文章目录
- 前言
- vae
- clip
- UNet
- unet训练
- 帮助、问询
前言
看了篇文:
https://zhuanlan.zhihu.com/p/617134893
运行一些组件试试效果。
vae
代码:
import torch
from diffusers import AutoencoderKL
import numpy as np
from PIL import Image# 加载模型: autoencoder可以通过SD权重指定subfolder来单独加载
autoencoder = AutoencoderKL.from_pretrained("/ssd/xiedong/src_data/eff_train/Stable-diffusion/majicmixRealistic_v7_diffusers", subfolder="vae")
autoencoder.to("cuda", dtype=torch.float16)# 读取图像并预处理
raw_image = Image.open("girl.png").convert("RGB").resize((512, 512))
image = np.array(raw_image).astype(np.float32) / 127.5 - 1.0
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image)# 压缩图像为latent并重建
with torch.inference_mode():# latentx形状是 (B, C, H, W) 的张量 (1,4,64,64)latentx = autoencoder.encode(image.to("cuda", dtype=torch.float16)).latent_dist.sample() # 压缩# 保存 latent 为 PNG 图像latent = latentx.permute(0, 2, 3, 1) # 将 latent 重新排列为 (B, H, W, C) 格式latent = latent.cpu().numpy() # 将 latent 转换为 NumPy 数组latent = (latent * 127.5 + 127.5).astype('uint8') # 将值缩放到 [0, 255] 范围内,并转换为 uint8 类型latent = latent.squeeze(0) # 去掉批次维度latent_image = Image.fromarray(latent) # 将 NumPy 数组转换为 PIL Imagelatent_image.save("latent.png") # 保存为 PNG 图像# shapeprint(latentx.shape)rec_image = autoencoder.decode(latentx).samplerec_image = (rec_image / 2 + 0.5).clamp(0, 1)rec_image = rec_image.cpu().permute(0, 2, 3, 1).numpy()rec_image = (rec_image * 255).round().astype("uint8")rec_image = Image.fromarray(rec_image[0])# save
rec_image.save("demo.png")原图:

encoder之后:
decoder之后:

clip
在自然语言处理任务中,tokenizer和text_encoder是两个重要的组件,用于将文本转换为模型可以理解的数值表示形式。
- Tokenizer:
Tokenizer的作用是将一个文本序列(如句子或段落)分割成一系列的token(通常是单词或子词)。它将文本映射到一个词表(vocabulary),每个token对应词表中的一个索引(index)。在您的代码示例中,tokenizer将输入的文本"a photograph of an astronaut riding a horse"转换为对应的token id序列。
- Text Encoder:
Text Encoder(文本编码器)是一个预训练的语言模型,它可以将token id序列编码为对应的向量表示(embeddings)。这些向量表示捕获了单词及其上下文的语义信息。
在您的代码中:
tokenizer(prompt)将文本"a photograph of an astronaut riding a horse"转换为对应的token id序列(如[1, 27, 38, 61, …]等)。text_encoder(text_input_ids)将这个token id序列输入到文本编码器模型中,得到对应的向量表示text_embeddings。
最终得到的text_embeddings的形状是 torch.Size([1, 77, 768])。其中:
- 1 表示批次大小(batch size),对于单个输入就是1。
- 77 表示输入token的数量(由于padding,长度被填充到模型的最大长度)。
- 768 是每个token的向量表示的维度。
通过这种编码方式,原始的文本被转换为了具有丰富语义信息的数值向量表示,方便被深度学习模型进一步处理。这种编码过程是自然语言处理中的常见做法。
from transformers import CLIPTextModel, CLIPTokenizertext_encoder = CLIPTextModel.from_pretrained("/ssd/xiedong/src_data/eff_train/Stable-diffusion/majicmixRealistic_v7_diffusers", subfolder="text_encoder").to("cuda")
# text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to("cuda")
tokenizer = CLIPTokenizer.from_pretrained("/ssd/xiedong/src_data/eff_train/Stable-diffusion/majicmixRealistic_v7_diffusers", subfolder="tokenizer")
# tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")# 对输入的text进行tokenize,得到对应的token ids
prompt = "a photograph of an astronaut riding a horse"
text_input_ids = tokenizer(prompt,padding="max_length",max_length=tokenizer.model_max_length,truncation=True,return_tensors="pt"
).input_idsprint(text_input_ids.shape) # torch.Size([1, 77]
# 将token ids送入text model得到77x768的特征
text_embeddings = text_encoder(text_input_ids.to("cuda"))[0]
print(text_embeddings.shape) # torch.Size([1, 77, 768])UNet
稳定扩散(Stable Diffusion,SD)是一种基于扩散模型的生成式人工智能模型,用于创建图像。它的核心是一个860万参数的UNet结构,负责将文本提示转化为图像。
UNet结构主要由编码器(Encoder)和解码器(Decoder)两部分组成,两部分通过跳跃连接(Skip Connection)相连。编码器用于捕获输入的潜在表征(Latent Representation),解码器则根据这些表征生成最终图像。
具体而言,编码器包含:
- 3个CrossAttnDownBlock2D模块,每个模块会对输入进行2倍下采样
- 1个DownBlock2D模块,不进行下采样
中间是一个UNetMidBlock2DCrossAttn模块,用于连接编码器和解码器。
解码器包含:
- 1个UpBlock2D模块
- 3个CrossAttnUpBlock2D模块
编码器和解码器的模块数量和结构是对应的,通过跳跃连接融合不同尺度的特征。
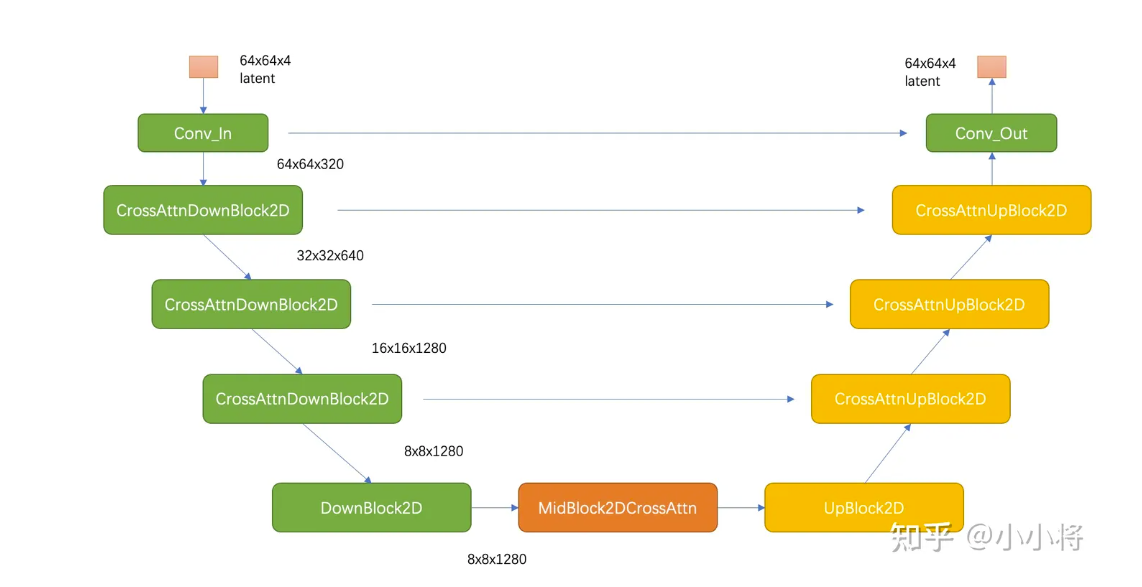
CrossAttnDownBlock2D 和 CrossAttnUpBlock2D 是 Stable Diffusion 中 UNet 架构的关键模块,用于将文本条件(text condition)融入到图像生成的过程中。它们利用了自注意力(Self-Attention)机制,将文本嵌入与图像特征进行交叉注意力(Cross-Attention)操作。
以 CrossAttnDownBlock2D 为例,其核心是一个 CrossAttention 模块,该模块的工作原理如下:
-
将文本条件(如"一只可爱的小狗")编码为文本嵌入(text embeddings),记为 E t e x t \mathbf{E}_{text} Etext。
-
从 UNet 的中间层获取图像特征,记为 F i m a g e \mathbf{F}_{image} Fimage。
-
在 CrossAttention 中,将 F i m a g e \mathbf{F}_{image} Fimage 作为 Query,而 E t e x t \mathbf{E}_{text} Etext 作为 Key 和 Value,计算注意力权重:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中 Q = F i m a g e Q=\mathbf{F}_{image} Q=Fimage, K = E t e x t K=\mathbf{E}_{text} K=Etext, V = E t e x t V=\mathbf{E}_{text} V=Etext, d k d_k dk 是缩放因子。
-
将注意力权重与 F i m a g e \mathbf{F}_{image} Fimage 相加,得到融合了文本条件的新特征表示。
这个过程可以用以下伪代码表示:
class CrossAttention(nn.Module):def forward(self, x, context):"""x: 图像特征 [batch, channels, height, width]context: 文本嵌入 [batch, text_len, text_dim]"""q = x.view(x.size(0), -1, x.size(-1)) # [batch, channels*height*width, dim]k = context.permute(0, 2, 1) # [batch, text_dim, text_len]v = context.permute(0, 2, 1) # [batch, text_dim, text_len]attn = torch.bmm(q, k) # [batch, channels*height*width, text_len]attn = attn / sqrt(k.size(-1))attn = softmax(attn, dim=-1)x = torch.bmm(attn, v) # [batch, channels*height*width, text_dim]x = x.view(x.size(0), -1, x.size(-1)) # [batch, channels, height, width]return x
CrossAttnUpBlock2D 的工作方式与 CrossAttnDownBlock2D 类似,只是它位于 UNet 的解码器部分。通过这种交叉注意力机制,Stable Diffusion 能够将文本条件与图像特征进行融合,从而根据提示生成所需的图像。
CrossAttention 模块是 Stable Diffusion 中实现文本到图像生成的关键部分,它利用注意力机制将文本信息注入到图像特征中,使生成的图像能够匹配给定的文本描述。
unet训练
SD训练过程原理:
SD模型的训练过程可以概括为以下几个步骤:
- 将图像编码到潜在空间,获得潜在向量表示。
- 使用CLIP文本编码器获取文本的嵌入向量表示。
- 在潜在空间中采样噪声,并将其添加到潜在向量中,进行扩散过程。
- U-Net模型接收扩散后的噪声潜在向量和文本嵌入,预测原始的噪声向量。
- 计算预测噪声和实际噪声之间的均方误差作为损失函数。
- 通过反向传播优化U-Net模型参数,使其能够更好地预测噪声。
整个过程可以用以下公式表示:
L = E x 0 , ϵ , t [ ∥ ϵ − ϵ θ ( x t , t , y ) ∥ 2 ] \mathcal{L} = \mathbb{E}_{x_0, \epsilon, t} \left[\left\| \epsilon - \epsilon_\theta(x_t, t, y) \right\|^2\right] L=Ex0,ϵ,t[∥ϵ−ϵθ(xt,t,y)∥2]
其中:
- x 0 x_0 x0是原始的潜在向量
- ϵ \epsilon ϵ是添加到潜在向量上的噪声
- t t t是随机采样的时间步长
- x t x_t xt是扩散后的噪声潜在向量
- y y y是文本嵌入向量
- ϵ θ \epsilon_\theta ϵθ是U-Net模型预测的噪声
通过最小化这个损失函数,U-Net模型可以学习到从噪声潜在向量和文本嵌入中预测原始噪声的能力。在生成图像时,可以通过从随机噪声开始,逐步去噪,并根据文本嵌入对每一步的去噪过程进行条件控制,最终得到符合文本描述的图像。
Classifier-Free Guidance (CFG)是一种在训练和生成过程中提高文本条件控制的技术。它的核心思想是在训练时,以一定概率随机丢弃文本嵌入,这样模型就可以同时学习条件预测和无条件预测。在生成时,将条件预测和无条件预测的结果进行加权融合,从而增强文本条件的影响。CFG可以用以下公式表示:
ϵ θ ( C F G ) = ϵ θ ( x t , t , y ) + s ⋅ ( ϵ θ ( x t , t , ∅ ) − ϵ θ ( x t , t , y ) ) \epsilon_\theta^{(CFG)} = \epsilon_\theta(x_t, t, y) + s \cdot (\epsilon_\theta(x_t, t, \emptyset) - \epsilon_\theta(x_t, t, y)) ϵθ(CFG)=ϵθ(xt,t,y)+s⋅(ϵθ(xt,t,∅)−ϵθ(xt,t,y))
其中:
- ϵ θ ( x t , t , y ) \epsilon_\theta(x_t, t, y) ϵθ(xt,t,y)是条件预测的噪声
- ϵ θ ( x t , t , ∅ ) \epsilon_\theta(x_t, t, \emptyset) ϵθ(xt,t,∅)是无条件预测的噪声
- s s s是一个scale参数,用于控制条件和无条件预测的权重
通过CFG,可以有效地提高生成图像与输入文本的一致性。
帮助、问询
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2







![[挖坟]如何安装Shizuku和LSPatch并安装模块(不需要Root,非Magisk)](https://img-blog.csdnimg.cn/direct/00ba67dd82014123b99265c133e5afaf.png)