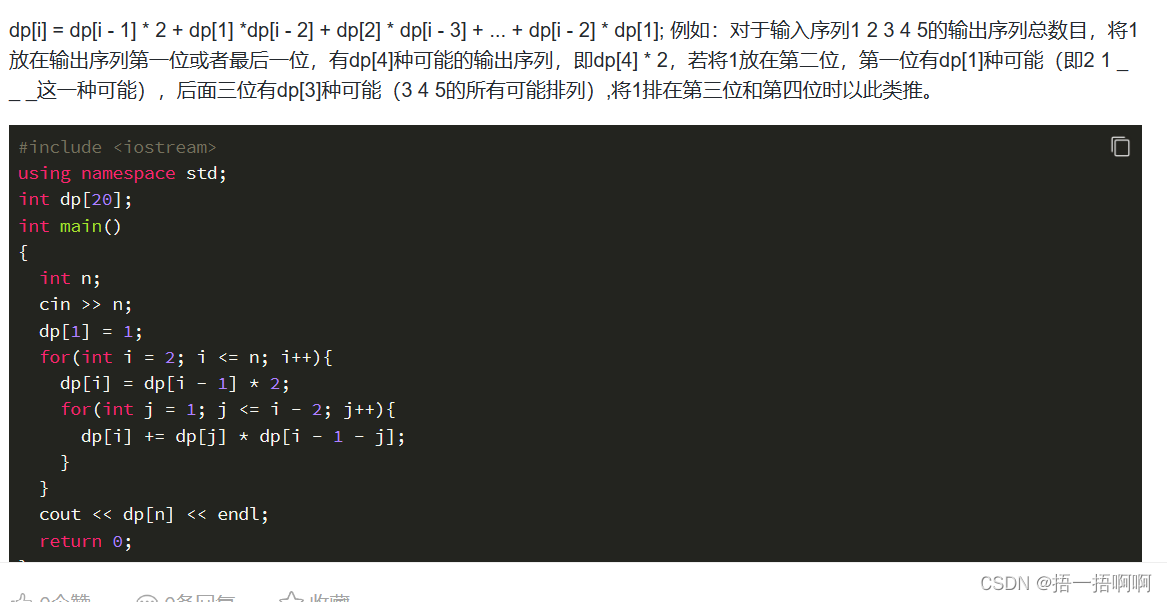
一、向量加法程序
Radeon Open Compute (ROCm) 是一个开源平台,用于加速高性能计算 (HPC) 和机器学习应用程序。它支持包括GPUs在内的多种硬件,并提供HIP (Heterogeneous-compute Interface for Portability) 作为CUDA代码的便捷转换工具。为了提供一个使用ROCm的实例,假设已经在符合要求的硬件上安装了ROCm环境。下面的例子是一个简单的向量加法程序,使用了ROCm的HIP API。
首先,需要编写 HIP 源代码,该代码之后可以被编译运行在 AMD GPU 上。可以创建一个名为 vector_add.cpp 的文件:
#include <hip/hip_runtime.h>
#include <iostream>#define N 50000__global__ void vector_add(float *out, float *a, float *b, int n) {int index = threadIdx.x + blockIdx.x * blockDim.x;if (index < n) {out[index] = a[index] + b[index];}
}int main() {float *a, *b, *out;float *d_a, *d_b, *d_out;// 分配host内存a = (float*)malloc(sizeof(float) * N);b = (float*)malloc(sizeof(float) * N);out = (float*)malloc(sizeof(float) * N);// 初始化数据for (int i = 0; i < N; i++) {a[i] = float(i);b[i] = float(i);}// 分配device(GPU)内存hipError_t err; err = hipMalloc((void**)&d_a, sizeof(float) * N);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMalloc failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }err = hipMalloc((void**)&d_b, sizeof(float) * N);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMalloc failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }err = hipMalloc((void**)&d_out, sizeof(float) * N);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMalloc failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }// 将host数据复制到device(GPU)上err = hipMemcpy(d_a, a, sizeof(float) * N, hipMemcpyHostToDevice);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMemcpy failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }err = hipMemcpy(d_b, b, sizeof(float) * N, hipMemcpyHostToDevice);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMemcpy failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }// 执行kernelint blockSize = 256;int gridSize = (int)ceil((float)N/blockSize);hipLaunchKernelGGL(vector_add, dim3(gridSize), dim3(blockSize), 0, 0, d_out, d_a, d_b, N);// 将计算结果复制回host内存err = hipMemcpy(out, d_out, sizeof(float) * N, hipMemcpyDeviceToHost);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipMemcpy failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }// 验证结果for (int i = 0; i < N; i++) {if (out[i] != a[i] + b[i]) {std::cerr << "结果验证失败,索引 " << i << ", " << out[i] << " != " << a[i] + b[i] << std::endl;break;}}// 释放内存err = hipFree(d_a); if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipFree failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }err = hipFree(d_b); if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipFree failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }err = hipFree(d_out);if (err != hipSuccess) {// 处理错误,比如打印错误信息并退出程序 fprintf(stderr, "hipFree failed: %s\n", hipGetErrorString(err)); exit(EXIT_FAILURE); }free(a); free(b); free(out);return 0;
}
接下来可以使用 hipcc 编译器来编译上述程序。hipcc 是一个包装好的编译器,用于将HIP源码编译为可以在准备好的AMD平台上运行的代码:
hipcc vector_add.cpp -o vector_add编译成功后,可以运行生成的应用程序:
./vector_add以上代码演示了如何使用HIP编写一个简单的GPU内核,其计算两个向量的逐元素加法。请确保在运行任何这些步骤之前,检查环境是否配置正确,ROCm是否与AMD GPU兼容,并且已正确安装。如果对ROCm更复杂的使用场景感兴趣,可以查看ROCm提供的示例和使用指南。

二、通义灵码
ROCm(Radeon Open Compute Platform)提供了HIP(Heterogeneous-Compute Interface for Portability)API,允许开发者编写高度可移植的代码,能够在AMD GPU和其他异构平台上运行。以下是一个使用HIP API编写的简单向量加法程序示例:
#include <hip/hip_runtime.h>
#include <iostream>#define VECTOR_SIZE 1024 // 向量长度// 定义向量加法的内核函数
__global__ void vectorAdd(float* A, float* B, float* C) {int idx = threadIdx.x + blockIdx.x * blockDim.x;if (idx < VECTOR_SIZE) {C[idx] = A[idx] + B[idx];}
}int main() {float* h_A; // 主机侧向量Afloat* h_B; // 主机侧向量Bfloat* h_C; // 主机侧结果向量C(用于验证)float* d_A; // 设备侧向量Afloat* d_B; // 设备侧向量Bfloat* d_C; // 设备侧结果向量Csize_t size = VECTOR_SIZE * sizeof(float);// 分配主机内存并初始化向量h_A = new float[VECTOR_SIZE];h_B = new float[VECTOR_SIZE];h_C = new float[VECTOR_SIZE];for (size_t i = 0; i < VECTOR_SIZE; ++i) {h_A[i] = static_cast<float>(i);h_B[i] = static_cast<float>(i * 2);}// 分配设备内存hipMalloc(&d_A, size);hipMalloc(&d_B, size);hipMalloc(&d_C, size);// 将主机内存数据复制到设备hipMemcpy(d_A, h_A, size, hipMemcpyHostToDevice);hipMemcpy(d_B, h_B, size, hipMemcpyHostToDevice);// 定义并启动内核dim3 blockSize(256); // 每块256个线程dim3 gridSize((VECTOR_SIZE + blockSize.x - 1) / blockSize.x); // 计算所需网格数vectorAdd<<<gridSize, blockSize>>>(d_A, d_B, d_C);// 将设备计算结果复制回主机hipMemcpy(h_C, d_C, size, hipMemcpyDeviceToHost);// 验证结果bool resultCorrect = true;for (size_t i = 0; i < VECTOR_SIZE; ++i) {if (h_C[i] != h_A[i] + h_B[i]) {resultCorrect = false;break;}}std::cout << "Vector addition test " << (resultCorrect ? "PASSED" : "FAILED") << std::endl;// 释放资源hipFree(d_A);hipFree(d_B);hipFree(d_C);delete[] h_A;delete[] h_B;delete[] h_C;return 0;
}
三、文心一言
HIP (Heterogeneous-compute Interface for Portability) 是一个用于简化在AMD GPU上编程的接口,它提供了类似于CUDA的编程模型,使得开发者可以更容易地将CUDA代码迁移到HIP上,以在AMD GPU上运行。
下面是一个简单的HIP程序示例,用于执行向量加法。请注意,这个示例假设你已经安装并配置了ROCm和HIP环境。
首先,你需要创建一个HIP源文件(例如,vector_add.hip),并写入以下代码:
#include <hip/hip_runtime.h>
#include <hip/hip_vector_types.h> __global__ void vector_add(float* A, float* B, float* C, int N) { int i = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x; if (i < N) { C[i] = A[i] + B[i]; }
} int main(void) { const int N = 1 << 20; // 1M elements const size_t size = N * sizeof(float); // Allocate Unified Memory – accessible from CPU or GPU float *A, *B, *C; hipMallocManaged(&A, size); hipMallocManaged(&B, size); hipMallocManaged(&C, size); // Initialize data on the host for (int i = 0; i < N; i++) { A[i] = 1.0f; B[i] = 2.0f; } // Run kernel on 1M elements on the GPU hipLaunchKernelGGL((vector_add), dim3(N/256, 1, 1), dim3(256, 1, 1), 0, 0, A, B, C, N); // Wait for GPU to finish before accessing on host hipDeviceSynchronize(); // Verify results for (int i = 0; i < N; i++) { if (C[i] != 3.0f) { printf("Error at element %d: %f != 3.0f\n", i, C[i]); return -1; } } printf("Test PASSED\n"); // Free memory hipFree(A); hipFree(B); hipFree(C); return 0;
}在这个示例中,vector_add 是一个GPU内核函数,用于执行向量加法。main 函数中首先分配了统一内存(Unified Memory),这是一种HIP和ROCm支持的特性,允许CPU和GPU无缝地访问同一块内存区域。然后,初始化数据并调用HIP内核。最后,验证结果并释放内存。
编译这个程序,你需要使用hipcc编译器,它是专门为HIP设计的。编译命令可能类似于:
hipcc -o vector_add vector_add.hip确保你的环境变量和路径已经配置好,以便hipcc可以找到ROCm和HIP相关的库和头文件。
运行编译后的程序:
./vector_add如果一切正常,你应该会看到“Test PASSED”的输出,表示向量加法已经成功执行。
请注意,HIP和ROCm的API和功能可能会随着版本的更新而发生变化,因此请确保查阅最新的官方文档以获取最准确的信息。

四、讯飞星火
以下是一个使用ROCm的HIP API进行向量加法的程序示例:
#include <iostream>
#include <vector>
#include <hip/hip_runtime.h>__global__ void vectorAdd(const float* A, const float* B, float* C, int numElements) {int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < numElements) {C[i] = A[i] + B[i];}
}int main() {int numElements = 50000;size_t size = numElements * sizeof(float);float* h_A = new float[numElements];float* h_B = new float[numElements];float* h_C = new float[numElements];for (int i = 0; i < numElements; ++i) {h_A[i] = static_cast<float>(i);h_B[i] = static_cast<float>(i * 2);}float* d_A = nullptr;float* d_B = nullptr;float* d_C = nullptr;hipMalloc((void**)&d_A, size);hipMalloc((void**)&d_B, size);hipMalloc((void**)&d_C, size);hipMemcpy(d_A, h_A, size, hipMemcpyHostToDevice);hipMemcpy(d_B, h_B, size, hipMemcpyHostToDevice);dim3 dimBlock(256);dim3 dimGrid((numElements + dimBlock.x - 1) / dimBlock.x);hipLaunchKernelGGL(vectorAdd, dimGrid, dimBlock, 0, 0, d_A, d_B, d_C, numElements);hipMemcpy(h_C, d_C, size, hipMemcpyDeviceToHost);for (int i = 0; i < numElements; ++i) {if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {std::cout << "Result verification failed at element " << i << std::endl;break;}}delete[] h_A;delete[] h_B;delete[] h_C;hipFree(d_A);hipFree(d_B);hipFree(d_C);return 0;
}
这个程序首先创建了三个大小为`numElements`的浮点数数组`h_A`、`h_B`和`h_C`,并将`h_A`和`h_B`的元素分别设置为连续的整数。然后,它使用HIP API分配设备内存并将主机数据复制到设备上。接下来,它定义了一个名为`vectorAdd`的CUDA内核函数,该函数将两个输入向量相加并将结果存储在输出向量中。最后,它将计算结果从设备复制回主机,并验证结果的正确性。如果结果验证失败,则输出错误信息。最后,它释放了所有分配的内存。

五、Kimi
ROCm(Radeon Open Compute)是一个开源的计算平台,旨在为AMD GPU提供高性能的计算能力。HIP(Heterogeneous-compute Interface for Portability)是ROCm的一个C/C++运行时API,它允许开发者编写可在多种计算设备上运行的代码,包括CPU和GPU。
下面是一个使用ROCm的HIP API实现的简单向量加法程序示例。这个程序将创建两个向量,将它们相加,并输出结果。
#include <hip/hip_runtime.h>
#include <iostream>__global__ void vectorAdd(const float *A, const float *B, float *C, int N) {int i = hipBlockIdx.x * hipBlockDim.x + hipThreadIdx.x;if (i < N) {C[i] = A[i] + B[i];}
}int main() {int N = 1 << 10; // 向量大小size_t size = N * sizeof(float);float *h_A, *h_B, *h_C;float *d_A, *d_B, *d_C;// 分配主机内存h_A = new float[N];h_B = new float[N];h_C = new float[N];// 初始化主机向量for (int i = 0; i < N; i++) {h_A[i] = i;h_B[i] = i * 2;}// 分配设备内存hipMalloc((void **)&d_A, size);hipMalloc((void **)&d_B, size);hipMalloc((void **)&d_C, size);// 将主机向量复制到设备hipMemcpy(d_A, h_A, size, hipMemcpyHostToDevice);hipMemcpy(d_B, h_B, size, hipMemcpyHostToDevice);// 启动核函数hipLaunchKernelGGL(vectorAdd, dim3((N + 255) / 256), dim3(256), 0, 0, d_A, d_B, d_C, N);// 将结果从设备复制回主机hipMemcpy(h_C, d_C, size, hipMemcpyDeviceToHost);// 验证结果for (int i = 0; i < N; i++) {if (h_C[i] != (h_A[i] + h_B[i])) {std::cout << "Error: C[" << i << "] != A[" << i << "] + B[" << i << "]" << std::endl;break;}}// 释放设备内存hipFree(d_A);hipFree(d_B);hipFree(d_C);// 释放主机内存delete[] h_A;delete[] h_B;delete[] h_C;return 0;
}在这个程序中,我们首先定义了一个名为`vectorAdd`的核函数,它将在GPU上执行。然后在`main`函数中,我们分配了主机和设备的内存,初始化了两个向量,并将它们复制到设备内存中。
接下来,我们调用`hipLaunchKernelGGL`函数来启动核函数。核函数执行后,我们将结果从设备内存复制回主机内存,并验证结果是否正确。
最后,我们释放了所有分配的内存资源。
要编译和运行这个程序,你需要安装ROCm软件平台,并使用`hipcc`编译器。例如,你可以使用以下命令来编译这个程序:
hipcc -o vector_add vector_add.cu
./vector_add请注意,这个程序是一个基本的示例,实际使用时可能需要根据具体情况进行调整。此外,为了提高性能,你可能需要调整线程块大小和网格大小等参数。