文章目录
- react query 学习笔记
- 查询客户端 QueryClient
- 获取查询客户端 useQueryClient
- 异步重新请求数据 queryClient.fetchQuery /
- 使查询失效 queryClient.invalidateQueries 与 重新请求数据queryClient.refetchQueries
- 查询 Queries
- useQuery查询配置对象
- 查询的键值 Query Keys
- 查询函数Query Functions
- 初始化的查询数据(查询数据占位符) initialData 与 placeholderData
- useQuery的返回值
- 分页查询 +keepPreviousData
- 修改 useMutation
- useMutation配置对象
- 场景:修改数据之后,需要刷新数据
- 乐观更新与状态回滚
- useMutation的返回值对象
- 触发mutationFn请求的属性mutate与mutateAsync
- 过滤器 Filters
- 查询过滤器 QueryFilters
react query 学习笔记
react query的一些概念理解
-
默认情况下,通过
useQuery或useInfiniteQuery生成的查询实例会将缓存的数据视为过时(stale)的。- 理解1:这里的数据都被称为缓存数据(都会被保存在内存中),只不过区分为新鲜(fresh)数据和过时(stale)数据,通过设置
staleTime来区分新鲜数据和过时数据。 - 理解2:新鲜数据与过时数据的作用是重新向后端发送请求时是否真的会请求后端。如果该查询的缓存状态是
stale(老旧),表示该查询将会有资格重新请求后端接口,但如果查询的缓存状态是fresh(最新)的,该查询不会请求后端接口直接采用缓存数据。 - 理解3:
useQuery或useInfiniteQuery返回的实例被称为查询实例
- 理解1:这里的数据都被称为缓存数据(都会被保存在内存中),只不过区分为新鲜(fresh)数据和过时(stale)数据,通过设置
-
出现以下情况时,过时的查询(缓存过时)会在后台自动重新获取数据
- ①挂载新的查询实例(很好理解创建一个新实例)。发生场景:当组件首次加载,将会触发数据的获取。如果组件被卸载后再次被加载,此时也会触发数据的重新获取。
- ②窗口重新聚焦。
- ③网络重新连接
- ④该查询可选地配置有重新获取数据的间隔
(refetch interval),设置定时刷新。 - 查询键被改变时,将会自动触发数据的重新获取。(
react-query会进行深度比对)
-
当查询结果不再具有
useQuery,useInfiniteQuery或查询观察者(query observers)的活动实例(active instances)时( 感觉意思是当前网页没有使用到的查询实例??),该查询结果将被标记为inactive(不活跃)。在缓存状态处于inactive状态或者使用这个查询数据的组件卸载时,超过5分钟(默认情况下)后,react-query将会自动清除该缓存。- 理解1:当在缓存中删除查询数据后,此时的表现和这个查询数据从未加载过一样。
- 理解2:缓存数据的第二对状态,
不活跃状态与活跃状态,这个状态影响的是react-query是否清除查询请求。(暂时不清楚清不清除有什么区分,猜测是否在开发调试工具中可以观测)
版本是
react query 5, 只记录工作中使用到的主要功能,在使用中会不断更新。
阅读文章:https://juejin.cn/post/7202945024748912699
react query文档:https://cangsdarm.github.io/react-query-web-i18n/react/
react query文档的简单翻译版:https://juejin.cn/post/7123119750523125796
查询客户端 QueryClient
作用:①管理缓存数据,
import { QueryClient } from '@tanstack/react-query'const queryClient = new QueryClient({defaultOptions: {queries: {staleTime: Infinity,},},
})
需要将查询客户端queryClient 提供给全局App
import {QueryClient,QueryClientProvider,
} from "@tanstack/react-query";// 创建一个 client
const queryClient = new QueryClient();function App() {return (// 提供 client 至 App<QueryClientProvider client={queryClient}><Todos /></QueryClientProvider>);
}获取查询客户端 useQueryClient
在项目的组件中,也可以调用queryClient,使用useQueryClient钩子,就可以获取全局的查询客户端queryClient。
import { useQueryClient } from '@tanstack/react-query'
const queryClient = useQueryClient();
queryClient对象的属性
| 用法 | 语法 | 描述 | 同步或者异步 | 返回值 |
|---|---|---|---|---|
| 获取缓存数据 | getQueryData(queryKey?: QueryKey,filters?: QueryFilters) | 获取现有查询的缓存数据,如果查询不存在,则返回undefined | 同步 | 缓存的数据 |
| 获取请求的状态 | getQueryState(queryKey?: QueryKey,filters?: QueryFilters) | 获取现有查询的状态,如果查询不存在,则返回undefined | 同步 | 状态对象dataUpdatedAt: number属性:查询最近一次返回status为"success"的时间戳 |
异步重新请求数据 queryClient.fetchQuery /
queryClient.fetchQuery({uery Keys,Query Function,other}):异步请求数据,类似useQuery,可用于提取和缓存查询。
在特殊场景下(如:强制触发查询等)可以使用queryClient.fetchQuery()请求数据。
如果在缓存中有对应的数据(通过查询键匹配)且未过期,可以无需请求直接使用缓存数据。
如果没有缓存或缓存已经过期,那么react-query会重新请求并且缓存数据。
使查询失效 queryClient.invalidateQueries 与 重新请求数据queryClient.refetchQueries
使查询失效 queryClient.invalidateQueries
queryClient.invalidateQueries(filters?: QueryFilters查询筛选器,options?: RefetchOptions):该方法使匹配到的查询失效。默认情况下,所有匹配的查询都会立即标记为无效,并且活动查询将在后台重新提取。
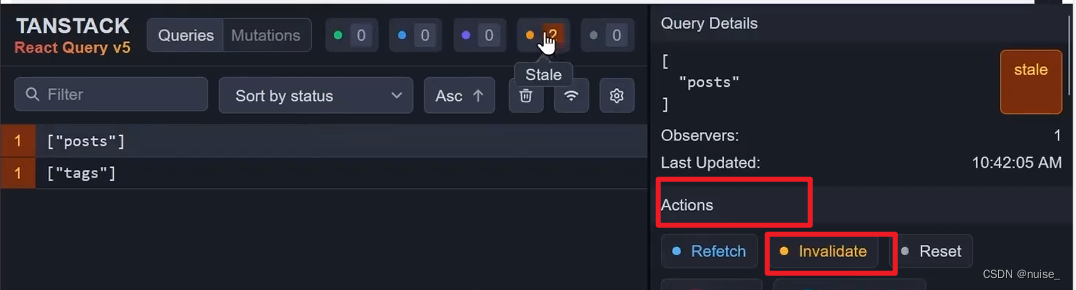
refetchType:active 默认值,活动查询重新提取
refetchType: 'none' 不会重新提取任何查询,仅将匹配查询标记为无效。
refetchType: 'all' 活动查询与非活动查询都会重新提取。
await queryClient.invalidateQueries({queryKey: ['posts'],exact, // 关闭模糊查询//refetchType?: 'active' | 'inactive' | 'all' | 'none'refetchType: 'active', },{ throwOnError, cancelRefetch },
)
predicate()函数可以进行更细力度的匹配, 此函数将从查询缓存中接收每个Query 实例,并允许你返回 true 或 false 来确定是否使该查询无效。
// 比如这个invalidateQueries,精确到参数version>10的请求
queryClient.invalidateQueries({predicate: (query) =>query.queryKey[0] === 'todos' && query.queryKey[1]?.version >= 10,
})// 这个请求会被设置为过期
const todoListQuery = useQuery({queryKey: ['todos', { version: 20 }],queryFn: fetchTodoList,
})// 这个请求会被设置为过期
const todoListQuery = useQuery({queryKey: ['todos', { version: 10 }],queryFn: fetchTodoList,
})// 这个请求不会
const todoListQuery = useQuery({queryKey: ['todos', { version: 5 }],queryFn: fetchTodoList,
})
重新请求数据queryClient.refetchQueries
queryClient.refetchQueries(filters?: QueryFilters查询筛选器,options?: RefetchOptions):所有匹配(默认非活动和活动)的查询请求(查询键值是模糊匹配)都重新请求。
// refetch all queries:await queryClient.refetchQueries()// refetch all stale queries:await queryClient.refetchQueries({ stale: true })// refetch all active queries partially matching a query key:await queryClient.refetchQueries({ queryKey: ['posts'], type: 'active' })// refetch all active queries exactly matching a query key:await queryClient.refetchQueries({queryKey: ['posts', 1],type: 'active',exact: true,})
两者的区别
invalidateQueries只是将数据标记为过时,以便它们在下次观察者挂载时重新获取,refetchQueries会立刻重新获取数据,即使没有观察者也可以。对于具有活动观察者的查询,没有区别。invalidateQueries有更细腻灵活的配置,可以精确到某些请求
查询 Queries
ReactQuery 会在全局维护一个服务端状态树,根据 Query key 去查找状态树中是否有可用的数据,如果有则直接返回,否则则会发起请求,并将请求结果以 Query key 为主键存储到状态树中。
订阅一个查询useQuery({配置对象}),通常包含两个参数:
- 唯一标识这个请求的
Query key:ReactQuery的缓存策略是基于这个key来实现的,key变化缓存失效,请求重新发送。 - 一个真正执行请求并返回数据的异步方法
查询的三个钩子
useQuery:发起单个请求useQueries:发起多个请求useInfiniteQuery:无限查询
const {data,dataUpdatedAt,error,errorUpdatedAt,failureCount,failureReason,fetchStatus,isError,isFetched,isFetchedAfterMount,isFetching,isInitialLoading,isLoading,isLoadingError,isPaused,isPending,isPlaceholderData,isRefetchError,isRefetching,isStale,isSuccess,refetch,status,
} = useQuery({queryKey,queryFn,gcTime,enabled,networkMode,initialData,initialDataUpdatedAt,meta,notifyOnChangeProps,placeholderData,queryKeyHashFn,refetchInterval,refetchIntervalInBackground,refetchOnMount,refetchOnReconnect,refetchOnWindowFocus,retry,retryOnMount,retryDelay,select,staleTime,structuralSharing,throwOnError,},queryClient,
)
useQuery查询配置对象
| 键 | 描述 |
|---|---|
| queryKey | 查询请求的key |
| queryFn | 查询请求的请求函数 |
| enabled: boolean | 查询是否自动运行,是否可用,为false不会发起请求。可以控制查询请求运行的时机(比如请求参数不为空时才发送查询请求 param!==null) 也可以使用 useQuery返回的refetch触发 |
| staleTime: number | Infinit | 数据缓存的时长,单位是毫秒,默认为0。在时间范围内,再次发送请求时,直接使用缓存数据。 |
查询的键值 Query Keys
语法:queryKey:数组 要求数组可序列化,并且数组唯一。
作用:React Query 在内部基于查询键值来管理查询缓存,可以理解为依赖,如果依赖变化那么会重新发送查询请求。
import { useQuery} from "@tanstack/react-query";function Todos({ todoId }) {{const result = useQuery({queryKey: ['todos', todoId],queryFn: () => fetchTodoById(todoId),});
}
案例1:查询键值序列化后,相同的会被去重。数组项的顺序影响序列化后的值,对象的key的顺序不影响序列化后的值。
// 不管对象中键值的顺序如何,以下所有查询都被认为是相等的:
useQuery({ queryKey: ['todos', { status, page }], ... });
useQuery({ queryKey: ['todos', { page, status }], ...});
useQuery({ queryKey: ['todos', { page, status, other: undefined }], ... });//以下查询键值不相等
useQuery({ queryKey: ['todos', status, page], ... });
useQuery({ queryKey: ['todos', page, status], ...});
useQuery({ queryKey: ['todos', undefined, page, status], ...});
案例2:如果你的查询功能依赖于变量,则将其包含在查询键值中
function Todos({ todoId }) {{const result = useQuery({queryKey: ['todos', todoId],queryFn: () => fetchTodoById(todoId),});
}
查询函数Query Functions
查询函数的参数
每一个查询函数的参数都是QueryFunctionContext对象,该对象中包含
queryKey: QueryKey: 查询键值pageParam: unknown | undefined:只会在无限查询场景传递,为查询当前页所使用的参数signal?: AbortSignal:可以用来做查询取消meta?: Record<string, unknown>:一个可选字段,可以填写任意关于该查询的额外信息
function Todos({ status, page }) {const result = useQuery({queryKey: ["todos", { status, page }],queryFn: fetchTodoList,});
}// 在查询函数中访问键值,状态和页面变量!
function fetchTodoList({ queryKey }) {const [_key, { status, page }] = queryKey;return new Promise();
}
查询函数的返回值
查询函数要求是返回Promise的函数(异步同步都可以),其该Promise最终状态会变成resolved或rejected。
初始化的查询数据(查询数据占位符) initialData 与 placeholderData
使用场景:在应用的其他地方已经获取到了查询的初始数据或者自定义一个初始数据
| 属性 | 保留在缓存 | 描述 |
|---|---|---|
initialData | √ 保留在缓存中,因此不建议为此选项提供占位符,部分或不完整的数据 | 初始化数据,一般用于已经有完整的数据但是不确定数据是否已经变更的场景 initialData 受staleTime影响,如果初始化数据没过时,就会一直使用初始化数据, 否则重新发起请求 |
placeholderData | × 数据没有被持久化到缓存中,更倾向于预览的作用 | 在还未第一次请求到数据之前的这段时间,如果获取该查询的data,则会获取到placeholderData属性的值 一旦查询从后端获取到了数据,则placeholderData属性失效 |
placeholderData理解与使用
1.placeholderData类似于解构,如果解构项的值为undefined,将会采用设置的默认值
{
const issuesQuery = useQuery(queryKey:["issues"], queryFn:fetch,placeholderData: [],}
)
const { data = [] } = useQuery({queryKey:["issues"], queryFn:fetch,}
)
2.当需要为用户提供假数据时,就可以使用placeholderData,比如在获取用户数据时,为了UI不那么难看,可以先默认展示一个占位头像。
3.如某个依赖查询,依赖了该数据需要使用isPlaceholderData属性来判断当前数据是否真实.
// 请求1
const userQuery = useQuery({queryKey:["user"],queryFn:fetchUser,}
)
// 依赖请求1返回值的请求2
const userIssues = useQuery({queryKey:["userIssues", userQuery.data.login],queryFn:fetchUserIssues,enabled: !userQuery.isPlaceholderData && userQuery.data?.login,}
)
initialData理解与使用
1.使用案例
// 将立即显示 initialTodos,但在挂载后也将立即重新获取todos, initialData立即过期
const result = useQuery({queryKey: ["todos"],queryFn: () => fetch("/todos"),initialData: initialTodos,
});// 使用之前的缓存信息:将 `todos` 查询中的某个 todo 用作此 todos 查询的初始数据
const result = useQuery({queryKey: ["todo", todoId],queryFn: () => fetch("/todos"),initialData: () => { return queryClient.getQueryData(["todos"])?.find((d) => d.id === todoId);},
});
2.精准控制过期时间,过期时间 = initialDataUpdatedAt + staleTime
initialDataUpdatedAt:表示初始数据上一次更新的时间,可以与getQueryState钩子函数、staleTime配置属性精准控制initialData过期时间。
initialDataUpdatedAt类型为Number类型的 JS 时间戳(以毫秒为单位,如Date.now())
const issueDetailQuery = useQuery({queryKey:["issue", repo, owner, issueNumber],queryFn:fetchIssue,staleTime: 1000 * 60,initialData: () => { // 初始数据的过期时间为getQueryData上一次刷新的时间+staleTime的时间const issues = queryClient.getQueryData(["issues", repo, owner])if (!issues) return undefined;const issue = issues.find(issue => issue.number === issueNumber)return issue;}, initialDataUpdatedAt: () => { // 初始数据issue最后一次新时间dataUpdatedAtconst {dataUpdatedAt} = queryClient.getQueryState(["issues", repo, owner])return dataUpdatedAt;}},
)
useQuery的返回值
useQuery返回值为包含所有关于该查询信息的对象
status告诉我们有关data的状态:有或者没有?
status:查询的状态,有正在加载、失败、成功三个状态isLoading或者status === 'loading':查询暂时还没有数据isError或者status === 'error':查询出错isSuccess或者status === 'success'查询成功,并且数据可用
以下两个状态是获取查询函数queryFn的返回值(Promise的返回值而不是一个新的Promise)
error:如果查询处于isError状态,则可以通过error属性获取该错误data:如果查询处于isSuccess状态,则可以通过data属性获得数据
fetchStatus告诉我们有关queryFn的状态:在执行还是没在执行?
fetchStatus === 'fetching'正在查询中fetchStatus === 'paused'查询想要获取,但它被暂停了fetchStatus === 'idle'该查询处于闲置状态
为什么需要两个键来表示对象?
后台刷新和数据过期重试可以让一个请求处于多种情况。
一个state='success'的查询通常处于fetchStatus='idle'状态。但如果同时后台重新获取动作,该查询也可能为fetchStatus='fetching'状态。
一个没有数据的查询通常处于status='loading'状态和fetchStatus='loading'状态。如果同时无网络连接,该请求也可能为fetchStatus='paused'状态。
分页查询 +keepPreviousData
将分页的信息作为queryKey,当页数发生变化时会自动重新请求新数据。
存在问题:UI 在success和loading状态之间来回跳转,因为每个新页面都被视为一个全新的查询。(感觉这样体现也正常?不是很理解,翻页不就是需要重新请求新数据吗?可能希望已经请求过的页数不在loading重新请求?)
const result = useQuery({queryKey: ["projects", page],queryFn: fetchProjects,
});
keepPreviousData:true的作用
1.请求新数据时,即使查询键值已更改,上次成功获取的数据仍可用
2.当新数据到达时,先前的数据将被无缝交换以显示新数据
3.可以使用isPreviousData来了解当前查询提供的是什么数据
function Todos() {const [page, setPage] = React.useState(0);const fetchProjects = (page = 0) =>fetch("/api/projects?page=" + page).then((res) => res.json());const { isLoading, isError, error, data, isFetching, isPreviousData } =useQuery({queryKey: ["projects", page],queryFn: () => fetchProjects(page),keepPreviousData: true,});return (<div>{isLoading ? (<div>Loading...</div>) : isError ? (<div>Error: {error.message}</div>) : (<div>{data.projects.map((project) => (<p key={project.id}>{project.name}</p>))}</div>)}<span>Current Page: {page + 1}</span><buttononClick={() => setPage((old) => Math.max(old - 1, 0))}disabled={page === 0}>Previous Page</button>{" "}<buttononClick={() => {if (!isPreviousData && data.hasMore) {setPage((old) => old + 1);}}}// 禁用跳转下一页的按钮,直到我们知道下一页数据是可用的disabled={isPreviousData || !data?.hasMore}>Next Page</button>{isFetching ? <span> Loading...</span> : null}{" "}</div>);
}
修改 useMutation
说明:react-query中使用useMutation向后端发送创建/更新/删除操作
mutationFn的调用时机:useMutation钩子不会在组件加载时就直接请求,需要手动调用mutate方法并传入请求参数才会生效。
const {data,error,isError,isIdle,isPending,isPaused,isSuccess,failureCount,failureReason,mutate,mutateAsync,reset,status,submittedAt,variables,
} = useMutation({mutationFn,gcTime,mutationKey,networkMode,onError,onMutate,onSettled,onSuccess,retry,retryDelay,throwOnError,meta,
})
使用案例:添加一个新todo
function App() {const mutation = useMutation({mutationFn: (newTodo) => {return axios.post("/todos", newTodo);},});return (<div>{mutation.isLoading ? ("Adding todo...") : (<>{mutation.isError ? (<div>An error occurred: {mutation.error.message}</div>) : null}{mutation.isSuccess ? <div>Todo added!</div> : null}<buttononClick={() => {mutation.mutate({ id: new Date(), title: "Do Laundry" });}}>Create Todo</button></>)}</div>);
}
useMutation配置对象
| 属性 | 描述 |
|---|---|
| mutationFn: (variables: TVariables) => Promise | 必选:执行异步任务并返回承诺的函数,参数variables是一个mutate传递给mutationFn的对象 |
| onSuccess: (data: TData, variables: TVariables, context: TContext) => Promise<unknown> | unknown | 第一个参数是mutationFn函数的返回值,第二个参数是mutate函数传递的参数 |
| onError: (err: TError, variables: TVariables, context?: TContext) => Promise<0unknown> | unknown | 失败的回调函数 |
| onSettled: (data: TData, error: TError, variables: TVariables, context?: TContext) => Promise<unknown> | unknown | 不管请求成功还是失败都会执行 |
| reset: () => void | 将突变重置为初始状态 |
场景:修改数据之后,需要刷新数据
在很多场景中,我们希望一个数据修改成功后,涉及该数据的相关查询都重新获取最新的数据
案例1
当对postTodo的修改成功时,我们可能希望对所有的todos查询都暂时失效,然后重新获取以显示新的 todo 项。
import { useMutation, useQueryClient } from "@tanstack/react-query";const queryClient = useQueryClient();// 当此修改成功时,将所有带有`todos`和`reminders`查询键值的查询都无效
const mutation = useMutation({mutationFn: addTodo,onSuccess: () => {queryClient.invalidateQueries({ queryKey: ["todos"] });},
});
乐观更新与状态回滚
在执行修改之前,当你"乐观"地打算进行更新时,修改有可能失败(可能性非零)。
①大多数情况下,让查询触发重新获取,使其恢复到真正的和服务器一致的状态。
②还有一种方式,是进行状态回滚
useMutation 的 onMutate 回调允许返回一个特定值,该值将作为最后一个参数传递给 onError 和 onSettled 处理 – 在大多数情况下,以这种方式来传递一个回滚函数是最有用的。
onMutate: (variables: TVariables) => Promise<TContext | void> | TContext | void :将在触发突变函数之前触发,同时也会接受传递给突变函数的参数
案例:添加新的todo时更新todos列表
const queryClient = useQueryClient();useMutation({mutationFn: updateTodo,// 当 mutate 调用时onMutate: async (newTodo) => {// 撤销相关的查询(这样它们就不会覆盖我们的乐观更新)await queryClient.cancelQueries(["todos"]);// 保存前一次状态的快照const previousTodos = queryClient.getQueryData(["todos"]);// 执行"乐观"更新queryClient.setQueryData(["todos"], (old) => [...old, newTodo]);// 返回具有快照值的上下文对象return { previousTodos };},// 如果修改失败,则使用 onMutate 返回的上下文进行回滚onError: (err, newTodo, context) => {queryClient.setQueryData(["todos"], context.previousTodos);},// 总是在错误或成功之后重新获取:onSettled: () => {queryClient.invalidateQueries("todos");},
});
useMutation的返回值对象
触发mutationFn请求的属性mutate与mutateAsync
useMutation返回值对象.mutate:同步触发useMutation返回值对象.mutateAsync:异步触发
mutate(variables, {onError,onSettled,onSuccess,
})
过滤器 Filters
某些方法可以接受查询过滤QueryFilters 或者修改过滤 MutationFilters 对象。
// 取消所有查询
await queryClient.cancelQueries();// 删除所有以`posts`开头的键值的非活跃的查询
queryClient.removeQueries({ queryKey: ["posts"], type: "inactive" });// 重新获取所有活跃的查询
await queryClient.refetchQueries({ type: 'active' })// 重新获取键中以`posts`开头的所有活跃的查询
await queryClient.refetchQueries({ queryKey: ['posts'], type: 'active' })
查询过滤器 QueryFilters
| 属性名 | 描述 |
|---|---|
| queryKey?: QueryKey | 设置此属性以定义要匹配的查询键值,默认匹配的规则是以queryKey开头的查询(模糊查询)。 |
| exact?: boolean | 是否关闭模糊查询,默认是false |
| type?: ‘active’ | ‘inactive’ | ‘all’ | 默认为allactive表示匹配活跃查询inactive表示匹配非活跃的查询 |
| stale?: boolean | true表示当前过时(staled)的false表示匹配当前没过时(fresh)的 |
| fetchStatus?: FetchStatus | fetching 匹配当前正在获取的paused匹配当前想要获取但被暂停了的idle配当前未在获取的 |