1.结构及特性
前面我们实现了无头单向非循环链表,它的结构是这样的:

在这里的head只是一个指向头结点的指针,而不是带头链表的头节点。
而带头双向循环链表的逻辑结构则是这样的
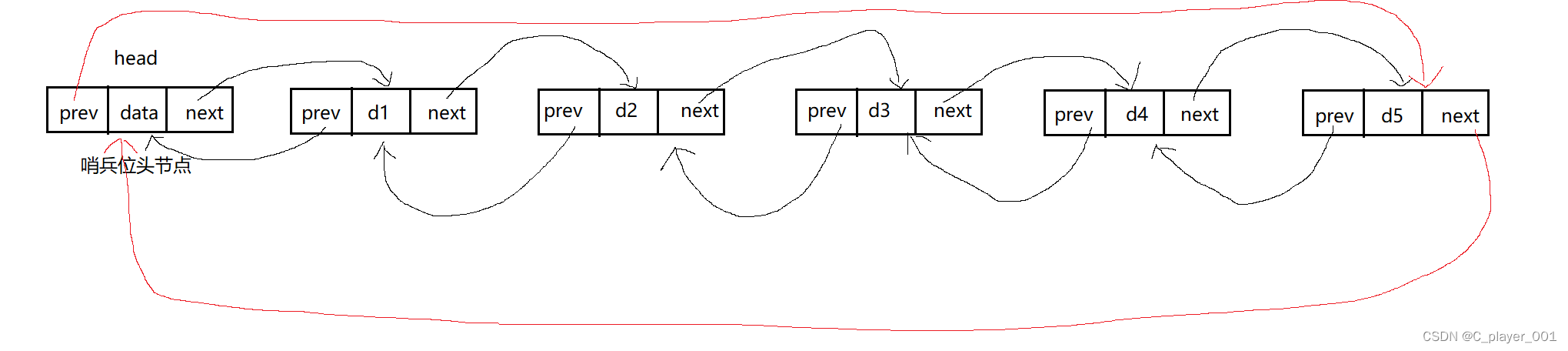
这就是链表的结构,链表的每一个节点都有两个指针,一个 prev 指针指向前一个节点,而 next 指针则指向下一个节点,而当链表为空时,我们就只有一个哨兵位的头节点,
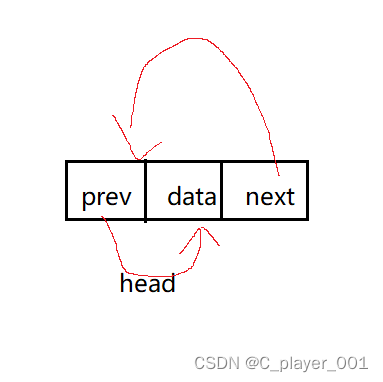
此时头结点的 prev 和 next 都是指向自己的,如果将prev和next设置为空的话,就不符合循环的结构了。带头双向循环链表相对于无头单向非循环链表的优点就是以下几个
1.有哨兵位的头,这时候我们插入数据的时候就不用分情况讨论,因为无论是第一个插入数据还是正常插入数据都是修改的 头节点 的next ,而不会修改头节点的指针,这样一来我们也不用传二级指针来操作了。我们只需要传头结点的指针 phead ,而后我们的插入删除数据都是对 头节点的 prev和next 进行操作,对结构体成员进行修改只要传结构体指针就行了。
2.双向链表,双向链表在进行指定位置之前插入和删除的时候就不用遍历链表去找指定位置的前一个节点了,我们直接用指定节点的prev就能找到前一个节点。
3.循环,循环链表的特性就是头节点的prev指向尾节点,尾节点的next指向头节点,这样一来,对链表进行尾插尾删操作时我们也不用遍历链表去找尾节点和前一个结点了,我们通过头节点就能删除和插入尾节点。
带头双向循环链表虽然结构比单链表复杂得多,但是它的结构带来了很多的优势,对于各种操作都很方便,完美解决了顺序表的所有问题。
2.链表的接口实现
首先我们定义结点的结构,一个数据和两个指向同类型节点的指针。
typedef int LTDataType;typedef struct ListNode
{struct ListNode* prev;LTDataType data;struct ListNode* next;
}LTNode;链表初始化
在这个链表结构的实现中,我们首先要在主函数内定义一个头结点,然后对头节点进行初始化。
//初始化
void LTInit(LTNode* phead)
{assert(phead);phead->prev = phead;phead->next = phead;
}由于头节点的数据我们是不会用的,所以我们直接不管他的数据,将两个指针都指向自己就行了

链表的打印
为了后续的测试方便,我们先将打印函数写出来,打印链表是要遍历链表的,而循环链表的尾节点不会指向NULL,而是指向头节点,所以我们遍历的循环结束条件就是 cur->next != phead ,遍历也是从head的next开始的。同时为了展现双向链表的特性,我们在开头和最后都打印一盒phead,同时数据之间用<=>来连接。
//打印链表
void LTPrint(LTNode* phead)
{assert(phead);printf("phead <=> ");LTNode* cur = phead->next;while (cur != phead){printf("%d <=> ",cur->data);cur = cur->next;}printf("phead\n");
}我们先来测试一下空链表的打印
void test1()
{LTNode head;LTInit(&head);LTPrint(&head);} 
链表销毁
链表的销毁也是从头结点的 next 开始遍历销毁,因为我们的头节点 head 不是动态开辟出来的,所以千万不要对 phead 进行 free 操作,而且我们的头节点也不需要 free ,当链表销毁之后我们对phead的prev和next进行置空。
//销毁链表
void LTDestroy(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* del = cur;cur = cur->next;free(del);}phead->prev = NULL;phead->next = NULL;
}创建节点
由于我们插入数据有多个接口,所以我们写一个创建节点的函数出来。
//创建节点
LTNode* NewLTNode(LTDataType x)
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));if (newnode == NULL){perror("malloc fail");exit(-1);}newnode->data = x;newnode->prev = NULL;newnode->next = NULL;return newnode;
}头插
头插数据在无头单链表的实现中要分两种情况,而在带头链表中我们就都可以一视同仁了。我们正常头插时,首先创建一个新节点,然后让新节点的next指向原来的第一个数据节点,再让原来的第一个数据节点的prev指向新节点,处理完新节点和原头节点的连接关系后再来处理新节点与哨兵位的关系,让新节点的prev指向phead,phead的next指向新节点。
这里同文字描述起来很复杂,但是用图和代码解释起来就会很简单,因为插入节点就只是改变了几个指针的指向。
我们也可以看一下空链表插入是否需要单独讨论。因为空链表的phead 的next和prev都指向phead自己,按照上面的逻辑,首先让新节点的 next 指向phead的 next ,也就是新节点的next 指向phead,然后让phead 的next 的prev指向新节点,也就是phead的prev指向新节点。然后再让新节点的prev指向phead,再让phead的next指向新节点。
文字描述还是很复杂,用途来说明就能知道同样的逻辑也适用于空链表头插。

//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = NewLTNode(x);newnode->next = phead->next;phead->next->prev = newnode;phead->next = newnode;newnode->prev = phead;
}写完头插代码之后我们测试一下头插。
LTNode head;LTInit(&head);LTPushFront(&head, 1);LTPushFront(&head, 2);LTPushFront(&head, 3);LTPushFront(&head, 4);LTPrint(&head);

尾插
尾插的方式跟头插类似,主要也是要注意指针修改的顺序,要先对新节点和原来的尾节点进行链接,然后再对phead和新节点链接。
其中1和2的顺序是可以变的,3和4 的顺序也是可以变的。再来看一下空链表的尾插。

我们可以发现他们的逻辑是一样的,所以也不要单独处理空链表的尾插。
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = NewLTNode(x);newnode->prev = phead->prev;phead->prev->next = newnode;newnode->next = phead;phead->prev = newnode;
}尾插测试
//尾插尾删
void test2()
{LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTPrint(&head);}
头删
头删我们只需要把phead的next指向第二个数据节点,而后让第二个数据节点的prev指向phead,最后释放第一个节点就行了。 我们再看一下只有一个数据时的头删要不要单独处理,首先将phead的next指向phead的next 的next,也就是phead自己,再将phead的next的next 也就是phead的prev指向phead,然后释放掉数据节点,这时候phead就回到了初始化的样子,所以上面的逻辑也完全适用于一个节点的头删.
我们再看一下只有一个数据时的头删要不要单独处理,首先将phead的next指向phead的next 的next,也就是phead自己,再将phead的next的next 也就是phead的prev指向phead,然后释放掉数据节点,这时候phead就回到了初始化的样子,所以上面的逻辑也完全适用于一个节点的头删.

但是在删除数据之前我们要判断是否为空链表,为了方便,因为后面的尾删也需要判断,所以我们写一个函数来实现判断。
//判断链表是否为空
bool LTEmpty(LTNode* phead)
{assert(phead);//如果为空链表就返回true//否则返回falsereturn phead->next == phead;
}//头删
void LTPopFront(LTNode* phead)
{assert(phead);assert(!LTEmpty(phead));//链表为空LTNode* del = phead->next;phead->next = phead->next->next;phead->next->next->prev = phead;free(del);
}测试头删
一个一个把数据删完
LTNode head;LTInit(&head);LTPushFront(&head, 1);LTPushFront(&head, 2);LTPushFront(&head, 3);LTPushFront(&head, 4);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);
再测试对空链表头删
LTNode head;LTInit(&head);LTPushFront(&head, 1);LTPushFront(&head, 2);LTPushFront(&head, 3);LTPushFront(&head, 4);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);LTPrint(&head);LTPopFront(&head);
尾删
尾删函数我们也是要找到倒数第二个节点,然后将这个节点和phead链接起来,最后free尾节点就行了。

当只有一个节点的时候尾删,

他们的逻辑也是一样的
//尾删
void LTPopBack(LTNode* phead)
{assert(phead);assert(!LTEmpty(phead));//判断是否为空链表LTNode* del = phead->prev;phead->prev->prev->next = phead;//倒数第二个节点链接pheadphead->prev = phead->prev->prev;free(del);
}测试尾删,先逐个删除直到删空
LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTPrint(&head);LTPopBack(&head);LTPrint(&head);LTPopBack(&head);LTPrint(&head);LTPopBack(&head);LTPrint(&head);LTPopBack(&head);LTPrint(&head);

再对空链表尾删

查找函数
查找函数只能便利查找,遍历的循环条件也是和打印函数一样的,找到就返回链表节点指针,找不到就返回空指针。
//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){if (cur->data == x){return cur;}cur = cur->next;}//找不到返回NULLreturn NULL;
}
我们测试查找函数直接同时兼顾修改函数的功能。
LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTNode* pos = LTFind(&head,1);pos->data = 10;LTPrint(&head);
这时候我们通过返回的结点指针将1修改成了10,说明函数功能是正常的。
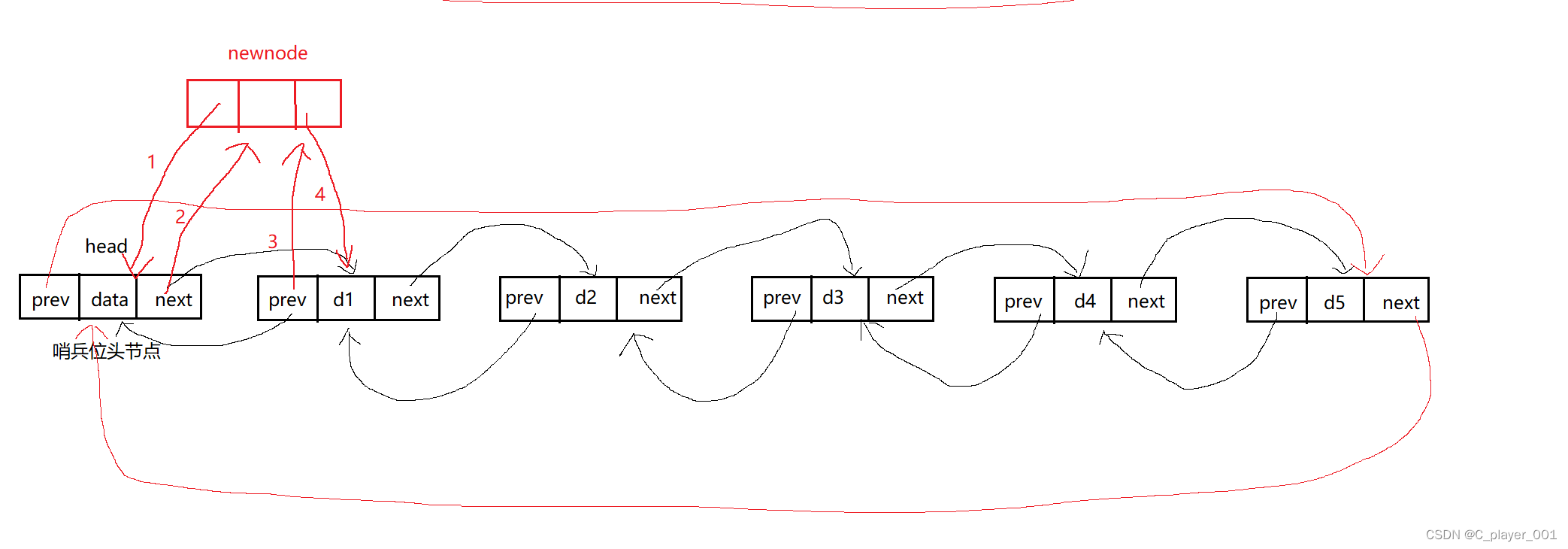
指定位置(之前)插入
我们在指定位置之前插入数据只需要将这个节点的前一个结点与新节点链接起来,再将新节点与该节点链接起来就行了。
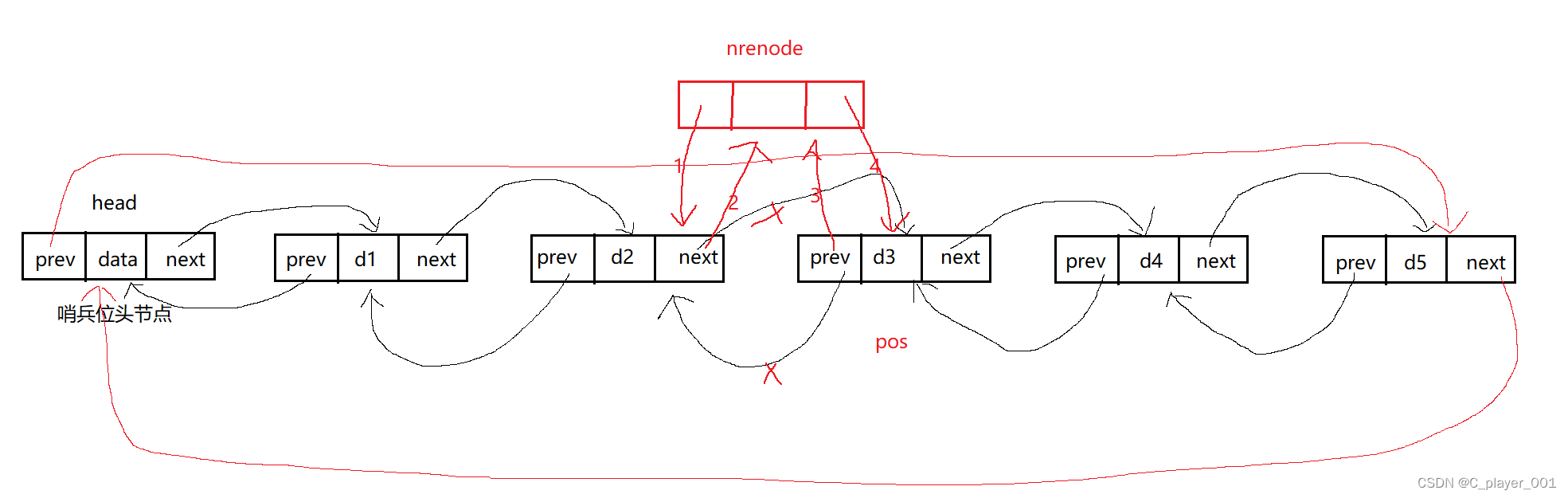
当pos是第一个数据节点的时候,也就是头插的时候,逻辑与上面的也是一样的
当pos是phead,这时候在哨兵头节点之前插入就是尾插了,逻辑也和正常插入一样

我们实现插入函数的时候就不用考虑空链表的情况了,这是使用者要考虑的事情,然后我们只要判断pos是否为NULL就行了。
//指定位置之前处插入
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = NewLTNode(x);pos->prev->next = newnode;newnode->prev = pos->prev;pos->prev = newnode;newnode->next = pos;}测试插入函数
LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTNode* pos = LTFind(&head,1);LTInsert(pos, 10);LTPrint(&head);
这说明我们的插入函数是能够成功实现头插的。
然后再测试是否能够实现尾插
LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTNode* pos = LTFind(&head,1);LTInsert(pos, 10);LTInsert(&head, 50);LTPrint(&head);
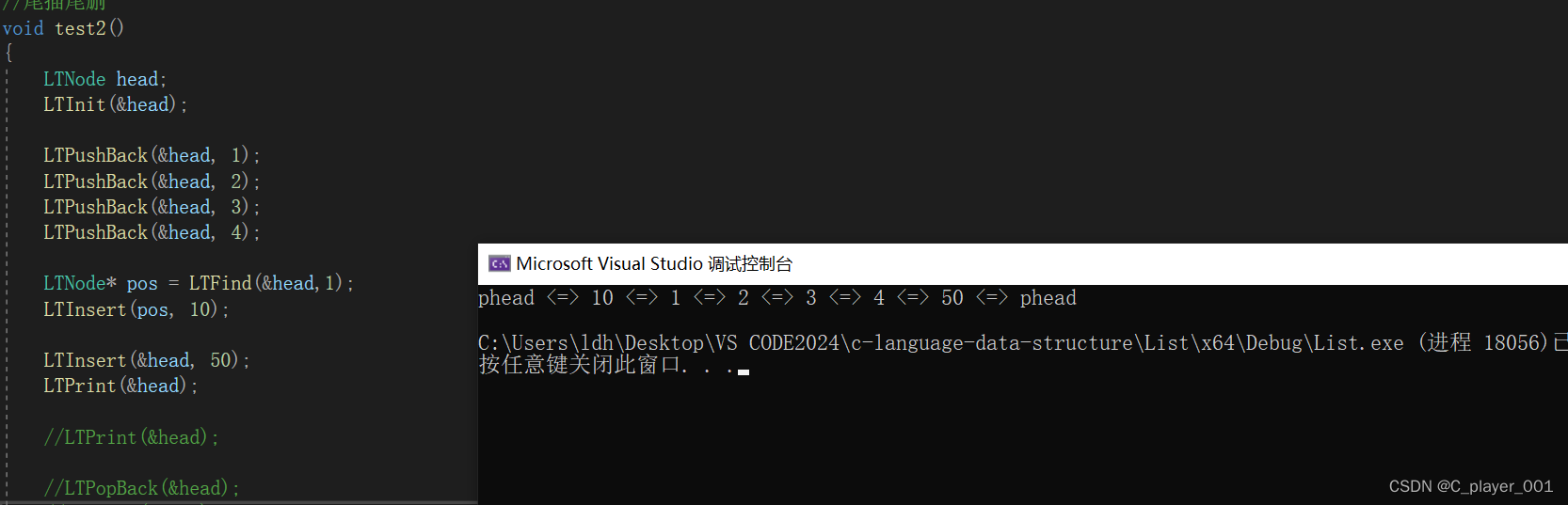 功能正常,这时候我们就能把前面写的头插尾插函数修改成用插入函数来实现的了。
功能正常,这时候我们就能把前面写的头插尾插函数修改成用插入函数来实现的了。
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTInsert(phead->next, x);
}//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTInsert(phead, x);
}删除指定位置
在这个函数中我们不用考虑链表为空的情况,这也是使用者该注意的事情。而指定位置的删除首先就是要将指定位置的前一个结点和后一个节点链接起来,然后再free掉pos节点。

而这个逻辑对于头节点和尾节点肯定也是适用的,大家可以自己去画图验证了。
//指定节点删除
void LTErase(LTNode* pos)
{assert(pos);pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);
}我们来测试一下删除头节点的情况
LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTErase(head.next);LTPrint(&head);

再测试一下删除尾节点
LTNode head;LTInit(&head);LTPushBack(&head, 1);LTPushBack(&head, 2);LTPushBack(&head, 3);LTPushBack(&head, 4);LTErase(head.prev);LTPrint(&head);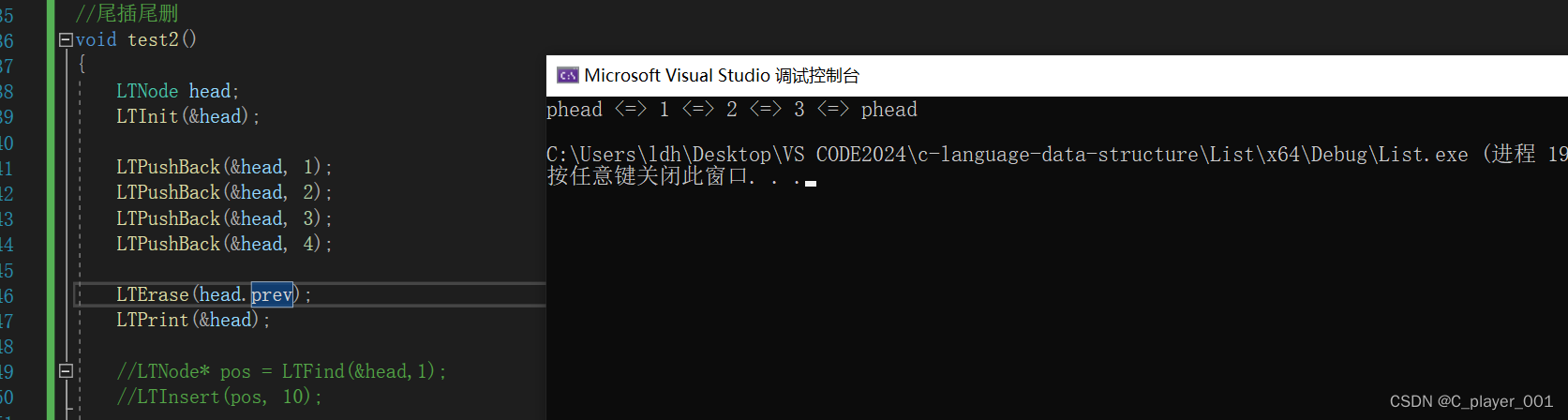
函数功能实现地没有问题,这时候我们就能用Erase去改造之前写的头删尾删了。
//头删
void LTPopFront(LTNode* phead)
{assert(phead);//头删要判断链表是否为空assert(!LTEmpty(phead));LTErase(phead->next);
}//尾删
void LTPopBack(LTNode* phead)
{assert(phead);//尾删也要判断链表是否为空assert(!LTEmpty(phead));LTErase(phead->prev);
}求数据个数
我们可以再设计一个函数来求链表的数据个数,同样是要遍历链表,与打印函数的遍历是一样的。
//求数据个数
size_t LTSize(LTNode* phead)
{assert(phead);if(LTEmpty(phead)){return 0;}size_t size = 0;LTNode* cur = phead->next;while (cur!=phead){size++;cur = cur->next;}return size;
}总结
虽然带头双向循环链表的结构比单链表要复杂的多,但是他的结构带来的优势就是增删的操作都十分简单,而且头插尾插能完全复用插入函数,头删尾删也能完全复用删除函数,代码量变小了很多,只要我们理解了指针之间的逻辑关系,这种结构使用起来就十分方便了。