引言
今天带来一篇短小精悍的论文GLU Variants Improve Transformer笔记,作者提出了GLU1的一种变体。
GLU(Gated Linear Units,门控线性单元)由两个线性投影的逐元素乘积组成,其中一个首先经过sigmoid函数。GLU的变体是可能生效的,可以使用不同的非线性(甚至线性)函数来替代sigmoid。作者在Transformer序列到序列模型的前馈子层中测试了这些变体,并发现其中一些相对于通常使用的ReLU或GELU激活函数会带来质量改进。
总体介绍
Transformer序列到序列模型在多头注意力和位置感知前馈网络之间交替进行。FFN接受一个向量 x x x,并通过两个学习得到的线性变换进行传递。在两个线性变换之间应用了ReLU激活函数。
FFN ( x , W 1 , W 2 , b 1 , b 2 ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 (1) \text{FFN}(x,W_1,W_2,b_1,b_2) =\max(0,xW_1 +b_1)W_2 +b_2 \tag 1 FFN(x,W1,W2,b1,b2)=max(0,xW1+b1)W2+b2(1)
沿用T5 codebase的设定,作者使用无偏置的版本
FFN ( x , W 1 , W 2 ) = max ( 0 , x W 1 ) W 2 (2) \text{FFN}(x,W_1,W_2) =\max(0,xW_1 )W_2 \tag 2 FFN(x,W1,W2)=max(0,xW1)W2(2)
后续的研究提出了将ReLU替换为其他非线性激活函数,例如GELU(Gaussian Error Linear Units)2, GELU ( x ) = x Φ ( x ) \text{GELU}(x) = x\Phi(x) GELU(x)=xΦ(x)和 Swish β ( x ) = x σ ( β x ) \text{Swish}_β(x) = xσ(βx) Swishβ(x)=xσ(βx)3。
FFN GELU ( x , W 1 , W 2 ) = GELU ( x W 1 ) W 2 FFN Swish ( x , W 1 , W 2 ) = Swish 1 ( x W 1 ) W 2 (3) \text{FFN}_{\text{GELU}}(x,W_1,W_2) =\text{GELU}(xW_1 )W_2 \\ \text{FFN}_{\text{Swish}}(x,W_1,W_2) =\text{Swish}_1(xW_1 )W_2 \tag{3} FFNGELU(x,W1,W2)=GELU(xW1)W2FFNSwish(x,W1,W2)=Swish1(xW1)W2(3)
Swish 1 = x σ ( x ) \text{Swish}_1 = xσ(x) Swish1=xσ(x),即 β = 1 \beta=1 β=1。
GLU及其变体
Dauphin等人1引入了GLU,一种神经网络层,被定义为输入的两个线性变换的逐元素乘积,其中一个经过了sigmoid激活。其作者还建议省略激活函数,称之为双线性(bilinear)层:
GLU ( x , W , V , b , c ) = σ ( x W + b ) ⊗ ( x V + c ) Bilinear ( x , W , V , b , c ) = ( x W + b ) ⊗ ( x V + c ) (4) \begin{aligned} \text{GLU}(x,W,V,b,c) &= \sigma(xW+b) \otimes (xV +c) \\ \text{Bilinear}(x,W,V,b,c) &= (xW+b) \otimes (xV +c) \end{aligned} \tag 4 GLU(x,W,V,b,c)Bilinear(x,W,V,b,c)=σ(xW+b)⊗(xV+c)=(xW+b)⊗(xV+c)(4)
我们也可以使用其他激活函数来定义GLU的变体:
ReGLU ( x , W , V , b , c ) = max ( 0 , x W + b ) ⊗ ( x V + c ) GeGLU ( x , W , V , b , c ) = GELU ( x W + b ) ⊗ ( x V + c ) SwiGLU ( x , W , V , b , c ) = Swish β ( x W + b ) ⊗ ( x V + c ) (5) \begin{aligned} \text{ReGLU}(x,W,V,b,c) &= \max(0,xW+b) \otimes (xV +c) \\ \text{GeGLU}(x,W,V,b,c) &= \text{GELU}(xW+b) \otimes (xV +c) \\ \text{SwiGLU}(x,W,V,b,c) &= \text{Swish}_\beta(xW+b) \otimes (xV +c) \\ \end{aligned} \tag 5 ReGLU(x,W,V,b,c)GeGLU(x,W,V,b,c)SwiGLU(x,W,V,b,c)=max(0,xW+b)⊗(xV+c)=GELU(xW+b)⊗(xV+c)=Swishβ(xW+b)⊗(xV+c)(5)
这几个激活函数的图像如下所示:

在本篇工作中,作提出了对Transformer FFN层的额外变种,其中使用GLU或其变种代替第一个线性变换和激活函数。同样,省略了偏置项。
FFN GLU ( x , W , V , W 2 ) = ( σ ( x W ) ⊗ x V ) W 2 FFN Bilinear ( x , W , V , W 2 ) = ( x W ⊗ x V ) W 2 FFN ReGLU ( x , W , V , W 2 ) = ( max ( 0 , x W ) ⊗ x V ) W 2 FFN GEGLU ( x , W , V , W 2 ) = ( GELU ( x W ) ⊗ x V ) W 2 FFN SwiGLU ( x , W , V , W 2 ) = ( Swish 1 ( x W ) ⊗ x V ) W 2 (6) \begin{aligned} \text{FFN}_{\text{GLU}}(x,W,V,W_2) &= (\sigma(xW) \otimes xV)W_2 \\ \text{FFN}_{\text{Bilinear}}(x,W,V,W_2) &= (xW \otimes xV)W_2 \\ \text{FFN}_{\text{ReGLU}}(x,W,V,W_2) &= (\max(0,xW) \otimes xV)W_2 \\ \text{FFN}_{\text{GEGLU}}(x,W,V,W_2) &= (\text{GELU}(xW) \otimes xV)W_2 \\ \text{FFN}_{\text{SwiGLU}}(x,W,V,W_2) &= (\text{Swish}_1(xW) \otimes xV)W_2 \\ \end{aligned} \tag 6 FFNGLU(x,W,V,W2)FFNBilinear(x,W,V,W2)FFNReGLU(x,W,V,W2)FFNGEGLU(x,W,V,W2)FFNSwiGLU(x,W,V,W2)=(σ(xW)⊗xV)W2=(xW⊗xV)W2=(max(0,xW)⊗xV)W2=(GELU(xW)⊗xV)W2=(Swish1(xW)⊗xV)W2(6)
与原始的FFN层相比,所有这些层都有三个权重矩阵,而不是两个。为了保持参数量和计算量的恒定,当将这些层与原始的双矩阵版本进行比较时,作者将隐藏单元的数量 d f f d_{ff} dff( W W W和 V V V的第二个维度以及 W 2 2 W_22 W22的第一个维度)减少了 2 3 \frac{2}{3} 32。
实验
作者在T5的迁移学习设置上对所描述的FFN变种进行了测试。使用了一个编码器-解码器的Transformer模型,在预测缺失文本段的去噪目标上进行训练,并随后在各种语言理解任务上进行了微调。
模型架构
使用与T5的基准模型相同的代码库、模型架构和训练任务。编码器和解码器各由12个层组成, d m o d e l = 768 d_{model} = 768 dmodel=768。对于注意力层, h = 12 , d k = d v = 64 h = 12,d_k = d_v = 64 h=12,dk=dv=64。FFN层的隐藏大小为 d f f = 3072 d_{ff} = 3072 dff=3072。如上所述,对于基于GLU变种的FFN层,它们具有三个权重矩阵而不是两个,将隐藏层减少到 d f f = 2048 d_{ff} = 2048 dff=2048,以保持与基准模型相同的参数和操作数量。
预训练和困惑度
与T5完全一致,在C4数据集上使用填充跨度任务进行了524288步的预训练。每个训练批次包含128个示例,每个示例的输入为512个标记,输出为114个标记,输出中包含从输入中删除的多个标记跨度。
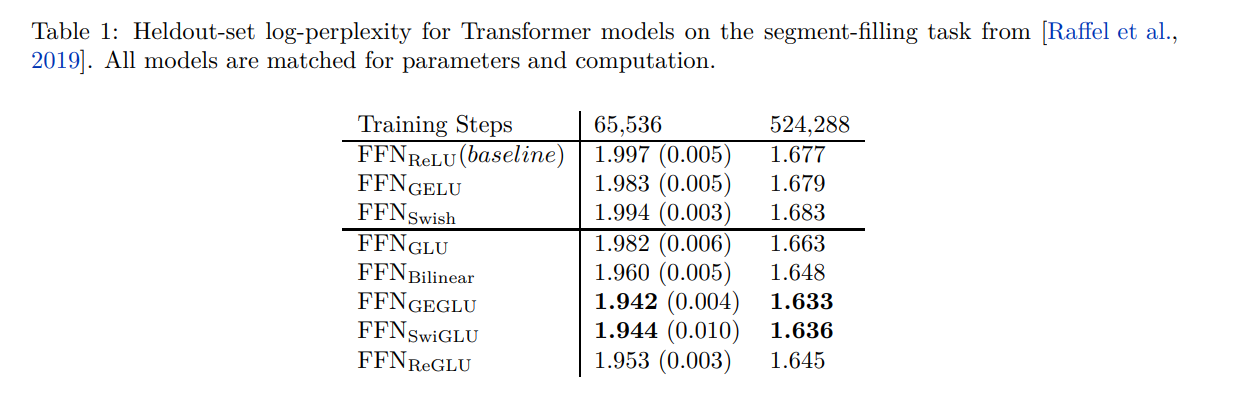
类似于T5,使用Adafactor优化器和反平方根学习率调度。还在线性方式下在训练最后10%的步骤中衰减学习率。与T5的主要不同之处在于,在预训练期间不使用dropout。作者发现这样可以产生更好的结果。使用C4数据集中的一个保留分片计算训练目标的对数困惑度,祖宗认为这是模型质量的一个很好的指标。对于每个模型架构,还训练了四个模型进行较短的时间65536步的训练,以衡量不同运行之间的可变性。结果列在表1中。GEGLU和SwiGLU变种产生了最佳的困惑度。
微调
然后,作者对每个完全训练的模型进行了一次微调,使用的是SQuAD和GLUE以及SuperGlue基准测试中的所有语言理解任务的例子按比例混合而成。微调共包含131072步,学习率为 1 0 − 3 10^{-3} 10−3。与训练过程类似,每一步的输入序列的总长度约为65536个标记。根据T5的建议,作者在层输出、前馈隐藏层和注意力权重上使用了0.1的dropout率。在微调期间,嵌入矩阵将被固定。
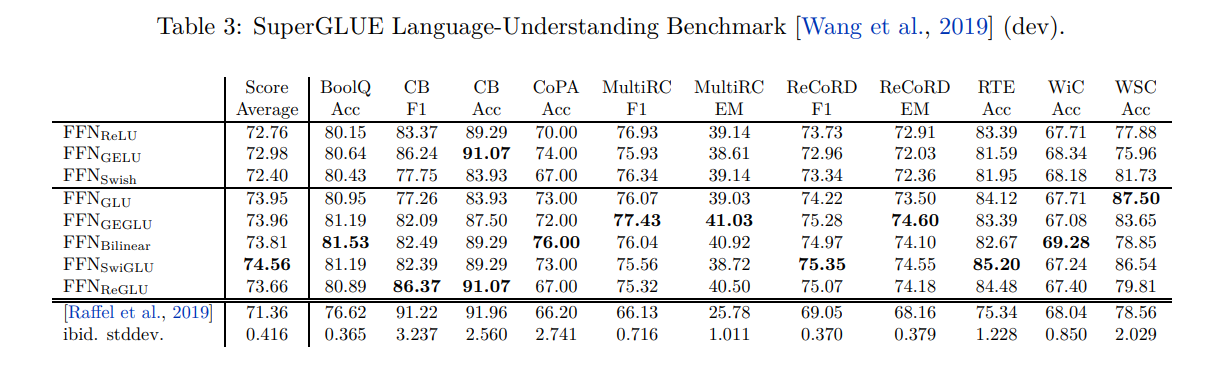
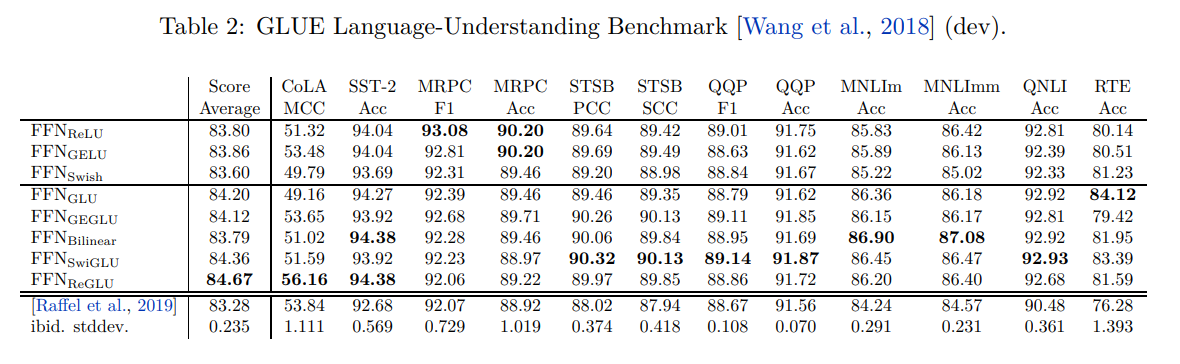
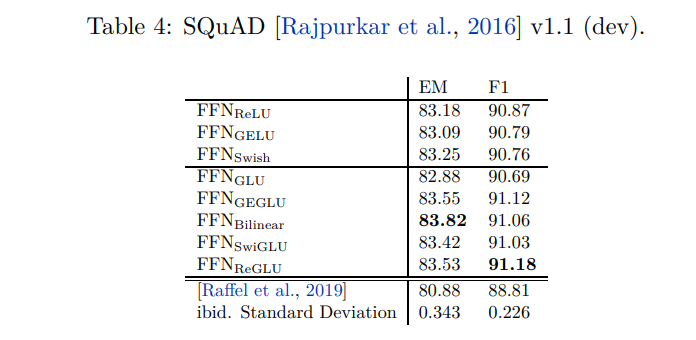
表2、表3和表4显示了在开发集上的结果。对于每个任务,作者报告了在微调过程中记录的任何检查点中的最佳得分。尽管结果有些噪音,但新的GLU变种在大多数任务上表现最佳。为了比较,在每个表的底部,作者列出了T5的结果。他们的模型与 FFN ReLU \text{FFN}_{\text{ReLU}} FFNReLU模型完全相同。值得注意的是,他们的结果明显较差,作者认为这是由于他们在预训练期间使用了dropout所导致的。还列出了由T5测量的运行间标准偏差。
结论
作者扩展了GLU家族并将它们应用于Transformer模型中。在迁移学习的设置中,新的变种似乎在预训练中用于去噪目标的困惑度上表现更好,并在许多下游语言理解任务上取得了更好的结果。
总结
⭐ 作者用流行的激活函数(Swish,GeLU和ReLU等)替换GLU中的激活函数,得到了一个困惑度比较好的GLU变体——SwiGLU,但作者也无法解释效果好的原因。
参考
GLU Variants Improve Transformer ↩︎ ↩︎
GAUSSIAN ERROR LINEAR UNITS (GELUS) ↩︎
SEARCHING FOR ACTIVATION FUNCTIONS ↩︎







![[lesson22]对象的销毁](https://img-blog.csdnimg.cn/direct/7d1b075e67ec44e68fb2404176dd9d2c.png#pic_center)