前言
一个通用系统意味着更广泛的适用性,但通用的另一种解释是平庸,因为它无法在所有场景内都做到极致。
ClickHouse 在没有像三驾马车这样的指导性论文的背景下,通过针对特定场景的极致优化,获得闪电般的查询性能。
ClickHouse 是什么

官方定义:ClickHouse is a high-performance, column-oriented SQL database management system (DBMS) for online analytical processing (OLAP).
高性能的 OLAP 数据库管理系统。
ClickHouse 核心特性
完备的 DBMS 功能
能被称为 DBMS,那么就具有完备的数据库管理功能,如 DDL(数据定义语言),允许动态地创建、修改或删除数据库、表和视图;DML(数据操作语言),允许动态查询、插入、修改或删除数据。同时,还包括权限控制,可以按照用户粒度设置数据库或者表的操作权限。
列式存储
行式存储(Row-Oriented)面向 OLTP(Online Analytical Processing),每行数据存储在一起,可以快速地进行增删改操作,不适合聚合查询,因为 data scan 范围大。
列式存储(Column-Oriented)面向 OLAP(Online Transaction Processing),每一列数据作为单独的物理存储,分析查询时只需要读取相关的列即可。
ClickHouse 默认每一列对应一个 column_name.bin 数据文件。列式存储也为 ClickHouse 的数据压缩和向量化执行提供了便利。

数据压缩
数据压缩后,体积减小,可以减少网络带宽和磁盘 IO 的压力。同时,因为采用了数据列式存储,同一列数据相似度就会高,天然的具备压缩优势。

向量化执行
相比于传统火山模型中的 row-based 模式,向量化执行引擎采用 batch-based 批量处理模式,可以大幅减少函数调用开销、数据的 Cache Miss,提升 CPU 利用效率。同时也能使用 SIMD CPU 指令集,也就是向量化执行。
SIMD(单指令多数据流),即能够使用一个汇编指令处理多个数据,如下图
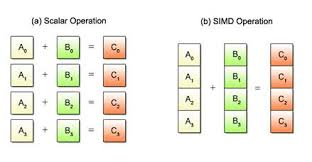
CPU 通过一些扩展指令集实现向量化执行,例如,在 intel 的处理器中,有以下扩展指令集:
-
SSE:这个指令集扩展了 8 个 128 位的寄存器,它们被命名为 XMM0 到 XMM7。后续的 SSE2,SSE3,SSE4 等版本在此基础上进行了扩展。
-
AVX:这个指令集扩展了 16 个 256 位的寄存器,它们被命名为 YMM0 到 YMM15。
-
AVX-512:这个指令集扩展了 32 个 512 位的寄存器,它们被命名为 ZMM0 到 ZMM31。
通过使用这些扩展指令集,我们可以一次将多个整数、字符、浮点数等多个数据加载到寄存器中,使用单条扩展汇编指令完成多个数据的批量处理后,再一次将寄存器中的值写回内存。
丰富的索引
通过 Partition、Part、Sparse-Primary-Key、skip-index、mark-range 等索引结构,ClickHouse 能够只读取 必要的列 的 必要的片段(granule),将 scan 粒度压缩到极致。
存储引擎
ClickHouse提供了丰富的存储引擎
外部表引擎
- File on FS
- S3
- HDFS
- MySQL
- Kafka
- … …
内部表引擎
- Memory
- Log
- StripeLog
- MergeTree family
尤其是 MergeTree 系列引擎,最基础的 MergeTree 引擎支持主键索引、数据分区、数据副本等能力,在其之上又有一系列的扩展特性。

特定场景的优化
specializations for special cases
字符串搜索(Substring Search)算法,如 C 中的 strstr、menmen,C++ 中的 std::search、std::find 等,但是通用意味着平庸,它们在特定场景下会很低效(slow in some usage scenario),拿 memmem 举例:
void * memmem(const void * haystack, size_t haystacklen, const void * needle, size_t needlelen)
memmem 的接口决定了其 代码可重入(reentrable)、无初始化例程(no separate initialization routine),这也是该算法成为标准库函数的理由——通用。
但是如果模式串(needle)只有一个,而文本串(haystack)有很多的情况下:
Searcher searcher(needle);
for (const auto & haystack : haystacks)searcher.search(haystack);
这种场景下使用 memmem 不是最优解,我们可以对 needle 做一些初始化例程(separate initialization routine)来获得更好的性能,例如 Boyer-Moore (BM)、Knuth-Morris-Pratt (KMP) 、Volnitsky 等算法就是这样做的,它们通过对模式串(needle)预先建立一系列规则来获得搜索加速。
单是字符串搜索(Substring Search)算法,就有非常多的场景:
- 精确搜索(exact search) / 近似搜索(approximate search)
- 一个模式串 / 多个模式串
- 长模式串 / 短模式串
- 模式串是字节 / unicode字符 / 单词集?
- 搜索是否在预定义的文本中进行,还是在未提前知道的文本中进行
- 文本是否完全存储在内存中(located in memory completely),还是作为数据流可用(a stream of data)
- 最坏情况时间复杂度的保证(with strong guarantees on time)
- … …
丰富的字符串搜索算法:
But none of these algorithms are used in ClickHouse.
ClickHouse 使用的:
- 当模式串是常量时,使用 Volnitsky 算法
- 当模式串是非常量时,使用 SIMD 加速的暴力搜索算法
- 当模式串是一组常量集合时,使用 Variation of Volnitsky 算法
- 正则表达式匹配时,使用 re2 和 hyperscan 库
- … …
同样的,排序(sorting)算法也是如此:
- 被排序元素类型是 number / tuple / string / structure
- 所有数据位于内存(available comletely in RAM)
- 基于比较(comparison) / 三向比较(3-way comparison) / 并行比较(parallel comparison) / 基数排序(by radix)
- 直接排序 / 间接排序(obtain a permutation)
- 稳定排序 / 非稳定排序(相同键值的相对顺序是否改变)
- full / partial / n-element
- … …
ClickHouse 使用了 pdqsort / radix sort 等
哈希表(Hash Table):
- 哈希函数的选择
- 小 key / 大 key
- 填充因子的选择
- 冲突解决算法的选择
- 元素是否支持移动语义
- 扩容后如何移动元素
- 使用位图快速探测
- 预取(prefetch)和批处理(batching)
- … …
关系模型与 SQL 查询
ClickHouse 使用关系模型以及 SQL 查询,使得其更容易理解和使用。同时,其 server 层支持 Mysql Client / ClickHouse Native TCP Client / HTTP Client 等方式接入,更加灵活易用。
MergeTree 引擎
ClickHouse 的 MergeTree 引擎支持重复 Sparse Primary Key 、partition 、skip index 等索引类型。
以下是 MergeTree 建表 DDL 以及 数据插入语句:
CREATE TABLE mt
(`EventDate` Date,`OrderID` Int32,`BannerID` UInt64,`GoalNum` Int8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventDate)
ORDER BY (OrderID, BannerID)INSERT INTO mt SELECTtoDate('2018-09-26'),number,number + 10000,number % 128
FROM numbers(1000000)INSERT INTO mt SELECTtoDate('2018-10-15'),number,number + 10000,number % 128
FROM numbers(1000000, 1000000)
每次写入数据(insert)会根据 分区键(PARTITION BY)在对应的 ClickHouse 数据目录下创建一个目录存储对应的数据,称之为 part,如
clickhouse-data/data/default/mt/201809_1_1_0/
clickhouse-data/data/default/mt/201810_2_2_0/
之所以不称为 partition,是因为新插入的 part 可能和之前的已经存在的 part 具有相同的分区键,但是真正的分区合并(Merge)并不会立即发生,而会在合适的时机在后台 Merge。因此,partition 是一个逻辑概念,一个 partition 包含多个 part。如果再次插入一个分区键同样为201810 的 part,就会新增一个数据目录,如下:
clickhouse-data/data/default/mt/201809_1_1_0/
clickhouse-data/data/default/mt/201810_2_2_0/
clickhouse-data/data/default/mt/201810_3_3_0/
此时 partition 201810 包含两个 part,可以使用以下语句立即合并 part
OPTIMIZE TABLE mt
合并后结果:
clickhouse-data/data/default/mt/201809_1_1_0/
clickhouse-data/data/default/mt/201810_2_2_0/
clickhouse-data/data/default/mt/201810_2_3_1/
clickhouse-data/data/default/mt/201810_3_3_0/
其中,part 201810_2_2_0 和 201810_3_3_0 被标记为无效,后续会被删除,scan 时会忽略
每个 part 中有以下信息:
- 每个字段对应的压缩数据列,如 BannerID.bin
- 分区信息,partition.dat 以及 分区级别的 minmax 索引,如 minmax_EventDate.idx
- 主键索引 primary.idx
- 维护主键索引和数据列对应关系的 mark 文件,如 BannerID.mrk(会根据是否压缩 / 数据文件的 compact / InMemory / Wide 格式改变后缀名)
$ tree 201809_1_1_0/
201809_1_1_0/
├── BannerID.bin
├── BannerID.cmrk2
├── checksums.txt
├── columns.txt
├── count.txt
├── default_compression_codec.txt
├── EventDate.bin
├── EventDate.cmrk2
├── GoalNum.bin
├── GoalNum.cmrk2
├── metadata_version.txt
├── minmax_EventDate.idx
├── OrderID.bin
├── OrderID.cmrk2
├── partition.dat
├── primary.cidx
└── serialization.json
每个 part 中的所有数据列都按照 Primary Key 排序。
Primary Key 为稀疏(Sparse)索引,默认间隔 8192 条记录生成一行索引数据,数据文件同样默认 8192 条数据作为一个 granule 并压缩为一个压缩块。主键索引和 granule 通过 mark 数据标记文件建立联系,mark 文件中记录了每个 granule 在压缩数据列的偏移位置。
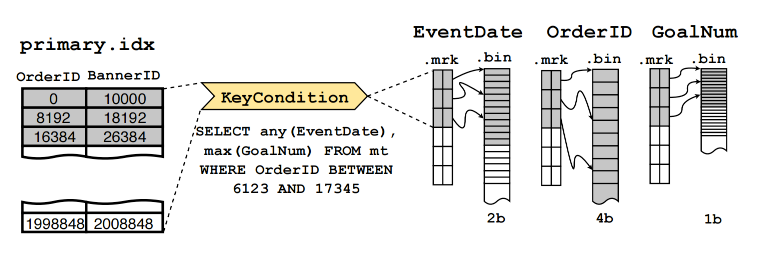
这样一来,通过分区索引、分区minmax索引、主键索引、二级索引、数据标记、压缩数据块等设计,ClickHouse 能够最小化 scan 成本。

ClickHouse 还支持多路径存储策略,将数据分布在不同的硬盘上,在此基础上,支持多线程读取压缩数据块,并尽可能将不同的硬盘分配给不同的线程,利用 RAID 技术提供更大的 IO 带宽。当一些线程提前完成读取任务时,还可以执行预分配给其他线程的任务(Threads can steal tasks)。
ClickHouse 分布式
如果单节点 ClickHouse 无法满足业务场景,那么就要考虑分布式多节点 ClickHouse。
在单机的场景下,表连接(Join)通常使用以下算法:
- Nested-Loop Join:这是最基本的连接算法,通过双层循环比较数据来获得结果。Nested-Loop Join 还包括一些优化版本,如 Index Nested-Loop Join 和 Block Nested-Loop Join。
- Hash Join:这种算法首先为一张表(通常是小表)建立一个哈希表,然后扫描另一张表(通常是大表),在哈希表中查找匹配的记录。Hash Join 在处理大数据量时通常比 Nested-Loop Join 更高效,但需要足够的内存来存储哈希表。
- Sort-Merge Join:这种算法首先将两张表按照连接键进行排序,然后顺序扫描两张表,找到匹配的记录。Sort-Merge Join 在处理大数据量且内存有限的情况下可能是一个好的选择,但它需要额外的排序步骤,可能会增加计算成本。
分布式场景下,通常使用以下策略(strategy): - Broadcast Join:在分布式环境中,如果一张表的数据量远小于另一张表,那么可以将小表广播到所有节点上,然后在每个节点上执行本地连接操作。只适合小集群或是小右表。
- Shuffle Join:当两张表的数据量都很大且无法广播时,可以使用 Shuffle Join。这种算法首先将两张表按照连接键进行分区,然后将相同连接键的数据发送到同一个节点上进行连接操作。
- Collocated join:在进行连接操作时,如果连接键上的数据已经在同一个节点上“共置”(collocated),那么可以在不需要跨节点移动大量数据的情况下执行连接,这可以显著提高查询性能。
ClickHouse 虽然是 MPP 架构,但是其查询执行策略中结合了 scatter/gather 的计算思想,CK 在 MergeTree 的基础上引入了 Distributed 引擎实现分布式,Distributed 是逻辑概念,数据首先被 scatter 分散到多个节点进行并行处理,然后将处理结果 gather 汇集到一个节点。这种架构非常适合可以并行且无需跨节点通信的计算任务。

但是,这种架构在 Gather 节点聚合数据时,可能会遇到性能瓶颈。另一个挑战是,由于数据需要跨节点重新分布,Scatter/Gather 架构并不适合实现真正的 shuffle join,而更倾向于使用 broadcast join。不过,在实际场景中,右表的数据需要先被 Gather 节点收集,然后再分发到各个节点,因此这并非是典型的 broadcast join 实现。同时,如果两个大表需要进行 join 操作,broadcast join 则会受到网络带宽和节点数量的限制。
Spark 使用的是 MapReduce 计算架构,在Spark中,执行过程被划分为多个阶段,每个阶段由一系列的 map 和 reduce 任务组成,这是一种类似于 MapReduce 的架构。当存在宽依赖(wide dependency),需要对数据进行重新分区(即 shuffle)时,就会形成一个新的阶段。在每个阶段结束时,Spark 都会将计算结果落盘,这样即使在后续的计算过程中发生了错误,也可以从这些持久化的结果中恢复,而不需要重新计算整个阶段。这种设计使得 Spark 的计算过程更加稳定,特别适合执行长时间运行的 ETL(Extract-Transform-Load)任务,但是不适合低延时的数据查询。
Doris 使用的是 MPP 架构支持数据混洗(shuffle),能够高效地完成表连接(quick joins)和高基数数据聚合(high-cardinality aggregations)
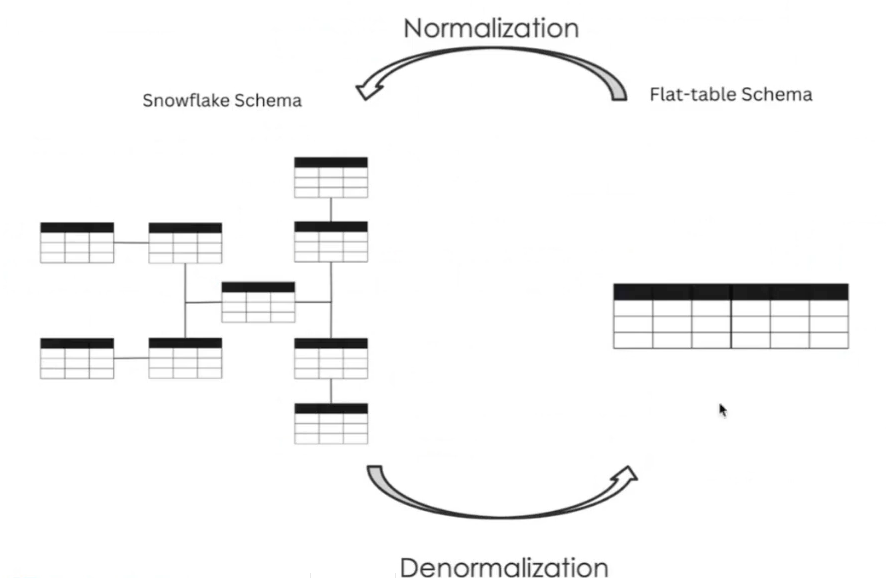
因此,在分布式 join 场景下,ClickHouse 的性能不如 Doris/ StarRocks 等引擎,ClickHouse 需要预先将雪花模式(Snowflake Schema)或是星型模式(Star Schema)转换为 宽表/平面表模式(Flat-table Schema),避免分布式 join 的性能瓶颈。
最佳实践
腾讯
腾讯游戏用户画像系统 / ClickHouse 实时数仓
- 微信海量多样化的业务形态,对数据分析提出了新的挑战。为了满足业务数据分析的需求,建设千台规模、数据 PB 级、批流一体的 ClickHouse 数据仓库,实现了 10 倍以上的性能提升。
字节跳动
用户增长分析平台 / 广告推送人群预估 / 推荐系统实时指标 / 用户分析平台 / 敏捷 BI 平台
- 推荐系统已有 T+1 离线 A/B 指标,但是算法研发通常需要实时反馈数据作为补充
携程
酒店数据智能平台
- 酒店数据智能平台从去年7月份试点,到现在80%以上的业务都已接入 ClickHouse。满足每天十多亿的数据更新和近百万次的数据查询,支撑 app 性能 98.3% 在 1秒内返回结果,pc端 98.5% 在 3 秒内返回结果。
微信 CK 实时数仓
面对的场景:
- 科学探索:服务于数据科学家,通过即席查询做业务上的归因推断。
- 看板:服务于运营和管理层,,展示所关注的核心指标。
- A/B 实验平台:服务于算法工程师,把新的模型,放在 A/B 实验平台上做假设检验,看模型是否符合预期。
除此以外,还有实时监控、日志系统明细查询等场景。

在所有的场景当中,使用者都有非常重要的诉求——快:希望查询响应更快,指标开发更快完成,看板更新更及时。与此同时,微信面临的是海量的数据,业务场景中“单表日增万亿”很常见,这就对下一代“数据分析系统”提出新的挑战。
在使用 ClickHouse 之前,微信使用的是 Hadoop 生态为主的数仓,存在以下这些问题:
1. 响应慢,基本上是分钟级,可能到小时,导致决策过程长;
2. 开发慢,由于传统的数仓理念的多层架构,使得更新一个指标的成本很高;
3. 架构臃肿,在微信业务体量规模的数据下,传统架构很难做到流批一体。进而导致,代码需要写多套、数据结果难以对齐、存储冗余。经过十几年的发展之后,传统的 Hadoop 生态的架构变得非常臃肿,维护难度和成本都很大。
所以,微信一直在寻求更轻量、简单敏捷的方案来解决这些问题。经过一番调研,在百花齐放的 OLAP 产品中,最终选定了 ClickHouse 作为微信 OLAP 的主要核心引擎。主要有两个原因:
1. 效率:在真实数据的实验场景下,ClickHouse 要比 Hadoop 生态快 10 倍以上(2020 年底测试);
2. 开源:微信的 A/B 实验、线上特征等场景会有些个性化需求,需要对引擎内核做较多改动;
因此,微信尝试在 OLAP 场景下,构建基于 ClickHouse 计算存储为核心的“批流一体”数仓。
但是,使用原生的 ClickHouse,在真正放量阶段出现了很多问题:
1. 稳定性:ClickHouse 的原始稳定性并不好,比如说:在高频写入的场景下经常会出现 too many part 等问题,整个集群被一个慢查询拖死,节点 OOM、DDL 请求卡死都比较常见。另外,由于 ClickHouse 原始设计缺陷,随数据增长的依赖的 zookeeper 瓶颈一直存在,无法很好解决;微信后期进行多次内核改动,才使得它在海量数据下逐步稳定下来,部分 issue 也贡献给了社区。
2. 使用门槛较高:会用 ClickHouse 的,跟不会用 ClickHouse 的,其搭建的系统业务性能可能要差 3 倍甚至 10 倍,有些场景更需要针对性对内核优化。
腾讯 CK OLAP 的生态
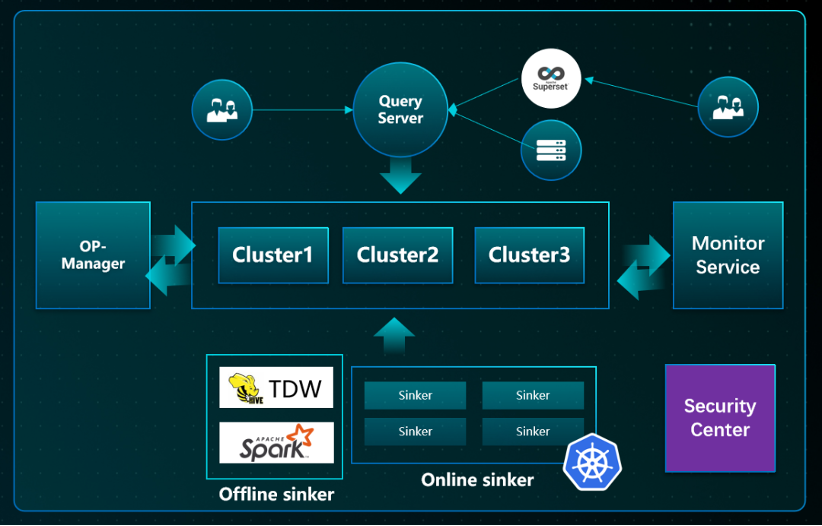
要想比较好地解决 ClickHouse 易用性和稳定性,需要生态支撑,整体的生态方案有以下几个重要的部分:
- QueryServer:数据网关,负责智能缓存,大查询拦截,限流;
- Sinker:离线 / 在线高性能接入层,负责削峰(令牌 / 反压)、hash 路由,流量优先级,写入控频;
- OP-Manager:负责集群管理、数据均衡,容灾切换、数据迁移;
- Monitor:负责监控报警,亚健康检测,查询健康度分析,可与 Manager 联动;
 1. 高性能接入:微信的吞吐达到了十亿级别,实时接入方面,通过令牌、反压的方案,比较好地解决了流量洪峰的问题。另外通过 Hash 路由接入,使数据落地了之后可直接做 Join,无需 shuffle 实现的更快 Join 查询,在接入上也实现了精确一次。离线同步方案上,微信跟大多数业界的做法基本上一致,在通过预构 Merge 建成 Part,再送到线上的服务节点,这其实是种读写分离的思想,更便于满足高一致性、高吞吐的场景要求。
1. 高性能接入:微信的吞吐达到了十亿级别,实时接入方面,通过令牌、反压的方案,比较好地解决了流量洪峰的问题。另外通过 Hash 路由接入,使数据落地了之后可直接做 Join,无需 shuffle 实现的更快 Join 查询,在接入上也实现了精确一次。离线同步方案上,微信跟大多数业界的做法基本上一致,在通过预构 Merge 建成 Part,再送到线上的服务节点,这其实是种读写分离的思想,更便于满足高一致性、高吞吐的场景要求。

2. 极致的查询优化:ClickHouse 整个的设计哲学,要求在特定的场景下,采用特定的语法,才能得到最极致的性能。为解决 ClickHouse 使用门槛高的问题,微信把相应的优化经验落地到内部 BI 平台上,沉淀到平台后,使得小白用户都可以方便使用 ClickHouse。通过一系列优化手段,在直播、视频号等多个 Case 实现 10 倍以上性能提升。

3.A/B 实验平台:早期做 A/B 实验的时候,前一天晚上要把所有的实验统计结果,预先聚合好,第二天才能查询实验结果。在单表数据量级千亿 / 天、大表实时 Join 的场景下,微信前后经历了几个方案,实现了近 50 倍的性能提升。从离线到实时分析的飞跃,使得 P95 响应<3S,A/B 实验结论更加准确,实验周期更短 ,模型验证更快。

4.实时特征计算:虽然大家普遍认为 ClickHouse 不太擅长解决实时相关的问题,但最终通过优化,可以做到扫描量数十亿,全链路时延 < 3 秒,P95 响应近 1 秒。
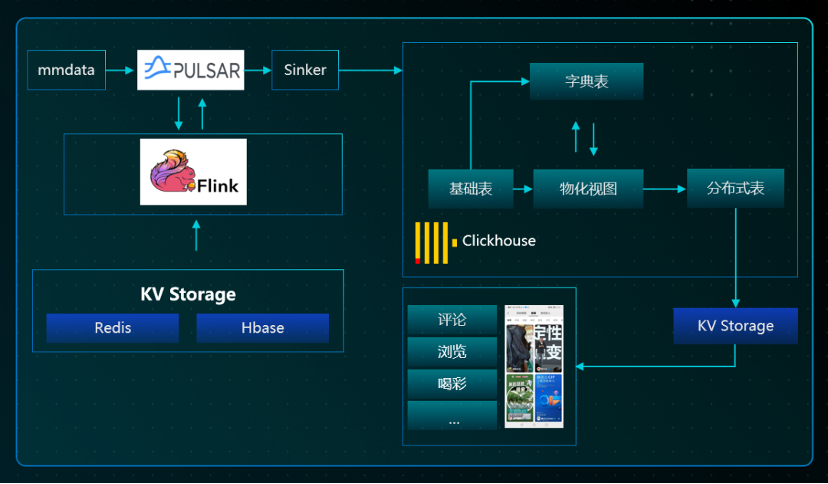
总结
- ClickHouse 通常用于秒级查询时长的交互式指标分析场景,包括 BI 分析、数据科学、A/B 实验 等
- 由于 ClickHouse 开源,可以根据业务做一些深入的适应性改造开发
- 随着集群规模扩大,运维成本提高,业界通常会开发对应的运维平台
- 日常运维界面化 / 程序化
- 关键指标监控 / 报警
- 诊断帮助问题分析
注意事项
- 使用物化视图来作为 cache / 快照,空间换时间,实现预聚合 / 高效查询
- 减少频繁少量的数据插入,每次 insert 插入至少会创建一个 part 目录
- 选择低基数(Low Cardinality)分区键,分区太多,可能会导致耗尽 inode
- 合理设计分区索引、主键索引、二级索引(skip-index),减少 scan 面积
- 避免分布式 join,数据源设计为大宽表 Flat-Table schema
- 减少扩缩容操作,会导致数据倾斜
- Native 实现如果有计算密集的场景,适当考虑 SIMD 实现
- 没有把握的情况下避免指明 prewhere,CK 做的谓词下推(predicate pushdown)很可能更优(自动选择 size 最小的 column / 自动选择合适数量的column)
- RAID,多路径存储,将数据分散到不同硬盘,多线程读取不同硬盘,获得更大 IO 带宽
- 压缩策略的选择,lz4 / zstd,压缩比和解压缩时间平衡
- 共置连接(collocate join),通过分析固定的查询模式,确定数据分布策略、分区方案和分片键的选择
- 关闭 swap 交换空间
TODO
ClickHouse 还有很多重要的 feature ,例如 固定查询下的物化视图、TwoLevel 的 Aggregation、batch-based 的 Pipeline 等内容。
Reference
- ClickHouse Document
- clickhouse-presentations/meetup41/merge_tree
- presentations.clickhouse.com/bdtc_2019
- ClickHouse 源码解析: 综述
- ClickHouse Join为什么被大家诟病?
- Why ClickHouse Cannot Keep Up
- ClickHouse之聚合功能源码分析