文章目录
- 一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod
- 1 Replication Controller(RC)
- 2 Replication Set(RS)
- 二、Deployment的使用
- 1 创建
- 2 滚动升级
- 3 回滚Deployment
- 三、 Pod 自动扩缩容HPA
- 1 使用kubectl autoscale
- 2 不使用kubectl autoscale
- 三、Job 和 Cronjob 的使用
- 1 Job
- 2 CronJob
- 四、Service
- 1.三种IP
- 2.定义Service
- 3.kube-proxy
- 4.Service 类型
- 5.NodePort 类型
- 6.ExternalName
- 五、ConfigMap
- 1.通过yaml文件的方式创建
- 2.通过目录和命令行创建
- 3.通过配置文件和命令行创建
- 4.通过命令行的--from-literal进行创建
- 5.如何在pod中使用?
一、使用Replication Controller(RC)、Replica Set(RS) 管理Pod
如果有一种工具能够来帮助我们管理Pod就好了,Pod不够了自动帮我新增一个,Pod挂了自动帮我在合适的节点上重新启动一个Pod,这样是不是遇到上面的问题我们都不需要手动去解决了。
幸运的是,Kubernetes就为我们提供了这样的资源对象:
- Replication Controller:用来部署、升级Pod
- Replica Set:下一代的Replication Controller
- Deployment:可以更加方便的管理Pod和Replica Set
1 Replication Controller(RC)
Replication Controller简称RC,RC是Kubernetes系统中的核心概念之一,简单来说,RC可以保证在任意时间运行Pod的副本数量,能够保证Pod总是可用的。如果实际Pod数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当Pod失败、被删除或者挂掉后,RC都会去自动创建新的Pod来保证副本数量,所以即使只有一个Pod,我们也应该使用RC来管理我们的Pod。
运行Pod的节点挂了,RC检测到Pod失败了,就会去合适的节点重新启动一个Pod就行,不需要我们手动去新建一个Pod了。如果是第一种情况的话在活动开始之前我们给Pod指定10个副本,结束后将副本数量改成2,这样是不是也远比我们手动去启动、手动去关闭要好得多,而且我们后面还会给大家介绍另外一种资源对象HPA可以根据资源的使用情况来进行自动扩缩容。
现在我们来使用RC来管理我们前面使用的Nginx的Pod,YAML文件如下:
apiVersion: v1
kind: ReplicationController
metadata:name: rc-demolabels:name: rc
spec:replicas: 3selector:name: rctemplate:metadata:labels:name: rcspec:containers:- name: nginx-demoimage: nginxports:- containerPort: 80
上面的YAML文件相对于我们之前的Pod的格式:
- kind:ReplicationController
- spec.replicas: 指定Pod副本数量,默认为1
- spec.selector: RC通过该属性来筛选要控制的Pod
- spec.template: 这里就是我们之前的Pod的定义的模块,但是不需要apiVersion和kind了
- spec.template.metadata.labels: 注意这里的Pod的labels要和spec.selector相同,这样RC就可以来控制当前这个Pod了。
这个YAML文件中的意思就是定义了一个RC资源对象,它的名字叫rc-demo,保证一直会有3个Pod运行,Pod的镜像是nginx镜像。
注意spec.selector和spec.template.metadata.labels这两个字段必须相同,否则会创建失败的,当然我们也可以不写spec.selector,这样就默认与Pod模板中的metadata.labels相同了。所以为了避免不必要的错误的话,不写为好。
然后我们来创建上面的RC对象(保存为 rc-demo.yaml):
$ kubectl create -f rc-demo.yaml
查看RC:
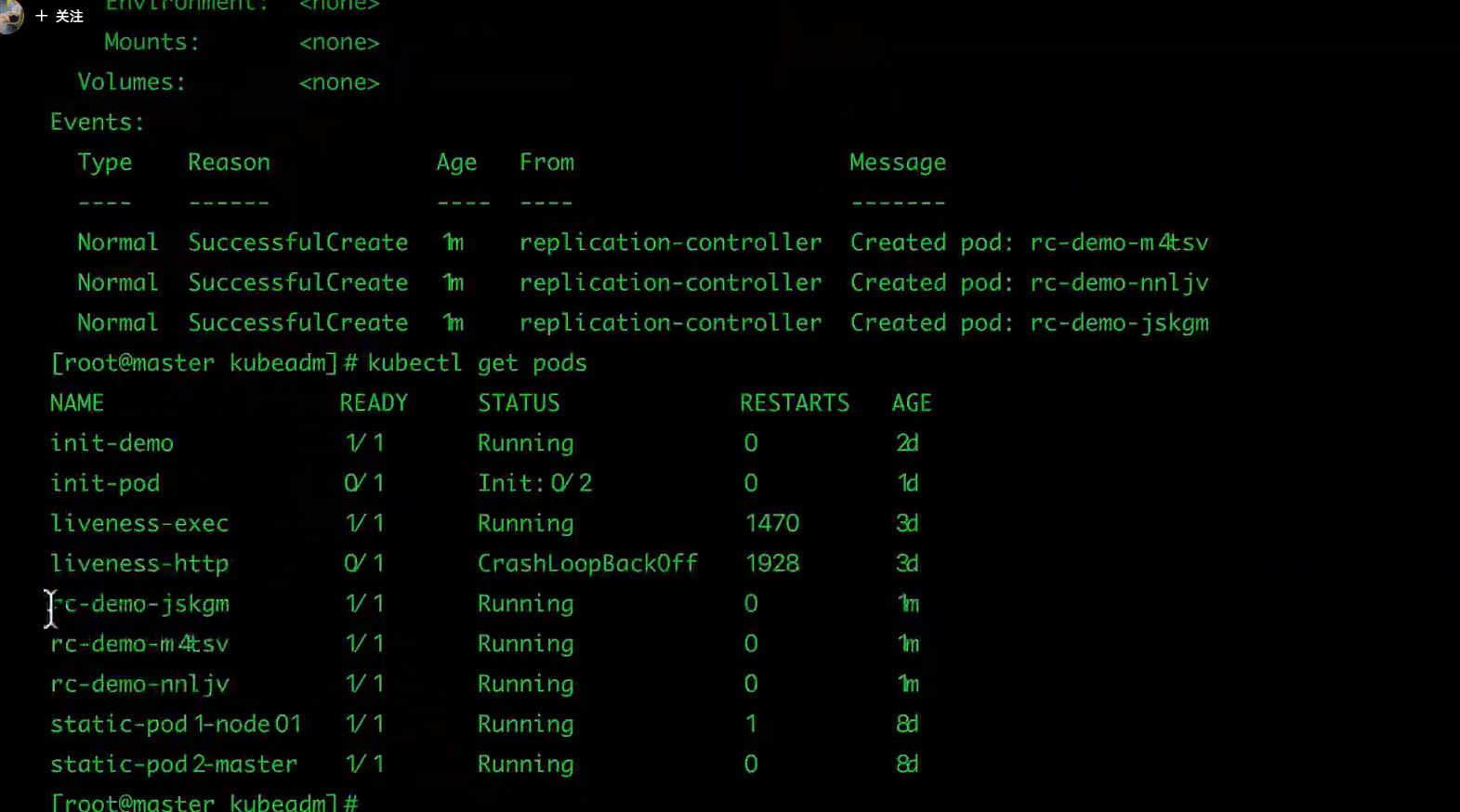
$ kubectl get rc
查看具体信息:
$ kubectl describe rc rc-demo
然后我们通过RC来修改下Pod的副本数量为2:
$ kubectl apply -f rc-demo.yaml或者
$ kubectl edit rc rc-demo
而且我们还可以用RC来进行滚动升级,比如我们将镜像地址更改为nginx:1.7.9:
$ kubectl rolling-update rc-demo --image=nginx:1.7.9
但是如果我们的Pod中多个容器的话,就需要通过修改YAML文件来进行修改了:
$ kubectl rolling-update rc-demo -f rc-demo.yaml
RC无法进行回滚操作
- 如果升级完成后出现了新的问题,想要一键回滚到上一个版本的话,使用RC只能用同样的方法把镜像地址替换成之前的,然后重新滚动升级。
2 Replication Set(RS)
Replication Set简称RS,随着Kubernetes的高速发展,官方已经推荐我们使用RS和Deployment来代替RC了,实际上RS和RC的功能基本一致,目前唯一的一个区别就是RC只支持基于等式的selector(env=dev或environment!=qa),但RS还支持基于集合的selector(version in (v1.0, v2.0)),这对复杂的运维管理就非常方便了。
eg:
apiVersion: v1
kind: ReplicationSet
metadata:name: rc-demolabels:name: rc
spec:replicas: 3selector:name: rctemplate:metadata:labels:name: rcspec:containers:- name: nginx-demoimage: nginxports:- containerPort: 80
kubectl命令行工具中关于RC的大部分命令同样适用于我们的RS资源对象。不过我们也很少会去单独使用RS,它主要被Deployment这个更加高层的资源对象使用,除非用户需要自定义升级功能或根本不需要升级Pod,在一般情况下,我们推荐使用Deployment而不直接使用Replica Set。
最后我们总结下关于RC/RS的一些特性和作用吧:
- 大部分情况下,我们可以通过定义一个RC实现的Pod的创建和副本数量的控制
- RC中包含一个完整的Pod定义模块(不包含apiversion和kind)
- RC是通过label selector机制来实现对Pod副本的控制的
- 通过改变RC里面的Pod副本数量,可以实现Pod的扩缩容功能
- 通过改变RC里面的Pod模板中镜像版本,可以实现Pod的滚动升级功能(但是不支持一键回滚,需要用相同的方法去修改镜像地址)
二、Deployment的使用
首先RC是Kubernetes的一个核心概念,当我们把应用部署到集群之后,需要保证应用能够持续稳定的运行,RC就是这个保证的关键,主要功能如下:
- 确保Pod数量:它会确保Kubernetes中有指定数量的Pod在运行,如果少于指定数量的Pod,RC就会创建新的,反之这会删除多余的,保证Pod的副本数量不变。
- 确保Pod健康:当Pod不健康,比如运行出错了,总之无法提供正常服务时,RC也会杀死不健康的Pod,重新创建新的。
- 弹性伸缩:在业务高峰或者低峰的时候,可以用过RC来动态的调整Pod数量来提供资源的利用率,当然我们也提到过如果使用HPA这种资源对象的话可以做到自动伸缩。
- 滚动升级:滚动升级是一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定性,
Deployment同样也是Kubernetes系统的一个核心概念,主要职责和RC一样的都是保证Pod的数量和健康,二者大部分功能都是完全一致的,我们可以看成是一个升级版的RC控制器,那Deployment又具备那些新特性呢?
- RC的全部功能:Deployment具备上面描述的RC的全部功能
- 事件和状态查看:可以查看Deployment的升级详细进度和状态
- 回滚:当升级Pod的时候如果出现问题,可以使用回滚操作回滚到之前的任一版本
- 版本记录:每一次对Deployment的操作,都能够保存下来,这也是保证可以回滚到任一版本的基础
- 暂停和启动:对于每一次升级都能够随时暂停和启动
作为对比,我们知道Deployment作为新一代的RC,不仅在功能上更为丰富了,同时我们也说过现在官方也都是推荐使用Deployment来管理Pod的,比如一些官方组件kube-dns、kube-proxy也都是使用的Deployment来管理的,所以当大家在使用的使用也最好使用Deployment来管理Pod。
1 创建
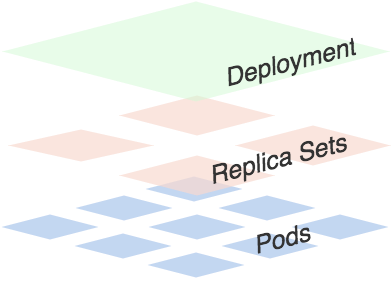
可以看出一个Deployment拥有多个Replica Set,而一个Replica Set拥有一个或多个Pod。
一个Deployment控制多个rs主要是为了支持回滚机制,每当Deployment操作时,Kubernetes会重新生成一个Replica Set并保留,以后有需要的话就可以回滚至之前的状态。
下面创建一个Deployment,它创建了一个Replica Set来启动3个nginx pod,yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploylabels:k8s-app: nginx-demo
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80
将上面内容保存为: nginx-deployment.yaml,执行命令:
$ kubectl create -f nginx-deployment.yaml
deployment "nginx-deploy" created
然后执行一下命令查看刚刚创建的Deployment:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 0 0 0 1s隔一会再次执行上面命令:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 3 3 3 4m
我们可以看到Deployment已经创建了1个Replica Set了,执行下面的命令查看rs和pod:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-431080787 3 3 3 6m$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deploy-431080787-53z8q 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
nginx-deploy-431080787-bhhq0 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
nginx-deploy-431080787-sr44p 1/1 Running 0 7m app=nginx,pod-template-hash=431080787
上面的Deployment的yaml文件中的replicas:3将会保证我们始终有3个POD在运行。
2 滚动升级
现在我们将刚刚保存的yaml文件中的nginx镜像修改为nginx:1.13.3,然后在spec下面添加滚动升级策略:
minReadySeconds: 5
strategy:# indicate which strategy we want for rolling updatetype: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1
minReadySeconds:
Kubernetes在等待设置的时间后才进行升级
- 如果没有设置该值,Kubernetes会假设该容器启动起来后就提供服务了
- 如果没有设置该值,在某些极端情况下可能会造成服务不正常运行
maxSurge:
- 升级过程中最多可以比原先设置多出的POD数量
- 例如:maxSurage=1,replicas=5,则表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
maxUnavaible:
- 升级过程中最多有多少个POD处于无法提供服务的状态
- 当maxSurge不为0时,该值也不能为0
- 例如:maxUnavaible=1,则表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-deploynamespace: testlabels:app: nginx-demo
spec:replicas: 3minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.13.3ports:- containerPort: 80name: nginxweb然后执行命令:
$ kubectl apply -f nginx-deployment.yaml --record=true
deployment "nginx-deploy" configured
然后我们可以使用rollout命令:
查看状态:kubectl rollout status deployment nginx-deploy
$ kubectl rollout status deployment/nginx-deploy
Waiting for rollout to finish: 1 out of 3 new replicas have been updated..
deployment "nginx-deploy" successfully rolled out暂停升级
$ kubectl rollout pause deployment nginx-deploy继续升级
$ kubectl rollout resume deployment nginx-deploy
升级结束后,继续查看rs的状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-2078889897 0 0 0 47m
nginx-deploy-3297445372 3 3 3 42m
nginx-deploy-431080787 0 0 0 1h
根据AGE我们可以看到离我们最近的当前状态是:3,和我们的yaml文件是一致的,证明升级成功了。
用describe命令可以查看升级的全部信息:
kubectl describe deployment nginx-deploy
Name: nginx-deploy
Namespace: default
CreationTimestamp: Wed, 18 Oct 2017 16:58:52 +0800
Labels: k8s-app=nginx-demo
Annotations: deployment.kubernetes.io/revision=3kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"k8s-app":"nginx-demo"},"name":"nginx-deploy","namespace":"defa...
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:Labels: app=nginxContainers:nginx:Image: nginx:1.13.3Port: 80/TCPEnvironment: <none>Mounts: <none>Volumes: <none>
Conditions:Type Status Reason---- ------ ------Progressing True NewReplicaSetAvailableAvailable True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deploy-3297445372 (3/3 replicas created)
Events:FirstSeen LastSeen Count From SubObjectPath Type Reason Message--------- -------- ----- ---- ------------- -------- ------ -------50m 50m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-2078889897 to 145m 45m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-2078889897 to 045m 45m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 139m 39m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 239m 39m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 238m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 138m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled up replica set nginx-deploy-3297445372 to 338m 38m 1 deployment-controller Normal ScalingReplicaSet Scaled down replica set nginx-deploy-431080787 to 0
3 回滚Deployment
我们已经能够滚动平滑的升级我们的Deployment了,但是如果升级后的POD出了问题该怎么办?我们能够想到的最好最快的方式当然是回退到上一次能够提供正常工作的版本,Deployment就为我们提供了回滚机制。
首先,查看Deployment的升级历史:
$ kubectl rollout history deployment nginx-deploy
deployments "nginx-deploy"
REVISION CHANGE-CAUSE
1 <none>
2 <none>
3 kubectl apply --filename=Desktop/nginx-deployment.yaml --record=true
从上面的结果可以看出在执行Deployment升级的时候最好带上record参数,便于我们查看历史版本信息。
默认情况下,所有通过kubectl xxxx --record都会被kubernetes记录到etcd进行持久化,这无疑会占用资源,最重要的是,时间久了,当你kubectl get rs时,会有成百上千的垃圾RS返回给你,那时你可能就眼花缭乱了。
上生产时,我们最好通过设置Deployment的.spec.revisionHistoryLimit来限制最大保留的revision number,比如15个版本,回滚的时候一般只会回滚到最近的几个版本就足够了。
其实rollout history中记录的revision都和ReplicaSets一一对应。如果手动delete某个ReplicaSet,对应的rollout history就会被删除,也就是还说你无法回滚到这个revison了。
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-deploynamespace: testlabels:app: nginx-demo
spec:replicas: 3revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80name: nginxwebrollout history和ReplicaSet的对应关系,可以在kubectl describe rs $RSNAME返回的revision字段中得到,这里的revision就对应着rollout history返回的revison。
同样我们可以使用下面的命令查看单个revison的信息:
$ kubectl rollout history deployment nginx-deploy --revision=3
deployments "nginx-deploy" with revision #3
Pod Template:Labels: app=nginxpod-template-hash=3297445372Annotations: kubernetes.io/change-cause=kubectl apply --filename=nginx-deployment.yaml --record=trueContainers:nginx:Image: nginx:1.13.3Port: 80/TCPEnvironment: <none>Mounts: <none>Volumes: <none>
假如现在要直接回退到当前版本的前一个版本:
$ kubectl rollout undo deployment nginx-deploy
deployment "nginx-deploy" rolled back
当然也可以用revision回退到指定的版本:
$ kubectl rollout undo deployment nginx-deploy --to-revision=2
deployment "nginx-deploy" rolled back
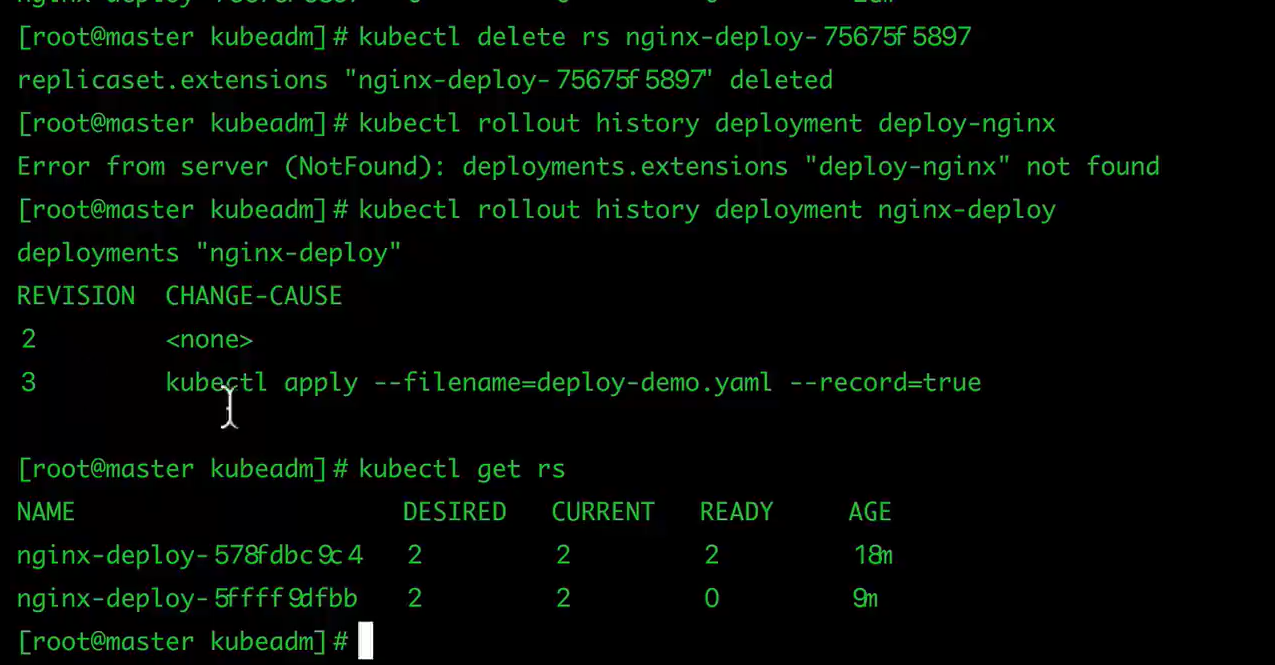
删除一个rs
$ kubectl delete rs nginx-deploy-431080787
三、 Pod 自动扩缩容HPA
手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。
Kubernetes为我们提供了这样一个资源对象:Horizontal Pod Autoscaling(Pod水平自动伸缩),简称HPA。HAP通过监控分析RC或者Deployment控制的所有Pod的负载变化情况来确定是否需要调整Pod的副本数量,这是HPA最基本的原理。
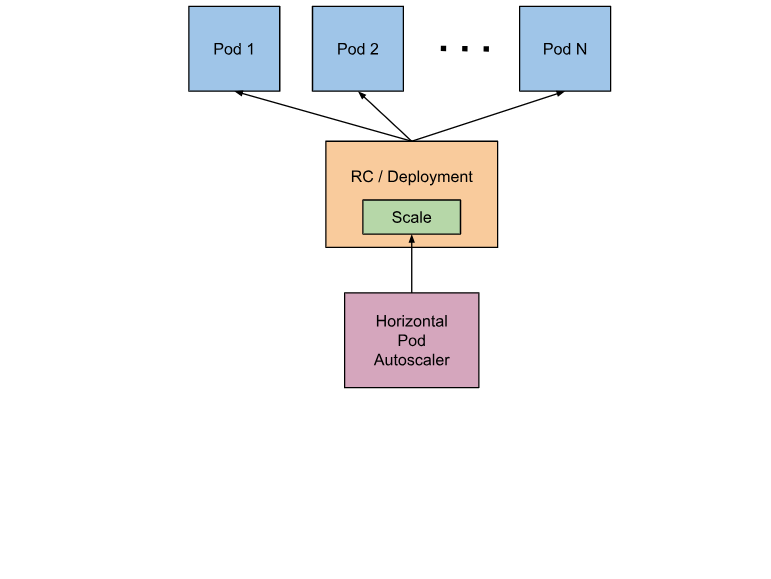
HPA在kubernetes集群中被设计成一个controller
- 我们可以简单的通过kubectl autoscale命令来创建一个HPA资源对象,
- HPA Controller默认30s轮询一次(可通过kube-controller-manager的标志–horizontal-pod-autoscaler-sync-period进行设置),查询指定的资源(RC或者Deployment)中Pod的资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
当你创建了HPA后,HPA会从Heapster或者用户自定义的RESTClient端获取每一个一个Pod利用率或原始值的平均值,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值并进行相应的操作。目前,HPA可以从两个地方获取数据:
- Heapster:仅支持CPU使用率
- 自定义监控:
实际上我们已经默认把Heapster(1.4.2 版本)相关的镜像都已经拉取到节点上了,所以接下来我们只需要部署即可:Heapster的github页面。

heapster.yaml中的image: gcr.io/google_containers/heapster-amd64:v1.3.0可能需要依据本地的image tag进行修改。
grafana.yaml(类似dashboard)中的image: gcr.io/google_containers/heapster-grafana-amd64:v4.2.0可能需要依据本地的image tag进行修改。
我们将该目录下面的yaml文件保存到我们的集群上,然后使用kubectl命令行工具创建即可.
执行所有的yaml文件
kubectl create -f .
查看某个pod的运行日志:
kubectl logs -f heapster-676cc864c6 -n kube-system
通过yaml文件删除pod
kubectl delete -f heapster.yaml
问题:直接启动heapster会出现以下问题:heapster没有权限
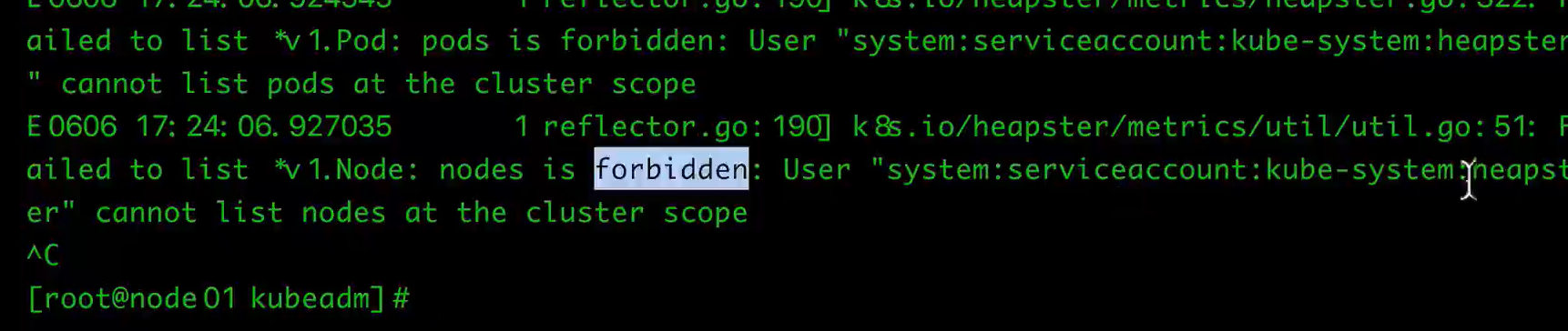
需要将heapster绑定到cluster-admin
---
apiVersion: v1
kind: ServiceAccount
metadata:name: heapsternamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: heapster-admin
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: cluster-admin
subjects:
- kind: ServiceAccountname: heapsternamespace: kube-system
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:name: heapsternamespace: kube-system
spec:replicas: 1template:metadata:labels:task: monitoringk8s-app: heapsterspec:serviceAccountName: heapstercontainers:- name: heapsterimage: gcr.io/google_containers/heapster-amd64:v1.3.0imagePullPolicy: IfNotPresentcommand:- /heapster- --source=kubernetes:https://kubernetes.default- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
---
apiVersion: v1
kind: Service
metadata:labels:task: monitoring# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# If you are NOT using this as an addon, you should comment out this line.kubernetes.io/cluster-service: 'true'kubernetes.io/name: Heapstername: heapsternamespace: kube-system
spec:ports:- port: 80targetPort: 8082selector:k8s-app: heapster
重新kubectl delete yaml、kubectl reate即可
另外创建完成后,如果需要在Dashboard当中看到监控图表,我们还需要在Dashboard中配置上我们的heapster-host。
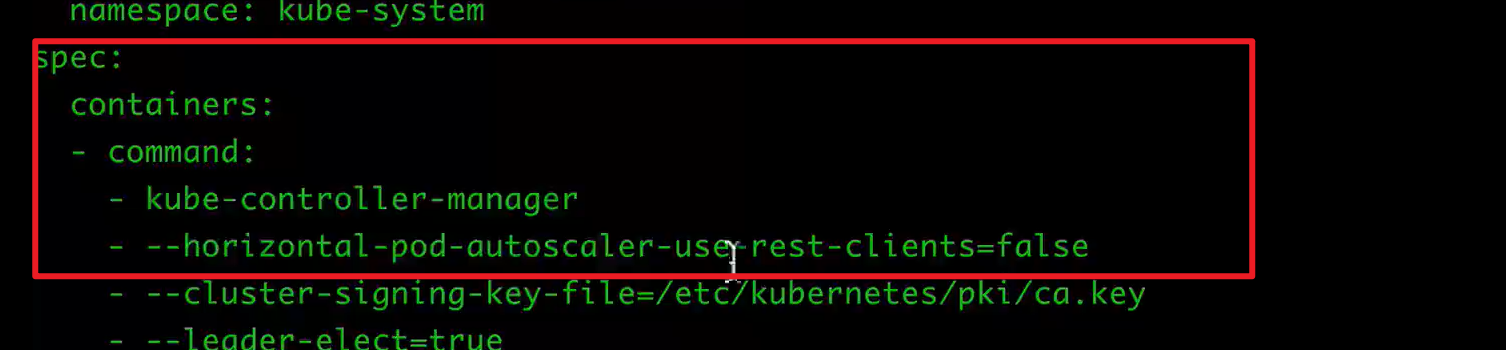
为了能够创建HPA,可能需要修改master上的kube-controller-manager.yaml

需要在command中增加下面的命令(修改完毕,则自动更新):
1 使用kubectl autoscale
我们来创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。
定义Deployment的YAML文件如下:(hap-deploy-demo.yaml)
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: hpa-demolabels:app: hpa
spec:revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxresources:requests:cpu: 100mports:- containerPort: 80
然后创建Deployment
$ kubectl create -f hpa-deploy-demo.yaml
现在我们来创建一个HPA,可以使用kubectl autoscale命令来创建:
$ kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=10 --min=1 --max=10
deployment "hpa-nginx-deploy" autoscaled
···
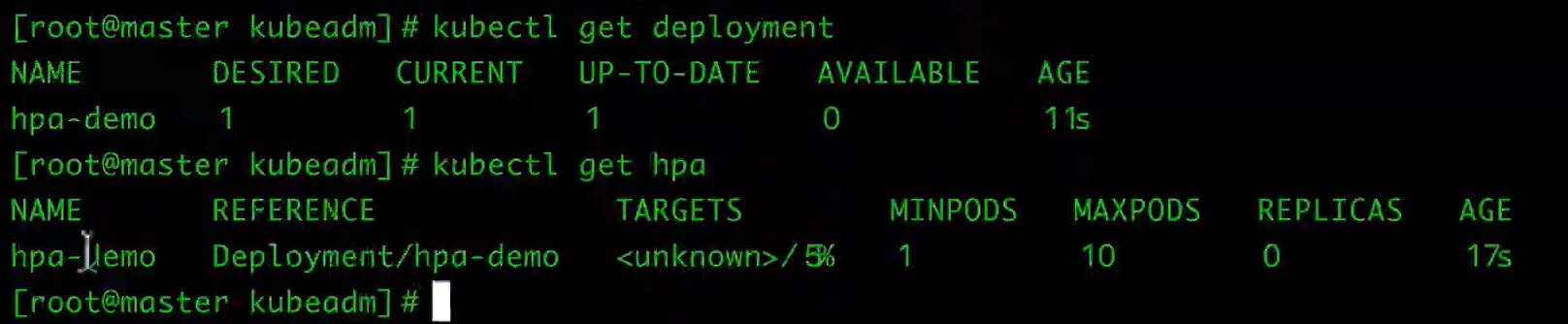
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 13s
此命令创建了一个关联资源 hpa-nginx-deploy 的HPA,最小的 pod 副本数为1,最大为10。HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。
现在我们来增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://172.16.255.60:4000; done
下图可以看到,HPA已经开始工作。
kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 29% 1 10 27m
同时我们查看相关资源hpa-nginx-deploy的副本数量,副本数量已经从原来的1变成了3。
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 3 3 3 3 4d
同时再次查看HPA,由于副本数量的增加,使用率也保持在了10%左右。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 9% 1 10 35m
同样的这个时候我们来关掉busybox来减少负载,然后等待一段时间观察下HPA和Deployment对象
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 48m
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 1 1 1 1 4d
可以看到副本数量已经由3变为1。
2 不使用kubectl autoscale
使用已经创建成功的hpa
$ kubectl get hpa hpa-nginx-deploy -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:creationTimestamp: 2017-06-29T08:04:08Zname: nginxtestnamespace: defaultresourceVersion: "951016361"selfLink: /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers/nginxtestuid: 86febb63-5ca1-11e7-aaef-5254004e79a3
spec:maxReplicas: 5 //资源最大副本数minReplicas: 1 //资源最小副本数scaleTargetRef:apiVersion: apps/v1kind: Deployment //需要伸缩的资源类型name: nginxtest //需要伸缩的资源名称targetCPUUtilizationPercentage: 50 //触发伸缩的cpu使用率
status:currentCPUUtilizationPercentage: 48 //当前资源下pod的cpu使用率currentReplicas: 1 //当前的副本数desiredReplicas: 2 //期望的副本数lastScaleTime: 2017-07-03T06:32:19Z

使用生成的HPA重新创建一个HPA
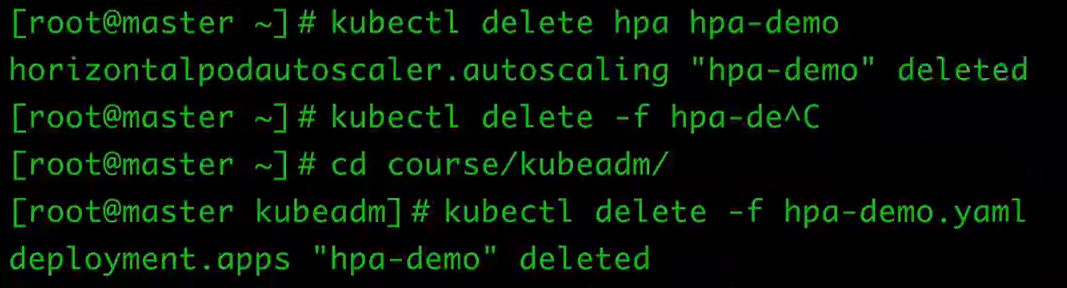
删除hpa
kubectl delete hpa hpa-demo删除deployments
kubectl delete -f hpa-demo.yaml
将生成的yaml追加到hap-deploy-demo.yaml,得到的内容如下:
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: hpa-demolabels:app: hpa
spec:revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxresources:requests:cpu: 100mports:- containerPort: 80---
5apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:name: hpa-demonamespace: default
spec:maxReplicas: 10minReplicas: 1scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: hpa-demotargetCPUUtilizationPercentage: 5重新创建
kubectl create -f hpa-demo.yaml

三、Job 和 Cronjob 的使用
Job负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而CronJob则就是在Job上加上了时间调度。
1 Job
我们用Job这个资源对象来创建一个任务,我们定一个Job来执行一个倒计时的任务,定义YAML文件:
apiVersion: batch/v1
kind: Job
metadata:name: job-demo
spec:template:metadata:name: job-demospec:restartPolicy: Nevercontainers:- name: counterimage: busyboxcommand:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
注意Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always,我们知道Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话是不是就陷入了死循环了?
然后来创建该Job,保存为job-demo.yaml:
$ kubectl create -f ./job.yaml
job "job-demo" created
然后我们可以查看当前的Job资源对象:
$ kubectl get jobs
$ kubectl describe job job-demo
注意查看我们的Pod的状态,同样我们可以通过kubectl logs来查看当前任务的执行结果。
$ kubectl logs job-demo-p6zst
2 CronJob
期性地在给定时间点运行。这个实际上和我们Linux中的crontab就非常类似了。
一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 时 日 月 星期 要运行的命令
第1列分钟0~59
第2列小时0~23)
第3列日1~31
第4列月1~12
第5列星期0~7(0和7表示星期天)
第6列要运行的命令
现在,我们用CronJob来管理我们上面的Job任务,
apiVersion: batch/v2alpha1
kind: CronJob
metadata:name: cronjob-demo
spec:schedule: "*/1 * * * *"jobTemplate:spec:template:spec:restartPolicy: OnFailurecontainers:- name: helloimage: busyboxargs:- "bin/sh"- "-c"- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
我们这里的Kind是CronJob了,要注意的是.spec.schedule字段是必须填写的,用来指定任务运行的周期,格式就和crontab一样,另外一个字段是.spec.jobTemplate, 用来指定需要运行的任务,格式当然和Job是一致的。
还有一些值得我们关注的字段.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit,表示历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job,默认没有限制,所有成功和失败的Job都会被保留。然而,当运行一个Cron Job时,Job可以很快就堆积很多,所以一般推荐设置这两个字段的值。如果设置限制的值为 0,那么相关类型的Job完成后将不会被保留。
接下来我们来创建这个cronjob
$ kubectl create -f cronjob-demo.yaml
cronjob "cronjob-demo" created
当然,也可以用kubectl run来创建一个CronJob:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 <none>
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name} -a)
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
一旦不再需要 Cron Job,简单地可以使用 kubectl 命令删除它:
$ kubectl delete cronjob hello
cronjob "hello" deleted
这将会终止正在创建的 Job。
然而,运行中的 Job 将不会被终止,不会删除 Job 或 它们的 Pod。为了清理那些 Job 和 Pod,需要列出该 Cron Job 创建的全部 Job,然后删除它们:
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1201907962 1 1 11m
hello-1202039034 1 1 8m
...$ kubectl delete jobs hello-1201907962 hello-1202039034 ...
job "hello-1201907962" deleted
job "hello-1202039034" deleted
...
一旦 Job 被删除,由 Job 创建的 Pod 也会被删除。注意,所有由名称为 “hello” 的 Cron Job 创建的 Job 会以前缀字符串 “hello-” 进行命名。如果想要删除当前 Namespace 中的所有 Job,可以通过命令 kubectl delete jobs --all 立刻删除它们。
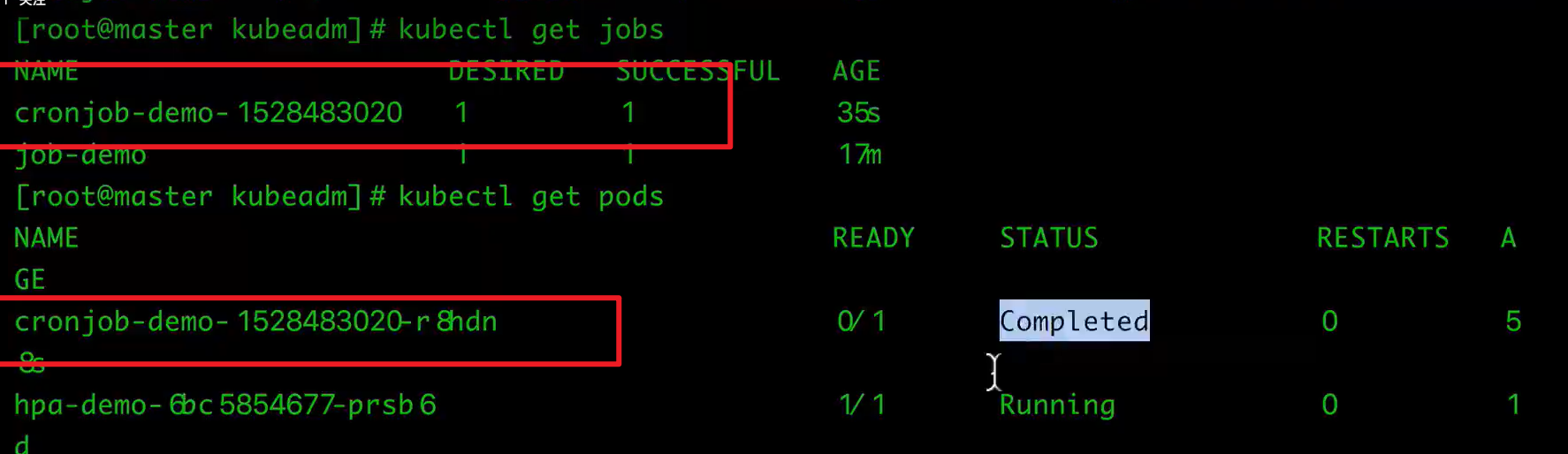
CronJob的某个job与pod之间的对应关系如下:
$ kubectl get cronjob
$ kubectl get jobs
$ kubectl get pods
看下job的对应的pod的log,无法直接查看某个cronjob的log
$ kubectl logs cronjob-demo-12XXX
删除CronJob
$ kubectl delte cronjob cronjob-demo
或者
$ kubectl delete -f cronjob-demo.yaml
四、Service
在没有使用Kubernetes之前,我相信可能很多同学都遇到过这样的问题,不一定是IP变化的问题,比如我们在部署一个WEB服务的时候,前端一般部署一个Nginx作为服务的入口,然后Nginx后面肯定就是挂载的这个服务的大量后端,很早以前我们可能是去手动更改Nginx配置中的upstream选项,来动态改变提供服务的数量,到后面出现了一些服务发现的工具,比如Consul、ZooKeeper还有我们熟悉的etcd等工具,有了这些工具过后我们就可以只需要把我们的服务注册到这些服务发现中心去就可以,然后让这些工具动态的去更新Nginx的配置就可以了,我们完全不用去手工的操作了,是不是非常方便。
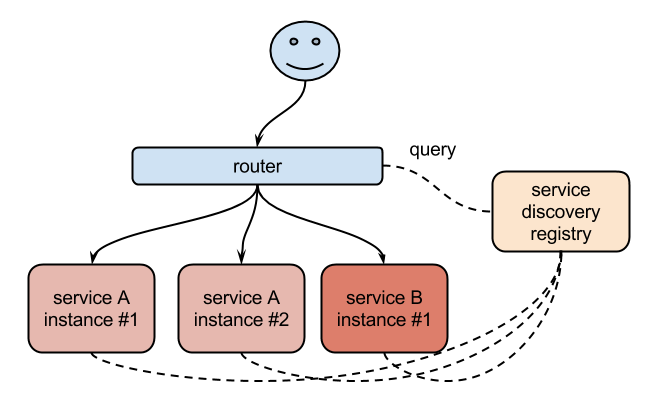
同样的,要解决我们上面遇到的问题是不是实现一个服务发现的工具也可以解决啊?没错的,当我们Pod被销毁或者新建过后,我们可以把这个Pod的地址注册到这个服务发现中心去就可以,但是这样的话我们的前端的Pod结合就不能直接去连接后台的Pod集合了是吧,应该连接到一个能够做服务发现的中间件上面,对吧?
没错,Kubernetes集群就为我们提供了这样的一个对象
- Service,Service是一种抽象的对象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,其实这个概念和微服务非常类似。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。
- 比如我们上面的例子,假如我们后端运行了3个副本,这些副本都是可以替代的,因为前端并不关心它们使用的是哪一个后端服务。尽管由于各种原因后端的Pod集合会发送变化,但是前端却不需要知道这些变化,也不需要自己用一个列表来记录这些后端的服务,Service的这种抽象就可以帮我们达到这种解耦的目的。
1.三种IP
- Node IP:Node节点的IP地址
- Pod IP: Pod的IP地址
- Cluster IP: Service的IP地址
首先,Node IP是Kubernetes集群中节点的物理网卡IP地址(一般为内网),所有属于这个网络的服务器之间都可以直接通信,所以Kubernetes集群外要想访问Kubernetes集群内部的某个节点或者服务,肯定得通过Node IP进行通信(这个时候一般是通过外网IP了)
然后Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的(我们这里使用的是flannel这种网络插件保证所有节点的Pod IP不会冲突)
最后Cluster IP是一个虚拟的IP,仅仅作用于Kubernetes Service这个对象,由Kubernetes自己来进行管理和分配地址,当然我们也无法ping这个地址,他没有一个真正的实体对象来响应,他只能结合Service Port来组成一个可以通信的服务。
2.定义Service
先创建pods
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:name: nginx-deploynamespace: testlabels:app: nginx-demo
spec:replicas: 3revisionHistoryLimit: 15minReadySeconds: 5strategy:type: RollingUpdaterollingUpdate:maxSurge: 1maxUnavailable: 1template:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxports:- containerPort: 80name: nginxweb
创建Deployment
$ kubectl create -f deploy-demo.yaml
创建service
apiVersion: v1
kind: Service
metadata:name: myservice
spec:selector:app: nginxports:- protocol: TCP# 该service的端口port: 80#匹配到app: nginx的容器的端口targetPort: nginxweb
$ kubectl create -f service-demo.yaml
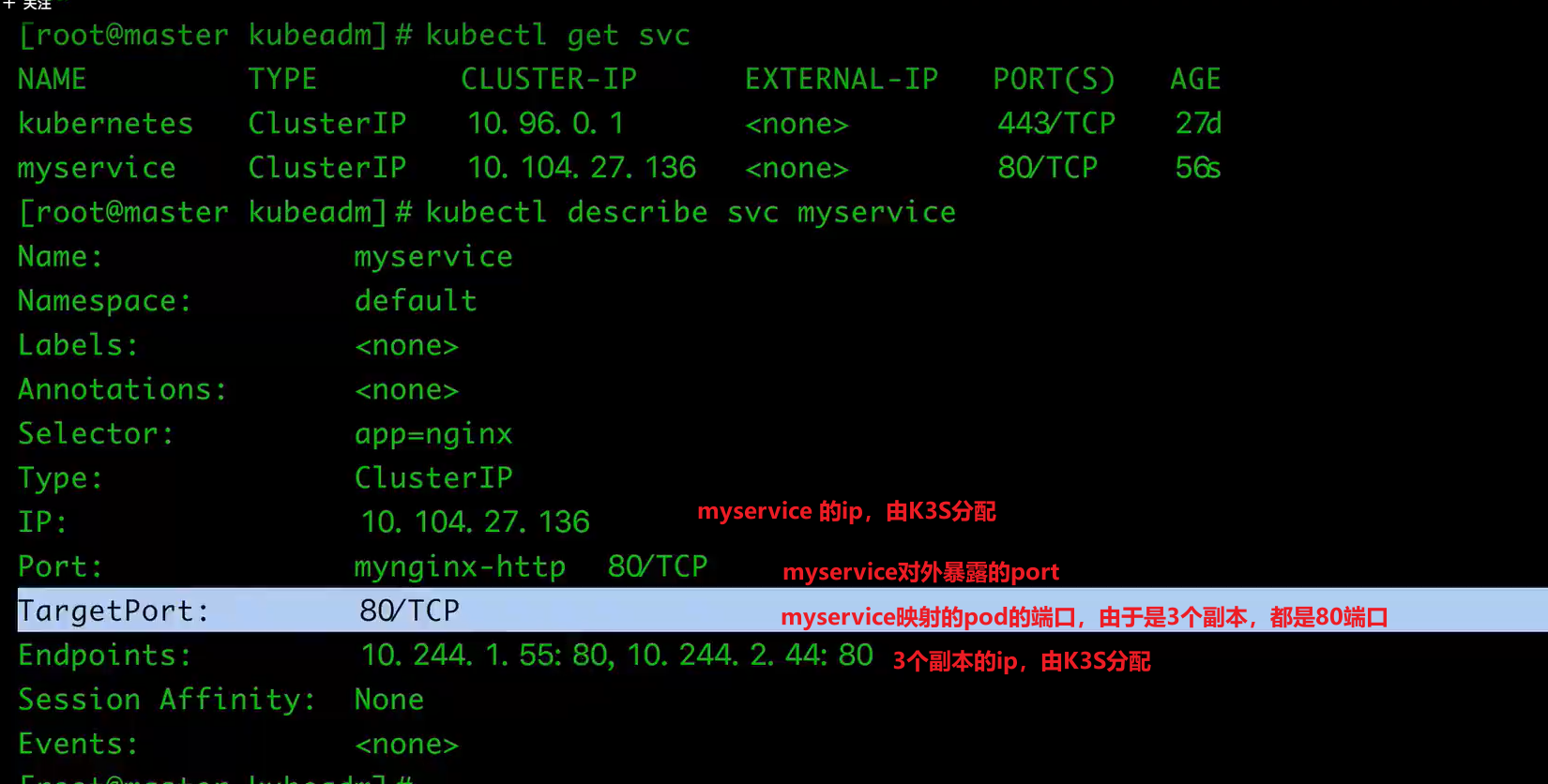
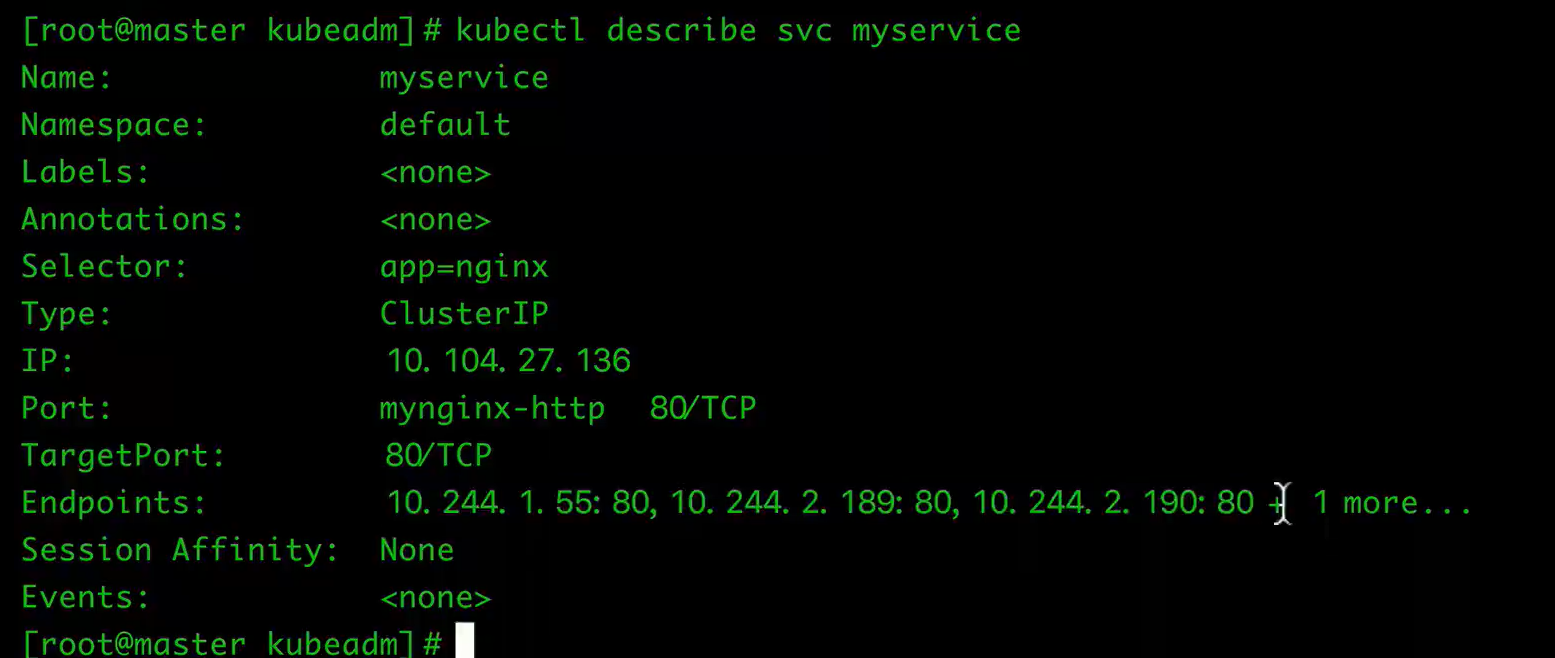
查看
$ kubectl get svc
$ kubectl describe svc myservice
测试Cluster IP
$ kubectl run -it testservice --image=busybox /bin/bash
$ wget -O- -q http://10.104.27.136:80
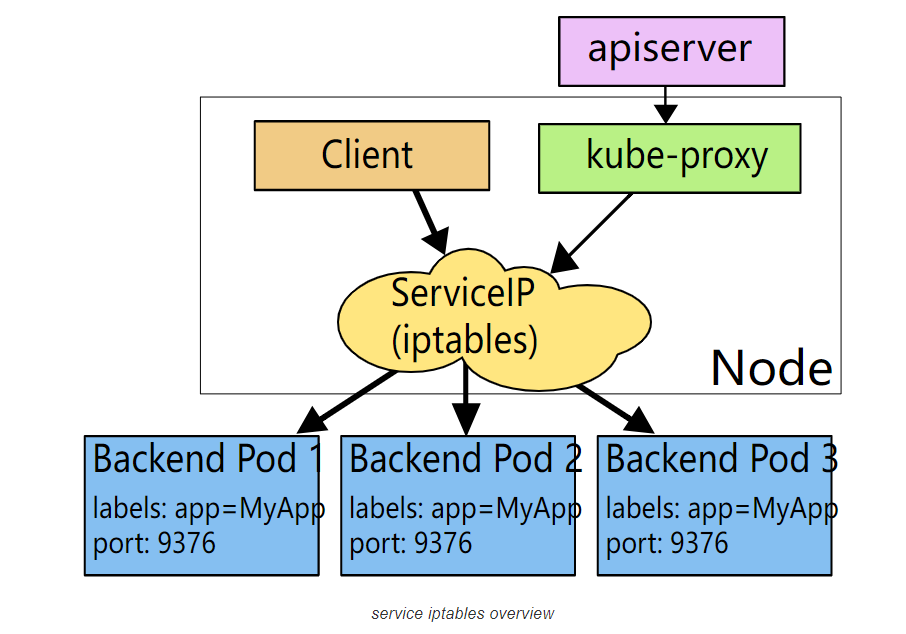
3.kube-proxy
在Kubernetes集群中,每个Node会运行一个kube-proxy进程, 负责为Service实现一种 VIP(虚拟 IP,就是我们上面说的clusterIP)的代理形式,现在的Kubernetes中默认是使用的iptables这种模式来代理。
这种模式,kube-proxy会监视Kubernetes master对 Service 对象和 Endpoints 对象的添加和移除。
对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个个上面。
对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend Pod。
默认的策略是,随机选择一个 backend。 我们也可以实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 “ClientIP” (默认值为 “None”)。
如果最开始选择的 Pod 没有响应,iptables 代理能够自动地重试另一个 Pod,所以它需要依赖 readiness probes。
4.Service 类型
我们在定义Service的时候可以指定一个自己需要的类型的Service,如果不指定的话默认是ClusterIP类型。
我们可以使用的服务类型如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。
- NodePort:通过每个 Node 节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由(会暴露一个node的端口)到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 node ip:node port,可以从集群的外部访问一个 NodePort 服务。
- LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,这个需要结合具体的云厂商进行操作。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
5.NodePort 类型
如果设置 type 的值为 “NodePort”,Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。
- 该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定,如果不指定的话会自动生成一个端口。
需要注意的是,Service 将能够通过 :spec.ports[].nodePort 和 spec.clusterIp:spec.ports[].port 而对外可见。
接下来我们来给大家创建一个NodePort的服务来访问我们前面的Nginx服务:(保存为service-demo.yaml)
apiVersion: v1
kind: Service
metadata:name: myservice
spec:selector:app: myapptype: NodePortports:- protocol: TCPport: 80targetPort: 80name: myapp-http
创建该Service:
$ kubectl create -f service-demo.yaml
然后我们可以查看Service对象信息:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 27d
myservice NodePort 10.104.57.198 <none> 80:32560/TCP 14h
我们可以看到myservice的 TYPE 类型已经变成了NodePort,后面的PORT(S)部分也多了一个 32560 的映射端口。
- 直接通过node ip:32560即可访问
6.ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。 对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:name: my-servicenamespace: prod
spec:type: ExternalNameexternalName: my.database.example.com
当查询主机 my-service.prod.svc.cluster.local (后面服务发现的时候我们会再深入讲解)时,集群的 DNS 服务将返回一个值为 my.database.example.com 的 CNAME 记录。 访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
五、ConfigMap
资源对象:ConfigMap,我们知道许多应用经常会有从配置文件、命令行参数或者环境变量中读取一些配置信息,这些配置信息我们肯定不会直接写死到应用程序中去的,比如你一个应用连接一个redis服务,下一次想更换一个了的,还得重新去修改代码,重新制作一个镜像,这肯定是不可取的,而ConfigMap就给我们提供了向容器中注入配置信息的能力,不仅可以用来保存单个属性,也可以用来保存整个配置文件,比如我们可以用来配置一个redis服务的访问地址,也可以用来保存整个redis的配置文件。
1.通过yaml文件的方式创建
ConfigMap 资源对象使用key-value形式的键值对来配置数据,这些数据可以在Pod里面使用,ConfigMap和我们后面要讲到的Secrets比较类似,一个比较大的区别是ConfigMap可以比较方便的处理一些非敏感的数据,比如密码之类的还是需要使用Secrets来进行管理。
我们来举个例子说明下ConfigMap的使用方法:
kind: ConfigMap
apiVersion: v1
metadata:name: cm-demonamespace: default
data:data.1: hellodata.2: worldconfig: |property.1=value-1property.2=value-2property.3=value-3
其中配置数据在data属性下面进行配置,前两个被用来保存单个属性,后面一个被用来保存一个配置文件。
使用kubectl create -f xx.yaml来创建上面的ConfigMap对象
查询configmap
$ kubectl get configmap
描述configmap
$ kubectl describe configmap cm-demo1
2.通过目录和命令行创建
我们可以看到可以从一个给定的目录来创建一个ConfigMap对象,比如我们有一个testcm的目录,该目录下面包含一些配置文件,redis和mysql的连接信息,如下:
$ ls testcm
redis.conf
mysql.conf$ cat testcm/redis.conf
host=127.0.0.1
port=6379$ cat testcm/mysql.conf
host=127.0.0.1
port=3306
然后我们可以使用from-file关键字来创建包含这个目录下面所以配置文件的ConfigMap:
$ kubectl create configmap cm-demo1 --from-file=testcm
configmap "cm-demo1" created
其中from-file参数指定在该目录下面的所有文件都会被用在ConfigMap里面创建一个键值对,键的名字就是文件名,值就是文件的内容。
创建完成后,同样我们可以使用如下命令来查看ConfigMap列表:
$ kubectl get configmap
NAME DATA AGE
cm-demo1 2 17s
可以看到已经创建了一个cm-demo1的ConfigMap对象,然后可以使用describe命令查看详细信息:
kubectl describe configmap cm-demo1
Name: cm-demo1
Namespace: default
Labels: <none>
Annotations: <none>Data
====
mysql.conf:
----
host=127.0.0.1
port=3306redis.conf:
----
host=127.0.0.1
port=6379Events: <none>
我们可以看到两个key是testcm目录下面的文件名称,对应的value值的话就是文件内容,这里值得注意的是如果文件里面的配置信息很大的话,describe的时候可能不会显示对应的值,要查看键值的话,可以使用如下命令:
$ kubectl get configmap cm-demo1 -o yaml
apiVersion: v1
data:mysql.conf: |host=127.0.0.1port=3306redis.conf: |host=127.0.0.1port=6379
kind: ConfigMap
metadata:creationTimestamp: 2018-06-14T16:24:36Zname: cm-demo1namespace: defaultresourceVersion: "3109975"selfLink: /api/v1/namespaces/default/configmaps/cm-demo1uid: 6e0f4d82-6fef-11e8-a101-525400db4df7
3.通过配置文件和命令行创建
以上面的配置文件为例,我们创建一个redis的配置的一个单独ConfigMap对象:
$ kubectl create configmap cm-demo2 --from-file=testcm/redis.conf
configmap "cm-demo2" created
$ kubectl get configmap cm-demo2 -o yaml
apiVersion: v1
data:redis.conf: |host=127.0.0.1port=6379
kind: ConfigMap
metadata:creationTimestamp: 2018-06-14T16:34:29Zname: cm-demo2namespace: defaultresourceVersion: "3110758"selfLink: /api/v1/namespaces/default/configmaps/cm-demo2uid: cf59675d-6ff0-11e8-a101-525400db4df7
我们可以看到一个关联redis.conf文件配置信息的ConfigMap对象创建成功了,另外值得注意的是–from-file这个参数可以使用多次,比如我们这里使用两次分别指定redis.conf和mysql.conf文件,就和直接指定整个目录是一样的效果了。
4.通过命令行的–from-literal进行创建
可以直接使用字符串进行创建,通过–from-literal参数传递配置信息,同样的,这个参数可以使用多次,格式如下:
$ kubectl create configmap cm-demo3 --from-literal=db.host=localhost --from-literal=db.port=3306
configmap "cm-demo3" created
$ kubectl get configmap cm-demo3 -o yaml
apiVersion: v1
data:db.host: localhostdb.port: "3306"
kind: ConfigMap
metadata:creationTimestamp: 2018-06-14T16:43:12Zname: cm-demo3namespace: defaultresourceVersion: "3111447"selfLink: /api/v1/namespaces/default/configmaps/cm-demo3uid: 06eeec7e-6ff2-11e8-a101-525400db4df7
5.如何在pod中使用?
ConfigMap这些配置数据可以通过很多种方式在Pod里使用,主要有以下几种方式:
- 设置环境变量的值
- 在容器里设置命令行参数
- 在数据卷里面创建config文件
(1)设置环境变量的值
apiVersion: v1
kind: Pod
metadata:name: testcm1-pod
spec:containers:- name: testcm1image: busyboxcommand: [ "/bin/sh", "-c", "env" ]env:- name: DB_HOSTvalueFrom:configMapKeyRef:name: cm-demo3key: db.host- name: DB_PORTvalueFrom:configMapKeyRef:name: cm-demo3key: db.portenvFrom:- configMapRef:name: cm-demo1
这个Pod运行后会输出如下几行:
$ kubectl logs testcm1-pod
......
DB_HOST=localhost
DB_PORT=3306
mysql.conf=host=127.0.0.1
port=3306
redis.conf=host=127.0.0.1
port=6379
......
我们可以看到DB_HOST和DB_PORT都已经正常输出了,另外的环境变量是因为我们这里直接把cm-demo1给注入进来了,所以把他们的整个键值给输出出来了,这也是符合预期的。
(2)在容器里设置命令行参数
ConfigMap也可以被用来设置容器中的命令或者参数值,如下Pod:
apiVersion: v1
kind: Pod
metadata:name: testcm2-pod
spec:containers:- name: testcm2image: busyboxcommand: [ "/bin/sh", "-c", "echo $(DB_HOST) $(DB_PORT)" ]env:- name: DB_HOSTvalueFrom:configMapKeyRef:name: cm-demo3key: db.host- name: DB_PORTvalueFrom:configMapKeyRef:name: cm-demo3key: db.port
运行这个Pod后会输出如下信息:
$ kubectl logs testcm2-pod
localhost 3306
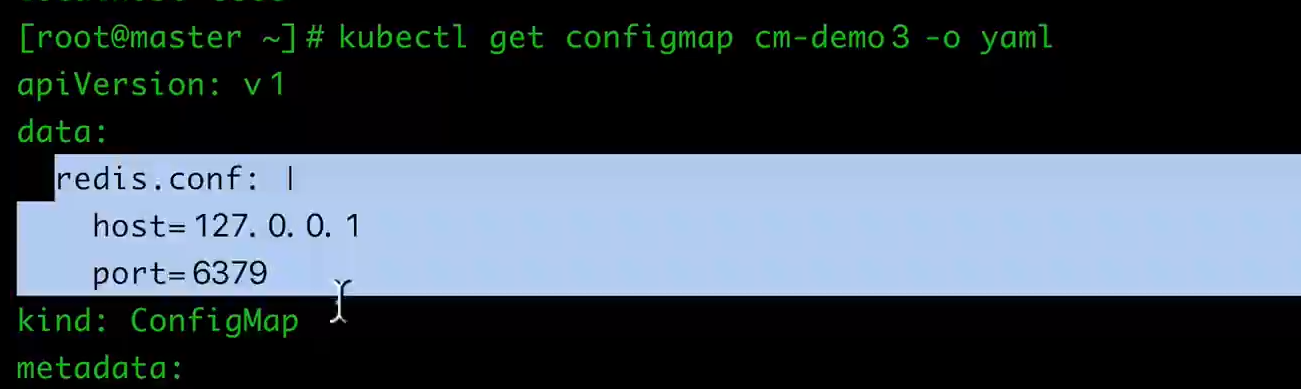
(3)在数据卷里面创建config文件
外一种是非常常见的使用ConfigMap的方式:通过数据卷使用,在数据卷里面使用ConfigMap,就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容:
apiVersion: v1
kind: Pod
metadata:name: testcm4-pod
spec:containers:- name: testcm4image: busyboxcommand: ["/bin/sh", "-c", "cat /etc/config/redis.conf"]volumeMounts:- name: config-volumemountPath: /etc/configvolumes:# 与volumeMounts.name保持一致- name: config-volumeconfigMap:name: cm-demo3
运行这个Pod的,查看日志:
$ kubectl logs testcm3-pod
host=127.0.0.1
port=6379
当然我们也可以在ConfigMap值被映射的数据卷里去控制路径,如下Pod定义:
apiVersion: v1
kind: Pod
metadata:name: testcm4-pod
spec:containers:- name: testcm4image: busyboxcommand: [ "/bin/sh","-c","cat /etc/config/path/to/msyql.conf" ]volumeMounts:- name: config-volumemountPath: /etc/configvolumes:- name: config-volumeconfigMap:name: cm-demo1items:- key: mysql.confpath: path/to/msyql.conf
运行这个Pod的,查看日志:
$ kubectl logs testcm4-pod
host=127.0.0.1
port=3306
另外需要注意的是,当ConfigMap以数据卷的形式挂载进Pod的时,这时更新ConfigMap(或删掉重建ConfigMap),Pod内挂载的配置信息会热更新。这时可以增加一些监测配置文件变更的脚本,然后reload对应服务。