1. 整体流程
第一步,加载视频/图片和音频/tts。用melspectrogram将wav文件拆分成mel_chunks。
第二步,调用face_detect模型,给出人脸检测结果(可以改造成从文件中读取),包装成4个数组batch:img_batch(人脸),mel_batch(语音),frame_batch(原图),coords_batch(坐标)
第三步,加载模型,进行计算。这个模型目前看下来就是简单的resnet,没有transfomer。另外mask也不是用分割模型,而是直接将图片下半部分全部作为mask😄,然后将mask图片拼接到原图片的色彩通道上作为输入。
第四步:预测出来的人脸拼接到原图上,输出位视频。
2. 优缺点
优点:极其简单,一个人脸检测模型+一个基于CNN的lipsync模型,速度很快。
缺点:嘴唇经常是歪的,而且有变形;牙齿不断在闪烁。经过图像增强后,我们取出截图如下:

3. 其他版本
3.1 Easy_Wav2Lip
这个版本相当好用。首先执行python install.py来下载模型文件。然后配置一下config.ini,执行python run.py即可。
生成配置文件的代码可以在目录下的Easy_Wav2Lip_v8.3.ipynb中来修改;也可以通过执行python GUI.py打开图形界面来修改:
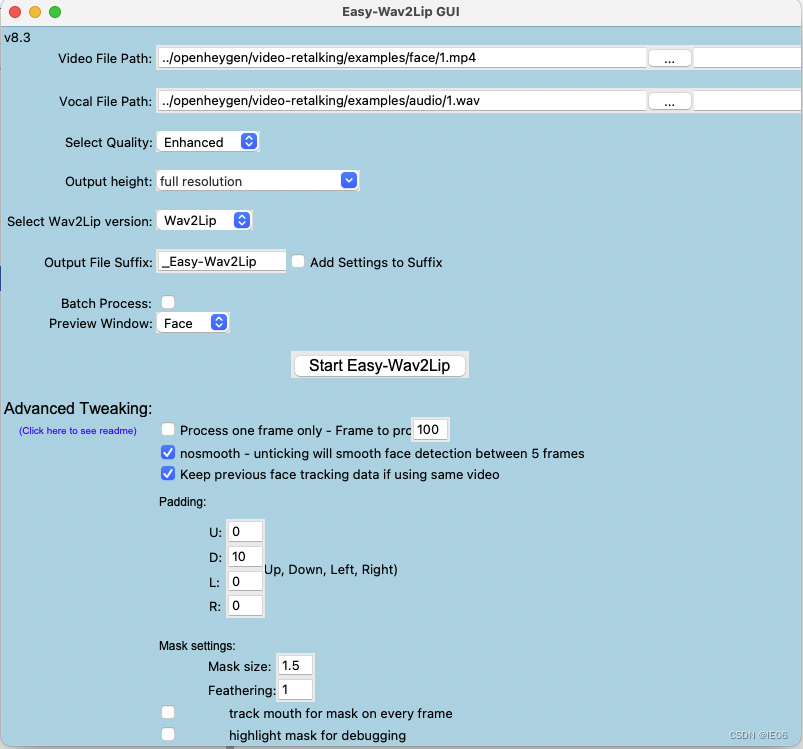
执行代码的入口仍然是inference.py。这里说明一下分支内容:
- 基础人脸检测模型为RetinaFace,模型文件为checkpoints/mobilenet.pth。
- 如果使用Imporved模式,会调用load_sr()方法加载sr_model(gfpgan做super resolution,参数文件);如果使用Enhanced,会进行upscale。
- 如果mouth_tracking为true,则会调用复杂一些的create_tracked_mask;否则仅启用create_mask