- 语言:C语言
- 软件:Visual Studio 2022
- 笔记书籍:数据结构——用C语言描述
- 如有错误,感谢指正。若有侵权请联系博主
一、线性表的逻辑结构
线性表是n个类型相同的数据元素的有限序列,对n>0,除第一元素无直接前驱、最后一个元素无直接后继外,其余的每个元素只有一个直接前驱和一个直接后继。

线性表逻辑结构
线性表的特点:
- 同一性。线性表由同类数据元素组成,每一个aⁱ必须属于同一数据类型。
- 有穷性。线性表由有限个数据组成,表长度就是表中数据元素的个数。
- 有序性。线性表中相邻数据元素之间存在着序偶关系<aⁱ,aⁱ+1>
由此可以看出,线性表既是一种最简单的数据结构(数据元素之间由前驱/后继直观、有序的关系确定),又是一种常见的数据结构(矩阵、数组、字符串、堆栈、队列等都符合线性条件)。
二、线性表的抽象数据定义
线性表的抽象数据类型定义如下:
ADT LinearList{数据对象:D={aⁱ|aⁱ∈D₀,i=1,2,...,n,n≥0,D₀为某一数据对象}结构关系:R={<aⁱ,aⁱ+1>|aⁱ,aⁱ+1∈D,i=1,2,...,n-1}基本操作:1.InitList(L)操作前提:L为未初始化线性表。操作结果:将L初始化为空表。2.ListLength(L)操作前提:线性表L已存在。操作结果:如果L为空表则返回0,否则返回表中的元素的个数。3.GetData(L,i)操作前提:表L存在,且1≤i≤ListLength(L)。操作结果:返回线性表L中第i个合法元素的值。4.InsList(L,i,e)操作前提:表L已存在,e为合法元素值且1≤i≤ListLength(L)+1。操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1。5.DelList(L,i,e)操作前提:表L已存在且非空,1≤i≤ListLength(L)。操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1。6.Locate(L,e)操作前提:表L已存在,e为合法数据元素值。操作结果:如果L中存在数据元素e,则返回e在L中的位置,否则返回空位置。7.DestroyList(L)操作前提:线性表已存在。操作结果:将L销毁。8.ClearList(L)操作前提:线性表L已存在。操作结果:将L置为空表。9.EmptyList(L)操作前提:线性表L已存在。操作结果:如果L为空表则返回TRUE,否则返回FALSE。
}ADT LinearList;以上仅为一个抽象数据类型。因为一个抽象数据类型仅是一个模型的定义,并不设计模型的具体实现,因此这里使用参数不考虑具体类型。在实际问题中对线性表的运算可能很多,例如有时需要将多个线性表合并成一个线性表,以及在此问题基础之上进行的有条件合并等。像合并分拆/复制/排序等复合运算问题都可以利用基本运算的组合来实现。
三、线性表的链式存储结构的概念及单链表
1、概念
链式存储是最常用的动态存储方式。为了克服顺序表的缺点,可以采用链式存储。通常将采用链式存储结构的线性表称为线性链表。从链式方式的角度来看,链表可分为单链表、循环链表和双链表,从实现方式角度,链表可分为动态链表和静态链表。
2、单链表
在顺序表中是用一组地址连续的存储单元来依次存放线性表的节点,因此节点的逻辑顺序和物理顺序是一致的。而链表则是用一组任意的存储单元来存放线性表的节点,这组存储单元可以是连续的,也可以是非连续的,甚至是零散分布在内存的任何位置上。因此,链表中节点的逻辑顺序和物理顺序不一定相同。为了正确的表示节点间的逻辑关系,必须在存储线性表的每个数据元素值得同时,存储指示其后继节点的地址信息,这俩部分组成的存储映像称为链表节点。
链表的节点包含俩个域:数据域用来存储节点的值,指针域用来存储数据元素的直接后继地址。线性链表正是通过每个节点的指针域将n个节点按逻辑顺序链接在一起。每个节点只有一个next指针域的链表称为单链表,其结果如下图所示:
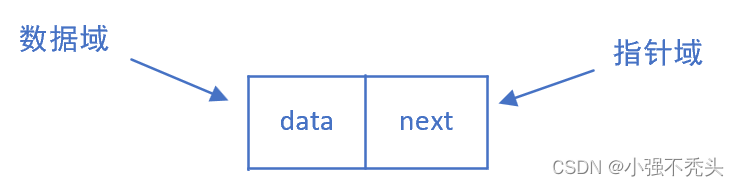
单链中每个节点的存储地址存放在其前驱节点的指针域中,由于线性表中第一个节点无前驱,所以应设一个头指针H指向第一个节点,由于线性表的最后一个节点没有直接后继,则指定单链表的最后一个节点的指针域为“空”(NULL)。
单链表的头指针H标示着整个单链表的开始,习惯上用头指针代表单链表。给定单链表的头指针H,即可顺着每个节点的next指针域得到单链表中的每个元素。单链表的逻辑顺序如下图所示:

单链表的逻辑状态
为了统一、方便,可以在单链表的第一个节点之前附设一个头节点。而头节点的指针域则用来存储指向第一个节点的指针(即第一个节点的存储位置)。此时头指针就不在指向表中第一个节点,而是指向头节点。如果线性表为空表,则头节点的指针域为“空”。逻辑如下图所示:

带头节点的单链表图示
四、线性表的链式存储结构的具体实现(单链表)
1、单链表的存储结构的表示
typedef struct Node //定义一个结构体 这个结构体的名字叫Node,typedef:用一个新的类型名代表原来的数据类型名,即用Node代表整个结构体类型
{ElemType data; //ElemType代表的是应该存储的数据的类型,可以是char,int,数组,结构体等等struct Node* next; //定义指向单链表中结点的指针
}Node,*LinkList; //LinkList为结构体指针类型说明:LinkList与Node *同为结构体指针类型,这俩种类型是等价的。习惯上用LinkList定义指向某个单链表的头指针变量,例如定义LinkList L,则L为指向单链表的头指针变量;用Node*定义指向单链表中结点的指针,例如Node *p,则p为指向单链表中节点的指针变量。
2、初始化单链表InitList(L)
算法思想:先用malloc为头指针开辟空间。malloc后边括号表示想要开辟空间的大小,这里用sizeof运算符获取结构体的内存空间,开辟刚好够的空间,malloc前边括号是强制类型转换,因为malloc返回值类型为void*,为了让他成为想要的类型,就需要在前边进行强制类型转换。malloc函数要导入<stdlib.h>头文件,代码就是:#include <stdlib.h>
为了放置内存泄漏,malloc开辟的空间,如果不用了需记得用free()函数释放开辟的空间
/*初始化单链表*/
int InitList(LinkList *L) {*L = (LinkList)malloc(sizeof(Node));(*L)->next = NULL; //将指针指向的地址置空return 0;
}第二行:传入的参数是个指针,这个指针存的数据是一个结构体指针。这个有点复杂,相当于把链表的头指针放到一个盒子里,而这个头指针本身就是一个盒子。
第三行:为这个指针地址里的的值开辟空间 即为盒子里的盒子开辟一个空间。
第四行:将指针指向的结构体的指针域置空。不能理解的 去看看前边关于链表结构的说明。
第五行:结束函数 返回结果0。
3、返回线性表中元素的个数ListLength(L)
算法思想:采用“数”结点的方法求出带头结点单链表中元素个数(长度),即从头开始“数”(r=r->next),用指针r依次指向各个结点,并附设计数器i计数,一直数到最后一个结点即p->next==NULL,从而的到单链表的长度。
/*返回线性表中元素的个数*/
int ListLength(LinkList L) {Node *r;r = L; int i = 0;while (r->next != NULL) {r = r->next;i++;}return i;
}第三行:定义一个节点指针变量,用于遍历时存储节点从而判断节点中的指针域是否为空,从而达到‘数’有多少个数据。
第四行:将头结点赋值给定义的变量,遍历时改变定义的变量从而不需要去破坏原有数据。它可以和第三行合并。
第五行:定义一个计数器,个数为0。
第六行:while循环 不满足条件结束循环,即节点中的指针域为空结束循环(这括号里的意思是不等于空即为真,执行循环,等于空结束循环)。
第七行:更新节点指针变量的值,使指向下一个节点。
第八行:每执行一次循环,计数器+1。
第十行:函数结束 返回元素个数。
这个函数时间足够的话细细研究一下,他是思路链表中的一个关键实现方式,思考一下如果将首元节点赋值给r(即r=L->next),循环条件咋设置,i的初始值咋设置。
4、返回线性表中第i个合法元素的值GetData(L,i)
算法思想:先定义一个结构体指针变量用于存放传入进来的链表,要不然一乱赋值,整个链表都乱了。定义一个计数器i用于看是否到指定位置。先判断输入地址是否合法即要在(0-ListLength(L))内,这个边界一定要注意。元素个数是从第一个开始的,地址下标才是从0开始的。若合法,在进行遍历,位于第几个,即循环执行链表指针移动多少次,最后遍历到的就是存放那个位置的数据。
ElemType GetData(LinkList L,int i) {Node* r;int j=0;r = L;if ((i > ListLength(L)) || i <= 0) {printf("返回位置不合法");return 0;}for (; j < i; j++) {r = r->next;}printf("第%d个元素是:%c",i,r->data);return r->data;
}第二行:声明一个节点结构体指针变量。
第三行:声明一个计数器,并赋值为0。
第四行:为声明的结构体指针赋值,便于后边操作链表而不至于破坏链表内数据。
第五行:判断寻找的元素是否合法,即要在0~链表长度范围内。
第六行:用于观察代码执行情况,可不要
第七行:如果寻找的元素不合法,直接结束函数 返回0
第九行:for循环,遍历寻找第i个数据,即循环i次
第十行:一层层往后走,直到结构体指针变量中存的是第i个节点。
第十二行:便于观察函数执行情况,可不要。
第十三行:将i节点中的数据域内数据作为函数结果返回。
5、将新的元素e插入表尾InsListEnd(L,e)
这个代码和书上给的代码不一样,书上给的是连续插入,这是另外一个思路,不想了解的可以略过,这个可以用InsList插入到最后实现。
算法思想:定义俩个结构体指针变量,一个用于存放新插入的数据,一个用于定位指针。为存放新插入的数据的指针变量开辟空间,将值存入,因为在表尾将指针域置空。将传入的链表头传入定位指针,移动定位指针,直到最后一个结点即指针域为空,再将新的结点插入到后边。
/*将新的元素e插入表尾*/
int InsListEnd(LinkList L, ElemType e) {Node* s = (LinkList)malloc(sizeof(Node)),*r;s->data = e;s->next = NULL;r = L;while (r->next != NULL) {r = r->next;}r->next = s;return 0;
}第三行:定义一个节点指针变量s,赋值时,这里用了malloc函数,它是C语言中开辟堆内存的函数,它前边的括号内是强制类型转换,将开辟的空间转换成LinkList类型,它后边的括号,是开辟的空间大小,这里用sizeof运算符获取这个节点应该需要多大的内存空间。后边还声明了另一个节点指针变量r,但并为其赋值。
第四行:将需要存入的数据放入为其新开辟的节点中的的数据域中。
第五行:因为是表尾插入,所以后续没有新的节点,故将指针域置空。
第六行:将链表L的头节点值赋值给声明的指针变量r,当做指针指向相应的节点。
第七行:判断该节点的指针域是否为空,为空结束循环。为啥要用为空来判断嘞,因为要把新的数据插入表位,单向链表中只有最后一个节点的指针域为空 借此来判断是否遍历到最后一个节点。
第八行:更新指针变量r中的值,将当前节点的下一节点值赋值给r。
第十行:当循环结束时,r中存放了最后一个节点,故只需要将新的节点的地址赋值给r中的指针域即可。
第十一行:结束函数 返回结果0。
6、将新的元素e插入表头InsListStrat(L,e)
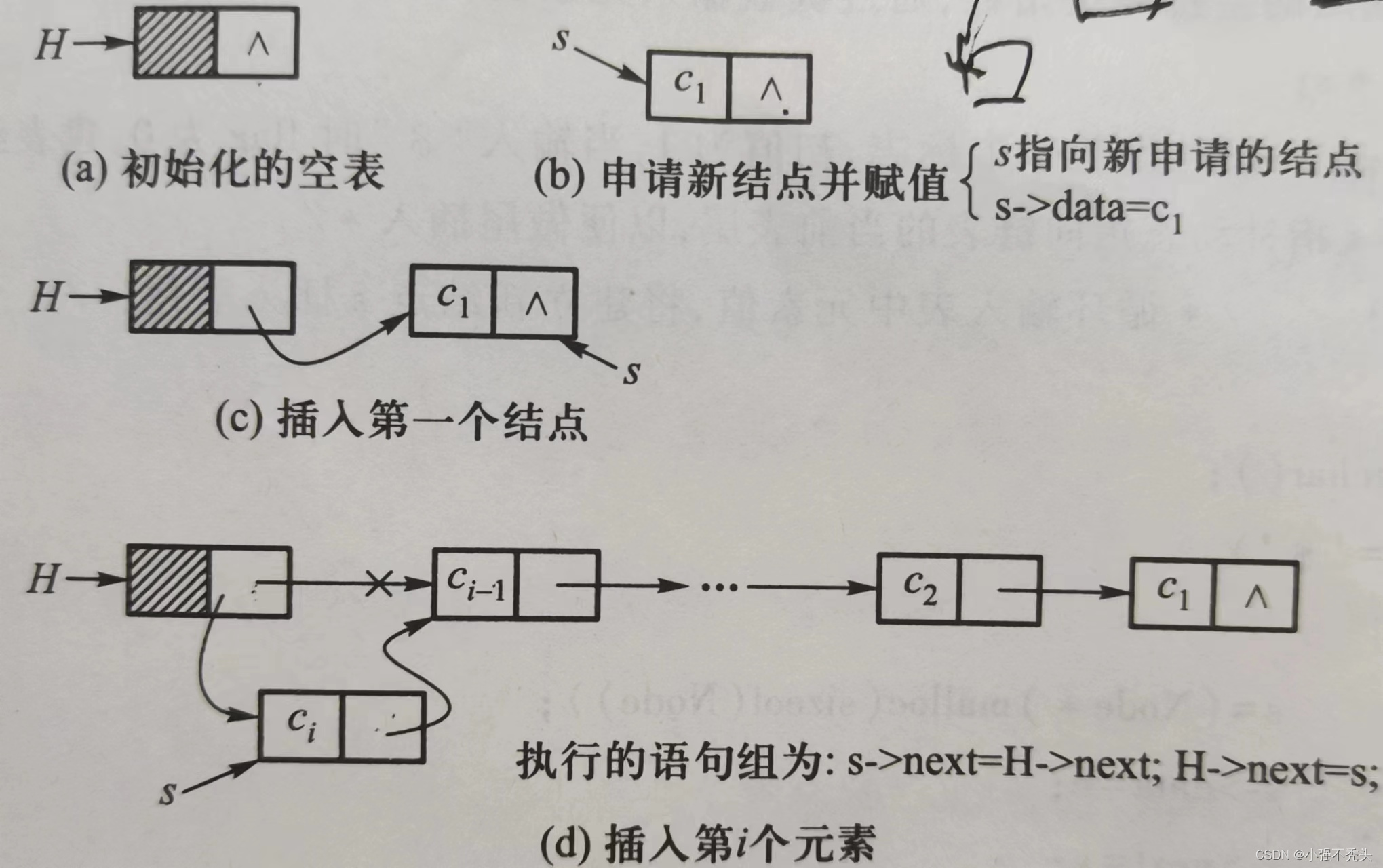
算法思想:创建一个指针变量,为指针变量开辟存储空间,将值赋给创建的变量中的数据域,再将头结点中存的地址值赋给创建的变量的指针域,最后将地址赋给头指针。变化示意图如下所示:
示意图
/*将新的元素e插入表头*/
int InsListStart(LinkList L, ElemType e) {Node* r = (LinkList)malloc(sizeof(Node));r->data = e;r->next = L->next;L->next = r;return 0;
}第三行:同上第三行
第四行:将需要存入的数据存入新开辟的节点中。
第五行:将首元节点的地址(即头节点中的指针域)赋值给新开辟的节点的指针域中,相当于图中断开链的那一步。
第六行:将新开辟的节点地址赋值给头结点的指针域 相当于图中重新连接的那一步。
第七行:函数结束 返回结果0。
7、在第i个地方插入一个新的数据元素 InsList(L,i,e)
算法思想:1.判断:判断插入地址是否在线性表长度范围内
2.查找:在单链表中找到第i-1个结点用于p指针指示
3.申请:申请新的结点s,将数据域的值置为e
4.插入:通过修改指针域将新结点s挂入单链表L
/*在第i个地方插入一个新的数据元素*/
int InsList(LinkList L, int i, ElemType e) {if (i <= 0 || i > (ListLength(L)+1)) {printf("插入地址不合法,建议使用LinkList()函数查看一下链表的长度");return 0;}Node* r = (LinkList)malloc(sizeof(Node)),*p;r->data = e;p = L;for (int j = 0; j < (i-1); j++) {p = p->next;}r->next = p->next;p->next = r;return 0;
}第三~六行:判断地址i是否合法,当小于等于0时是非法,比较没用第0个和负几个,超过最长长度也不行,毕竟如果只有30个,你说你要找第31个,咋可能有。
第七~九行:同上第三、四、六行。
第十、十一行:,遍历循环i次,使p中存放的是第i个节点的数据。
第十二行:将该节点的指针域内数据赋值给新开辟的节点的指针域中,即从该节点断开。
第十三行:将新开辟的节点地址存入断开处的指针域中。
不能理解的想象一下小时候玩的老鹰捉小鸡,假如有六个人在玩老鹰捉小鸡,刚好第三个人是你喜欢的人,你就想到她后边,你就得先去数,数到第三个人,然后让她后边的人松开第三个人的衣服,来牵着你的衣服(即第十二行),然后你再去抓住第三个人的衣服(即第十三行)。
8、删除L的第i个数据元素,并返回第i个元素的值 DeList(L,i)
算法思想:1.判断:判断需要删除的地址是否合法
2.查找:通过循环i-1次将获取需删除元素的前一个结点
3.转移:将需删除的结点转移找一个变量中,将需删除结点内指针域内数据转移到它前一个结点的指针域中
4.存值:将需删除的结点内的值存入一个变量中
5.删除:用free函数释放空间,最后返回之前存的值
/*删除L的第i个数据元素,并返回第i个元素的值*/
ElemType DelList(LinkList L, int i) {if (i <= 0 || i > ListLength(L)) {printf("删除地址不合法,建议使用LinkList()函数查看一下链表的长度");return 0;}Node* r,*pre;ElemType e;r = L;for (int j = 0; j < (i-1); j++) {r = r->next;}pre = r->next;r->next = pre->next;e = pre->data;free(pre);return e;
}第三~六行:同上三到六行,有点细微差别自己思考一下为啥。
第七行:声明俩个结构体指针变量,一个用于存节点,进行删除,一个用于遍历节点知道了指向哪个节点了。
第八行:声明一个变量,用于存储需要删除的节点中的数据域的值,也可以不声明,用函数的参数带出,不过用参数带出需要把参数设置成指针类型。
第九行:将头节点赋值给r。
第十~十二行:for遍历循环到i节点的前一个节点,即它的指针域指向的就是i节点,之所以在前一个节点停止,是为了将i节点的下一节点好放置在该节点,要不然按照单向单链表的性质,遍历过去了就不能往前走了。
第十三行:将i前一个节点的指针域(即i节点)赋值给存节点的指针变量(pre)。
第十四行:将i中下一节点赋值给i的上一节点的指针域中。至此,已将i节点完整取出。
第十五行:将i节点中的数据取出。
第十六行:是用free函数销毁开辟的堆内存,防止内存泄露。
第十七行:函数结束 返回结果e(即销毁的节点中的数据)。
9、按内容查找数据元素 Locate(L,e)
算法思想:定义一个计数器j,用于计指针所走的结点,用while循环遍历,内部设置一个指针移动r = r->next,再设置一个匹配语句和计数语句。
/*按内容查找数据元素*/
int Locate(LinkList L, ElemType e) {Node* r;int j = 1;r = L;while (r->next!=NULL) {r = r->next;if (r->data == e) {printf("%c为位于数组中%d的位置",e,j);return j;}j++;}printf("%c不在数组中",e);return 0;
}第三行:声明一个结构体节点指针。
第四行:声明一个计数器,并赋值为1,为啥要赋值为1嘞,因为判断的时候判断的是该节点的指针域去判断的,即无论如何都是从第一个开始的。
第五行:将头节点赋值给r。
第六行:while循环判断下一节点是否为空,若为空表示全遍历完了 还是没有。
第七行:将节点指向往后移。
第八~十一行:将循环中的每个节点中的数据域中的数据和需查找的数据进行匹配,匹配成功返回位于第几个。
第十二行:计数器 用于计数到第几个了。
10、打印输出顺序表 PrintList(L)
算法思想:判断是否为空表(因为要'[ ]',所以最后一个需特殊输出),空表直接输出空表提示语句。while遍历循环输出至倒数第二个,最后一个特殊输出。(注:因为最后一个特殊输出,不能将r最后赋值为NULL,故只能到倒数第二个。我目前只想到这个方法,若有好的方法,欢迎评论区留言,或私信作者)
/*打印输出顺序表*/
int PrintList(LinkList L) {if (L->next == NULL) {printf("该表是一个空表");return 0;}Node* r;printf("[");r = L->next;while (r->next != NULL) {printf("'%c',",r->data);r = r->next;}printf("'%c']\n", r->data);return 0;
}该函数为自定义的函数,用于观察链表中的数据,可有可没有,不做说明。
11、将线性表L置为空表 ClearList(L)
算法思想:将每一个结点逐个遍历,逐个销毁空间直至最后一个为空的结点,最后将头结点置空。
/*将线性表L置为空表*/
int ClearList(LinkList L) {Node* r, * pre;r = L->next;while (r != NULL) {pre = r;r = pre->next;printf("销毁%c", pre->data); //查看销毁情况,可以不要free(pre);}L->next = NULL;return 0;
}第三行:定义两个结构体指针变量,用于存储结点已经用于遍历结点。
第四行:将首元结点赋值给r。
第五行:while循环判断r是否为空,即若为空表示遍历到最后一个了。
第六行:将r赋值给另一指针变量,用于存储某一个结点。
第七行:再更改变量r的值。
第八行:便于观察程序允许情况,可以不要。
第九行:销毁拿出来的某一个结点,以此循环,直至处头节点外所有数据全删除。
第十一行:将头结点的指针域置空,即为空链表。
12、判断表是否为空 EmptyList(L)
算法思想:判断头节点的指针域是否为空即可。
/*判断表是否为空*/
bool EmptyList(LinkList L) {if (L->next == NULL) {printf("该表是一个空表");return true;}printf("该表不是一个空表");return false;
}第三行:判断链表是否为空,即头节点的指针域是否为空。
第四、五行:为空执行的代码,最后 返回true。
第七、八行:非空执行的代码。
第四、七行可以不要,仅仅是为了方便观察程序允许情况。
13、销毁线性表 DestroyList(L)
算法思想:先清空表,最后把头节点也销毁
/*销毁线性表*/
int DestroyList(LinkList L) {ClearList(L);free(L);return 0;
}第三行:执行线性表置空函数,将线性表置空。
第四行:销毁头指针。
第五行:结束函数,返回0。
五、单链表全部代码及每个模块测试
注:inputs函数是为了测试而设置的,慎用;它没有任何错误保障措施,也就是有一个出错了直接进入死循环,这个函数我自己也没搞懂。故用inputs函数测试的时候,别输入离谱的输入,否则就会报错。
#include <iostream>
#include <stdlib.h>
#define ElemType chartypedef struct Node
{ElemType data;struct Node* next;
}Node,*LinkList;/*初始化单链表*/
int InitList(LinkList *L) {*L = (LinkList)malloc(sizeof(Node));(*L)->next = NULL;return 0;
}/*返回线性表中元素的个数*/
int ListLength(LinkList L) {Node *r;r = L; int i = 0;while (r->next != NULL) {r = r->next;i++;}return i;
}/*返回线性表中第i个合法元素的值*/
ElemType GetData(LinkList L,int i) {Node* r;int j=0;r = L;if ((i > ListLength(L)) || i <= 0) {printf("返回位置不合法");return 0;}for (; j < i; j++) {r = r->next;}printf("第%d个元素是:%c",i,r->data);return r->data;
}/*将新的元素e插入表尾*/
int InsListEnd(LinkList L, ElemType e) {Node* r;Node* s = (LinkList)malloc(sizeof(Node));s->data = e;s->next = NULL;r = L;while (r->next != NULL) {r = r->next;}r->next = s;return 0;
}/*将新的元素e插入表头*/
int InsListStart(LinkList L, ElemType e) {Node* r = (LinkList)malloc(sizeof(Node));r->data = e;r->next = L->next;L->next = r;return 0;
}/*在第i个地方插入一个新的数据元素*/
int InsList(LinkList L, int i, ElemType e) {if (i <= 0 || i > (ListLength(L)+1)) {printf("插入地址不合法,建议使用LinkList()函数查看一下链表的长度");return 0;}Node* r = (LinkList)malloc(sizeof(Node)),*p;r->data = e;p = L;for (int j = 0; j < (i-1); j++) {p = p->next;}r->next = p->next;p->next = r;return 0;
}/*删除L的第i个数据元素,并返回第i个元素的值*/
ElemType DelList(LinkList L, int i) {if (i <= 0 || i > ListLength(L)) {printf("删除地址不合法,建议使用LinkList()函数查看一下链表的长度");return 0;}Node* r,*pre;ElemType e;r = L;for (int j = 0; j < (i-1); j++) {r = r->next;}pre = r->next;r->next = pre->next;e = pre->data;free(pre);return e;
}/*按内容查找数据元素*/
int Locate(LinkList L, ElemType e) {Node* r;int j = 1;r = L;while (r->next!=NULL) {r = r->next;if (r->data == e) {printf("%c为位于数组中%d的位置",e,j);return j;}j++;}printf("%c不在数组中",e);return 0;
}/*打印输出顺序表*/
int PrintList(LinkList L) {if (L->next == NULL) {printf("该表是一个空表");return 0;}Node* r;printf("[");r = L->next;while (r->next != NULL) {printf("'%c',",r->data);r = r->next;}printf("'%c']\n", r->data);return 0;
}/*将线性表L置为空表*/
int ClearList(LinkList L) {Node* r, * pre;r = L->next;while (r != NULL) {pre = r;r = pre->next;printf("销毁%c", pre->data); //查看销毁情况,可以不要free(pre);}L->next = NULL;return 0;
}/*判断表是否为空*/
bool EmptyList(LinkList L) {if (L->next == NULL) {printf("该表是一个空表");return true;}printf("该表不是一个空表");return false;
}/*销毁线性表*/
int DestroyList(LinkList L) {ClearList(L);free(L);return 0;
}/*通过键盘连续获取值并插入表中*/
int inputs(LinkList L) { int num, chars,i;printf("1.表头插入 2.表尾插入 3.选择位置插入");printf("请输入要插入的方式(数字):");for (int n = 0; n < 5;n++) {scanf_s("%d", &num);if (num == 1 || num == 2 || num == 3) break;printf("输入错误,请在1-3中输入一个数字:");}printf("请输入要插入的个数:");scanf_s("%d",&i);if (num == 1) {for (int j = 0; j < i; j++) {printf("请输入第%d个数据",(j+1));scanf_s("%c", &chars);scanf_s("%c", &chars);InsListStart(L, chars);}}else if (num == 2) {for (int j = 0; j < i; j++) {printf("请输入第%d个数据", (j + 1));scanf_s("%c", &chars);scanf_s("%c", &chars);InsListEnd(L, chars);}}else {int site;ElemType value;for (int j = 0; j < i; j++) {printf("请输入你要插入的位置:");scanf_s("%d", &site);printf("请输入你要插入的数据:");scanf_s("%c", &value);scanf_s("%c", &value);InsList(L, site, value);}}return 0;
}int main()
{LinkList *L,list; //list是一个头节点,是指针变量;L是存放节点的,是存放指针变量的指针变量。L = &list;InitList(L);printf("---------------------长度为0测试,元素个数、输出测试-------------------\n");printf("元素个数为%d\n", ListLength(list));PrintList(list);printf("\n\n\n--------------------头插法测试、长度获取测试、输出测试-------------------\n");inputs(list);printf("元素个数为%d", ListLength(list));PrintList(list);printf("\n\n\n----------------------尾插法测试、输出测试----------------------\n");inputs(list);printf("元素个数为%d\n", ListLength(list));PrintList(list);printf("\n\n\n---------------------------随机插入测试、输出测试------------------\n");inputs(list);printf("元素个数为%d\n", ListLength(list));PrintList(list);printf("\n\n\n---------------------按位置查找测试---------------------\n");printf("查找第3个值\n");GetData(list, 3);printf("\n查找第0个值\n");GetData(list, 0);printf("\n查找第100个值\n");GetData(list, 100);printf("\n查找第-1个值\n");GetData(list,-1);printf("\n\n\n------------------------按值查找测试---------------------------\n");printf("查找A\n");Locate(list,'A');printf("\n查找*\n");Locate(list, '*');printf("\n\n\n----------------------------------删除测试-------------------\n");printf("删除第3个位置的值\n");DelList(list, 3);printf("\n删除第100个位置的值\n");DelList(list, 100);printf("\n删除第0个位置的值\n");DelList(list, 0);printf("\n\n\n-------------------------判断表是否为空、置空测试---------------------\n");printf("判断表是否为空\n");EmptyList(list);printf("将表置空\n");ClearList(list);printf("再次判断表是否为空\n");EmptyList(list);printf("\n\n\n-------------------销毁表测试-------------------\n");printf("销毁结果:%d",DestroyList(list));
}测试结果