AutoAlignV2
Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
论文网址:AutoAlignV2
论文代码:AutoAlignV2
简读论文
这篇论文提出了一种名为AutoAlignV2的动态多模态3D目标检测框架,旨在高效融合激光雷达点云和RGB图像以提高3D目标检测的精度。主要贡献包括:
-
提出了一种Cross-Domain DeformCAFA模块,用于在不同模态之间实现高效的特征聚合。该模块采用可形变注意力机制,通过学习采样点对齐RGB特征,大幅降低了计算复杂度,同时保留了多层次图像特征的层次表示。
-
设计了一种简单有效的Depth-Aware GT-AUG数据增强策略,利用3D物体注释的深度信息合成图像,简化了2D-3D数据同步的过程。
-
提出了一种图像级别的dropout训练策略,使模型能够动态地在有或无图像的情况下进行推理,提高了模型的通用性和适用性。
-
在nuScenes数据集上进行了大量实验,结果表明AutoAlignV2相比现有方法能够显著提升3D目标检测性能,在测试集上取得了72.4的最新state-of-the-art NDS分数。
-
通过消融实验,分析了每个模块对性能的贡献,并探讨了不同设置下的速度与准确性权衡。
总的来说,该工作提出了一种高效、通用且精度卓越的多模态3D目标检测解决方案,对于促进自动驾驶感知技术具有重要意义。
摘要
点云和 RGB 图像是自动驾驶中两种常见的感知源。前者可以提供物体的准确定位,后者语义信息更密集、更丰富。最近,AutoAlign 提出了一种可学习的范例,将这两种模式结合起来进行 3D 目标检测。然而,它受限于全局注意力带来的高计算成本。为了解决这个问题,在这项工作中提出了Cross-Domain Deform CAFA模块。它关注跨模态关系建模的稀疏可学习采样点,增强了对校准误差的容忍度,并大大加快了不同模态的特征聚合速度。为了克服多模态设置下复杂的 GT-AUG,本文在给定深度信息的图像块凸组合上设计了一种简单而有效的跨模态增强策略。此外,通过执行一种新颖的图像级 dropout 训练方案,模型能够以动态方式进行推断。为此,本文提出了 AutoAlignV2,这是一个更快、更强的多模态 3D 检测框架,建立在 AutoAlign 之上。 nuScenes 基准上的大量实验证明了 AutoAlignV2 的有效性和效率。值得注意的是,本文的最佳模型在 nuScenes 测试排行榜上达到了 72.4 NDS,在所有已发布的多模态 3D 物体检测器中取得了最先进的结果。
引言
3D 目标检测是自动驾驶中的一项基本计算机视觉任务。现代 3D 目标检测器 在 KITTI 、Waymo 和 nuScenes 数据集等竞争基准上表现出了良好的性能。尽管检测精度进步很快,但进一步改进的空间仍然很大。最近,将 RGB 图像与 LiDAR 点云相结合进行精确检测的热潮引起了许多关注 。与有利于空间定位的点云不同,影像数据在提供语义和纹理信息方面更优越,即更适合分类。因此,相信这两种方式是互补的,可以进一步提高检测精度。
然而,如何有效地结合这些异构表示来进行 3D 目标检测尚未得到充分探索。在这项工作中,主要将当前训练跨模态检测器的困难归因于两个方面。一方面,结合图像和空间信息的融合策略仍然不是最优的。由于 RGB 图像和点云之间的异构表示,在聚合在一起之前需要仔细对齐特征。这通常是通过 LiDAR 相机投影矩阵在点和图像像素之间建立确定性对应关系来实现的。 AutoAlign 提出了一种可学习的全局对齐模块用于自动配准,并取得了良好的性能。然而,它必须借助CSFI模块进行训练,以获得点与图像像素之间的内部位置匹配关系。此外,注意力式操作的复杂性与图像大小成二次方,使得在高分辨率特征图(例如,C2、C3)上应用查询是不切实际的。这样的限制会导致图像信息粗糙且不准确,以及 FPN 带来的层次表示的丢失(见图 1)。另一方面,数据增强,尤其是 GT-AUG ,是 3D 检测器获得有竞争力的结果的关键一步。对于多模态方法来说,一个重要的问题是在进行剪切和粘贴操作时如何保持图像和点云之间的同步。 MoCa 在 2D 域中使用劳动密集型掩模注释来获得准确的图像特征。框级注释也适用,但需要精细且复杂的点过滤。
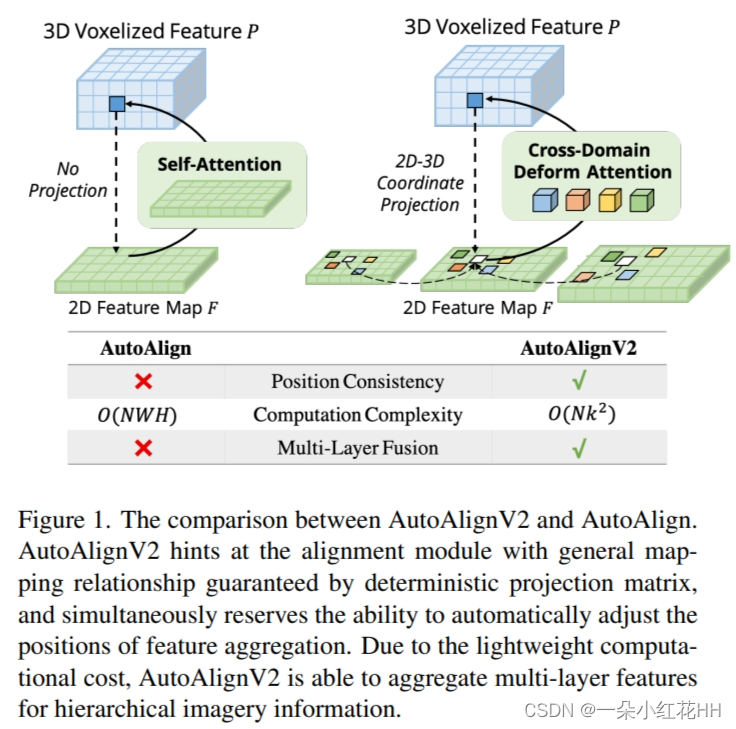
在这项工作中,提出 AutoAlignV2 以更简单、更有效的方式缓解上述问题。它以确定性投影矩阵保证的一般映射关系暗示对齐模块,同时保留自动调整特征聚合位置的能力。针对2D-3D联合增强中的同步问题,引入了一种新颖的深度感知GT-AUG算法来应对图像域中的对象遮挡,摆脱了复杂的点云过滤或精细掩模注释的需要。还提出了一种名为图像级丢弃策略的新训练方案,该方案使模型即使在没有图像的情况下也能够动态推断结果。通过大量的实验,验证了 AutoAlignV2 在两个代表性 3D 检测器上的有效性:Object DGCNN 和 CenterPoint ,并在竞争性 nuScenes 基准上实现了新的最先进的性能。
相关工作
基于点云的目标检测
现有的 3D 目标检测器可大致分为基于点的方法和基于体素的方法。基于点的方法直接从点预测回归框。例如,Point R-CNN 采用语义网络对点云进行分割,然后在每个前景点生成建议。 3DSSD 在单阶段架构上完全应用了点级预测,其中在类似PointNet的特征提取之后设计了无锚头。尽管保持了准确的 3D 定位信息,但这些算法通常会面临较高的计算成本 。与逐点检测不同,基于体素的方法通过体素化将无序点集转换为二维特征图,可以直接应用于卷积神经网络。例如,VoxelNet 是一种广泛使用的范例,其中提出了 VFE 层来为每个 3D 体素提取统一的特征。基于此,CenterPoint 提出了一种基于中心的标签分配策略,在 3D 目标检测中实现了有竞争力的性能。
多模态3D目标检测
最近,用于 3D 目标检测的多模态数据受到越来越多的关注 。 AVOD 和 MV3D 是该领域的两个先驱工作,其中 2D 和 3D RoI 在框预测之前直接连接。有方法利用图像生成 2D 提案,然后将它们提升到 3D 空间(视锥体),这缩小了点云中的搜索空间。 3D-CVF 和 EPNet 通过学习的校准矩阵探索不同模态特征图上的融合策略。尽管易于实现,但它们可能会受到粗糙特征聚合的影响。为了缓解这个问题,各种方法使用由 3D 坐标给出的相机-LiDAR 投影矩阵来获取逐像素图像特征。例如,MVX-Net 为跨模式 3D 目标检测提供了一个易于扩展的框架,并在 2D 和 3D 分支中进行联合优化。 AutoAlign 将投影关系表述为注意力图,并通过网络自动学习这种对齐方式。在这项工作中,探索了一种更快、更有效的对齐策略,以进一步提高逐点特征聚合的性能。
AutoAlignV2
AutoAlignV2 的目标是有效聚合图像特征,以进一步增强 3D 目标检测器的性能。从 AutoAlign 的基本架构开始:将配对图像输入到轻量级主干 ResNet ,然后输入 FPN 以获得特征图。然后,通过可学习的对齐图聚合相关图像信息,以丰富体素化阶段非空体素的 3D 表示。最后,增强的特征将被输入到后续的 3D 检测管道中以生成实例预测。
这样的范例可以以数据驱动的方式聚合异构特征。然而,仍然有两个主要瓶颈阻碍性能。第一个是低效的特征聚合。虽然全局注意图自动进行了 RGB 图像和 LiDAR 点之间的特征对齐,但计算成本很高:给定体素数量 N 和图像特征大小 W×H,复杂度为 O(NWH)。由于WH值较大,AutoAlign丢弃除C5之外的其他层以降低成本。第二个是图像和点之间复杂的数据增强同步。 GT-AUG是高性能3D目标检测器的重要步骤,但如何在训练过程中保持点和图像之间的语义一致性仍然是一个复杂的问题。
在本节中,展示了通过提出的 AutoAlignV2 可以有效解决上述挑战,该 AutoAlignV2 由两部分组成:跨域变形 CAFA 模块和深度感知 GT-AUG 数据增强策略(见图 2)。还提出了一种新颖的图像级 dropout 训练策略,使模型能够以更动态的方式进行推断。
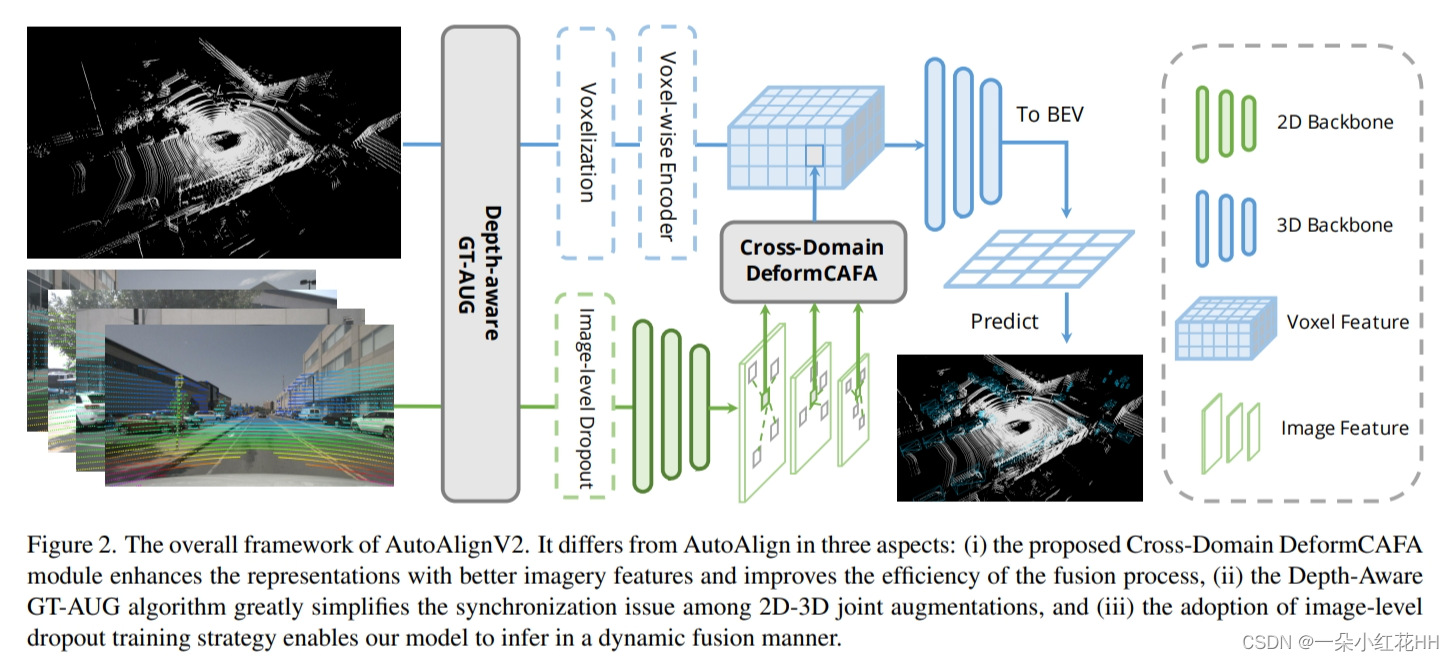
Deformable Feature Aggregation
Revisiting to CAFA
首先回顾 AutoAlign 中提出的交叉注意力特征对齐模块。它不是与相机-激光雷达投影矩阵建立确定性对应关系,而是使用可学习的对齐图对映射关系进行建模,这使得网络能够以动态和数据驱动的方式自动对齐非同质特征。具体来说,给定特征图 F = {f1, f2, …, fhw}(fi 表示第 i 个空间位置的图像特征)和体素特征 P = {p1, p2, …, pJ} (pj 表示从原始点云中提取的每个非空体素特征),每个体素特征pj将查询整个图像像素并基于体素特征和像素特征之间的点积相似度生成注意权重。每个体素特征的最终输出是根据注意力权重的所有像素特征值的线性组合。这种范例使模型能够聚合语义相关的空间像素来更新 pj,并且与特征的双线性插值相比表现出优越的性能。然而,巨大的计算成本将查询候选限制为仅 C5,从而丢失了高分辨率特征图中的细粒度信息。
Cross-Domain DeformCAFA
CAFA的瓶颈在于它将所有像素作为可能的空间位置。根据二维图像的属性,最相关的信息主要位于几何上邻近的位置。因此,不必考虑所有位置,而只考虑几个关键点区域。受此启发,本文引入了一种新颖的跨域变形CAFA操作(见图3),它大大减少了采样候选者,并为每个体素查询特征动态确定图像平面上的关键点区域。
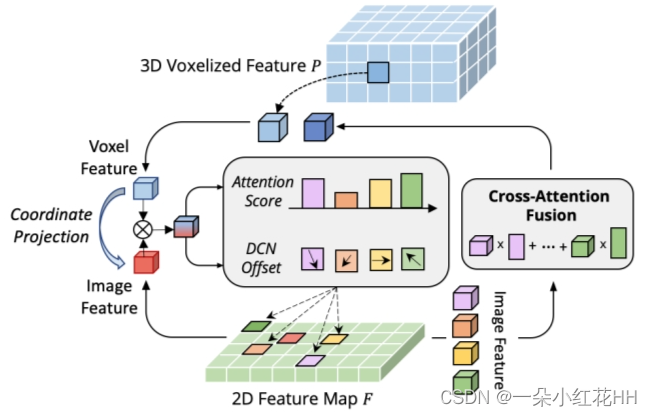
更正式地说,给定从图像主干(例如 ResNet、CSPNet)中提取的特征图 F ∈ Rh×w×d 和非空体素特征 P ∈ RN×c,首先计算参考点 Ri = (rx x, ,ri y) 在图像平面中从每个体素特征中心 Vi = (vi x, vi y, vi z) 与相机投影矩阵 Tcam−lidar,
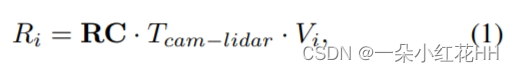
其中RC是相机的校正旋转矩阵和标定矩阵的组合。,获得参考点Ri后,采用双线性插值得到图像域的特征Fi。查询特征 Qi 是图像特征 Fi 和相应体素特征 Pj(稍后讨论)的逐元素乘积。,最终的可变形交叉注意力特征聚合的计算公式如下:
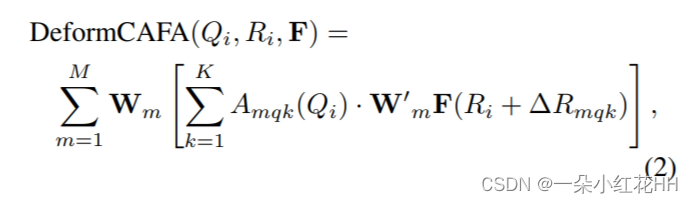
其中 Wm 和 W’ m 是可学习的权重,Amqk 是一个 MLP,用于在聚合图像特征上生成注意力分数。遵循自注意力机制的设计,本文采用M个注意力分裂头。这里,K是采样位置的数量(K2<<HW,例如K = 4)。借助动态生成的采样偏移量 Δmqk,DeformCAFA 能够比普通操作更快地进行跨域关系建模。复杂度从 O(NWH) 降低到 O(NK2),使本文能够执行多层特征聚合,即充分利用 FPN 层提供的层次信息。 DeformCAFA的另一个优点是它明确地保持与相机投影矩阵的位置一致性以获得参考点。因此,即使不采用 AutoAlign 中提出的 CFSI 模块, DeformCAFA 也可以产生语义和位置一致的对齐。
Cross-Domain Token Generation
与普通的非局部操作相比,稀疏风格的 DeformCAFA 极大地提高了效率。然而,当直接应用体素特征作为token来生成注意力权重和可变形偏移时,检测性能几乎无法与双线性插值对应物相比甚至更差。经过仔细分析,本文发现token生成过程中存在跨领域知识翻译问题。与通常在单模态设置下执行的原始可变形操作不同,跨域注意力需要来自两种模态的信息。然而,仅由空间表示组成的体素特征很难感知图像域中的信息。因此,允许不同模式之间的交互非常重要。
受启发,本文假设每个对象的表示可以明确地分解为两个组成部分:特定于域的信息和特定于实例的信息。前者指与表示本身相关的数据,包括域特征的内置属性,而后者表示有关对象的身份信息,无论其编码在哪个域中。具体来说,给定相应的配对图像特征Fi 和体素特征 Pj,有:
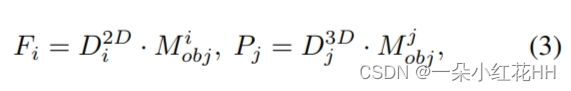
其中 D2D i 和 D3D j 是图像域和点域中的域相关特征,而 Mi obj 和 Mj obj 分别是特定于对象的表示。由于 Fi 和 Pj 是几何配对特征,因此 Mi obj 和 Mj obj 在特定于实例的表示空间中可以接近(即,Mobj ≈ Mi obj ≈ Mj obj)。基于此,可以隐式地交互不同领域知识的特征,
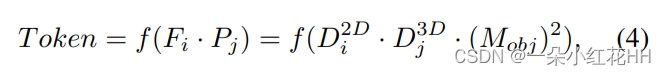
其中f是一个全连接(FC)层,用于聚合跨域信息并提高token生成的灵活性。
Depth-Aware GT-AUG
数据增强是大多数深度学习模型获得有竞争力的结果的关键部分。然而,就多模态 3D 目标检测而言,在数据增强中将点云和图像组合在一起时很难保持点云和图像之间的同步,这主要是由于对象遮挡或视点的变化。为了解决这个问题,本文设计了一种简单而有效的跨模式数据增强,名为深度感知 GT-AUG。与以往方法不同,本文的方法放弃了复杂的点云过滤过程或图像域中精细掩模注释的要求。相反,受到[38]中提出的 MixUp 的启发,结合了 3D 对象注释的深度信息来混合图像区域。
具体来说,给定要粘贴的虚拟对象 P,遵循 GT-AUG 中相同的 3D 实现。对于图像域,首先按照由远到近的顺序对它们进行排序。对于每个要粘贴的对象,从原始图像中裁剪相同的区域,并将它们与目标图像上的混合比 α 组合。,具体实现如算法1所示。

深度感知 GT-AUG 简单地遵循 3D 域中的增强策略,但同时通过基于 MixUp 的剪切和粘贴来保持图像平面中的同步。关键的直觉是,在将增强补丁粘贴到原始 2D 图像之上后,MixUp 技术并没有完全删除相应的信息。相反,它会衰减此类信息相对于深度的紧凑性,以保证对应点的特征的存在。具体来说,如果一个对象被其他实例遮挡 n 次,则该对象区域的透明度将根据其深度顺序衰减 (1 − α)n 倍。
Image-Level Dropout Training Strategy
实际上,图像通常是可选输入,可能并非所有 3D 检测系统都支持。因此,更现实、更适用的多模态检测解决方案应该是动态融合的方式:当图像不可用时,模型基于原始点云检测物体;当图像可用时,模型进行特征融合并产生更好的预测。为了实现这一目标,本文提出了一种图像级 dropout 训练策略,即在训练过程中随机丢弃图像级别的聚合图像特征并用零填充它们,如图 5 所示。由于图像信息会间歇性丢失,因此模型应该,逐渐学习利用 2D 特征作为一种替代输入。稍后,将展示这种策略不仅大大加快了训练速度(每批处理的图像更少),而且还提高了最终性能。

结论
本文开发了一种动态且快速的多模态 3D 目标检测框架 AutoAlignV2。它利用多层可变形交叉注意网络来提取和聚合来自不同模态的特征,从而大大加快了融合过程。还设计了深度感知 GT-AUG 策略来简化多模态数据增强过程中 2D 和 3D 域之间的同步。有趣的是, AutoAlignV2 更加灵活,可以以特定的方式在有图像和无图像的情况下进行推断,这更适合现实世界的系统。本文希望 AutoAlignV2 能够成为多模态 3D 对象检测中简单而强大的范例。