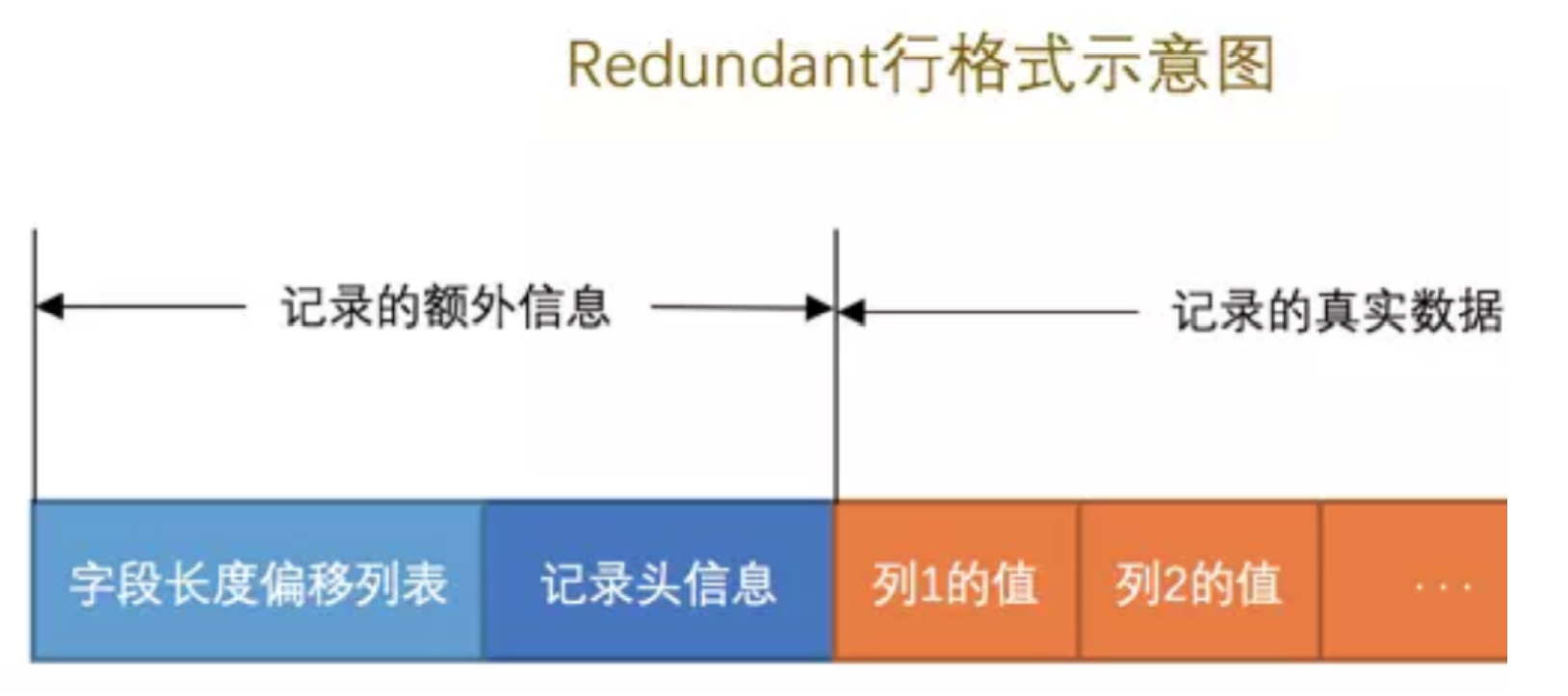
1.索引的代价
空间上的代价
时间上的代价
每次对表中的数据进⾏增、删、改操作时,都需要去修改各个B+树索引。⽽且我们讲过,B+树每层节点都是按照索引列的值从⼩到⼤的顺序排序⽽组成了双 向链表。不论是叶⼦节点中的记录,还是内节点中的记录(也就是不论是⽤户记录还是⽬录项记录)都是按照索引列的值从⼩到⼤的顺序⽽形成了⼀个单向链 表。⽽增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进⾏⼀些记录移位,⻚⾯分裂、⻚⾯回收啥的操作来维护好节点和 记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进⾏相关的维护操作,这还能不给性能拖后腿么?
总结:
所以说,一个表上索引建的越多,就会占用越多的存储空间,在增删改的时候性能就会越差。
2.索引适用的条件
为了将索引的效能发挥最大,我们需要对索引由深刻的认识。下面,我们通过查询来更加深入理解索引的使用方式。
1.1 准备
建立表:
CREATE TABLE person_info(id INT NOT NULL auto_increment,name VARCHAR(100) NOT NULL,birthday DATE NOT NULL,phone_number CHAR(11) NOT NULL,country varchar(100) NOT NULL,PRIMARY KEY (id),KEY idx_name_birthday_phone_number (name, birthday, phone_number)
);
对应这个表,有几点需要注意:
- 表中的主键是id,Innodo存储引擎会自动为id生成聚簇索引
- 我们额外定义了⼀个⼆级索引idx_name_birthday_phone_number,它是由3个列组成的联合索引。所以在这个索引对应的B+树的叶⼦节点处存储的⽤户记录 只保留name、birthday、phone_number这三个列的值以及主键id的值,并不会保存country列的值。
直接看一下二级索引的图示:

从图中可以看出:
- 先按照name列的值进行升序
- 如果name一样,就按照birthday列进行升序
- 如果birthday一样,就按照phone_numer进行升序
这个排序十分重要,因为只有页面和记录排好序,我们才可以通过二分法快速查找。
1.2 索引发挥作用
1.2.1 全值匹配
如果我们的搜索条件中的列和索引列一致的话,这种情况就称为全值匹配,比方说下面这个条件:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239';
这个查询过程很简单,先按照name,接着birthday,最后phone_numer
如果 where后面的查询条件顺序改一下会有什么影响嘛?
SELECT*
FROMperson_info
WHEREbirthday = '1990-09-27' AND phone_number = '15123983239' AND NAME = 'Ashburn';
答案:没有影响,Mysql查询优化器会按照可以使用索引中列的顺序来决定先使用哪个条件。
1.2.2 匹配最左边列
有时候,我们不想全值匹配,只是通过一个列,比如下面:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn';
或者
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1990-09-27';
只要where条件后面按照索引顺序,但又不是全值匹配,都会走索引。因为B+树的数据⻚和记录先是按照name列的值排序的,在name列的值相同的情况下才使⽤birthday列进⾏排序,也就是说name列的值不同的 记录中birthday的值可能是⽆序的。
但是:像下面这种方式就不会走索引了:
SELECT*
FROMperson_info
WHEREbirthday = '1990-09-27';
总结一下:
- 在联合索引时,如果想要使用索引,where 条件后面顺序一定要和索引保持顺序,这有点像找个人一样,刚开始拿姓匹配,如果匹配不上就第二个字,再匹配不上就第三个字。。。
1.2.3 匹配列前缀
走索引:
SELECT*
FROMperson_info
WHERENAME LIKE 'As%';
不走索引:
SELECT * FROM person_info WHERE name LIKE '%As%';
原因:Mysql无法定位记录的位置,因为可能性太多了,可以时AAS,aAS,甚至aAas。只有记录无序,Mysql就无法走索引,只能全表扫描了。
像这种的匹配规则是这样的,其实和列匹配差不多:
- 先比较字符串的第一个字符
- 第一个字符一样就比较第二个字符
- 第二个字符如果一样就比较第三个字符,如果一样,继续往后,不一样就终止。
案例:

1.2.4 匹配范围值
回头看我们idx_name_birthday_phone_number索引的B+树示意图,所有记录都是按照索引列的值从⼩到⼤的顺序排好序的,所以这极⼤的⽅便我们查找索引列的 值在某个范围内的记录。⽐⽅说下边这个查询语句:
走索引:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';
不走索引:
SELECT*
FROMperson_info
WHERENAME > 'Asa' AND NAME < 'Barlow' AND birthday > '1980-01-01';
上边这个查询可以分为两个部分:
- 通过条件name > ‘Asa’ AND name < 'Barlow’来对name进⾏范围,查找的结果可能有多条name值不同的记录
- 对这些name值不同的记录继续通过birthday > '1980-01-01’条件继续过滤
这样⼦对于联合索引idx_name_birthday_phone_number来说,只能⽤到name列的部分,⽽⽤不到birthday列的部分,因为只有name值相同的情况下才能⽤ birthday列的值进⾏排序,⽽这个查询中通过name进⾏范围查找的记录中可能并不是按照birthday列进⾏排序的,所以在搜索条件中继续以birthday列进⾏查找 时是⽤不到这个B+树索引的。
总结一下:
**为什么加上个birthday条件就用不上索引,其实说到底,就是通过name查找出来的记录birthday不是有序的。比如说 ASA 1980-01-01、ASAa 1979-01-01、Barlow 1981-01-01取出来的birthday不就无序了嘛 **
1.2.5 精确匹配某一列并范围匹配另外一列
对于同⼀个联合索引来说,虽然对多个列都进⾏范围查找时只能⽤到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进⾏范围查找,⽐⽅说 这样:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday > '1980-01-01' AND birthday < '2000-12-31' AND phone_number > '15100000000';
这个查询的条件可以分成3个部分:
- name = ‘Ashburn’,对name列进⾏精确查找,当然可以使⽤B+树索引了。
- birthday > ‘1980-01-01’ AND birthday < ‘2000-12-31’,由于name列是精确查找,所以通过name = 'Ashburn’条件查找后得到的结果的name值都是相 同的,它们会再按照birthday的值进⾏排序。所以此时对birthday列进⾏范围查找是可以⽤到B+树索引的。
- phone_number > ‘15100000000’,通过birthday的范围查找的记录的birthday的值可能不同,所以这个条件⽆法再利⽤B+树索引了,只能遍历上⼀步查询 得到的记录。
同理,下边的查询也是可能用到这个联合索引的:
SELECT*
FROMperson_info
WHERENAME = 'Ashburn' AND birthday = '1980-01-01' AND phone_number > '15100000000';
1.2.6 排序
我们在写查询语句的时候可以通过order by来进行升序。一般情况下,是把数据加载到内存中,然后在使用排序算法在内存中进行排序,但是如果数据集太大,**可能需要通过磁盘来存放中间结果,排序完再返回到客户端。**再磁盘中进行排序慢的和蜗牛一样,这时候通过索引直接取出来,不就不需要排序了吗,是不是特别快,哈哈
SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;
这个查询的结果集需要先按照name值排序,如果记录的name值相同,则需要按照birthday来排序,如果birthday的值相同,则需要按照phone_number排序。
使用联合索引排序需要注意事项
1) order by 列的顺序一定要和建立联合索引的顺序一致
2) 等值+order by 其余索引列可以使用联合索引

3) ASC、DESC混用
对于联合索引进行排序的场景,要求各个列要么都是ASC排序,要么都是DESC排序

但是,对于先按照name升序,再按照birthday降序的话,比如这样的:
SELECT * FROM person_info ORDER BY name, birthday DESC LIMIT 10;
这样如果使用索引的话,过程是这样的:
- 先从索引的最左边确定name列最⼩的值,然后找到name列等于该值的所有记录,然后从name列等于该值的最右边的那条记录开始往左找10条记录。
- 如果name列等于最⼩的值的记录不⾜10条,再继续往右找name值第⼆⼩的记录,重复上边那个过程,直到找到10条记录为⽌。
累不累,累啊,对于索引的使用一点也不高效,设计Mysql觉得这样还不如直接文件排序来的快,所以联合索引的各个排序列的排序顺序必须是一样的
1】 where子句中出现非排序使用到的索引列,如果说:
SELECT * FROM person_info WHERE country = 'China' ORDER BY name LIMIT 10;
这个查询是把符合条件的数据先查询出来然后排序,这样是使用不到索引的。
2】 排序列包含非同一个索引的列
有时候⽤来排序的多个列不是⼀个索引⾥的,这种情况也不能使⽤索引进⾏排序,⽐⽅说:
SELECT * FROM person_info ORDER BY name, country LIMIT 10;
name和country并不属于⼀个联合索引中的列,所以⽆法使⽤索引进⾏排序,⾄于为啥我就不想再唠叨了,⾃⼰⽤前边的理论⾃⼰捋⼀捋把~
3】 排序列使用了复杂的表达式
要想使⽤索引进⾏排序操作,必须保证索引列是以单独列的形式出现,⽽不是修饰过的形式,⽐⽅说这样:
SELECT * FROM person_info ORDER BY UPPER(name) LIMIT 10;
使⽤了UPPER函数修饰过的列就不是单独的列啦,这样就⽆法使⽤索引进⾏排序啦。
1.2.7 分组
有时候我们为了⽅便统计表中的⼀些信息,会把表中的记录按照某些列进⾏分组。⽐如下边这个分组查询:
SELECT NAME,birthday,phone_number,COUNT( * )
FROMperson_info
GROUP BYNAME,birthday,phone_number
这个查询相当于做了这3次分组操作:
- 先按照name分组,把所有name相同的分成一个个大组
- 一个个大组再按照birthday分成一个个小组
- 一个个小组再按照phone_numer分成一个个更小的组

3.回表的代价
这个东西对于我来说,很好理解就放张整图了:

索引覆盖
问题:回表的代价这么大,我们怎么减少拿?
为了彻底告别回表操作带来的性能损耗,我们建议:最好在查询列表⾥只包含索引列,⽐如这样:
SELECT NAME,birthday,phone_number
FROMperson_info
WHERENAME > 'Asa' AND NAME < 'Barlow'
因为我们只查询name, birthday, phone_number这三个索引列的值,所以只需要通过联合索引就可以得到,就可以不用聚簇索引回表查询 剩余列,也就是country的值了。 我们把这种只查询索引排序列的方式称之为索引覆盖
排序操作也优先使用索引覆盖的方式查询,比方说这个查询:
SELECT NAME,birthday,phone_number
FROMperson_info
ORDER BYNAME,birthday,phone_number;
虽然这个查询中没有LIMIT⼦句,但是采⽤了覆盖索引,所以查询优化器就会直接使⽤idx_name_birthday_phone_number索引进⾏排序⽽不需要回表操作了。
当然,如果业务需要查询出索引以外的列,那还是以保证业务需求为重。但是我们很不⿎励⽤*号作为查询列表,最好把我们需要查询的列依次标明。
4.如何挑选索引
4.1 只为搜索、排序或者分组的列创建索引
只为出现在WHERE⼦句中的列、连接⼦句中的连接列,或者出现在ORDER BY或GROUP BY⼦句中的列创建索引。而出现在查询列表中的列就不没必要建立索引了:
SELECT birthday, country FROM person_name WHERE name = 'Ashburn';
像查询列表中的birthday、country这两个列就不需要建⽴索引,我们只需要为出现在WHERE⼦句中的name列创建索引就可以了。
4.2 考虑列的基数
列的基数指的是某一列中不重复数据的个数,比方说某个列包含值2, 5, 8, 2, 5, 8, 2, 5, 8,虽然有9条记录,但该列的基数却是3。也就是说,在记录⾏数⼀ 定的情况下,列的基数越⼤,该列中的值越分散,列的基数越⼩,该列中的值越集中。
- 这个列的基数指标⾮常重要,直接影响我们是否能有效的利⽤索引。假设某 个列的基数为1,也就是所有记录在该列中的值都⼀样,那为该列建⽴索引是没有⽤的,因为所有值都⼀样就⽆法排序,⽆法进⾏快速查找了
- 如果某个建⽴ 了⼆级索引的列的重复值特别多,那么使⽤这个⼆级索引查出的记录还可能要做回表操作,这样性能损耗就更⼤了
最好为那些列的基数⼤的列 建⽴索引,为基数太⼩列的建⽴索引效果可能不好。
4.3 索引列的类型尽量小
我们在定义表结构的时候要显示的指定列的类型,以整数类型为理,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT这几种,它们占用的存储空间依次递增,我们这里所说的类型大小指的就是 **该类型表示的数据范围大小。**能表示的整数范围当然也是依次递增,如果我们想要对某个整数列建⽴索引的话,在表示的整数范围允许 的情况下,尽量让索引列使⽤较⼩的类型, 比如,我们能用INT就不要使用BIGINT,能使⽤MEDIUMINT就不要使⽤INT,这是因为:
- 数据类型越⼩,在查询时进⾏的⽐较操作越快(这是CPU层次的东东)
- 数据类型越⼩,索引占⽤的存储空间就越少,在⼀个数据⻚内就可以放下更多的记录,从⽽减少磁盘I/O带来的性能损耗,也就意味着可以把更多的数据⻚缓 存在内存中,从⽽加快读写效率。
这个建议对于表的主键来说更加适⽤,因为不仅是聚簇索引中会存储主键值,其他所有的⼆级索引的节点处都会存储⼀份记录的主键值,如果主键适⽤更⼩的数 据类型,也就意味着节省更多的存储空间和更⾼效的I/O。
4.4 索引字符串的前缀

4.5 让索引列在比较表达式中单独出现
假设表中有一个整数列my_col,我们为这个列建立索引,下面两个where子句虽然语义上是一致的,但在执行效率上却有很大差别:
- WHERE my_col * 2 < 4
- WHERE my_col < 4/2
第1个WHERE⼦句中my_col列并不是以单独列的形式出现的,⽽是以my_col * 2这样的表达式的形式出现的,存储引擎会依次遍历所有的记录,计算这个表达式的 值是不是⼩于4,所以这种情况下是使⽤不到为my_col列建⽴的B+树索引的。⽽第2个WHERE⼦句中my_col列并是以单独列的形式出现的,这样的情况可以直接使 ⽤B+树索引。
如果索引列在⽐较表达式中不是以单独列的形式出现,⽽是以某个表达式,或者函数调⽤形式出现的话,是⽤不到索引的。
4.6 主键选择-最好是自增
我们知道,对于⼀个使⽤InnoDB存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶⼦节点的。⽽记录⼜是存储在数据 ⻚中的,数据⻚和记录⼜是按照记录主键值从⼩到⼤的顺序进⾏排序,所以如果我们插⼊的记录的主键值是依次增⼤的话,那我们每插满⼀个数据⻚就换到下⼀ 个数据⻚继续插,⽽如果我们插⼊的主键值忽⼤忽⼩的话,这就⽐较麻烦了,假设某个数据⻚存储的记录已经满了,它存储的主键值在1~100之间:

可这个数据⻚已经满了啊,再插进来咋办呢?我们需要把当前⻚⾯分裂成两个⻚⾯,把本⻚中的⼀些记录移动到新创建的这个⻚中。⻚⾯分裂和记录移位意味着 什么?意味着:性能损耗。所以如果我们想尽量避免这样⽆谓的性能损耗,最好让插⼊的记录的主键值依次递增,这样就不会发⽣这样的性能损耗了。所以我们建议:让主键具有AUTO_INCREMENT,让存储引擎⾃⼰为表⽣成主键,⽽不是我们⼿动插⼊,比如说我们可以这么定义person_info表:

4.7 冗余和重复索引
有时候有的人有意或者无意的就对同一列创建了多个索引,比方说这样写建表语句:

我们知道,通过 idx_name_birthday_phone_number索引就可以对 name进行快读搜索,再创建一个专门针对 name列的索引就算是一个 **冗余索引,**维护这个索引只 会增加维护的成本,并不会对搜索有什么好处。
另外一种情况就是,我们对某个列重复建立索引,比方说这样:

我们看到,c1既是主键、⼜给它定义为⼀个唯⼀索引,还给它定义了⼀个普通索引,可是主键本身就会⽣成聚簇索引,所以定义的唯⼀索引和普通索引是重复 的,这种情况要避免。
5.总结
5.1 B+树索引在空间和时间上都有代价,所以没事⼉别瞎建索引。
5.2 B+树索引适⽤于下边这些情况:
- 全值匹配
- 匹配左边的列
- 匹配范围值
- 精确匹配某⼀列并范围匹配另外⼀列
- 用于排序
- 用于分组
这里我自己的总结:怎么判断走不走索引?可以看一下这个操作之前的数据是否是有序的,Mysql能不能快速查询,还是得一个个查询,有序的并且能够快速查询(就像快速扫描一样)肯定是能走索引的。
5.3 在使用索引时要注意以下事项:
- 只为⽤于搜索、排序或分组的列创建索引
- 为列的基数⼤的列创建索引
- 索引列的类型尽量⼩
- 可以只对字符串值的前缀建⽴索引 只有索引列在⽐较表达式中单独出现才可以适
- 为了尽可能少的让聚簇索引发⽣⻚⾯分裂和记录移位的情况,建议让主键拥有AUTO_INCREMENT属性。
- 定位并删除表中的重复和冗余索引
- 尽量使⽤覆盖索引进⾏查询,避免回表带来的性能损耗。