递归其实在压测场景用的不多,但是批量造数据或批量导出,用的比较多,常见的压测登陆,首先你要有登陆账号的csv,这个时候自己可以实现一个批量获取账号的py就很惬意。
编辑器 VScode
VSCode 全称 Visual Studio Code,是微软出的一款轻量级代码编辑器,免费、开源而且功能强大。
这次主要是写一个批量导出账号的示例
请求方式: GET;
参数: pageNo和pageSize;
最终产出2个文件
- index.py: 执行文件
- accounts.csv: 导出获取的所有账号
项目依赖库
# 用于http请求
pip install requests
Python和Pip版本
pip 23.2.1
Python 3.11.7
新建index.py文件-开始编码
1.请求url;请求参数;自定义头部
# 请求地址
url = 'https:xxx.cn/api/account/page'
# 请求参数
params = {'pageNo': 0,'pageSize': 0,
}
# 自定义头部
headers = {"Content-Type": "application/json;charset=utf-8",
}
2.递归请求函数
import requests# 导出账号批量拼接
accAllList = []
# 递归请求方法
def account_batches(pageNo, pageSize) {# 声明全局变量: 把定义的url,参数,自定义头部放进来global url, params, headers# 动态修改参数params['pageNo'] = pageNoparams['pageSize'] = pageSize# 使用requests库# 使用global声明的全局变量:url,params,headersresponse = requests.get(url, params=params, headers=headers)if response.status_code == 200:# 把返回结果进行处理result = response.json()# 取到对讲账号列表accList = result['data']['list']# 如果账号列表是空的代表请求完毕退出循环if len(accList) == 0:print(f"请求完毕导出中")# 导出exportAccounts()return# 合并数组accAllList.extend(accList)# 页码加1,继续递归获取账号return account_batches(pageNo+1, pageSize)else:print(f"第 {pageNo} 页账号拉取失败")
}
# 执行递归函数批量请求;从第1页开始,每页请求5000条
account_batches(1, 5000)
3.导出
# 导出用到了csv依赖需要在头部导入
import csv# accAllList内部数据格式 => [{account: 'yyh', '前端进阶者', id: 1}]
def exportAccounts():new_array = [[d['account'], d['name'], d['id']] for d in accAllList]# new_array处理后 => [['yyh', '前端进阶者', 1]]# 打开accounts.csv,'mode=w'不存在就创建并覆盖'newline'换行符;'utf-8'编码格式;with open('accounts.csv', mode='w', newline='', encoding='utf-8') as file:writer = csv.writer(file) for account in new_array:writer.writerow(account)
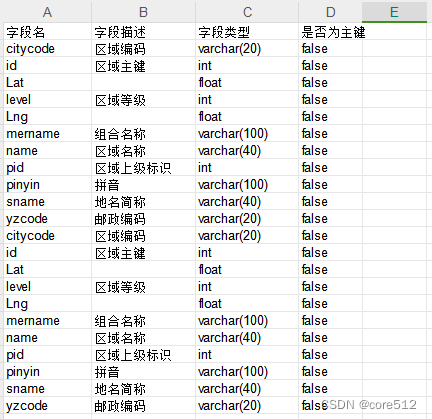
4.导出后的accounts.csv依次是: 账号; 名称; 账号id
yyh,前端进阶者,1
yyh1,前端进阶者1,2
合并所有片段
# 1.用到的依赖
import csv
import requests# 2.请求url;请求参数;自定义头部
# 请求地址
url = 'https:xxx.cn/api/account/page'
# 请求参数
params = {'pageNo': 0,'pageSize': 0,
}
# 自定义头部
headers = {"Content-Type": "application/json;charset=utf-8",
}
# 3.递归请求函数
# 导出账号批量拼接
accAllList = []
# 递归请求方法
def account_batches(pageNo, pageSize) {# 声明全局变量: 把定义的url,参数,自定义头部放进来global url, params, headers# 动态修改参数params['pageNo'] = pageNoparams['pageSize'] = pageSize# 使用requests库# 使用global声明的全局变量:url,params,headersresponse = requests.get(url, params=params, headers=headers)if response.status_code == 200:# 把返回结果进行处理result = response.json()# 取到对讲账号列表accList = result['data']['list']# 如果账号列表是空的代表请求完毕退出循环if len(accList) == 0:print(f"请求完毕导出中")# 导出exportAccounts()return# 合并数组accAllList.extend(accList)# 递归执行return account_batches(pageNo+1, pageSize)else:print(f"第 {pageNo} 页账号拉取失败")
}# 4.导出csv方法
def exportAccounts():new_array = [[d['account'], d['name'], d['id']] for d in accAllList]with open('accounts.csv', mode='w', newline='', encoding='utf-8') as file:writer = csv.writer(file) for account in new_array:writer.writerow(account)
# 5.执行递归函数批量请求;从第1页开始,每页请求5000条
account_batches(1, 5000)
执行
- vsCode右键文件选择在集成终端中打开
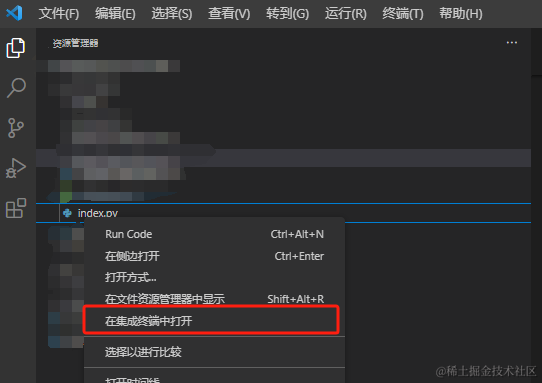
- 在终端输入: python index.py