1.什么是强化学习
强化学习是机器学习的一种,是一种介于监督学习和非监督学习的机器学习方法。
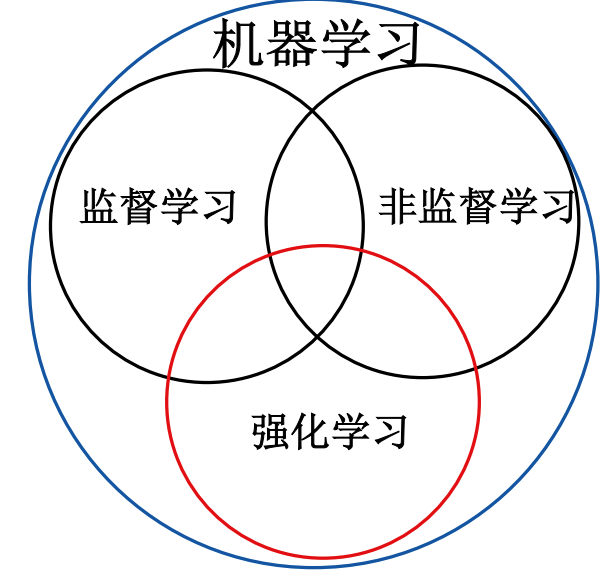
学习二字就很形象的说明了这是一种利用数据(任何形式的)来实现一些已有问题的方法,学习方法,大致可以分为机器学习,监督学习,非监督学习和强化学习。
机器学习:机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
监督学习:已知数据和其一一对应的标签,训练一个智能算法,将输入数据映射到标签的过程。
非监督学习:已知数据不知道任何标签,按照一定的偏好,训练一个智能算法,将所有的数据映射到多个不同标签的过程。
强化学习:智能算法在没有人为指导的情况下,通过不断的试错来提升任务性能的过程。
强化学习和其他机器学习的不同之处在哪里呢?总的来说,强化学习就是一种试错过程,正确答案是试出来的,其他机器学习则是通过标记的训练数据来学习模型或者规律,已实现特定的分类回归聚类等特定任务。
所以一个非常重要的特点就是强化学习会与环境提供的奖励信号来指导学习过程,根据动作;来获取反馈,其他机器学习通常是静态的数据学习,不需要与环境进行交互注意,强化学习反馈的信号是延迟和稀疏的,需要考虑时间相关性和延迟决策。
强化学习与其他机器学习方法的不同之处:
- 学习过程中没有监督信号,只有奖励反馈和实验试错
- 其反馈具有延时性,非瞬时的
- 智能体的动作会影响后续接收到的序列数据
- 强化学习的过程与时间序列相关,是一个序贯决策的过程
2.强化学习的发展历史
RL从统计学、控制理论和心理学等多学科发展而来,是一个基于数学框架、由经验驱动的自主学习方法,RL有3条发展主线:
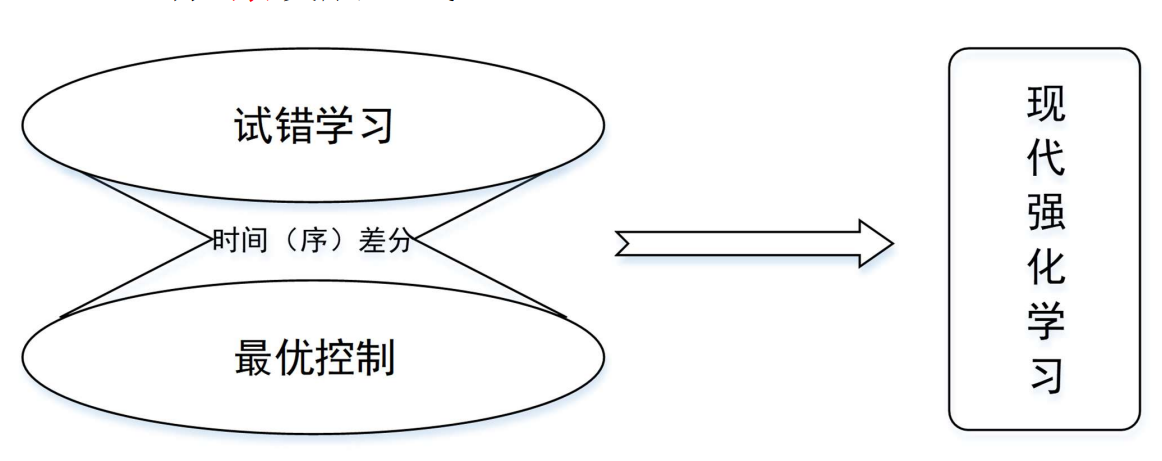
2.1最优控制
20世纪50年代后期开始使用,用来描述通过设计控制器来最小化动态系统的行为随时间变化的测度问题,即控制动态系统在每一时刻都能根据外界环境的变化选出最优的行为。
- 20世纪50年代中期,Bellman和一些人对Hamilton、Jacobi理论进行了扩展,提出了Bellman方程,使用动态系统的状态和值函数(或“最优返回函数”)的概念定义了函数方程。
- 通过求解Bellman方程来解决最优控制问题的方法叫做DP方法。
- DP方法受到了“维度灾难”的限制,即它的计算量随着状态变量数目的增加呈指数级增长
- Bellman还引入了最优控制问题的离散随机版本,称之为马尔可夫决策过程(Markov Decision Process, MDP)。
- 1960年,Howard又设计了MDP的策略(policy)迭代方法。
以上所有这些都是现代RL理论和算法的重要组成部分。
2.2试错学习
- 在早期人工智能独立于其他工程分支之前,一些研究人员就开始探索将试错学习作为工程原理。该方法始于动物学习过程中的心理学,其中的“强化”学习理论很常见。在20世纪60年代,术语“强化”和“强化学习”首次被用于工程文献中。
- Edward Thorndike第一个简洁表达了试错学习的本质,即每一次采取的动作尝试所引发的好的或坏的结果都会对之后的动作选择产生相应地影响。——“效果定律”,效果定律涉及试错学习的两个最重要的方面:
- 首先,它是选择性的,意味着它可以尝试替代方案,并通过比较它们所产生的结果来进行选择。
- 其次,它是关联性的,即通过选择找到的替代方案与特定的情况相关联。
比如,进化过程中的自然选择是选择性的,但它不是相关联的;监督学习是相关的,但不是选择性的,这两者的结合对效果定律和试错学习至关重要。
2.3时间差分(TD)学习
- TD学习方法部分起源于动物学习过程中的心理学,特别是辅助强化学,由同一时间内进行的连续估计之间的差异所驱动。
- 1972年,Klopf提出了“广义强化”的概念,即每个组成部分(名义上,每个神经元)都以强化的角度来看待所有的输入。Klopf通过这一想法将试错学习与TD学习的重要组成部分结合起来,同时将其与动物学习心理学的大量经验数据库联系起来。
- 1977年Witten最早出版的TD学习规则,也就是我们现在所谓的表格TD(0)方法,用作解决MDP自适应控制器的一部分,这种方法跨越了RL研究的主要思路——试错学习和最优控制。
- 1981年人们开发了一种在试错学习过程中使用TD学习的方法,称为actor-critic架构,也有人叫做行动者-评论者架构,其中actor是行动者,负责动作的选择和执行,critic代表评论者,负责评价actor所选动作的好坏。
- 1989年,Watkins将TD学习和最优控制完全融合在一起,发明了Q-learning学习算法,扩展并整合了先前RL研究三条主线的所有工作。
3强化学习的分类
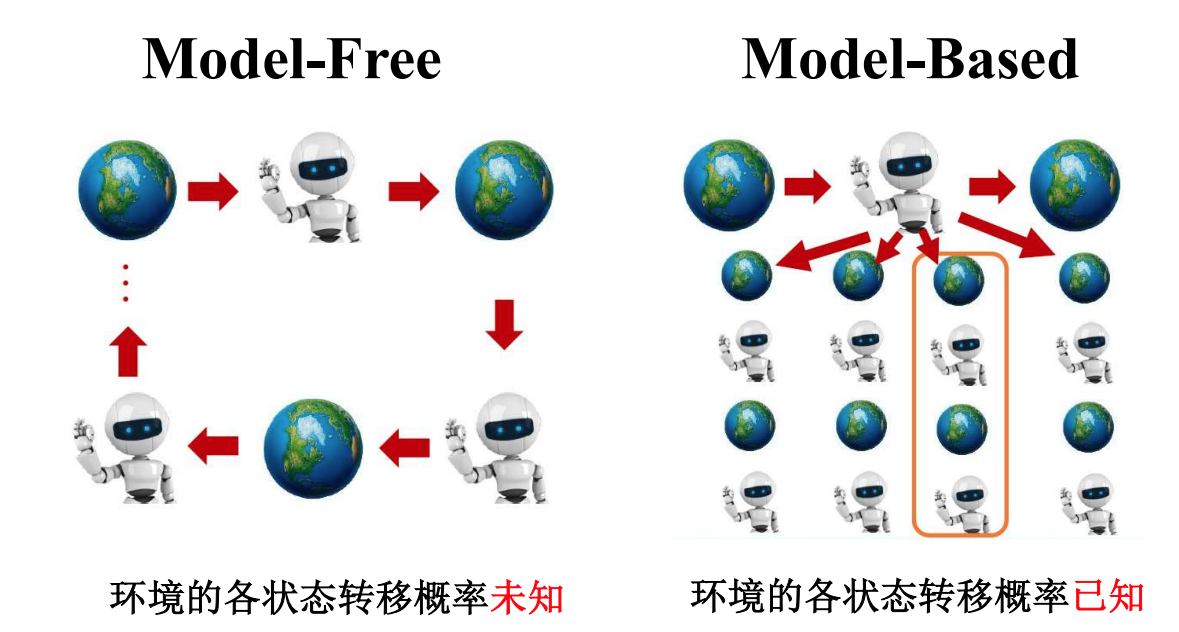
基于模型和无模的两类
- 模型型强化学习:这类方法在学习过程中建立了对环境的模型,可以使用该模型进行推理和规划。常见的模型型方法包括基于模型的强化学习、动态规划等。
- 无模型型强化学习:这类方法直接从与环境的交互中学习,不依赖于环境模型。常见的无模型型方法包括蒙特卡洛方法、时序差分方法等。
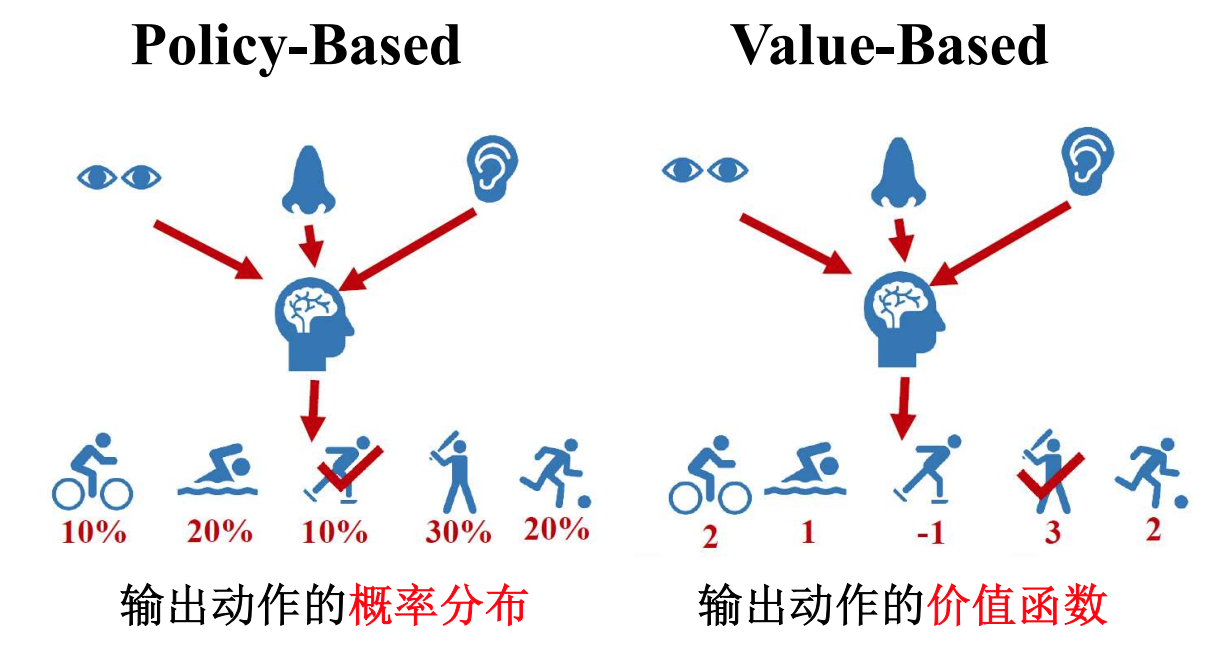
根据输出动作的两种类型可以分为: - 值函数方法:这类方法通过估计状态或状态-动作对的价值函数,来指导代理的决策。常见的值函数方法包括Q-learning、SARSA等。
- 策略方法:这类方法直接学习策略函数,将状态映射到动作的概率分布。常见的策略方法包括策略梯度算法、Actor-Critic方法等。
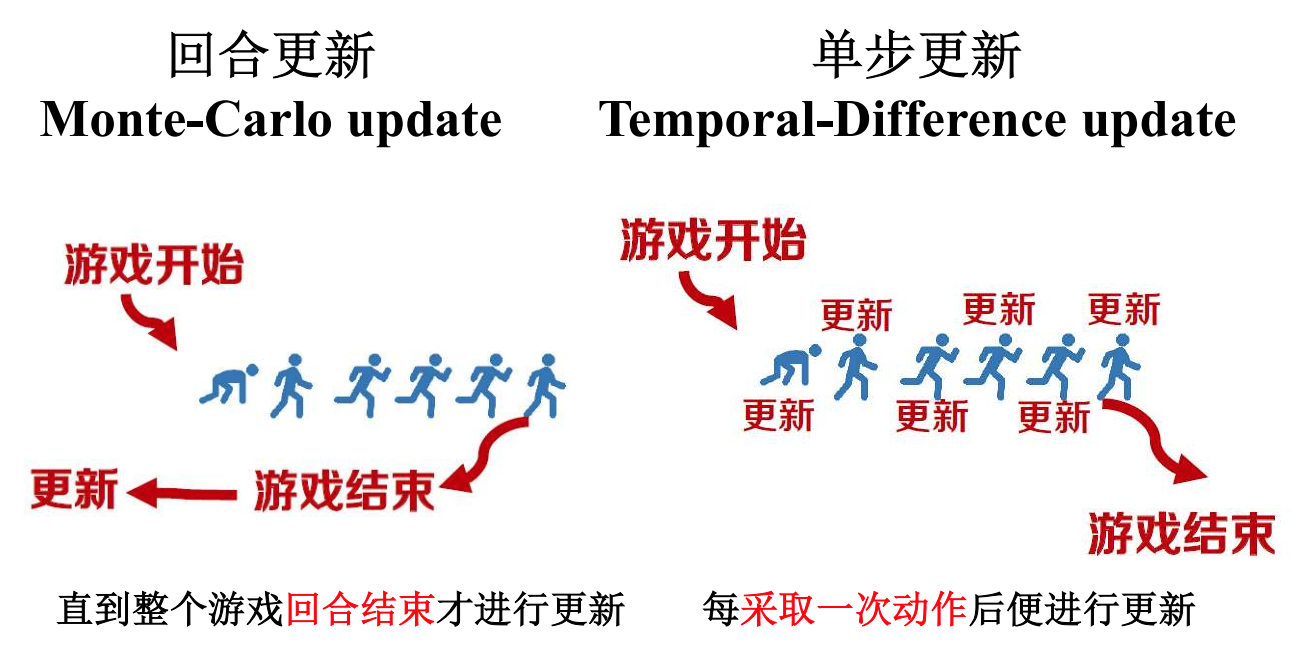
根据更新的方式来说,分为单步和回合更新两种
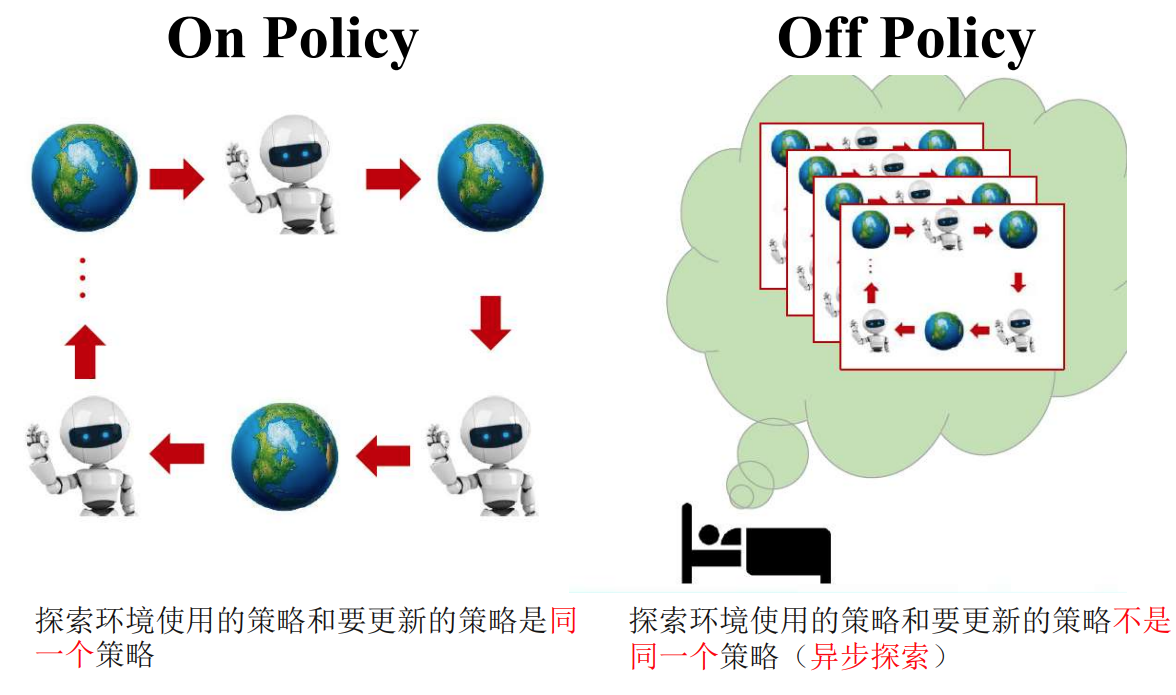
这个不是很懂。 - On-policy(同策略)学习:在On-policy学习中,(agent)使用当前正在学习的策略与环境进行交互,并且学习的目标是优化当前策略本身。通过不断尝试并收集与当前策略相一致的数据,然后使用这些数据来更新策略的参数。常见的On-policy算法包括REINFORCE、Proximal Policy Optimization (PPO)等。
- Off-policy(离策略)学习:在Off-policy学习中,使用之前收集的数据(通常是由其他策略生成的)进行学习,并且学习的目标是优化与当前策略不同的策略。在训练阶段可以采取一种策略生成数据,然后使用另一种策略从这些数据中学习。这种方法的优势在于可以更充分地利用历史数据,并且学习的目标可以是不同的策略。常见的Off-policy算法包括Q-learning、Deep Q-Network (DQN)等。
4强化学习基本概念
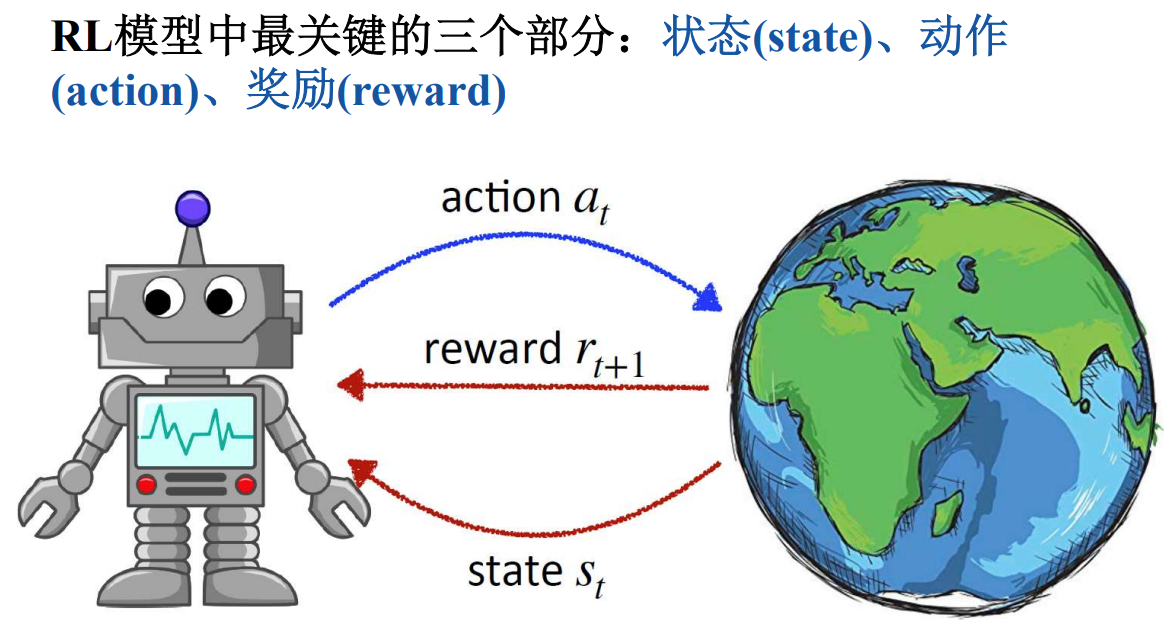
三大基本概念就是状态动作和奖励。状态是智能体所处的外界环境信息。动作是智能体在感知到所处的外界环境状态后所要采取的行为。奖励是当智能体感知到外界环境并采取动作后所获得的奖赏值。
智能体的任务就是最大化累计奖励(强化学习是基于奖励假设(Reward Hypothesis)的,所有任务目标均可以用最大化期望累计奖励描述)

精彩学习内容:
价值函数,动作价值函数
回报?累计回报?
状态转移?
输入,输出内容
模型预测控制中的非线性解析数学方法
微分:未来的偏差(趋势),减少超调和振荡,加快响应速度,
一步预测。——>模型 更多的迭代?
积分:消除稳态误差 振荡
多目标多变量多约束 泛函问题
mpc问题建立:一个最优控制问题
解法:线性or非线性MPC
非线性优化,贝尔曼最优 二次规划QP,序列二次规划
模型信息,优化指标,多步结果。极点配置,直接就调参了。比例控制,会有稳态误差,,只取第一个用于控制,滚动优化控制。
增量式MPC,从直接从0开始转为0.1到0.2,,变化率。
Lqr又是什么?
带有约束的mpc求解。
mpc->最优控制?
线性 带不等式约束和状态等式约束 控制偏差和效率
多变量系统叫梯度(不是导数)
带着约束的多变量问题—kkt条件
NP hard