在之前的文章中,我们学习了三道任务,运用之前学到的方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(15)-CSDN博客文章浏览阅读1.5k次,点赞38次,收藏32次。今天开始的文章,我会带着大家来做三道任务,运用之前学到的方法,温故知新,举一反三,将知识紧紧掌握,cogroup两种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137658076之前的文章,我们都是在IDEA的非集群环境下进行的操作,但是,每一个学习spark的人都应该知道我们学习spark的目的都是为了最终能够完成分布式计算系统任务,它具有的大规模数据集上快速进行复杂分析和计算的能力让它在集群环境下保守欢迎。今天的文章,我会带着大家一起来到Linux集群环境下,学习我们的spark。
之前的文章中我们已经学习过如何搭建我们Linux中的spark集群环境,还不会的朋友可以查看这篇专栏。
大数据技术之Hadoop全生态组件学习与搭建![]() https://blog.csdn.net/qq_49513817/category_12599218.html
https://blog.csdn.net/qq_49513817/category_12599218.html
目录
一、知识回顾
二、外部文件读取并处理
启动集群
文件读取
一、知识回顾
在上一篇文章中,我们讲了三道任务题,分别是使用Spark完成单词去重,使用Spark统计133 136 139开头的总流量,完成统计相同字母组成的单词。
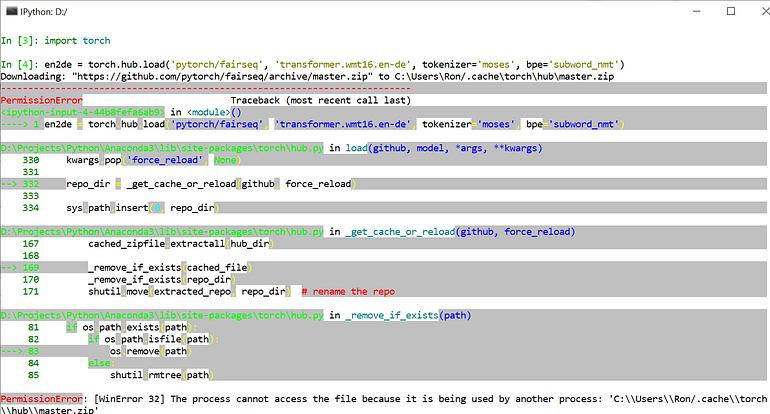
在单词去重中,我们主要使用了我们的distinct()方法进行去重操作
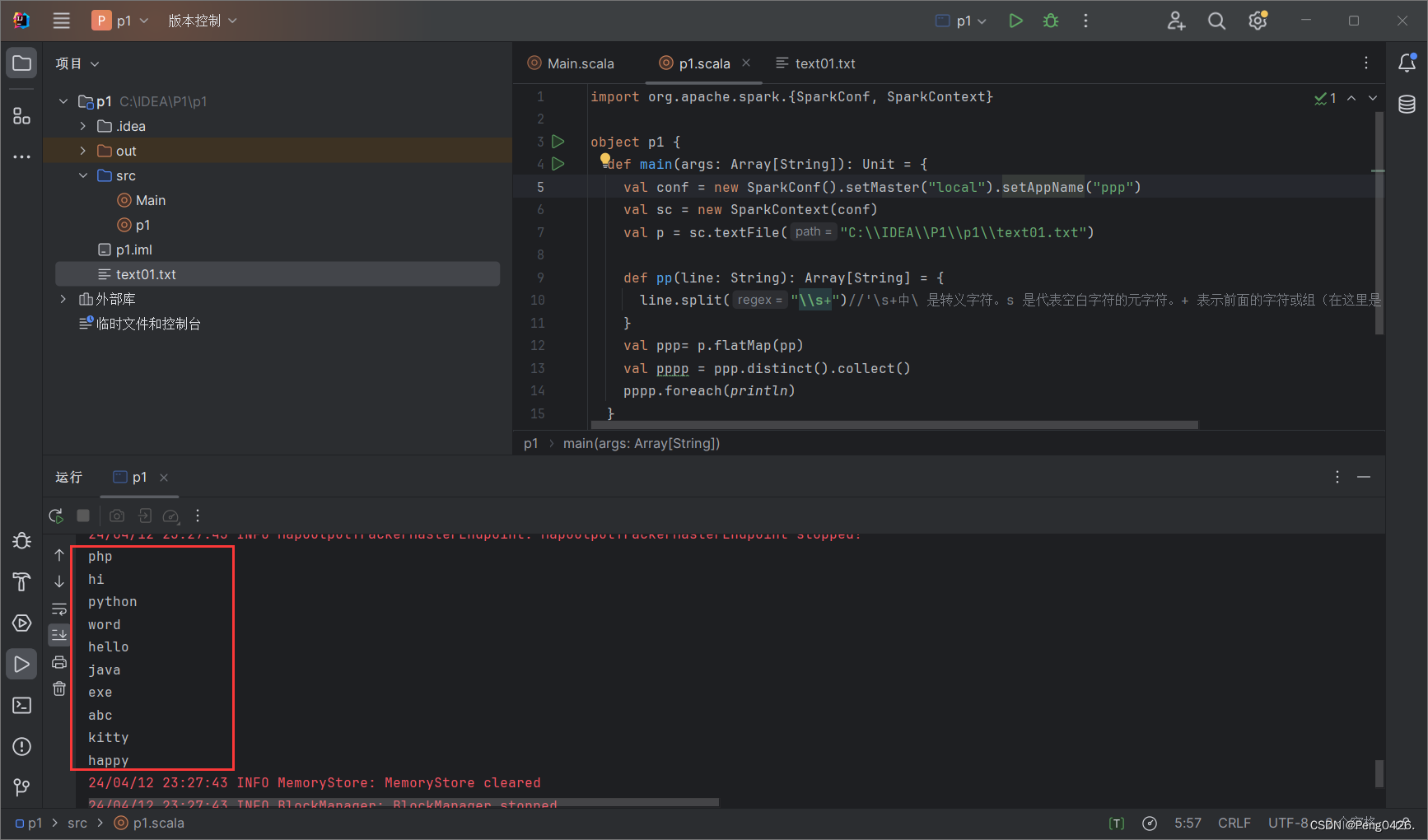
在统计流量中,我们首先使用了之前使用过的键值对方法将手机号与流量进行匹配,在使用map方法与groupByKey方法切分手机号前三位并分组,最后使用sum求和得出总流量。
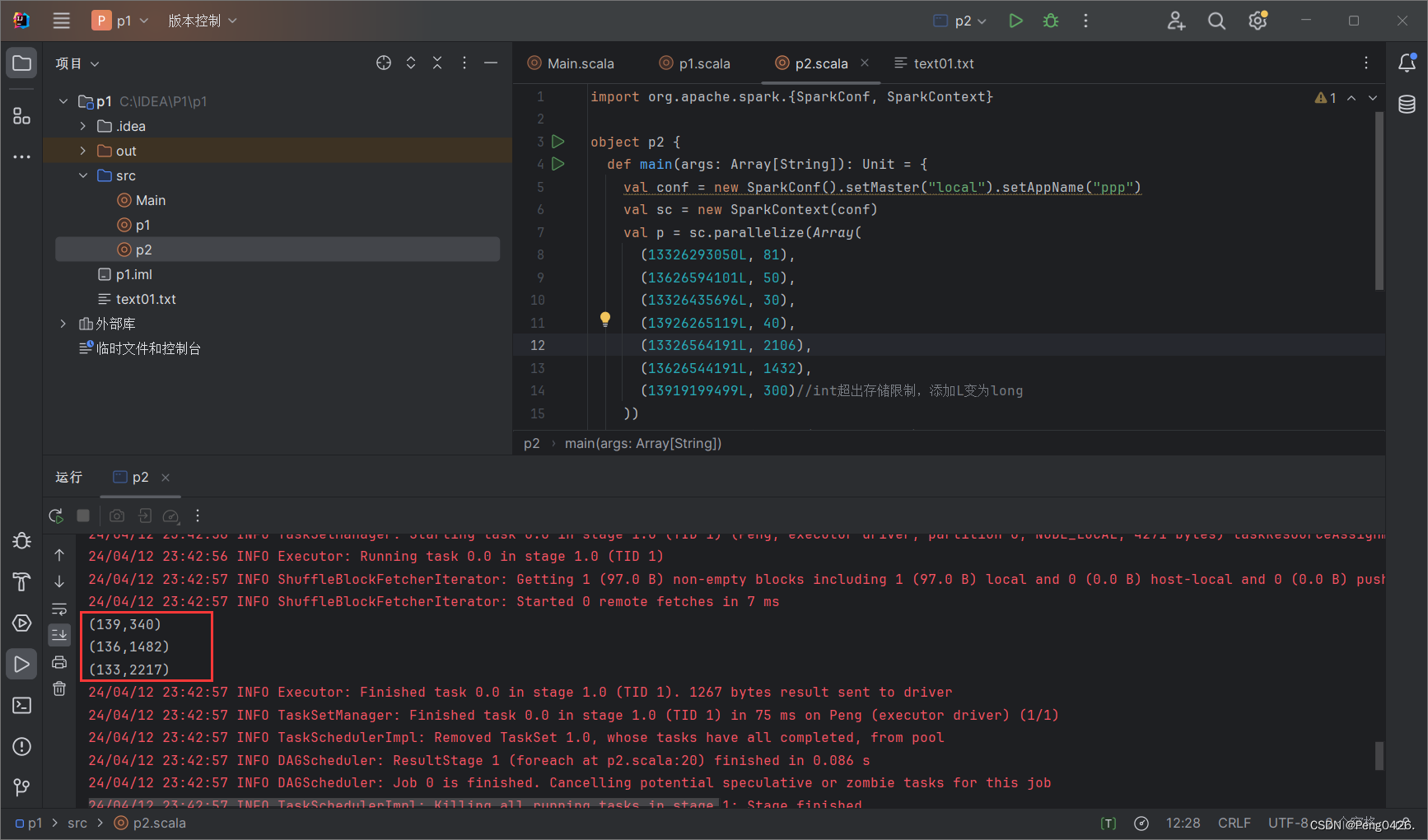
在统计单词中,我们显示切分了单词并进行排序,最后使用reduceByKey方法统计。
 现在,开始今天的学习吧~
现在,开始今天的学习吧~
二、外部文件读取并处理
启动集群
首先,我们肯定是要启动我们的集群环境。
systemctl stop firewalld.service
start-dfs.sh
start-yarn.shcd /opt/spark-3.2.1/sbin/./start-all.sh- systemctl stop firewalld.service的作用是关闭我们的防火墙,在进行绝大部分的集群操作时都需要用到它。
- start-dfs.sh的作用是启动我们Hadoop的分布式文件系统(HDFS)
- start-yarn.sh的作用是启动我们Hadoop的YARN组件
- cd /opt/spark-3.2.1/sbin/是切换到我们的spark下的sbin目录
./start-all.sh是启动我们Spark集群的所有服务
然后,我们需要启动我们的spark
cd /opt/spark-3.2.1/
./bin/spark-shell切换到我们的spark目录下,启动我们的spark
出现我们的spark图标与版本号,及成功。
文件读取
我们有一个名为testcsv的csv文件,它里面存贮了一些数据,那我们该如何读取呢?
首先你要知道文件存储的路径,我这里的路径是spark中自己创建的目录,你们创建时记得不要和原有目录名称冲突。
在读取我们的文件之前,你需要知道在IDEA中编写我们的spark与在集群环境下编写我们的spark语法是有一些小差异的。IDEA用于编写和调试代码,而Linux和Spark则用于运行和管理分布式计算任务。它们之间的协作使得我们能够在IDEA中高效地开发Spark应用程序,并在Linux操作系统上的Spark集群中执行这些应用程序。
现在开始我们的任务:
val p = sc.textFile("/opt/spark-3.2.1/P/testcsv.csv")
- val p = sc.textFile("/opt/spark-3.2.1/P/testcsv.csv"):读取我们的文件存贮到名为p的RDD中
val pp = p.map{ line =>| val ppp = new CSVReader(new StringReader(line));| ppp.readNext();}

- val pp = p.map{ line =>:使用
map操作对RDD中的每一行文本进行处理。map是一个转换操作,它会对RDD中的每个元素应用一个函数,并返回一个新的RDD,其中包含了应用函数后的结果。 - val ppp = new CSVReader(new StringReader(line)):对于RDD中的每一行
line,创建一个新的CSVReader实例来读取该行。 - ppp.readNext():使用
CSVReader的readNext方法来读取并解析CSV行的下一部分
pp.collect
- pp.collect:收集RDD数据,以数组返回
可以看到我们文件中的数据成功输出,任务完成