在分布式领域里,一致性成为了炙手可热的名词,缓存、数据库、消息中间件、文件系统、业务系统……,各类分布式场景中都有它的身影,因此,想要更好的理解分布式系统,必须要理解“一致性”这个概念。
其实关于一致性的讲述,之前聊《深入浅出 -- 系统架构之分布式CAP理论和BASE理论》这两个分布式理论时也曾提及过,讲到CAP一致性是数据一致性,BASE一致性则是指状态一致性,不过当时讲的不够具体、不够体系化,更多是围绕着两个分布式理论在阐述,而本文就展开聊聊 分布式系统里的一致性模型。
一、重要的一致性模型
回想《深入浅出 -- 系统架构之分布式CAP理论和BASE理论》聊到的一致性:
CAP一致性:任何时间点,在任意节点上看到的数据完全一致;BASE一致性:数据只能从一个一致状态变化到另一个一致状态。
CAP理论针对的是数据一致性,主要关注怎样维持多副本的一致性视图,即如何使多个节点上的数据,对外表现的和一份数据一样。BASE理论关注状态一致性,主要在于根据业务需求操作不同节点的数据时,最终实际执行结果和我们的观念一致,即分布式系统中的业务操作,执行完成后结果都在预期之内,而不是"部分成功、部分失败"这种预期之外的结果。
这两个一致性的定义,涵盖了分布式系统中的所有场景,建立在这两个定义的基础上,又存在三种较为重要的一致性模型,即强一致性、弱一致性、最终一致性,这三个一致性模型,作用在数据一致性、状态一致性上的含义并不相同,为了更好的说明不同的一致性模型,我们先针对数据一致性、状态一致性分别给出个例子,后续分析会建立在这两个案例的基础上进行展开探讨~
实际一致性模型只有强一致性、弱一致性两大类之分,所有不满足强一致性要求的,都能被称之为弱一致性,因此,最终一致性是一种另类的弱一致性体现,而弱一致性还有很多其他的细分,如顺序一致性、因果一致性、会话一致性、客户端一致性、单调读一致性、单调写一致性等多种,这里暂时不做展开,后续会简单提及。
数据一致性案例:互联网大流量的背景下,为了保证服务可用性,通常会采用集群化模式部署,以此实现任意节点故障,都不会影响系统正常的对外服务能力:

如上图所示,这是一个十分典型的高可用场景,采用集群式部署,当外部向系统写入一个值X后,该值会被同步给集群内剩余两个节点,从而保保证所有节点的数据一致性,流量切至任意节点,都能确保看到的数据相同。
状态一致性案例:为了尽可能提升系统吞吐量,也会将原本单个庞大的系统,拆分成多个子系统/微服务运行,一个业务需求由多个服务一起满足,多个服务之间通过远程调用来进行交互与通信,如下:
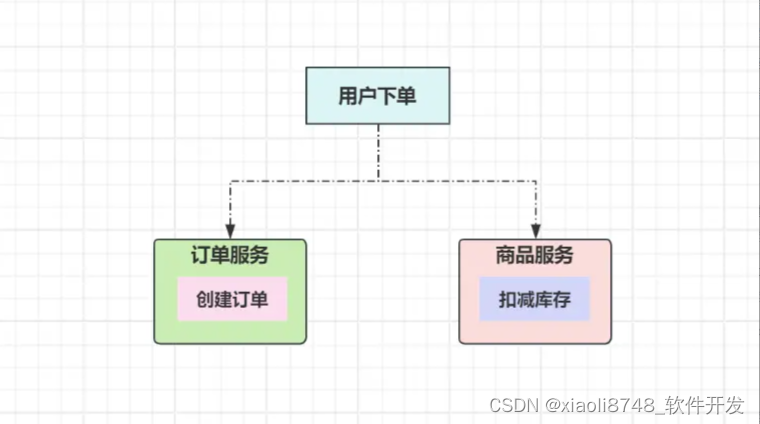
这是一个简化到极致的下单场景,只由创建订单、扣减库存两个动作组成,在分布式系统中,每一个下单请求都会执行这两步操作。按照我们的观念,创建一笔订单后,相应的库存都会进行扣减,这样的结果才符合设想的预期,而这种符合我们预期的结果,则满足状态一致性的要求,毕竟整体数据的变化是一致的(具体可参考《状态一致性》)。
好了,有了上述两个案例作为分析的基础,下面来对常见的三个一致性模型进行展开。
1.1、强一致性模型
强一致性,又称原子一致性、线性一致性、严格一致性、实时一致性……,它是一种苛刻的一致性要求,这是实现难度最高、可用性最低、性能最差的一致性模型,先来看看数据的强一致性。
1.1.1、数据强一致性
还是这幅图:

当外部写入X值在A节点成功后,B、C节点应该立即能看到此数据,只有这样才是满足强一致性要求的。这个要求听起来没啥特别,但要注意,集群内各节点的数据同步工作,依靠网络完成,走网络需要时间成本,无论如何优化,A和B、C节点间都会存在短暂的不一致,而这就打破了“强一致性”的要求。
那该怎么做?在之前有提过,如果想要保证所有节点的数据强一致,那就在数据写入时下功夫,即X写入A节点后,并不代表X写入成功,需要继续在B、C节点写入成功后,才算数据写入完成,这样就能保证强一致性。当然,这样还不够,对数据读取请求也得进行控制,如下:
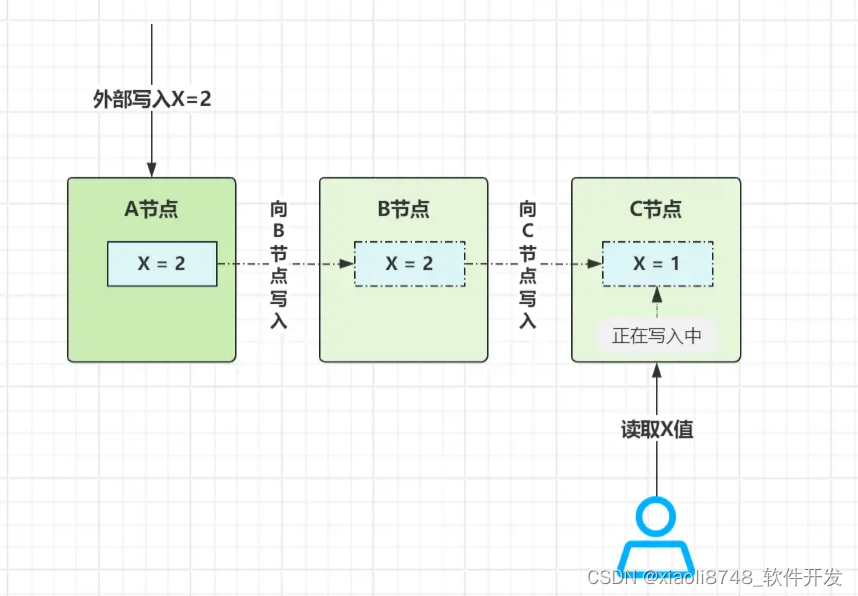
当数据在A、B节点写入完成、C节点正在写入中,此时去C读取数据会怎么样?答案是看到X=1这个旧值;当请求去A读值,为了保证看到的数据相同,这时A就不能返回X=2这个新值,而是同样返回1(需设计类似于MVCC这种多版本并发机制),这样才能保证所有节点的强一致性。
1.1.2、状态强一致性
前面说清楚了数据的强一致,接着来聊聊状态的强一致性,回到最开始给出的下单场景:
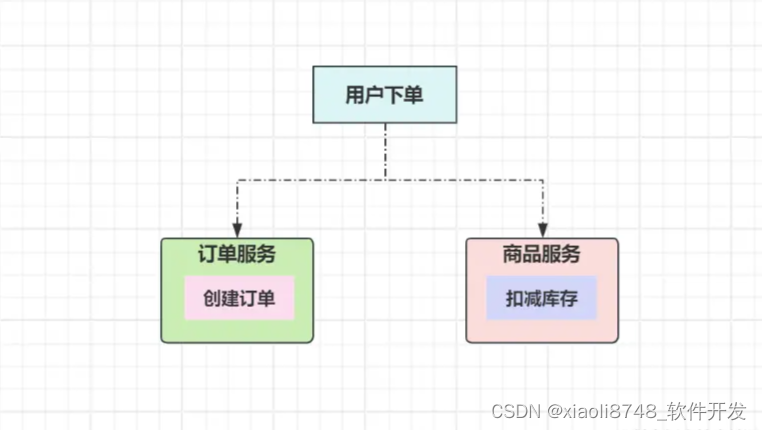
想要保证这个场景中的状态强一致,意味着需要保证创建订单、扣减库存操作一起完成,即订单服务创建订单后,不能立马将订单数据提交,必须等扣减库存成功才行。如果扣减库存未完成,前面的订单数据就需要一直阻塞等待,也就是典型的XA事务模式,在分布式场景中咋实现?
首先要引入独立的事务管理者,分布式事务对应的多个操作,会被视为一个“事务组”:

上述下单场景中,两个动作分别对应着两个子事务,在创建订单后,首先订单服务会向事务管理者中注册一个事务组,而后把创建订单的执行结果(成功或失败)提交给管理者;接着商品服务开始执行,执行完成后也会将结果加入到前面创建的事务组中。
两个子事务均已抵达事务管理者后,事务管理者会做统一的决断,当事务组所有子事务都执行成功后,才会真正向该组事务的参与者下发“提交事务”的信号,此时整组事务才会真正被提交。同理,只要一个子事务失败,整组事务都需要被回滚(具体原理可参考:《手写分布式事务框架篇》)。
上述方案中,在事务管理者没有下发最终处理结果之前,所有子事务都需要阻塞等待,从而保证状态的强一致性,整体数据一起从一个状态转变为另一个状态。尽管这种方式能实现接近于ACID原则的强一致性效果,可对应的代价是牺牲掉一定的可用性,一方面阻塞的事务会长时间占用着数据库连接不释放,另一方面则会延长接口响应时间,影响整体的性能。
1.2、弱一致性模型
聊完了强一致模型,接着来看看弱一致性模型,它与强一致截然相反,即:虽然我提供了一致性的支持,但系统可能会出现不一致的现象,对这种不一致的情况,我也不保证它最终会变成一致的结果。这有点类似于Redis提供的“弱事务机制”,Redis虽然提供了事务相关的命令支持,但它并不保证事务一定生效,并且对于失效的现象不会有任何补救措施,下面套进案例中讲述。
1.2.1、数据弱一致性
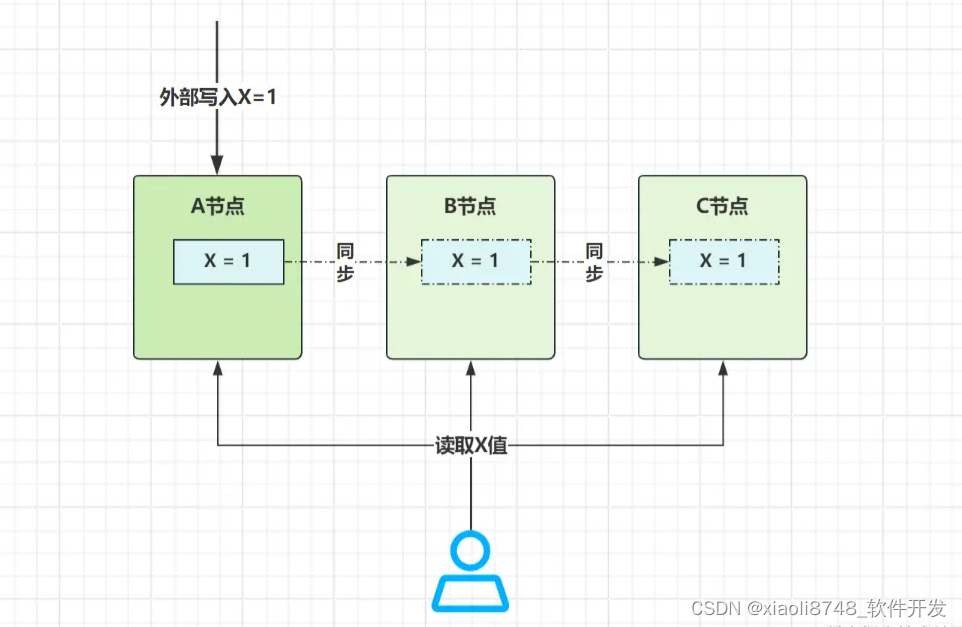
依旧看到这幅图,当外部写入X=1的数据到A节点后,立马会向客户端返回写入成功,而数据如何交给B、C节点呢?通过异步的方式完成。如果异步复制时出错,好比B节点在同步时宕机,就算恢复后,也不会管X这个值,毕竟“我”是弱一致性呀,如果你运气好,写进来的值在所有节点里最后肯定会一致,如若运气不好,丢了就丢了,跟我没关系~
综上,数据弱一致性模型,在写入成功后,即不保证相同时刻所有节点读到的值相同,也不保证故障节点恢复后,会和其他保持相同的最新数据。
1.2.2、状态弱一致性
相信经过前面的案例,大家也能猜出来弱一致模型作用在“状态”上的效果,即正常情况下,创建订单和扣减库存都会正常提交,此时整体数据的变化是一致的,订单数据、库存数据都从“初始态”变成了“结果态”。可是在不正常的情况下,有可能碰到“订单有了、库存没扣”这种状态不一致的变化,就这种情况来说,弱一致模型不会做任何处理。
大家能很明显的感受出,弱一致模型其实很不靠谱,它不承诺会数据/状态会立马一致,也不承诺多久后能达到一致,只尽可能保证正常情况下的一致性,但凡出现特殊情况,就会造成不一致的场景出现。
1.3、最终一致性模型
一开始提到过,最终一致性是弱一致性的另类表现,也是最重要的弱一致性模型,也是各种分布式系统中最推崇的一致性模型,即:不保证数据/状态立马一致,但保证经过一定时间后,最终肯定能收敛到一致状态。
1.3.1、数据最终一致性
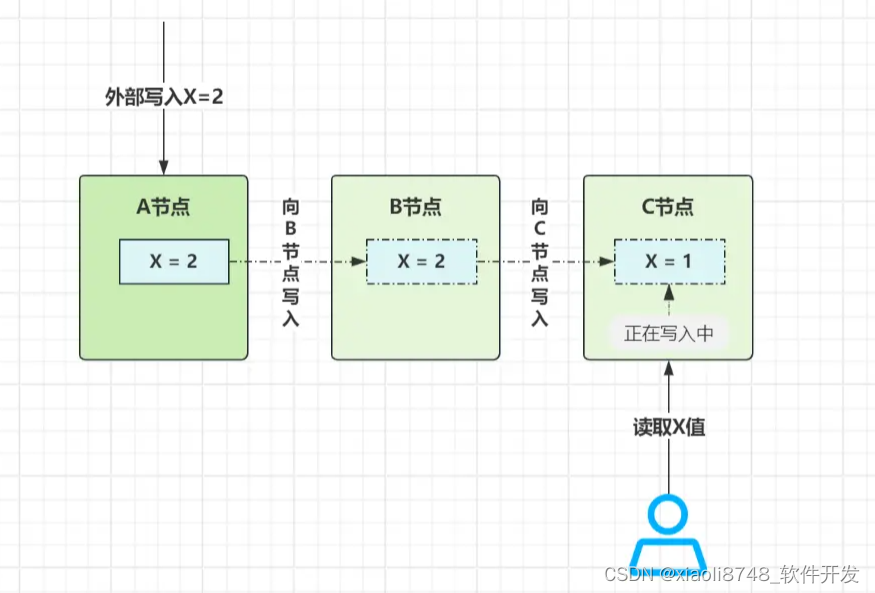
此时外部请求将X值从1更新成2,在A节点更新成功后立马返回,X=2这个值,通过异步方式同步给B、C节点。而在“A节点写入成功、B、C节点同步完成前”这段时间内,属于“不一致窗口”,如下:
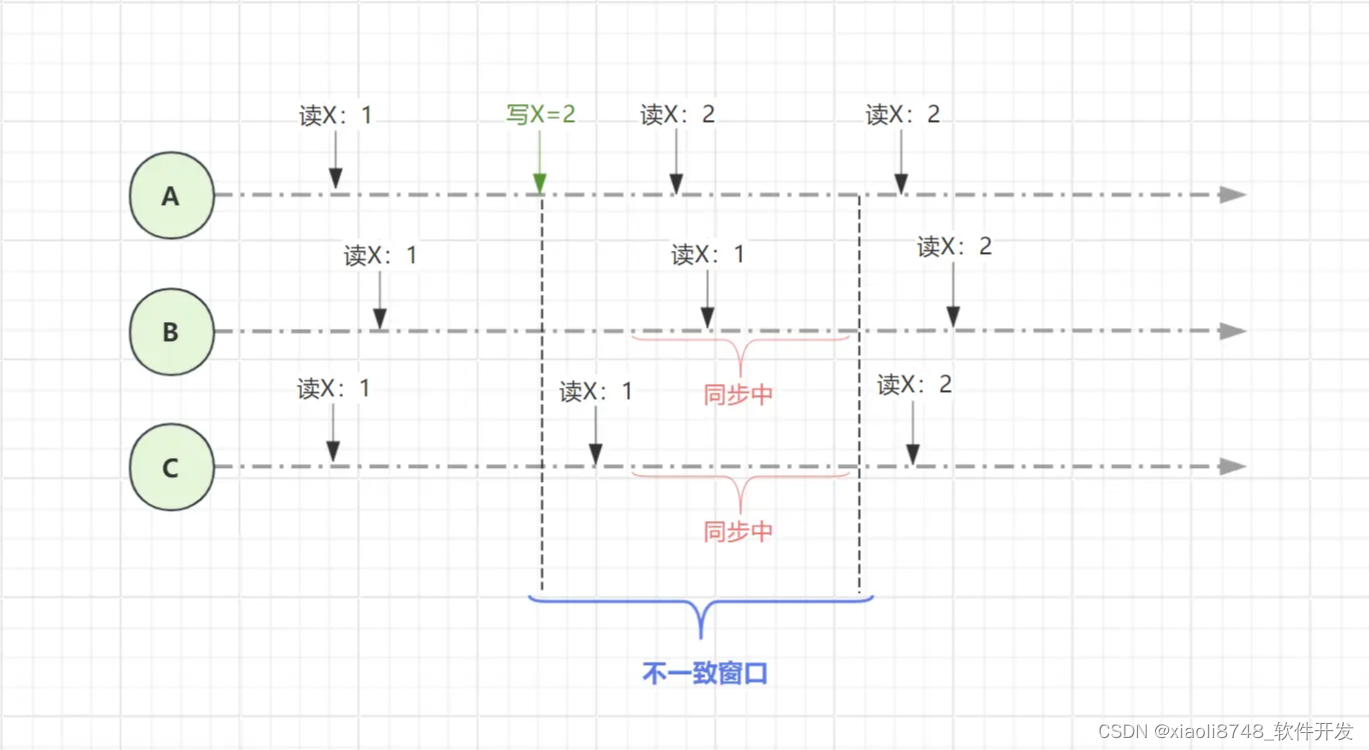
如上图所示,在不一致窗口内,在不同节点有几率看到不一样的值,但这种不一致的现象很短暂,随着不一致窗口结束,集群内所有节点依然会保持数据的一致性。同时,对于B节点同步时发生故障这种现象,在B节点恢复后,会用自身数据和集群其他节点比对(如比对POS点),如果发现其他节点的数据更新,则自动从最新的节点上拉取数据,以此实现最终一致性模型。
大多数存储型组件实现的主从集群,其支持的异步复制、半同步复制模式,就是最终一致性模型的落地。
状态的最终一致性,在分布式理论篇的《重新理解BASE理论》阶段有结合案例讲解:
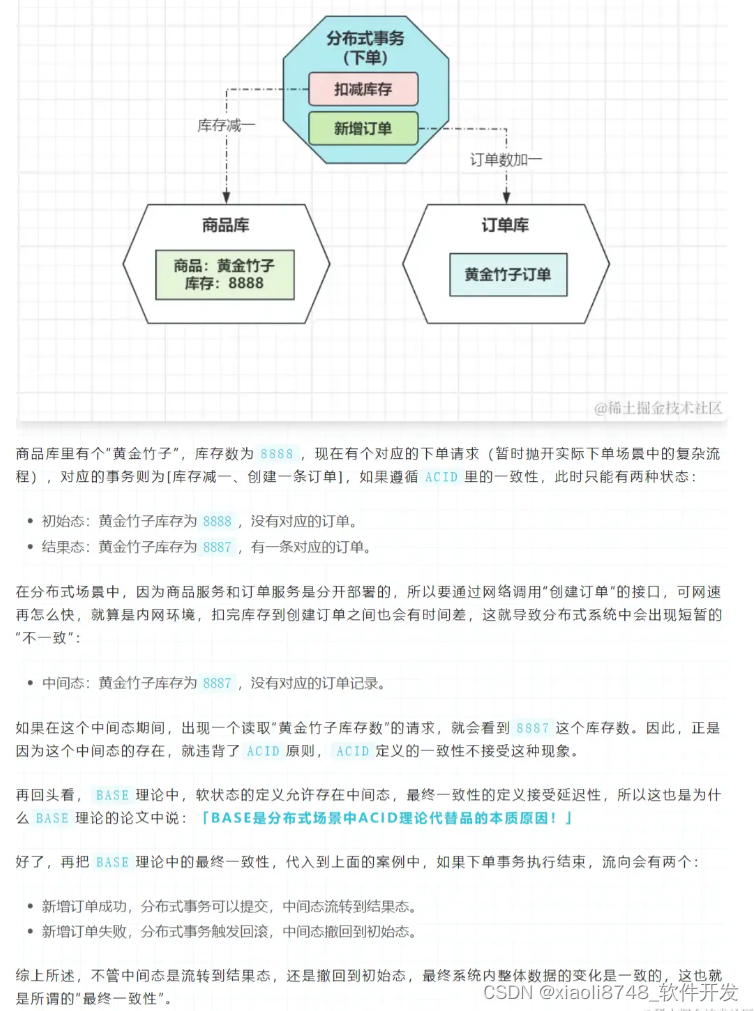
因为之前写过这块,所以不再重复赘述,下面总结一下常见的三种一致性模型。
1.3.2、常见的一致性模型小结
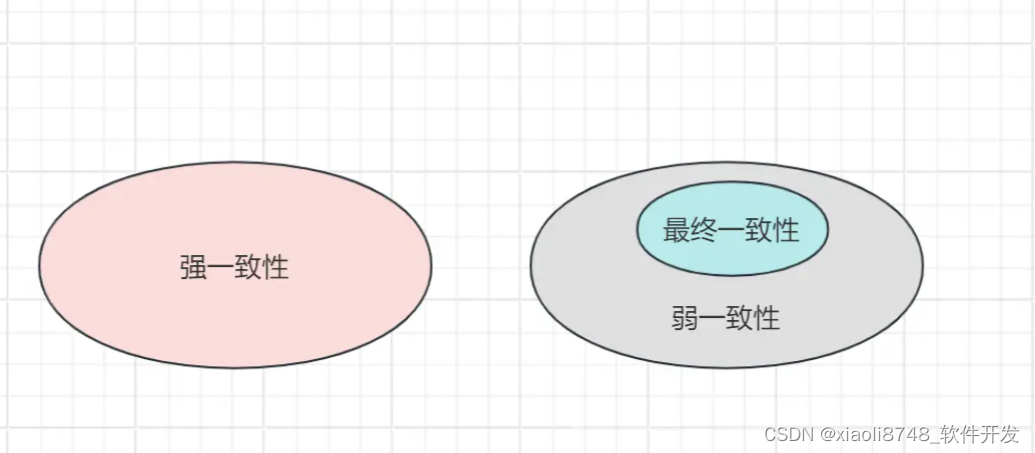
前面简单讲述了三种常规的一致性模型,强一致性最理想,但性能方面不可直视;弱一致性性能很棒,可是太不靠谱;而最终一致性,则是弱一致性的特例,在弱一致性模型中,在保证性能的同时,也尽力保证了一致性,最多只会出现一定时间的“不一致窗口”,换到生活中,三种一致性模型的释义如下:
- 强一致性:我们在一起吧!现在就去民政局领证!
- 弱一致性:我们在一起吧,结婚看情况咯,能结就结吧,结不了就算了。
- 最终一致性:我们在一起吧,虽然现在不能立马领证,但最后我们肯定会结婚的。
好了,对这三种常见一致性模型有了认知后,接着来看看弱一致模型中的其他衍生,如前面提到的顺序一致性、因果一致性、会话一致性、单调读一致性、单调写一致性等等,不过弱一致性模型的大家族中,只有最终一致性模型较为重要,剩余这些简单了解即可。
二、弱一致性大家族
上面提到了一堆“一致性模型”,但其实很多模型是用在CPU多核架构上,而并非是针对分布式领域提出,多核架构的CPU,允许多条线程并行执行,而多线程执行是无序的,这些模型定义了 不同线程并行执行时,如何保证CPU寄存器、CPU高速缓存区、机器内存之间的数据一致性。
当然,本阶段只简单探讨这些一致性模型,不对各类操作系统中的具体实现进行分析,如因特尔的
MESI协议,其他厂商的MOESI、MSI、MOSI、Synapse、Firefly、DragonProtocol等等,感兴趣的小伙伴可自行去研究。
2.1、顺序一致性
顺序一致性,从它的名字应该也能猜出大致含义,它并不要求数据或状态要严格一致,但起码要保证顺序的一致,啥意思?来看例子:
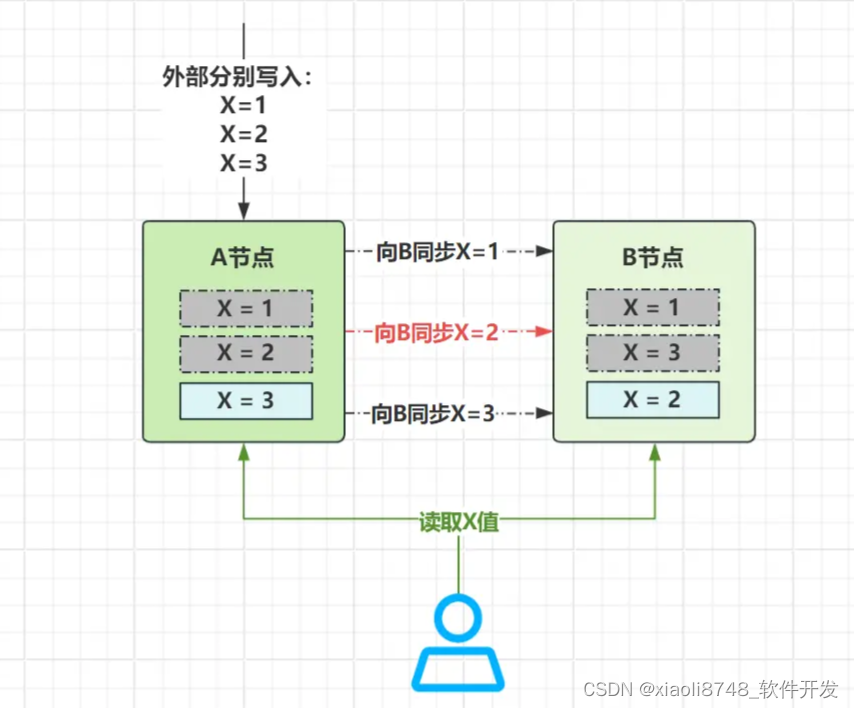
客户端分别按序将A中X值变更成1、2、3,接着按照向节点B依次同步,可是在同步X=2这个值时,由于网络延迟问题,导致比X=3要晚到B节点,因此B节点会按1、3、2的顺序进行同步。这时,当读取请求分别去到A、B节点读X值就会不一致。
顺序一致性,则是约束上面说的这种现象,它并不要求A更新的值,立马能够在B看到,但起码要按照写入A的顺序去同步数据,不管遇到何种问题,一定要保证B节点上读取时,和A节点相同!同理,换到之前分布式事务的例子中,下单流程是先创建订单、再扣减库存,总不能库存已经扣了,却没有对应订单产生(MQ的顺序消费,也有这个含义在里面)。
2.2、因果一致性
因果一致性并不要求完全满足顺序一致,但要保证因果一致,来看例子:
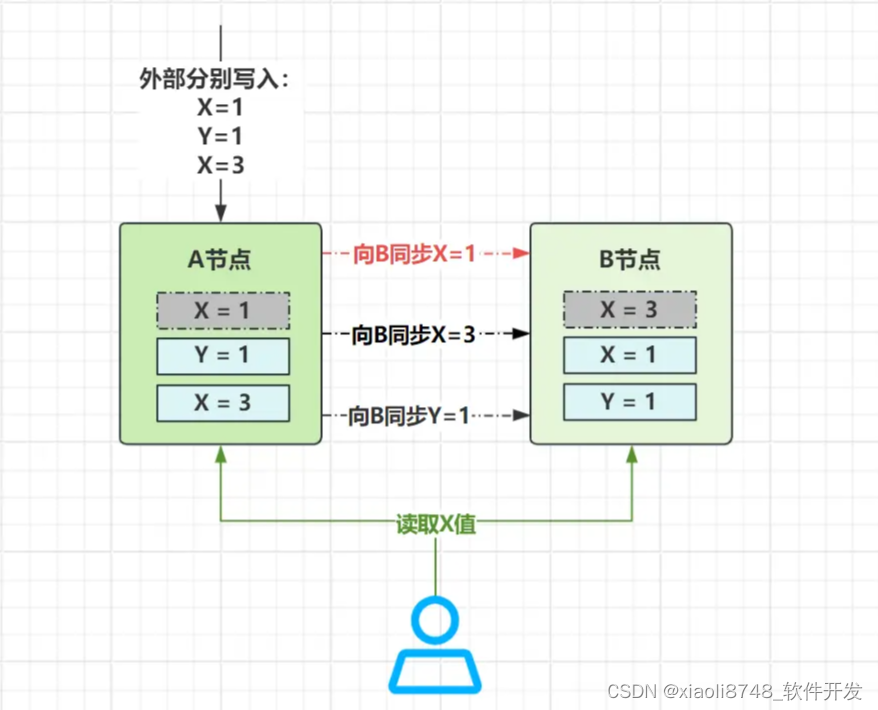
外部按序向A写入X=1、Y=1、X=3三次值,其中X=1、X=3写的是同一个数据,两个操作之间存在因果关系。此时就必须保证:B节点上X=3的同步工作,要发生于X=1之后!如图中所示,X=1同步出现网络延迟,导致X=3先完成同步,此时从B读数据,就会先读到X=3,再读到X=1,这就颠倒了因果关系。当然,至于不存在任何关联关系的Y=1,随便打乱顺序到任何时间点都行!
大家观察会发现,因果一致性比顺序一致性更宽松,不要求全局所有顺序一致,但必须存在“因果关系”的操作,则要保证顺序的前后性。不过,怎么判断两个操作间是否存在因果关系,不同的分布式系统或许有不同的设定,上面的案例属于一种(数据依赖因果关系),再来看个例子:
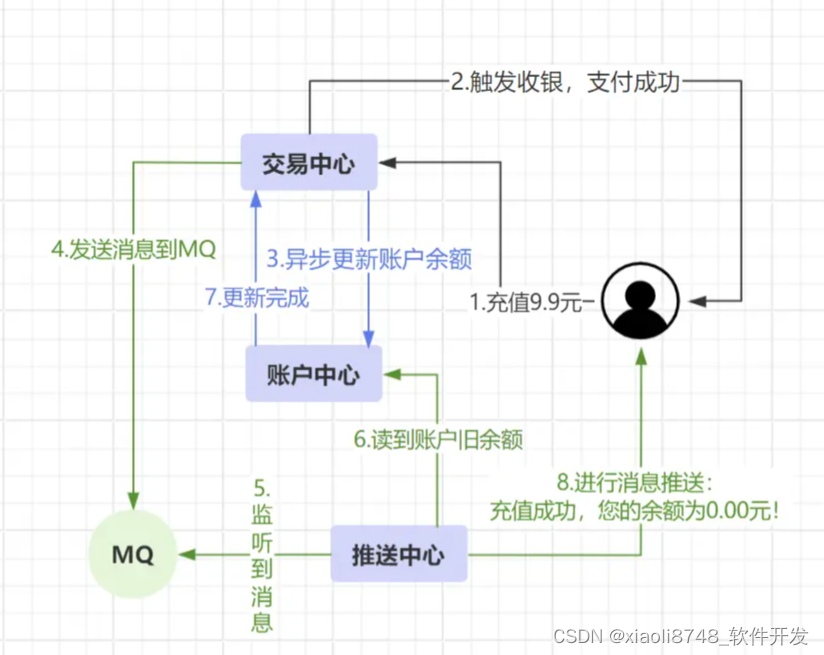
小竹在平台充值9.9元巨资,先走交易中心完成支付,接着异步更新账户中心的余额,并将“支付成功”的消息发送到MQ,推送中心立马监听到支付消息,于是触发推送机制,从账户中心读取旧余额:0.00元,并向小竹推送了一条信息:
“充值成功,您的余额为0.00元!”
这合理吗?答案显而易见。在这个例子中,更新账户余额、读取余额推送两者存在因果关系,必须要保证更新余额先发生于推送之前,否则就会出现上述问题,这则是业务逻辑上的因果关系。
再来个例子,比如分库分表中,订单分了四个库,小竹下了一笔组合单,生成订单时,被系统自动拆分成了三个子订单。在订单数据分片时,主订单和其中两条子订单,落入到第一个节点,而另一条子订单落入到第三个节点,后续关联查询时,就无法查询出组合单的所有子单。
在订单数据分片场景中,主单、子单存在因果关系,必须让这种具备因果关系的订单,同时落入到一个节点中,这样才能保证后续查询的订单信息一致!类似的场景还有很多,总之存在主外关联关系的数据,在进行分片存储时,相同主键的数据一点要落入到相同节点。
PS:其实还有很多因果一致性的场景,这里不再一一例举,经上面阐述,相信大家能理解因果一致性模型。
2.3、会话一致性
会话一致性,相信这个大家并不陌生,在很早之前的开发业务系统时,用户登录后的信息,通常都会直接存储在服务端的Session里,接着给客户端(如浏览器)返回一个SessionID,当同一个已经登录过的客户端,再次请求系统时,就能直接根据SessionID拿到前面的登录信息,从而避免本次请求进行重复登陆。
上述这种方案,将系统集中式部署在单台机器上,这是没有问题的,可是换到分布式系统中,如采用集群模式部署,这时就会出现问题:集群内每个节点都有自己的Session存储空间,当客户端请求第一次去到A节点并登录成功,第二次请求分发到C节点,因为登录凭证存储在A上面,所以C又会要求客户端重新登录。

这对客户端来说,显然并不合理,明明我刚刚才登陆过,凭什么又叫我登录啊?这就是分布式系统中的会话不一致问题。不过这类问题解决起来很容易,只需要将原本保存会话信息的空间,挪出来让所有节点共享即可。
好了,上面是会话一致性的一种体现,在分布式存储系统中,会话一致性有着不同的释义。具体来说,它保证在同一个有效的会话中,一旦客户端更新了某个数据项的值,那么在这个会话中,客户端在读取这个数据项时,将不会读到比这个更新值更旧的值。
大家看这个定义,是不是和“事务机制”有点类似?比如在MySQL中,T1事务将ID=1的name字段,从ZhuZi更新为XiongMao,T1事务再次查询ID=1的数据行时,将不会读到XiongMao之前的name值。当然,如果事务T2读取ID=1的数据呢?并不保证能读到最新的值,毕竟T1可能还未提交事务。
在分布式存储系统中同理,会话一致性保证:客户端在进行更新操作后,在同一会话中始终能读到该数据项的最新值。不过它只保证单次会话内数据的一致性,而对于不同会话间的数据,一致性则没有保障。
三、客户端一致性
客户端一致性针对的是分布式存储领域,是站在一个客户端的角度观察系统的一致性,它确保了同一客户端对相同数据访问的一致性,但并不为不同客户端的并发访问提供一致性保证。再来看到这幅图:
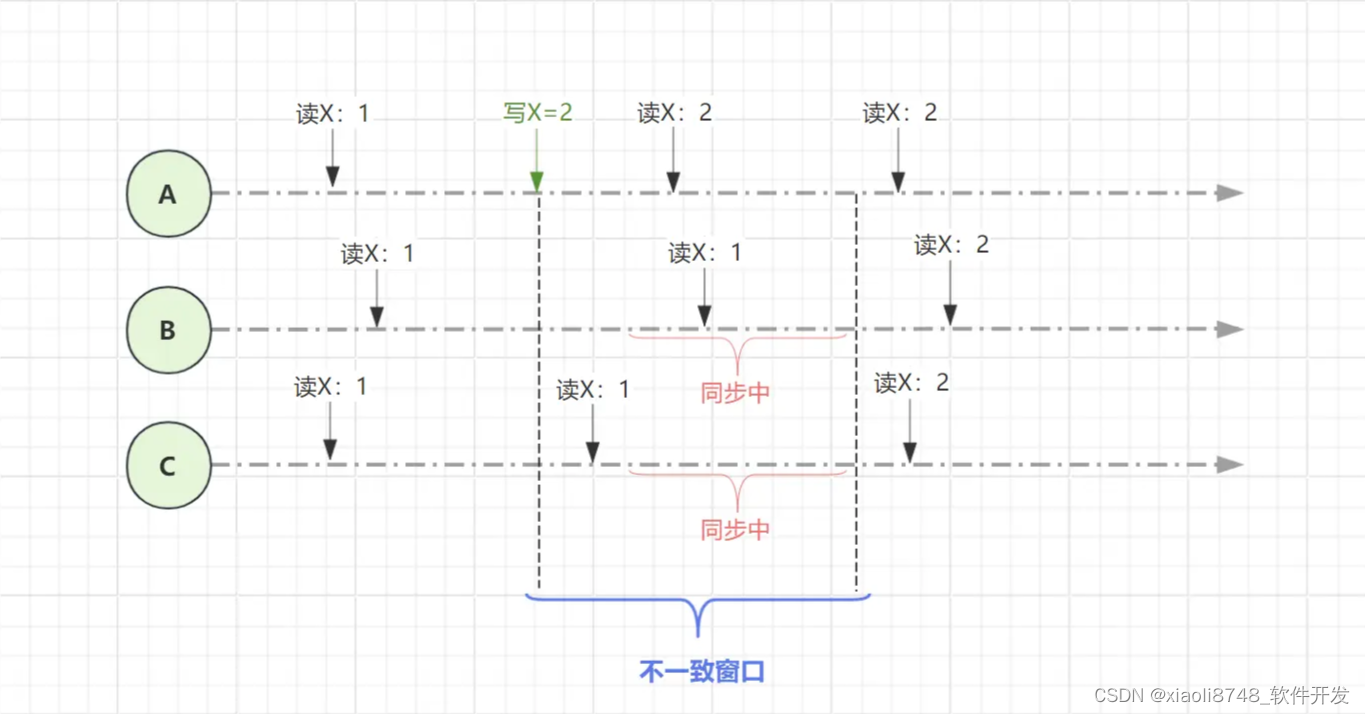
在之前聊到的最终一致性模型中,一个客户端在“不一致窗口”期间内,访问不同节点的同一数据时,由于数据复制的延迟性,可能会出现读到不同的数据。为了解决此问题,业界提出了以客户端为中心的一致性模型,客户端一致性涵盖了多种策略:
- ①
Writes-Follow-Reads Consistency:写跟随读; - ②
Pipeline Random Access Memory:管道随机访问存储; - ③
Read Replica Selection:读取副本选择; - ④
Read Consistency Level:读取一致级别; - ⑤
Write Commit Level:写入提交级别;
这些策略都是用来保证在同一个客户端的视角下,相同数据的读取和写入是一致的,但不同策略在数据一致性、延迟、吞吐量等方面有不同的权衡和取舍,下面咱们来挨个看看。
3.1、写跟随读策略
Writes-Follow-Reads Consistency写跟随读,也称为会话因果一致性(session causal),即会话一致性、因果一致性的“组合版”,这是一种确保客户端读取和写入一致性的策略,它强调在一个客户端的读写操作中,写操作应该跟随之前的读操作,以保证数据的读写一致性。
写跟随读策略要求,当客户端读取某个数据项的值后,如果它随后决定写入一个新值,那么这个新值必须是在读取时看到的值的后续版本,啥意思?来举个例子。
假设你正在玩
游戏中途,你决定通过“氮气加速”并超过前面的玩家,你按下加速按钮,就相当于一个“写操作”,你希望服务器更新你的赛车的速度和位置,并同步给其他玩家。
套入写跟随读策略的概念,在你按下加速按钮后,服务器应该基于你之前读取的游戏状态来更新你的位置。也就是说,你的新位置,应该是基于你当时看到的其他玩家的位置和速度来计算的。
简单来说,写跟随读一致性就像是你玩游戏时,你的动作(写操作)应该基于你当前看到的游戏状态(读操作)来执行。比如当一个客户端第一次读取X值为1,接着写入了X=2,那从当前客户端的角度来看,X值的读取和写入操作是连贯和一致的。
3.2、管道随机访问存储策略
Pipeline Random Access Memory简称PRAM,虽然我感觉翻译过来叫“管道随机访问存储”有点怪,但我们不做过多纠结。PRAM也是一种保证客户端一致性的策略,它要求客户端一直连接同一个节点进行读写操作,从而避免了因延迟性导致的数据不一致问题,还是之前这幅图:
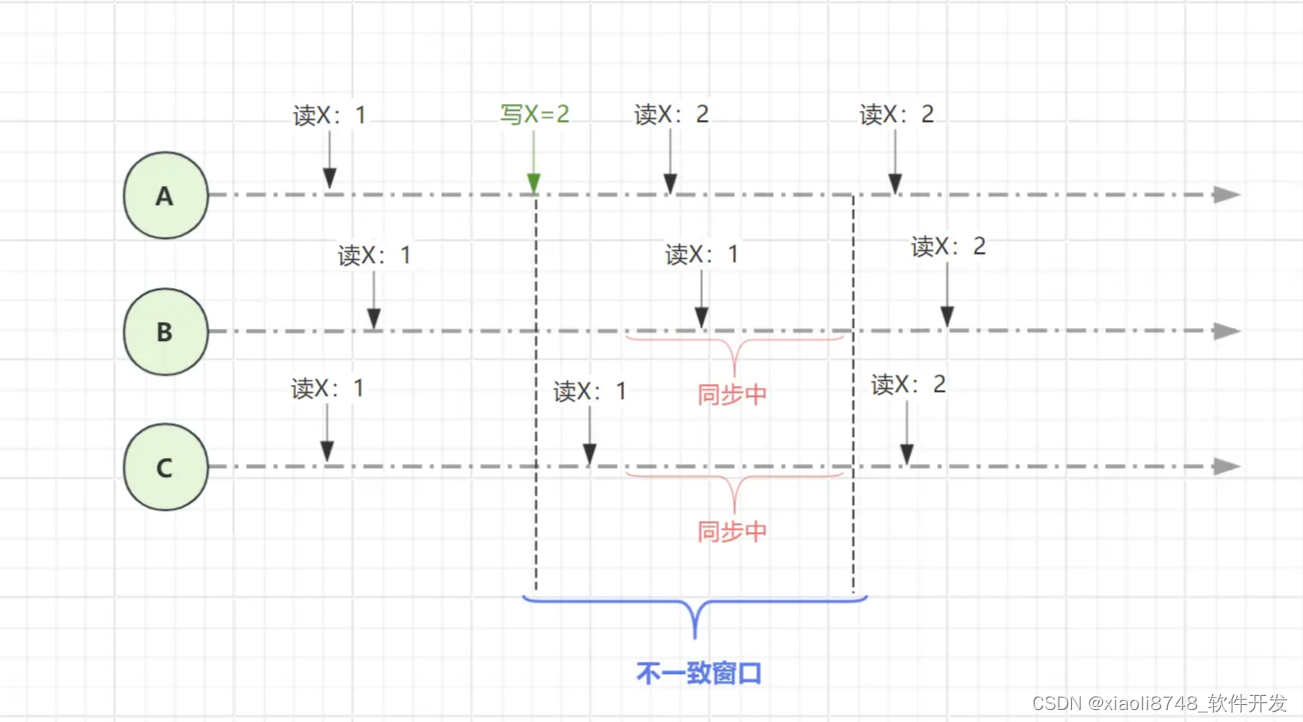
当一个客户端,先在A节点将数据X更新2之后,接着再去C节点读取X值,因为同步存在延迟,所以出现了不一致窗口,导致读到X=1这个值。PRAM策略的解决方案很简单,既然你是在A节点写入的数据,那你后续读取X值时,就去到A节点读取,这样就能避开不一致窗口,保证数据读取的一致性。
PS:如果一个新的客户端,去到
B、C节点读取X值时,还是会看到不一致的数据,毕竟PRAM只是客户端一致性策略,无法为不同客户端的并发访问提供一致性保证。
当然,其实PRAM可以拆解成三种一致性模型,相信部分小伙伴接触过,即:单调读一致性、单调写一致性、读己所写一致性,下面简单聊两句。
3.2.1、单调读一致性(Monotonic-read Consistency)
单调读一致性,指的是:一个客户端读到一个值后,后续该客户端中,任何一次读取都能看到该值,或者该值之后的新值,而不会读取到之前的旧值,同样来看案例:

上图中总共读了三次X,第一次读的值为1,由于中途更新过一次X,因此第二、三次为2,这个案例则满足单调读一致性,即第二次读到了2,第三次也肯定能看到2,而不会看到第一次读取时的1!也就是说:相同客户端后续发起的读操作,都能感知到先前读取到的值,或者更新的版本值,而不会读到比上一次读取更旧的版本值。
3.2.2、单调写一致性(Monotonic-write Consistency)
单调写和单调读类似,只不过说的是写操作,即客户端后续发起的写操作,都能感知到先前写入的值,或者更新的写入版本。这和顺序一致性有点类似,客户端按序写入X=1、2、3,那么写入2的动作,肯定发生于1之后,写入3同理。
当然,单调写一致性针对的是多主类型的场景,如下:

这里A、B都为主节点,具备处理客户端写入动作的能力,如果客户端按序写入X=1、2、3的动作,其中X=1、3落入A,X=2落入B节点,那么A在执行X=3时,必须感知到X=2,否则就有可能出现X=2在X=3之后执行,最终相互同步数据时,X=2因为是最后执行,所以X的最终值变成错误的2,而不是预期的3。
3.2.3、读己所写一致性(Read-your-writes Consistency)
读己所写,有的地方也叫读你所写一致性,即客户端后续发起的写操作,能感知到自己先前写入过的值:
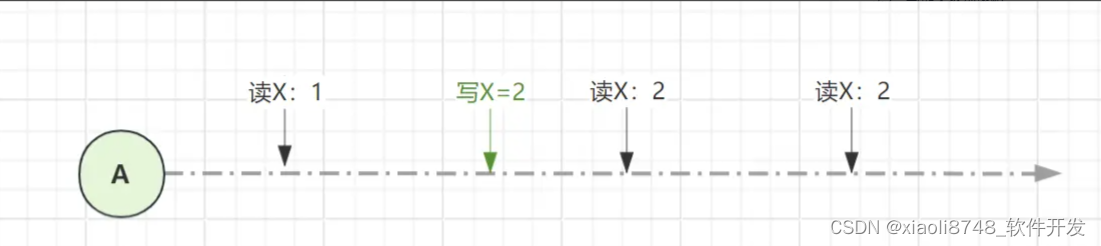
还是这个熟悉的图,这里在第一次读取、第二次读取之间,写入过一次X=2,因此在第二次读取X值时,就能正确读取到自己写入的X=2。
综上,其实大家会发现,PRAM策略因为要求客户端一直连接着同一个节点执行读写操作,所以对相同的客户端来说,它的读写操作必然满足单调读、单调写、读己所写这三个一致性模型。
3.3、读副本选择策略
Read Replica Selection读副本选择策略,在分布式系统中,由于数据被复制存储在多个副本上,客户端在读取数据时,可以选择从哪个副本读取。读副本选择策略可以基于多种因素,如副本的地理位置、网络延迟、负载情况、数据新鲜度等,选择一个最合适的副本读取,可以提高读取性能、减少网络延迟,并确保读取到的是最新的数据。
一种常见的策略是选择离客户端最近的副本进行读取,以减少网络传输延迟,例如CDN内容分发技术,为了提升客户端访问静态资源时的速度,通常大型C端系统,都会采用CDN来缓存静态资源,客户端在请求静态资源,会自动根据客户端的IP地址,通过智能DNS解析技术,选择距离客户端物理距离最近的CDN站点获取数据并返回,具体可参考《CDN内容分发》。
另一种策略是根据副本的负载情况来选择,即负载均衡算法里的最小连接数算法,根据集群各节点的实际负载情况,将请求智能化分发到负荷最低的节点,避免负荷过载的节点被频繁访问,造成响应缓慢、节点故障等现象。
PS:也可以根据数据新鲜度,则
POS点来分发读取请求,路由节点只需要记录集群内,每个节点同步数据的POS点即可,读取请求优先分发到POS值更大的节点处理,毕竟POS越大,代表同步的数据越多,意味着数据会越“新鲜”。
3.4、读一致性级别策略
Read Consistency Level读一致性级别策略,关注的是客户端在读取数据时,对于数据一致性的期望和要求。不同的应用场景对读一致性有不同的要求,它可以根据业务需求来切换读取的节点。
比如在MySQL主从架构中,某些业务要求强一致性,要看到最新的数据,这时可以将请求路由到主节点处理;而部分业务可以接受稍微陈旧的数据,则可以分发到从节点处理。又或者在MongoDB集群模式下,读取数据可以设置readConcern参数,实现读取时选择不同的客户端一致性保障,具体可参考之前《MongoDB保姆级指南》,或《MongoDB官网-可调一致性》。
总之,在分布式存储系统中,强一致性读,通常需要更多的同步和协调机制,可能会增加延迟或成本;而弱一致性读,则可以提供更高的性能和可用性。因此,在选择读一致性级别策略时,需要根据业务的需求进行权衡。
3.5、写提交级别策略
Write Commit Level写提交级别策略,主要涉及的是:写操作的提交方式,写提交级别决定了写操作在分布式系统中的提交方式和时机。与读一致性级别策略类似,写提交水平也有多种选择,如下:
- 同步提交:要求系统内所有节点都写入数据成功后,才认定为写操作成功;
- 异步提交:只要求客户端连接的节点写入数据成功后,就认定为写操作成功;
- 多数提交:要求系统内部分节点(通常是节点数的一半以上)写入成功后,就认为写操作成功。
上述三种提交级别,正好对应着大多数技术栈中,同步复制、异步复制、半同步复制这三种主从数据同步模式,同步提交能保证数据的强一致性,但可能会增加延迟和降低性能。异步提交可以提高性能,但可能会牺牲一定的一致性。多数提交是前两者的妥协,性能、一致性之间做到了平衡,属于中庸方案。当然,在在实际项目中,究竟选哪种模式?需要根据业务数据的重要性和应用的性能要求,综合选择不同的写提交级别。
MongoDB在写入数据时,也支持通过writeConcern参数来指定写提交级别,如下:

四、一致性模型篇总结
任何一个分布式系统,底层都离不开一致性模型的支持,我们通篇读下来,会发现各种各样的一致性模型,实际都是在描述了客户端和系统交互的一系列规则。其中强一致性是对客户端最友好的模型,它不要求客户端留意任何规则,允许客户端在任何时刻发起任意请求,系统都能返回一致的结果,可这种方式对系统本身来说,额外影响性能、吞吐、可用性。
根据CAP定律,一致性、可用性两者之间存在本质矛盾。在实际的分布式领域里,并不是所有系统都看重实时一致性,有时候某些系统反而更加追求性能、吞吐、可用性。正因如此,根据不同的使用场景,诞生出了不同的一致性模型,有些模型种放松了对外的一致性保证,由客户端来容忍特定的不一致行为,进而换取更好的性能。
就目前为止,本文汇总了分布式领域里相较核心的一致性模型,由紧到宽,从常见的三种一致性模型,到弱一致性模型的大家族,再到最后的客户端一致性模型,对“分布式一致性模型”这个话题展开了细致阐述,而下一节内容则会一起聊聊分布式领域著名的一致性协议与算法,如Paxos、Raft等,我们下篇见~