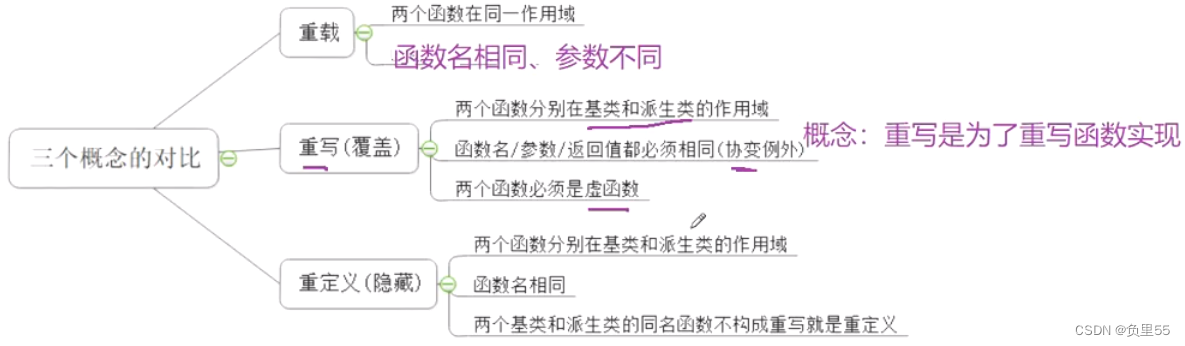
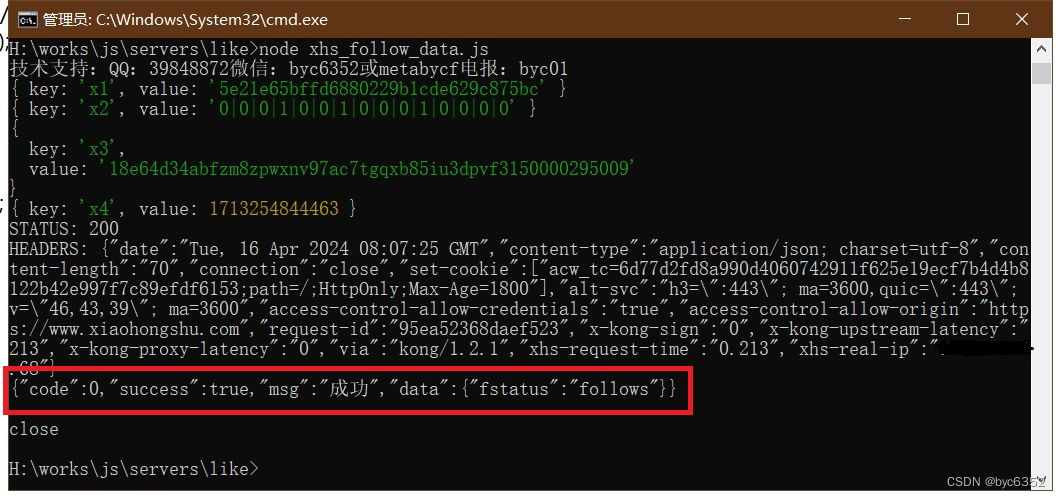
数据分析流程
数据分析开发流程一般分为下面5个阶段,主要包含:数据采集、数据处理、数据建模、数据分析、数据可视化
数据采集: 数据通常来自于企业内部或外部,企业内部数据可以直接从系统获得,外部数据则需要购买,或者通过爬虫等数据采集工具采集;
数据处理: 获取到的数据往往会包含一些干扰数据、不完整数据,因此一般需要对数据做相应的处理;
数据建模: 不同的业务对数据的需求不同,根据相关业务或战略需求建立相应的数据模型,有针对性进行主题分析;
数据分析: 根据模型中要分析或计算的指标,采用相应的分析方法进行数据分析,得出目标分析结果;
数据可视化: 将数据分析结果进行可视化展示,使其更加方便业务人员或决策者理解
1、数据采集
数据的来源主要分为两大类,企业 外部来源 和 内部来源。
外部来源 :外包购买、网路爬取、免费开源数据等;
内部来源:销售数据、社交通信数据、考勤数据、财务数据、服务器日志数据等;
2、数据处理
数据清洗
数据清洗(data cleaning) :是通过填补缺失值、光滑噪声数据,平滑或删除离群点,纠正数据的不一致来达到清洗的目的。
数据清洗是一项繁重的任务,需要根据数据的准确性、完整性、一致性、时效性、可信性和解释性来考察数据,从而得到标准的、干净的、连续的数据。
缺失值处理
删除变量: 若变量的缺失率较高(大于80%)覆盖率较低,且重要性较低可以直接将变量删除;
统计量填充: 若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况用基本统计量填充(最大值、最小值、均值、中位数、众数)进行填充;
插值法填充: 包括随机插值、多重差补法、热平台插补、拉格朗日插值、牛顿插值等;
模型填充: 使用回归、贝叶斯、随机森林、决策树等模型对缺失数据进行预测;
哑变量填充: 若变量是离散型,且不同值较少,可转换成哑变量(通常取值0或1);
总结来看,常用的做法是:先用Python中的pandas.isnull.sum() 检测出变量的缺失比例,考虑删除或者填充,若需要填充的变量是连续型,一般采用均值法和随机差值进行填充,若变量是离散型,通常采用中位数或哑变量进行填充。
噪声处理
噪声(noise) 是被测量变量的随机误差或方差,是观测点和真实点之间的误差。
分箱法: 对数据进行分箱操作,等频或等宽分箱,然后用每个箱的平均数,中位数或者边界值(不同数据分布,处理方法不同)代替箱中所有的数,起到平滑数据的作用;
回归法: 建立该变量和预测变量的回归模型,根据回归系数和预测变量,反解出自变量的近似值
离群点处理
异常值(离群点)是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。异常分为两种:“伪异常”,由于特定的业务运营动作产生,是正常反应业务的状态,而不是数据本身的异常;“真异常”,不是由于特定的业务运营动作产生,而是数据本身分布异常,即离群点。主要有以下检测离群点的方法:
简单统计分析:根据箱线图、各分位点判断是否存在异常,例如Python中pandas的describe函数可以快速发现异常值。
基于绝对离差中位数(MAD):这是一种稳健对抗离群数据的距离值方法,采用计算各观测值与平均值的距离总和的方法。放大了离群值的影响。
基于距离: 通过定义对象之间的临近性度量,根据距离判断异常对象是否远离其他对象,缺点是计算复杂度较高,不适用于大数据集和存在不同密度区域的数据集
基于密度: 离群点的局部密度显著低于大部分近邻点,适用于非均匀的数据集
基于聚类: 利用聚类算法,丢弃远离其他簇的小簇。
数据集成
多个数据源集成时会遇到的问题:实体识别问题、冗余问题、数据值的冲突和处理。
1. 实体识别问题
匹配来自多个不同信息源的现实世界实体,数据分析者或计算机如何将两个不同数据库中的不同字段名指向同一实体,通常会通过数据库或数据仓库中的元数据(关于数据的数据)来解决这个问题,避免模式集成时产生的错误。
2. 冗余问题
如果一个属性能由另一个或另一组属性“导出”,则此属性可能是冗余的。属性或维度命名的不一致也可能导致数据集中的冗余。 常用的冗余相关分析方法有皮尔逊积距系数、卡方检验、数值属性的协方差等。
3. 数据值的冲突和处理
不同数据源,在统一合并时,保持规范化,去重
数据规约
数据变换
数据变换包括对数据进行规范化,离散化,稀疏化处理,达到适用于挖掘的目的。
1. 规范化处理
数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,如[-1,1]区间,或[0,1]区间,便于进行综合分析。
2. 离散化处理
数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或优化的方法。
3. 稀疏化处理
针对离散型且标称变量,无法进行有序的LabelEncoder时,通常考虑将变量做0,1哑变量的稀疏化处理,稀疏化处理既有利于模型快速收敛,又能提升模型的抗噪能力。
3、数据建模
常用数据分析模型,主要包括:对比分析、漏斗分析、留存分析、A/B测试、用户行为路径分析、用户分群、用户画像分析等。
用户画像
用户画像分析是基于自动标签系统将用户完整的画像描绘清晰。
常用的画像标签类别有:基本属性、心理特征、兴趣爱好、购买能力、行为特征、社交网络等。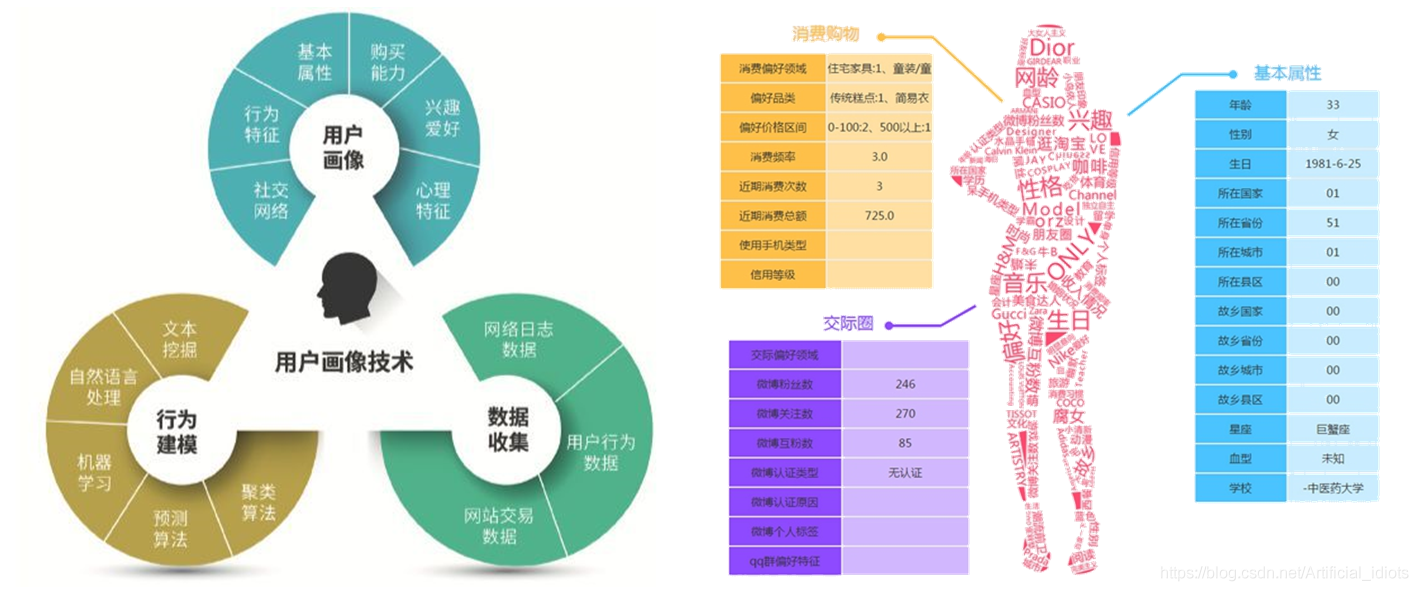
4、数据分析
常用数据分析方法:描述统计、假设检验、信度分析、相关分析、方差分析、回归分析、聚类分析、判别分析、主成分分析、因子分析、时间序列分析等。
回归分析
回归分析研究的是因变量和自变量之间的定量关系,运用十分广泛,可以用于房价预测、销售额度预测、贷款额度预测等。常见的回归分析有线性回归、非线性回归、有序回归、岭回归、加权回归等。
线性回归(Linear regression) :是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
一元线性回归分析: 只有一个自变量X与因变量Y有关,X与Y都必须是连续型变量,因变量y或其残差必须服从正态分布。
多元线性回归分析:分析多个自变量与因变量Y的关系,X与Y都必须是连续型变量,因变量y或其残差必须服从正态分布 。
Logistic回归分析:Logistic回归模型对因变量的分布没有要求,一般用于因变量是离散时的情况。Logistic回归分为条件Logistic回归和非条件Logistic回归,条件Logistic回归模型和非条件Logistic回归模型的区别在于参数的估计是否用到了条件概率。
回归分析与相关分析的联系:
相关分析是回归分析的基础和前提。假若对所研究的客观现象不进行相关分析,直接作回归分析,则这样建立的回归方程往往没有实际意义。只有通过相关分析,确定客观现象之间确实存在数量上的依存关系,而且其关系值又不确定的条件下,再进行回归分析,在此基础上建立回归方程才有实际意义。
回归分析是相关分析的深入和继续。对所研究现象只作相关分析,仅说明现象之间具有密切的相关关系是不够的,统计上研究现象之间具有相关关系的目的,就是要通过回归分析,将具有依存关系的变量间的不确定的数量关系加以确定,然后由已知自变量值推算未知因变量的值,只有这样,相关分析才具有实际意义。
回归分析侧重于研究随机变量间的依赖关系,以便用一个变量去预测另一个变量;相关分析侧重于发现随机变量间的种种相关特性。
5、数据可视化
常见数据可视化图表
常见数据可视化图表有:柱状图、折线图、饼图、散点图、雷达图、箱型图、气泡图、词频图、桑基图、热力图、关系图、漏斗图等。