2024Mathorcup数学应用挑战赛C题|图神经网络的预测模型+ARIMA时间序列预测模型+人员排班混合整数规划模型|完整代码和论文全解全析
我们已经完成了2024Mathorcup数学建模挑战赛C题的40+页完整论文和代码,相关内容可见文末,部分图片如下:

问题分析
这是一个关于电商物流网络分拣中心货量预测和人员排班的复杂问题,需要综合运用多种数据分析和建模技术。以下是本文的问题分析 :
问题背景及目标分析
-
这是一个电商物流网络中分拣中心的货量预测及人员排班问题。分拣中心作为网络的中间环节,其管理效率直接影响整体网络的履约效率和运作成本。
-
主要目标包括:
-
根据历史货量数据预测未来30天各分拣中心的每日及每小时货量。
-
在线路关系发生变化的情况下,再次预测未来30天各分拣中心的每日及每小时货量。
-
建立人员排班模型,合理安排正式工和临时工,在完成货量处理的前提下尽量降低人员成本。
-
针对特定分拣中心(SC60),确定正式工和临时工的具体出勤计划。
数据分析及预处理
-
附件1提供了57个分拣中心过去4个月的每日货量数据,附件2提供了这些分拣中心过去30天的每小时货量数据。
-
附件3给出了过去90天各分拣中心之间的平均运输货量,附件4描述了未来30天分拣中心之间的线路变化。
-
需要对这些数据进行清洗、缺失值处理、异常值检测等预处理步骤,确保数据质量。
问题一和问题二货量预测模型分析
-
针对问题1,可以尝试时间序列预测模型,如ARIMA、Prophet、神经网络等,对各分拣中心的每日及每小时货量进行预测。
-
考虑到线路关系的动态变化,在问题2中可以结合分拣中心间的网络连接关系,构建基于图神经网络的预测模型,提高预测精度。
-
可以采用滚动预测的方式,利用最新的历史数据不断更新预测结果,提高模型适应性。
-
对预测结果进行评估,选择合适的模型和参数设置,确保预测的准确性和稳定性。
问题三人员排班优化模型分析
-
针对问题3,可以建立一个优化模型,在满足每个分拣中心每个班次的货量处理需求的前提下,最小化总人力成本。
-
模型可以包括以下约束条件:
-
每名员工(正式工或临时工)每天只能出勤一个班次。
-
正式工的最高小时人效为25包裹/小时,临时工的为20包裹/小时。
-
尽量减少总人天数,同时保证每天的实际小时人效尽量均衡。
-
可以采用整数规划、启发式算法等方法求解此优化问题。
问题四特定分拣中心排班计划分析
-
针对问题4,以分拣中心SC60为例,需要在满足每天货量处理需求的前提下,确定正式工和临时工的具体出勤计划。
-
需要考虑的约束条件包括:
-
每名正式工的出勤率不能高于85%,连续出勤天数不能超过7天。
-
在每天货量处理完成的基础上,安排的总人天数尽可能少。
-
每天的实际小时人效尽量均衡,正式工的出勤率也尽量均衡。
-
可以采用类似于问题3的优化建模方法,结合正式工出勤率约束,求解此问题
模型的建立与求解
问题1货量预测模型的建立与求解
针对问题1的货量预测部分的复杂的时间序列预测问题,需要综合运用多种建模技术。下面是我的分析:
-
问题概述 电商物流网络的分拣中心是整个网络运作的关键环节,对分拣中心的货量预测对后续的资源管理和决策至关重要。问题1要求建立货量预测模型,对57个分拣中心未来30天的每日和每小时货量进行预测。这需要充分利用历史货量数据,选择合适的预测算法,并对结果进行评估和优化。
-
数据预处理 首先需要对附件1和附件2提供的历史货量数据进行预处理,包括:
-
数据清洗:识别并处理异常值、缺失值等问题,确保数据质量。
-
特征工程:根据业务需求,挖掘和构造可能影响货量的相关特征,如节假日、天气等。
-
时间序列分析:对原始货量序列进行平稳性检验,必要时进行差分或对数变换等操作。
-
时间序列预测模型 针对这个问题,我们可以尝试以下几种时间序列预测模型:
ARIMA时间序列模型建立
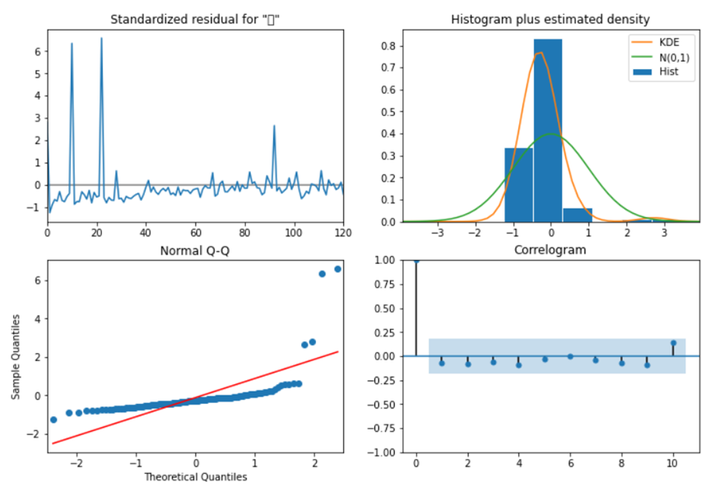
使用ARIMA模型进行预测的主要步骤如下: 1. 模型识别:通过观察数据的自相关函数(ACF)和偏自相关函数(PACF),确定合适的p和q值。选择适当的d值,使序列满足平稳性假设。 2. 参数估计:利用最小二乘法或极大似然估计法,估计ARIMA模型的参数。 3. 模型诊断:对估计的ARIMA模型进行检验,确保模型残差满足白噪声假设。 4. 预测与评估:将确定的ARIMA模型应用于未来30天的预测,并采用滚动预测的方式不断更新模型。使用MAE、RMSE等指标评估预测结果。
Prophet时间序列模型建立
Prophet是Facebook开源的一种时间序列预测模型,它结合了傅里叶级数和增长模型,能够很好地处理时间序列中的趋势、季节性和节假日等因素。Prophet模型的数学表达式如下:
其中: - 是趋势函数 - 是周期性函数 - 是节假日效应 - 是误差项
Prophet模型的优点是可解释性强,容易调参,适合于具有明显趋势和季节性的时间序列。它的建模步骤如下: 1. 数据预处理:处理缺失值、异常值,构造节假日特征等。 2. 模型训练:指定Prophet模型的超参数,如增长模型、季节性周期等。 3. 模型预测:将训练好的模型应用于未来30天的预测。 4. 结果评估:使用MAPE、RMSE等指标评估预测效果,必要时调整模型参数。
LSTM神经网络预测模型建立
近年来,基于深度学习的时间序列预测模型也受到广泛关注,如LSTM、TCN等。这类模型可以自动学习时间序列中的复杂模式,在处理非线性、高维特征方面表现出色。
一种典型的基于LSTM的时间序列预测模型如下:
输入层: LSTM层: 输出层:
其中, 和 分别是隐藏状态和细胞状态, 是输出函数。
神经网络模型的建模步骤包括: 1. 数据预处理:将时间序列数据转换为监督学习格式。 2. 模型设计:确定网络结构,如LSTM层的数量、隐藏单元数等超参数。 3. 模型训练:使用梯度下降法优化模型参数,最小化预测误差。 4. 模型评估:在验证集上评估模型性能,必要时调整模型结构和超参数。
基于图神经网络的预测模型建立
2024Mathorcup数学建模C题:由于分拣中心之间存在复杂的网络连接关系,我们还可以考虑引入图神经网络(GNN)来建模这种关系,以进一步提高预测的准确性。
(见文末完整版)
总之,针对问题1的货量预测,我们可以尝试ARIMA、Prophet、神经网络以及基于图神经网络的模型,并通过模型融合等方法进一步提高预测精度。在具体实现时,还需要关注数据预处理、模型选择与优化、结果评估等各个环节,以确保最终的预测结果满足业务需求。
问题3人员排班混合整数规划模型的建立与求解
决策变量的定义
目标函数
目标是在满足每个分拣中心每天的货量需求的前提下,最小化总的人员成本。由于正式工的人工成本低于临时工,我们可以设置不同的单位成本:
约束条件
(1) 满足每个分拣中心每天每个班次的货量需求: (见完整版)

通过求解上述优化模型,我们可以得到未来30天每个分拣中心每个班次的正式工和临时工的出勤人数,满足货量需求的同时尽量减少总的人员成本,并且保证每天的实际小时人效尽量均衡,同时满足正式工出勤率和连续出勤天数的要求。在求解过程中,我们需要引入一些松弛变量来处理一些约束条件,例如第4个约束条件 。同时,为了使得每天的实际小时人效更加均衡,我们也可以考虑在目标函数中加入一个关于实际小时人效差异的惩罚项。
此外,由于这是一个复杂的混合整数规划问题,在实际求解中需要采用一些启发式算法,如遗传算法、模拟退火算法等,来提高求解效率和解质量。这个人员排班优化问题涉及多个方面的因素,需要进行细致的建模和求解。通过以上的数学模型,我们可以为这个问题提供一个较为全面的解决方案。如有任何其他问题,欢迎继续交流。
混合整数规划问题的求解
我们将使用Python的scipy.optimize库来求解这个混合整数规划问题。
首先,我们定义所需的函数和参数:
问题4特定分拣中心排班计划模型的建立与求解
问题4要求研究特定分拣中心的排班问题,以分拣中心SC60为例。SC60当前有200名正式工,需要基于问题2的预测结果,确定未来30天每名正式工及临时工的班次出勤计划。具体要求如下:
-
每名正式工的出勤率不能高于85%,且连续出勤天数不能超过7天。
-
在每天货量处理完成的基础上,安排的人天数尽可能少,每天的实际小时人效尽量均衡。
-
正式工出勤率尽量均衡。
为了满足上述要求,我们需要建立一个优化模型来确定每名正式工及临时工的具体出勤计划。
问题4数学模型建立
决策变量定义
-
正式工每天每个班次的出勤状态:
-
每个班次需要雇佣的临时工人数:
目标函数
目标是在满足每天货量需求的前提下,最小化总的人员成本。由于正式工的人工成本低于临时工,我们可以设置不同的单位成本:
约束条件

问题4求解算法设计
由于问题4涉及0-1整数规划,求解起来较为复杂。我们可以采用以下算法步骤来求解这个优化问题:(见完整版)
该算法主要包括以下几个步骤:
-
初始化:读取输入数据并设置优化参数。
-
构建初始可行解:根据货量需求优先安排正式工出勤,不足部分使用临时工补充。
-
迭代优化:使用整数规划求解器求解优化模型,检查解是否满足约束条件,如果不满足则适度松弛约束条件后重复求解。
-
输出结果:输出最终的正式工出勤计划和临时工需求。
该算法的优势在于:
-
采用了整数规划模型,可以精确地描述问题的约束条件。
-
通过迭代优化的方式,可以逐步满足各项约束条件,得到最优解。
-
引入了一些松弛参数,可以在满足主要约束的前提下,适度调整次要约束条件,提高求解效率。
-
初始可行解的构建方法简单高效,为后续优化提供了良好的起点。
mathorcup C题完整论文和代码获取:https://docs.qq.com/doc/DZWN6RXlSTWVEcmZM
![[蓝桥杯] 岛屿个数(C语言)](https://img-blog.csdnimg.cn/direct/941e8f330b1a416d8204db1ff55a949e.png)