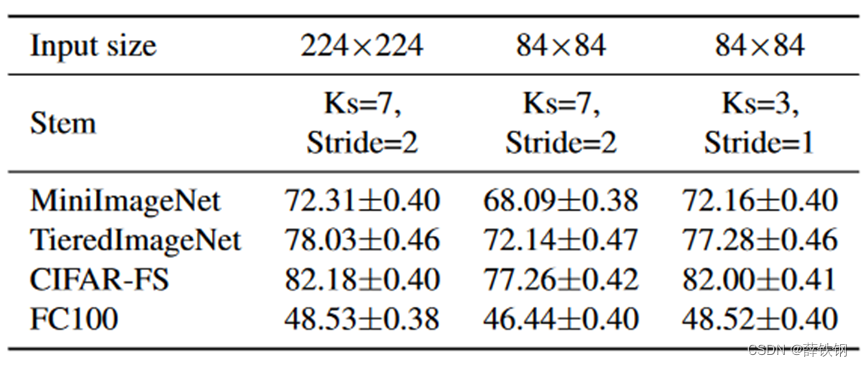
返回的是文档解析分段内容组成的列表,分段内容默认chunk_size: int = 250, chunk_overlap: int = 50,250字分段,50分段处保留后面一段的前50字拼接即窗口包含下下一段前面50个字划分
from typing import Union, Listimport jieba
import reclass SentenceSplitter:def __init__(self, chunk_size: int = 250, chunk_overlap: int = 50):self.chunk_size = chunk_sizeself.chunk_overlap = chunk_overlapdef split_text(self, text: str) -> List[str]:if self._is_has_chinese(text):return self._split_chinese_text(text)else:return self._split_english_text(text)def _split_chinese_text(self, text: str) -> List[str]:sentence_endings = {'\n', '。', '!', '?', ';', '…'} # 句末标点符号chunks, current_chunk = [], ''for word in jieba.cut(text):if len(current_chunk) + len(word) > self.chunk_size:chunks.append(current_chunk.strip())current_chunk = wordelse:current_chunk += wordif word[-1] in sentence_endings and len(current_chunk) > self.chunk_size - self.chunk_overlap:chunks.append(current_chunk.strip())current_chunk = ''if current_chunk:chunks.append(current_chunk.strip())if self.chunk_overlap > 0 and len(chunks) > 1:chunks = self._handle_overlap(chunks)return chunksdef _split_english_text(self, text: str) -> List[str]:# 使用正则表达式按句子分割英文文本sentences = re.split(r'(?<=[.!?])\s+', text.replace('\n', ' '))chunks, current_chunk = [], ''for sentence in sentences:if len(current_chunk) + len(sentence) <= self.chunk_size or not current_chunk:current_chunk += (' ' if current_chunk else '') + sentenceelse:chunks.append(current_chunk)current_chunk = sentenceif current_chunk: # Add the last chunkchunks.append(current_chunk)if self.chunk_overlap > 0 and len(chunks) > 1:chunks = self._handle_overlap(chunks)return chunksdef _is_has_chinese(self, text: str) -> bool:# check if contains chinese charactersif any("\u4e00" <= ch <= "\u9fff" for ch in text):return Trueelse:return Falsedef _handle_overlap(self, chunks: List[str]) -> List[str]:# 处理块间重叠overlapped_chunks = []for i in range(len(chunks) - 1):chunk = chunks[i] + ' ' + chunks[i + 1][:self.chunk_overlap]overlapped_chunks.append(chunk.strip())overlapped_chunks.append(chunks[-1])return overlapped_chunkstext_splitter = SentenceSplitter()def load_file(filepath):print("filepath:",filepath)if filepath.endswith(".md"):contents = extract_text_from_markdown(filepath)elif filepath.endswith(".pdf"):contents = extract_text_from_pdf(filepath)elif filepath.endswith('.docx'):contents = extract_text_from_docx(filepath)else:contents = extract_text_from_txt(filepath)return contentsdef extract_text_from_pdf(file_path: str):"""Extract text content from a PDF file."""import PyPDF2contents = []with open(file_path, 'rb') as f:pdf_reader = PyPDF2.PdfReader(f)for page in pdf_reader.pages:page_text = page.extract_text().strip()raw_text = [text.strip() for text in page_text.splitlines() if text.strip()]new_text = ''for text in raw_text:new_text += textif text[-1] in ['.', '!', '?', '。', '!', '?', '…', ';', ';', ':', ':', '”', '’', ')', '】', '》', '」','』', '〕', '〉', '》', '〗', '〞', '〟', '»', '"', "'", ')', ']', '}']:contents.append(new_text)new_text = ''if new_text:contents.append(new_text)return contentsdef extract_text_from_txt(file_path: str):"""Extract text content from a TXT file."""with open(file_path, 'r', encoding='utf-8') as f:contents = [text.strip() for text in f.readlines() if text.strip()]return contentsdef extract_text_from_docx(file_path: str):"""Extract text content from a DOCX file."""import docxdocument = docx.Document(file_path)contents = [paragraph.text.strip() for paragraph in document.paragraphs if paragraph.text.strip()]return contentsdef extract_text_from_markdown(file_path: str):"""Extract text content from a Markdown file."""import markdownfrom bs4 import BeautifulSoupwith open(file_path, 'r', encoding='utf-8') as f:markdown_text = f.read()html = markdown.markdown(markdown_text)soup = BeautifulSoup(html, 'html.parser')contents = [text.strip() for text in soup.get_text().splitlines() if text.strip()]return contentstexts = load_file(r"C:\Users\lo***山市城市建筑外立面管理条例.docx")
print(texts)