一、信息增益(Information Gain)
决定使用什么特征来划分一个节点取决于什么样的特征选择最能减少熵(也就是使纯度最大化)
在决策树中,熵的减少被称为信息增益。
所以如何选择呢?
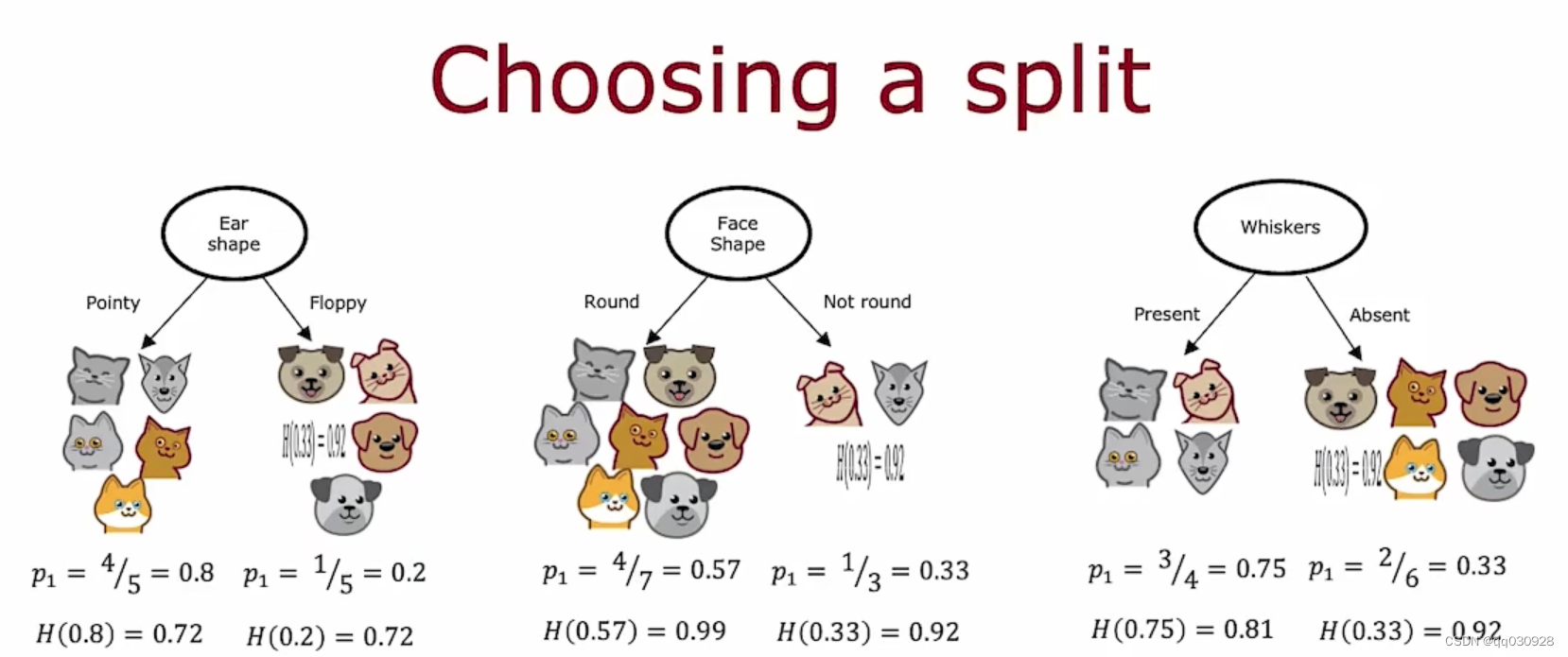
假设现在有三个特征可以选择,那每个特征会产生两个熵,如何去选择最适合的呢?
不能只看一个熵,所以要对两个熵一起操作。
计算过程:
1. 计算两个熵的加权平均数
2. 计算根节点的熵
3. 计算加权平均数与熵的差(这个值就是信息增益)
衡量的是减少的熵。
当特征不止有3个值来划分的时候(比如脸不再是只有round, pointy,而是多了一个oval),这个时候要怎么办?我们用one-hot(独热编码)来解决。
二、One-hot(独热编码)
如果一个特征能有k个值来分类,也就是说一个类别可以分出k种可能,那我们会创建k个二元特征(每个特征的取值只能是0或1)
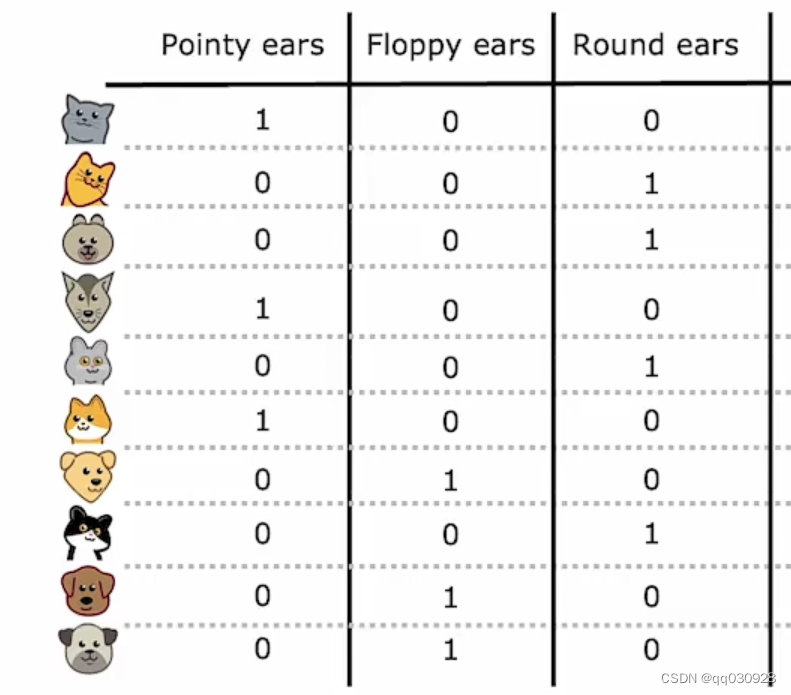
比如这里,因为ears可以分为3种,point,floppy 和round,所以在这里变成了三个特征值,作为单独的特征。但是注意,这里是离散值的时候。如果特征能取的不只是离散值,而是任意值(连续值)呢?
其实就是要找到一个阈值,去把该特征给分开,但是这个阈值怎么找?本质上也是要通过信息增益来看(选最高信息增益的)
三、回归树
因为原来的决策树是通过输入去判断种类,而回归是是通过输入去预测值,比如预测猫的体重这些具体的数值,那如果使用回归树的话,树的构建有什么不同?
其实就是在计算信息增益那里修改一下,不比较熵,把熵换成样本方差,然后使用同样的计算公式,一直找到使方差减少最大的特征。
四、集成树(Tree ensembles)
使用单一决策树会导致它对数据中的微小变化高度敏感。如何提高模型的robustness呢?就要通过构建很多决策树而不是单个决策树。
五、随机森林算法
使用有放回抽样将原有数据集生成多个样本集,训练每个决策树。
六、XGBoost模型
其实就是比起随机森林来说,它是把那些它分类错误的例子单独抽出来,继续去循环训练,可以理解为反复做错题,去训练那些原本做得不好的决策树,训练好之后再拿去放到集合里。
它的优点还在于它内置了正则化,防止过拟合。
决策树和集成树都很适合处理表格类的结构化的数据,不适用于非结构化的。
而且它们的训练速度很快。