一、概述
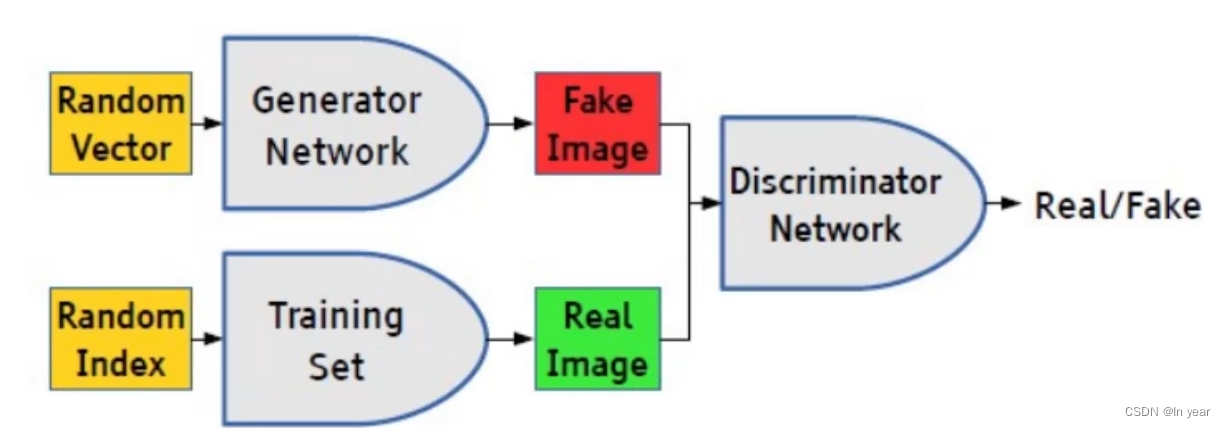
对抗生成网络(GAN)是一种深度学习模型,由两个神经网络组成:生成器G和判别器D。这两个网络被训练来协同工作,以生成接近真实数据的新样本。
生成器的任务是接收一个随机噪声向量,并将其转换为与真实数据相似的假样本。而判别器则尝试区分生成器生成的假样本和真实数据之间的区别。通过训练,生成器不断优化以生成更逼真的假样本,而判别器也不断优化以更好地区分真假样本。
在训练过程中,生成器和判别器之间形成了一种对抗关系:生成器努力欺骗判别器,而判别器努力识别生成器生成的假样本。这种对抗性的竞争推动了两个网络的同时学习和提升,最终使得生成器能够生成高质量的假样本。
GAN 在许多领域都有广泛的应用,包括图像生成、图像修复、图像超分辨率、语音合成等。GAN 的成功在于其能够学习数据的分布,并生成与真实数据相似的样本,而不需要显式地建模数据的概率分布。
二、基本原理
1.生成器:
输入n维向量,通过生成器神经网络生成所需要的结果。
2.判别器:
二分类网络,判别数据的真假,,将真实的判断为真,生成的判断为假。
3.训练:
- 初始化判别器D的参数 θ d θ_d θd 和生成器G的参数 θ g θ_g θg
- 从真实样本中采用m个样本 { x 1 , x 2 , … x m } \{x^1,x^2,\ldots x^m\} {x1,x2,…xm},从先验分布噪声中采样m个噪声样本 { z 1 , z 2 , … z m } \{z^1,z^2,\ldots z^m\} {z1,z2,…zm},并通过生成器获取m个生成样本 { t i l d e x 1 , x ~ 2 , … , x ~ m } \{tilde{x}^1,\tilde{x}^2,\ldots,\tilde{x}^m\text{ }\} {tildex1,x~2,…,x~m }。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本。
- 循环k次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽可能使判别器判别错误。
- 多次更新迭代之后,最终理想情况是使得判别器判别不出样本是来自于生成器的输出还是真实的输出。即最终样本判别概率均为0.5。
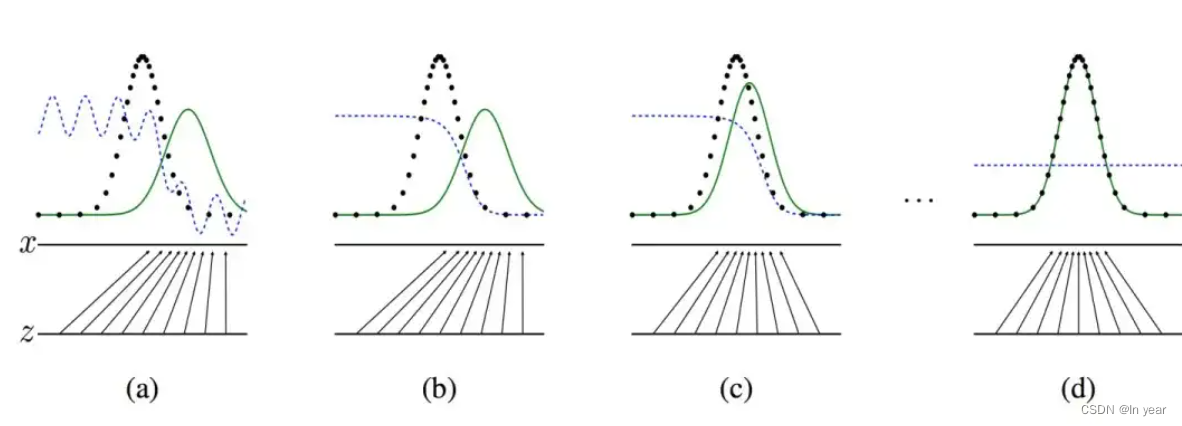
- 黑色点线为训练集数据分布曲线
- 蓝色点线为判别器输出的分布曲线
- 绿色实线为生成器输出的分布曲线
三、损失函数
l o s s ( o , t ) = − 1 / n ∑ ( t [ i ] ∗ l o g ( o [ i ] ) + ( 1 − t [ i ] ) ∗ l o g ( 1 − o [ i ] ) ) loss(o,t)=-1/n\sum(t[i]*log(o[i])+(1-t[i])*log(1-o[i])) loss(o,t)=−1/n∑(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))
- t[i] :概率值
- log(o[i]) :对数值
四、应用实例
1.数据增强:
GAN网络通过学习训练集样本的分布,然后进行采样生成新的样本。
2.风格迁移:
将一张图片的style迁移到另一张图片上。
3.图像生成和合成:
GAN 可以生成逼真的图像,这在艺术、设计和娱乐行业中具有广泛的应用。例如,可以使用 GAN 生成艺术作品、虚拟场景、虚拟人物等。
4.图像编辑和修复:
GAN 可以用于图像编辑和修复,例如图像超分辨率、去雨滴、去水印、填充缺失区域等。
5.图像风格转换:
GAN 可以将图像从一种风格转换为另一种风格,例如将素描转换为彩色图像,将照片转换为油画效果等。
6.视频生成和编辑:
GAN 可以生成逼真的视频序列,也可以用于视频编辑和合成,例如视频修复、视频插帧等。
7.语音合成和转换:
GAN 可以用于语音合成和转换,例如从文本生成语音、改变语音的说话风格等。
8.医学影像处理:
GAN 可以用于医学影像的分割、重建和增强,帮助医生进行诊断和治疗。
9.虚拟现实和增强现实:
GAN 可以用于创建逼真的虚拟场景和角色,用于虚拟现实和增强现实应用中。
10.数据增强和样本生成:
GAN 可以用于数据增强,帮助训练深度学习模型,也可以用于生成合成数据,用于模型测试和评估。