能是目前已经构建的数据使用模式。例如通过爬虫获取数据、通过合同方式购买第三方数据或者模型。新体验主要在效率、实时性、准确性等方面好于就体验模式。
另一方面,如何使得替换成本尽可能的低,也是确保用得好的一个重要方面。例如,通过提升工具能力,降低用户替换成本。
总之,数据要想流得动,需要从供给、流通和消费来思考成本效益最低的解决方案。从数据交易流通的情况分析,是否流得动是关键。只有聚集足够的需求,才能撬动足够的供给,是一个典型的平台交易结果。20年前的淘宝,10年前的美团,都是需要通过补贴使得供需匹配,并提高效率。在数据交易场景中,不同时刻,对供需两方的场景要求不同。现阶段,各大数据交易所还是属于上架供给数据为主,消费者还很难使用目前的数据。
笔者认为,如果有足够的数据供给,应该会有消费者出现。不过基于上述从消费者角度来看,数据收益需要客户旧模式的价值,以及投入替换成本,这个过程往往比较困难。除非,应用场景的新模式具有压倒性的优势。
以上是笔者对于数据如何交易的一些思考,欢迎大家讨论,不妥之处,欢迎拍砖。