目录
字符的截取
substr()
trim()、ltrim()、rtrim()
字符串的拼接
||、+
字符的大小写转换
upper('column_name'):大写
lower('column_name'):小写
字符替换
replace()
搜索字符
instr(column_name, 'substring_to_find',start,n_appearence)
charindex('substring_to_find', column_name[,START])
通配符
小例子
rowid
字符的截取
substr()
在 sqlserver 中是 substring,不过参数一样,但是不能缺少长度,也就不会默认到末尾
select substr('str',start[,length]) from xx从 start 开始,截取长度为 lenth 的字符,其中空格长度为1
trim()、ltrim()、rtrim()
SELECT TRIM([ '目标str' from] '源str') FROM xx从源 str 两边、左边、右边开始截取目标 str,缺省目标字符串时截取空格

字符串的拼接
||、+
oracle 中可连接多个字符串,SqlServer 里可以用 + 进行连接

(SqlServer)
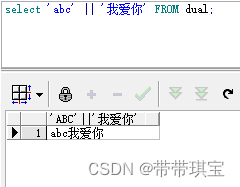
(Oracle)
除此之外,Oracle 也可用 concat ('str1','str2') 函数拼接,这种方法只能拼接两个字符串
字符的大小写转换
upper('column_name'):大写
lower('column_name'):小写
select * FROM emp;
select lower(job) FROM emp; 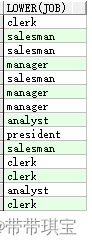
字符替换
replace()
将源字符串中的某些字符替换,格式:
select replace('string_expression', string_pattern, string_replacement) from xxx- string_expression:要进行替换的字符串,如某一列或某个字串
- string_pattern:要被替换的 string
- string_replacement:所进行替换的 string
搜索字符
instr(column_name, 'substring_to_find',start,n_appearence)
- column_name:列名,可以为字符串
- substring_to_find:需要搜索的字符串
- start:搜索的起始位置
- n_appearence:第n次出现
select instr('abc-def-abc-xyz','-'),instr('abc-def-abc-xyz','-',5),instr('abc-def-abc-xyz','-',5,2),instr('abc-def-abc-xyz','-',-1)
from dual;
该函数是在 Oracle 中可以使用的

比如:第三列 str 中第五位开始查找字符 '-' 第 2 次出现的位置,未找到将返回0,第一个字符下标记为1
charindex('substring_to_find', column_name[,START])
SqlServer 中可用该方法实现同样效果,但其参数位置不同,且没法限定目标字符出现的次数,最多也只有三个参数
通配符
是与 LIKE 一起使用进行模糊搜索字符的符号
%、_:匹配多个或一个字符
SELECT * FROM EMP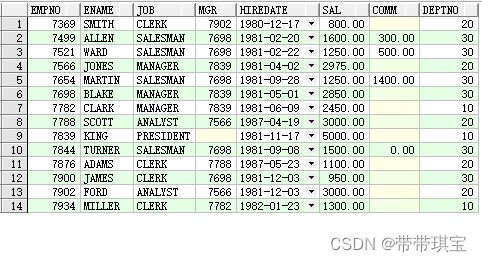
SELECT * FROM EMP WHERE JOB LIKE 'M%' [escape 特殊字符]
--注意字符的小写 
后面的 escape:
- 用法一:当字符串本身含有 % 或 _ 时,避免其当做通配符
- 用法二:当需要剔除某字符(如每个数据都有*号,直接匹配会每个数据都返回),那我可以escape '*' 忽略掉这个字符
此外,对字符串出现 % 或 _ 也可以用反斜杠 \ 对其忽略
小例子
对 oracle 中自带的 EMP 表进行字符处理
SELECT emp.*,rowid FROM EMP;

摘出需要进行替换的字母
SELECT emp.*,substr(rowid,-5) FROM EMP;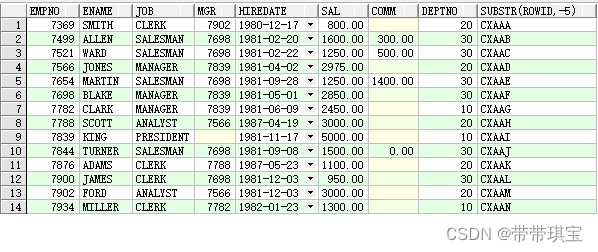
进行替换
SELECT emp.*,replace(rowid,substr(rowid,-5),'*****') FROM EMP;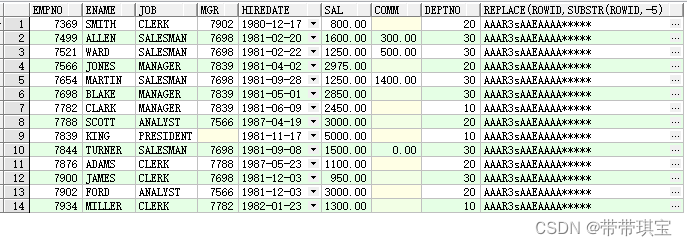
rowid
这个 rowid 是在 oracle 中记录每一行数据在插入数据库时分配的物理地址(是唯一的字符串)