xlwings 简介
xlwings 是一个 Python 库。简化了 Python 和 Excel 通信。
xlwings - 让Excel跑得飞快!
本文写作背景 & 需求 & 方案
因前几个月帮在医院工作的朋友现学现卖用VBA写了段程序,处理2个excel文档的数据到第3个Excel文档上,有模板数据,有图表,怕数据出错,反复测试,折腾了有2天才弄出来。在摸索怎么用VBA开发的过程中发现,VBA开发太痛苦了。
前几天我无意间看到了一篇文章的标题 叫做 插上翅膀,让Excel飞起来——xlwings ,我被标题吸引住了,看到了有这么个东西。
更巧的是昨天朋友又让我帮她处理个Excel问题,这次的需求非常简单,为:
1. 只有一张只有3列的表
2. 如果表中存在两行或多行数据,它们的第2列和第3列数据都相同,第1列数据是否相同不考虑
3. 那么就只保留任意一行数据即可。
即:删除表中后两列数据相同的多余的行
于是乎想到了xlwings这个东西,想试一试,看看怎么玩(我还不会python的HelloWorld)
效果图如下:

解决方案
- 代码见本文编码部分,推荐方案代码2,实际情况不推荐!(2023/01/08更新:现在也不推荐方案代码2了,推荐方案代码3)
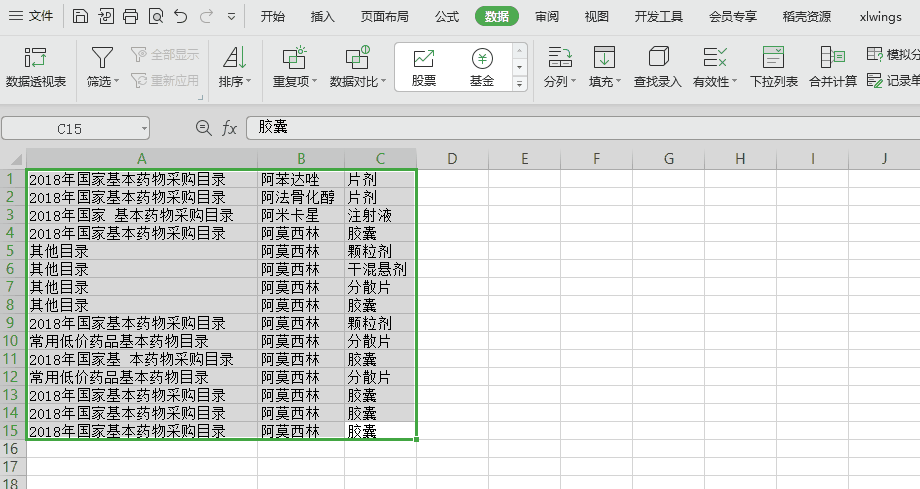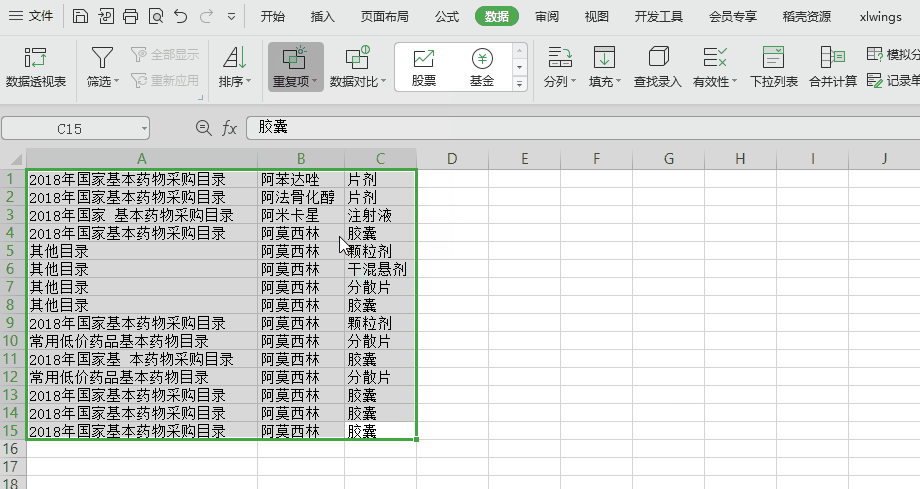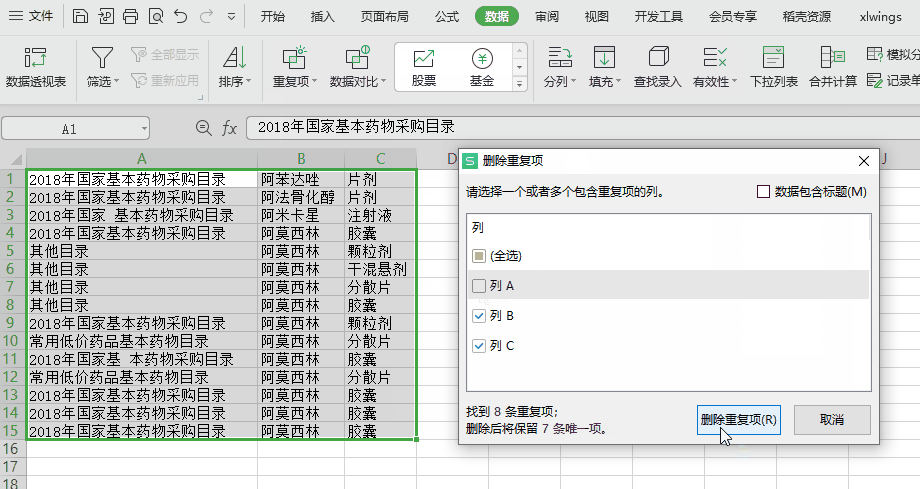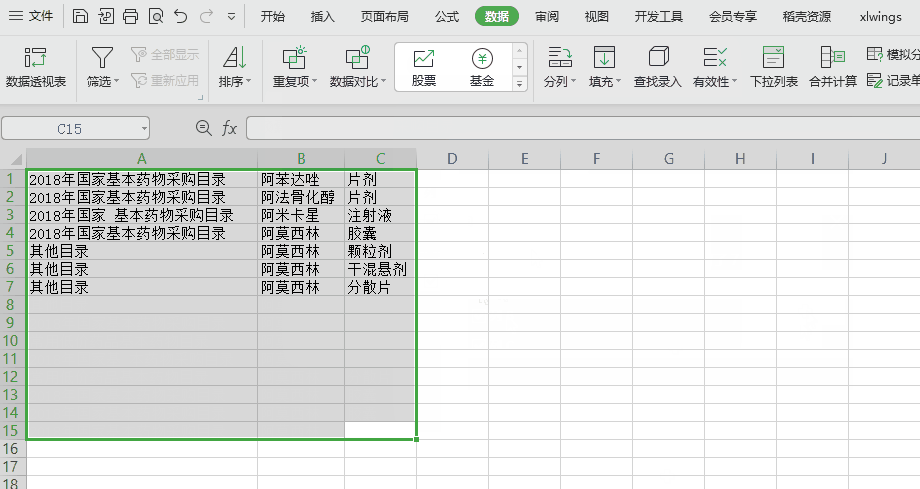
推荐优先不编码!使用 WPS 或 Excel 已有功能去实现,如下图,点几下就OK了。本文旨在站在程序猿的角度玩一把编码实现,尝试下python的味道。
环境准备
推荐使用 anaconda 解决环境问题,具体用法自行百度
Python3 安装
注意:安装时提供管理员权限,否则容易出错。
库安装
pip install 库名[=版本号]
-
xlwings
pip install xlwings
-
其他库(看需安装)
- NumPy
- NumPy Matplotlib
- pandas
Python 语法基础
>>> def fib(n):
>>> a, b = 0, 1
>>> while a < n:
>>> print(a, end=' ')
>>> a, b = b, a+b
>>> print()
>>> fib(1000)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
中文报错
需要首行加入 #coding=utf-8 或 # -*- coding: UTF-8 -*-
内置函数
https://docs.python.org/zh-cn/3.7/library/functions.html
type()用于检测一个数据的数据类型,非常有用。效果如:<class ‘list’> <class ‘xlwings.main.Range’>str()转为字符串int()转为intlen()获取序列或集合对象长度max()返回可迭代对象中最大值,等等其他数学函数round(num, n)四舍五入保留n位小数的函数input("请输入:")等待接收用户输入数据并将接收数据返回
严格代码对齐
因为没有大括号,必须要严格代码对齐,否则语义可能不同甚至报错!
序列类型 — list, tuple, range
-
列表list 是可变序列
class list([iterable])¶
使用一对方括号来表示空列表: []
使用方括号,其中的项以逗号分隔: [a], [a, b, c]
使用列表推导式: [x for x in iterable]
使用类型的构造器: list() 或 list(iterable) -
元组tuple是不可变序列,通常用于储存异构数据的多项集
class tuple([iterable])
使用一对圆括号来表示空元组: ()
使用一个后缀的逗号来表示单元组: a, 或 (a,)
使用以逗号分隔的多个项: a, b, c or (a, b, c)
使用内置的 tuple(): tuple() 或 tuple(iterable)
tuple(‘abc’) 返回 (‘a’, ‘b’, ‘c’) 而 tuple( [1, 2, 3] ) 返回 (1, 2, 3)。 如果没有给出参数,构造器将创建一个空元组 () -
范围range 类型表示不可变的数字序列,通常用于在 for 循环中循环指定的次数。
class range(stop)
class range(start, stop[, step]) -
举例
>>> 3,0,-1 (3, 0, -1) >>> (3,0,-1) # 同上,为元组,括号大多可省,不建议省 (3, 0, -1) >>> range(3,0,-1) # range ,表示开始为3,结束为1,步长为-1的整数范围 range(3, 0, -1) >>> for i in range(3,0,-1): ... print(i) ... 3 2 1
集合/字典
-
集合可用多种方式来创建:
使用花括号内以逗号分隔元素的方式: {‘jack’, ‘sjoerd’}
使用集合推导式: {c for c in ‘abracadabra’ if c not in ‘abc’}
使用类型构造器: set(), set(‘foobar’), set([‘a’, ‘b’, ‘foo’]) -
字典可用多种方式来创建:
使用花括号内以逗号分隔 键: 值 对的方式: {‘jack’: 4098, ‘sjoerd’: 4127} or {4098: ‘jack’, 4127: ‘sjoerd’}
使用字典推导式: {}, {x: x ** 2 for x in range(10)}
使用类型构造器: dict(), dict([(‘foo’, 100), (‘bar’, 200)]), dict(foo=100, bar=200)
for 循环,和其他语言还真不一样
语法格式只有 for-in 这一种格式
"for" target_list "in" expression_list ":" suite["else" ":" suite]`
因此,如果想动态修改循环次数,可使用while替换
r = 3
for i in range(r):print(i)# 下面的修改对for循环没有用,因为i的值会被下次循环覆盖,i的值在range范围内i-=1r-=2
# 输出:
# 0
# 1
# 2
字符串拼接
加号用于字符串拼接时,需要注意非字符串需要str()函数处理才可以,如:"你好" + str(123) ;或 print("你好%s"%123) 或更简单的print(a, b, c...) 或 format()方法拼接:
"你好{1}{0}{2}".format(1,2,3) # ‘你好213’ "你好{}{}{}".format(1,2,3) # ‘你好123’ 等
冒号
-
if / for 等语句中,分割代码作用
>>> if x < 0: ... x = 0 ... print('Negative changed to zero') ... elif x == 0: ... print('Zero') ... elif x == 1: ... print('Single') ... else: ... print('More') -
列表(类似C语言数组,Python中没有数组)引用中
>>> x [1, 3, 5, 8, 9] >>> x[1:3] # 索引范围 [3, 5] >>> x[:] # 全部 [1, 3, 5, 8, 9]包含3个子列表的一维列表X=array( [[1,2,3,4], [5,6,7,8], [9,10,11,12]] )
X[:, 0]就是取矩阵X的所有行的第0列的元素,X[:,1] 就是取所有行的第1列的元素
X[:, m:n]即取矩阵X的所有行中的的第m到n-1列数据,含左不含右 -
双冒号
推荐:官方文档在Range处的解释(点击查看)
a[x:y:z]
x表示切片起点,y表示切片终点,z表示步长,步长z默认为1;
如果z为正数,则默认x、y分别为列表的开始和结束索引,内容的公式为 a[i] = start + step*i 其中 i >= 0 且 r[i] < stop;
如果z为负数,表示倒序,内容的公式仍然为 a[i] = start + step*i,但限制条件改为 i >= 0 且 a[i] > z.;
如果 a[0] 不符合值的限制条件,则该 a 对象为空。 a 对象确实支持负索引(最后一个元素的索引是-1,倒数第二个元素索引为-2),但是会将其解读为从正索引所确定的序列的末尾开始索引;
如果z为0,则报错。如下:
>>> a = [1,3,5,8] >>> a[::] [1, 3, 5, 8] >>> a[1:3:] [3, 5] >>> a[::2] [1, 5] >>> a[::-1] [8, 5, 3, 1] >>> a[::-2] [8, 3] >>> a[1::-2] [3] >>> a[0:3:-1] [] >>> a[3:0:-1] [8, 5, 3] >>> a[3:0:-2] [8, 3] >>> a[1:3:0] Traceback (most recent call last):File "<stdin>", line 1, in <module> ValueError: slice step cannot be zerorange(10)[::2] 表示范围 [0, 10) 步长为2的切片
>>> range(10)[::2] range(0, 10, 2) -
切片完全指南(语法篇)
-
[xx for xx in yy] 链表推导式
-
for 循环
遍历列表的四种方法

类
https://www.runoob.com/python3/python3-class.html
class people:#定义基本属性name = ''age = 0#定义私有属性,私有属性在类外部无法直接进行访问__weight = 0#定义构造方法def __init__(self,n,a,w):self.name = nself.age = aself.__weight = wdef speak(self):print("%s 说: 我 %d 岁。" %(self.name,self.age))# 实例化类
p = people('runoob',10,30)
p.speak()
模块和包
https://www.runoob.com/python3/python3-module.html
- 模块,是一个python文件。包,是一个包含若干模块的文件夹。
- 模块导入方式
import 模块名 [as 别名]from 模块名 import <成员名1 [as 别名1], 成员名2 [as 别名2],...>或from 包名 import *
- 使用方式
有别名的使用别名,导入成员的可直接使用成员,否则使用 模块名.成员 - 包导入方式类似,包中必须包含文件
__init__.py,__all__
python 标准库
python 标准库
常用标准库——菜鸟教程
- sys
print(sys.argv) # 程序执行参数
print(sys.platform) # 系统平台
sys.exit()
sys.exit(“崩了”) - pprint
pprint.pprint(sys.modules) # 模块字典
print(sys.path) #模块搜索路径 - os
pprint.pprint(os.environ) # 格式化打印系统环境变量
print(os.environ[“path”]) # 打印path
os.system(“ls”) # 执行系统命令
print(os.getcwd()) # 当前的工作目录 - 字符串正则匹配
- 数学
- 日期和时间
- 数据压缩
- 访问互联网
零散知识点
__name__属性,主程序的该属性值为__main__dir()函数,可以找到模块内定义的所有名称
编码
本需求方案代码 1 (不推荐)
该代码虽然能得到正确的结果,但是 for i in range(rows-1): 语句内部虽然有对 rows 值的修改,但是i 在下次循环时又会被重新赋值,i 在下次循环的取值依然不会因循环体内部对 rows 的改变而改变。i 始终会将所有的 [0, rows-1) 内的整数值取完。可参见官方 for 语句解释
#coding=utf-8
# 首行作用:防止中文乱码
import xlwings as xw
import operator# 打开Excel程序,默认设置为程序可见,只打开不新建
app = xw.App(visible=True,add_book=False)
wb = xw.Book('test.xls')
sht = wb.sheets[0]rng = sht.range('A1').expand('table')
rows = rng.rows.count
cols = rng.columns.count
print(str(rows)+", "+ str(cols))# 将表中数据转为二维数组格式
all = sht.range((1,1),(rows,cols)).valuefor i in range(rows-1):print("--"+str(i)+"---")print(range(rows-1,i,-1))for j in range(rows-1,i,-1):# print(str(i)+", "+str(j))# 先用strip()去除单元格数据中首尾空白,防止数据因空白影响结果if operator.eq(all[i][1].strip(),all[j][1].strip()) and operator.eq(all[i][2].strip(),all[j][2].strip()):# print(all[j])# print(str(j))rng.rows[j].api.EntireRow.Delete()del all[j]rows-=1wb.save()
wb.close()
app.quit()
方案代码2 (推荐)(2023/01/08更新:不再推荐这种自写算法方案方式)
#coding=utf-8
import xlwings as xw# app = xw.App(visible=True, add_book=False)
wb = xw.Book('ok.xls')
# wb = app.books.open(r'D:/cuncaojin/desktop/ok.xls')
# wb = xw.Book(r'D:/cuncaojin/desktop/ok.xls')
sht = wb.sheets[0]# myList = [['2018年国家基本药物采购目录', '阿苯达唑', '片剂'], ['2018年国家基本药物采购目录', '阿法骨化醇', '片剂'], ['2018年国家 基本药物采购目录', '阿米卡星', '注射液'], ['2018年国家基本药物采购目录', '阿莫西林', '胶囊'], ['其他目录', '阿莫西林', '颗粒剂'], ['其他目录', '阿莫西林', '干混悬剂'], ['其他目录', '阿莫西林', '分散片'], ['其他目录', '阿莫西林', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', '颗粒剂'], ['常用低价药品基本药物目录', '阿莫西林', '分散片2'], ['2018年国家基 本药物采购目录', '阿莫西林', '胶囊'], ['常用低价药品基本药物目录', '阿莫西林', '分散片'], ['2018年国家基本药物采购目录', '阿莫西林3', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', '胶囊'], ['2018年国家基本药物采购目录', '阿莫西林', ' 胶囊']]
myList = sht[0,0].current_region.value# print(len(myList),"\n", myList)i = 0
while i<len(myList)-1:for j in range(len(myList)-1,i,-1):if myList[i][1].strip()==myList[j][1].strip() and myList[i][2].strip()==myList[j][2].strip():# 移除重复数据myList.remove(myList[j])# 补偿删除造成的数据迁移i-=1i+=1sht['F1'].value = myList
# sht['F1'].current_region.autofit()
# sht['F1'].current_region.color = (221,170,244)# 打印最终数据行数
print("最终有效数据行数:%d"%len(myList))wb.save()
wb.close()
# 有时quit、甚至使用kill都无法关闭Excel
# app.quit()
# app.kill()# 退出Excel应用
for app in xw.apps:app.quit()
方案代码3 (推荐,更新于2023/01/08)
得助于CSDN工具里chatgpt 引擎力量,让我初步了解了pandas库这么好用。加上报错自行百度,最终有此方案更新。
原表格数据
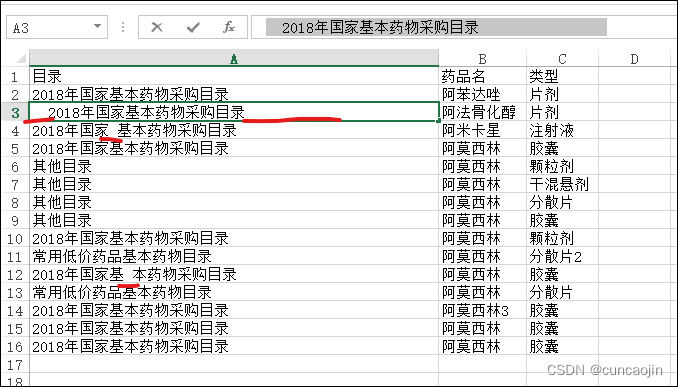
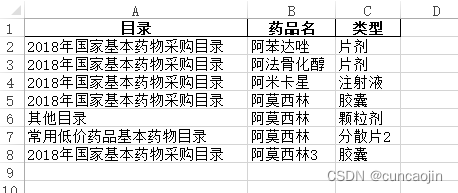
处理后表格数据
# 首先要安装依赖库
# pip install pandas
# python -m pip install openpyxldef deal_excel():import pandas as pddf = pd.read_excel('filename.xlsx')print(df)# 正则去除整个表中所有空白符df.replace('\s+', '', regex=True, inplace=True)# 去除“目录”列中每个单元格数据两端的空白符# df['目录'] = df['目录'].str.strip()print("///")print(df)df = df.drop_duplicates(subset=['目录', '药品名'], keep="first", inplace=False)print("///")print(df)# header为false则不要表头df.to_excel('filename.xlsx', index=False, header=True)# 注意:pycharm中python方法间要保持至少两行空行
if __name__ == '__main__':deal_excel()
通过以上脚本,处理了带有空白符数据的表格,日志如下:
目录 药品名 类型
0 2018年国家基本药物采购目录 阿苯达唑 片剂
1 2018年国家基本药物采购目录 阿法骨化醇 片剂
2 2018年国家 基本药物采购目录 阿米卡星 注射液
3 2018年国家基本药物采购目录 阿莫西林 胶囊
4 其他目录 阿莫西林 颗粒剂
5 其他目录 阿莫西林 干混悬剂
6 其他目录 阿莫西林 分散片
7 其他目录 阿莫西林 胶囊
8 2018年国家基本药物采购目录 阿莫西林 颗粒剂
9 常用低价药品基本药物目录 阿莫西林 分散片2
10 2018年国家基 本药物采购目录 阿莫西林 胶囊
11 常用低价药品基本药物目录 阿莫西林 分散片
12 2018年国家基本药物采购目录 阿莫西林3 胶囊
13 2018年国家基本药物采购目录 阿莫西林 胶囊
14 2018年国家基本药物采购目录 阿莫西林 胶囊
///目录 药品名 类型
0 2018年国家基本药物采购目录 阿苯达唑 片剂
1 2018年国家基本药物采购目录 阿法骨化醇 片剂
2 2018年国家基本药物采购目录 阿米卡星 注射液
3 2018年国家基本药物采购目录 阿莫西林 胶囊
4 其他目录 阿莫西林 颗粒剂
5 其他目录 阿莫西林 干混悬剂
6 其他目录 阿莫西林 分散片
7 其他目录 阿莫西林 胶囊
8 2018年国家基本药物采购目录 阿莫西林 颗粒剂
9 常用低价药品基本药物目录 阿莫西林 分散片2
10 2018年国家基本药物采购目录 阿莫西林 胶囊
11 常用低价药品基本药物目录 阿莫西林 分散片
12 2018年国家基本药物采购目录 阿莫西林3 胶囊
13 2018年国家基本药物采购目录 阿莫西林 胶囊
14 2018年国家基本药物采购目录 阿莫西林 胶囊
///目录 药品名 类型
0 2018年国家基本药物采购目录 阿苯达唑 片剂
1 2018年国家基本药物采购目录 阿法骨化醇 片剂
2 2018年国家基本药物采购目录 阿米卡星 注射液
3 2018年国家基本药物采购目录 阿莫西林 胶囊
4 其他目录 阿莫西林 颗粒剂
9 常用低价药品基本药物目录 阿莫西林 分散片2
12 2018年国家基本药物采购目录 阿莫西林3 胶囊
吐槽
顺便吐槽一下chatgpt,真是恶心透了,禁止咱们国家使用,明白地搞垄断、搞封锁。国内想使用该功能太麻烦了,要么搞国外服务器代理之类,要么掏钱使用国内中介服务,如使用CSDN的这个服务只免费使用不到5次,再想用就要办VIP才能用。
给自己看的其它代码
更多用法可访问本文参考链接部分,强烈建议看Python 官方api 、xlwings 官方api 和 Excel 官方api 。
import matplotlib.pyplot as plt
import xlwings as xwimport pandas as pd
import numpy as npimport osexit = os.path.exists(r'E:\yg\desktop\test.xlsx')app=xw.App(visible=True,add_book=False)if(exit):wb = xw.Book(r'E:\yg\desktop\test.xlsx')
else:wb=app.books.add()sht = wb.sheets[0]df = pd.DataFrame(np.random.rand(7, 4), columns=['aaa', 'bb', 'c', 'd'])
ax = df.plot(kind='bar')
fig = ax.get_figure()
sht.pictures.add(fig, name='MyPlot', update=True)wb.save(r'E:\yg\desktop\test.xlsx')
wb.close()
app.quit()
帮助
因没接触过python,也不懂VBA,因此本文内容可能存在若干不当或错误,如有发现,敬请斧正。
参考
- Python 官方标准库
- Python API
- [菜鸟教程——Python 3 教程
- 菜鸟教程——Python 基础教程
- xlwings 官方API 中文
- xlwings 官方文档 英文
- Range.EntireRow 属性 (Excel)
- xlwings 项目含Demo
- 插上翅膀,让Excel飞起来——xlwings
- 使用python绘制常用的图表
- Pandas 教程
- python numpy数组中冒号的使用
- python中双冒号[::]切片的作用
- Python_Python遍历列表的四种方法
- Python 中形如 xx for xx in yy 的链表推导式
- Pandas中如何去掉空格
- 51_Pandas (to_excel) 编写 Excel 文件 (xlsx, xls)





![[NAS] QNAP/威联通 常用设置和操作](https://img-blog.csdnimg.cn/cb4d601b67b34898b0e79ea6ca18f0d5.png)