- 在对比学习领域,最近很多研究利用高质量生成模型来提升对比学习
- 给定一个未标记的数据集,在其上训练一个生成模型来生成大量的合成样本,然后在真实数据和生成数据的组合上执行对比学习
- 这种使用生成数据的最简单方式被称为“数据膨胀”
- 这与数据增强过程正交,其中无论是原始还是生成的图像都会经过手动增强以产生在对比学习中使用的正负样本对
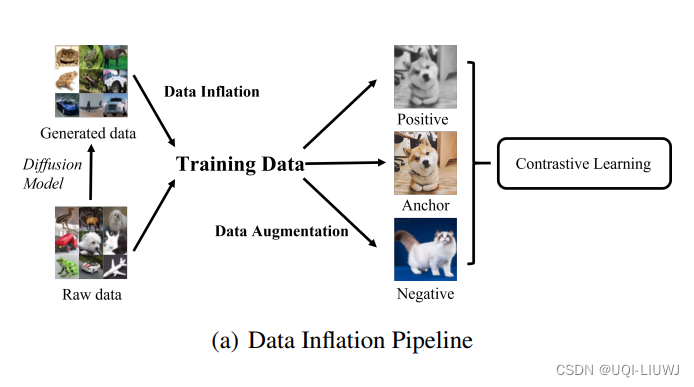
- 论文发现:生成的数据并不总是有利于对比学习
- 仅仅将CIFAR-10通过DDPM生成的100万图像进行数据膨胀,反而导致线性探测精度更差
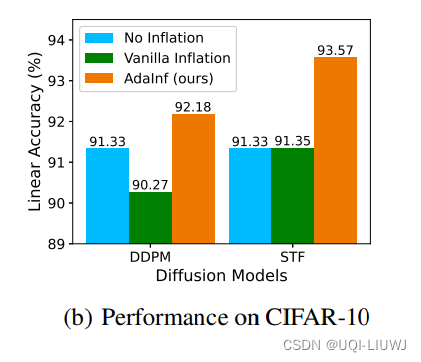
- ——>论文从两个方面调查这种意外的性能下降
- 数据膨胀(如何构建膨胀数据)
- 更好的生成质量帮助有限,而重新加权真实数据和生成数据可以获得更大的收益
- 数据增强(如何使用膨胀数据制作增强样本)
- 尽管在标准对比学习中有害,但较弱的数据增强与数据膨胀结合使用时可以非常有益
- 数据膨胀(如何构建膨胀数据)
- ——》建立了第一个针对膨胀对比学习的普遍性保证,并通过揭示数据膨胀和数据增强之间的互补作用来解释弱增强的好处
- 基于这些见解,论文提出了一种自适应膨胀(AdaInf)策略,该策略可以自适应调整数据增强的强度和混合比例,从而在不增加任何计算开销的情况下显著提高下游性能