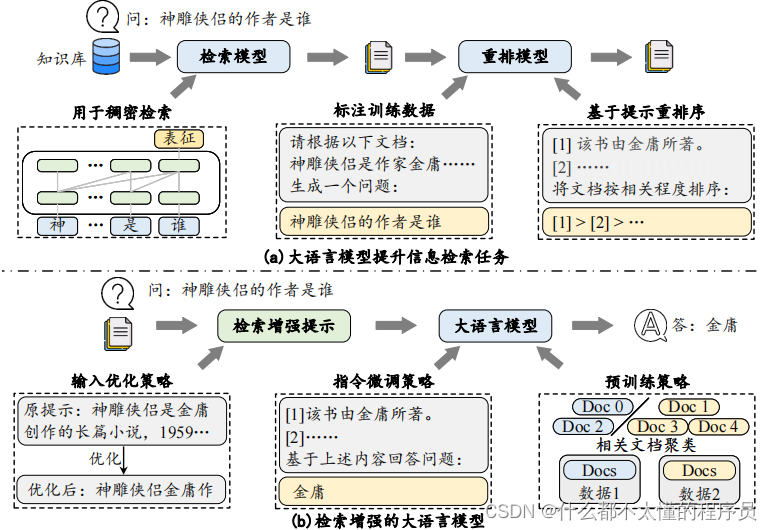
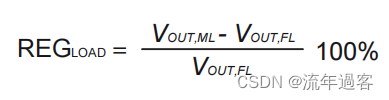NumPy简单学习(需要结合书本:Python数据分析与应用)
文章目录
- NumPy简单学习(需要结合书本:Python数据分析与应用)
- 前言
- 导库:
- 一、大概内容
- 1.掌握NumPy数组对象ndarray
- (1)创建数组对象
- (2)生成随机数
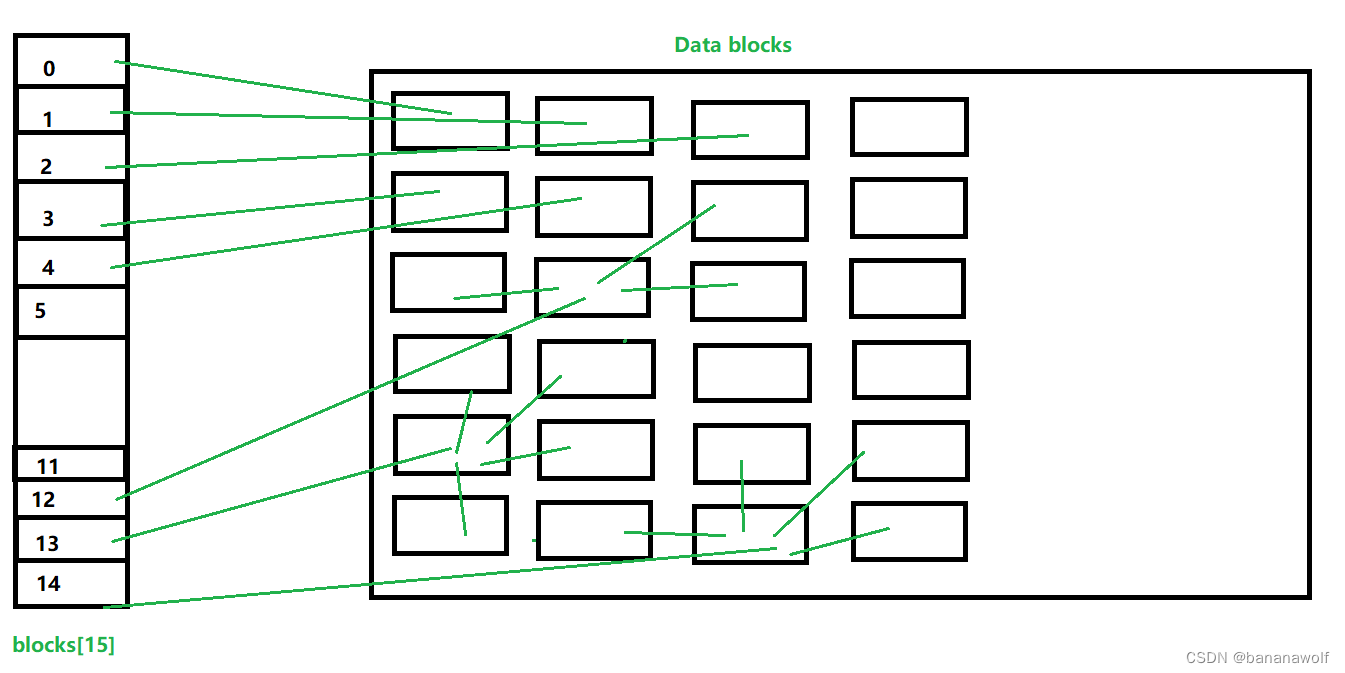
- (3)通过索引访问数组
- (4)变换数组的形态(广播)
- 2.掌握矩阵和通用函数
- (1)创建矩阵
- (2)ufunc函数
- 3.使用NumPy进行统计分析
- (1)读/写文件
- (2)使用函数进行简单的统计分析
- 二、案例:读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行统计分析。
- 1. 案例介绍
- 2. 使用了什么技术
- (1)鸢尾花(Iris)数据集
- (2)累计和:会显示计算的中间结果
- 3. 完整代码与分析
- 4. 结果示意图
- 补充:iris_sepal_length.csv文件展示
- 三、思考
- 总结
前言
需要之后来填坑😓😓😓
导库:
import numpy as np
提示:以下是本篇文章正文内容:
一、大概内容
1.掌握NumPy数组对象ndarray
(1)创建数组对象
(2)生成随机数
(3)通过索引访问数组
(4)变换数组的形态(广播)
2.掌握矩阵和通用函数
(1)创建矩阵
(2)ufunc函数
3.使用NumPy进行统计分析
(1)读/写文件
(2)使用函数进行简单的统计分析
二、案例:读取iris数据集中的花萼长度数据(已保存为csv格式),并对其进行统计分析。
1. 案例介绍
简单使用numpy
2. 使用了什么技术
(1)鸢尾花(Iris)数据集
鸢尾花(Iris)数据集是一个经典的机器学习数据集,
包含了三个不同种类(山鸢尾、变色鸢尾、维吉尼亚鸢尾)共150个样本,(150行)
每个样本包含了四个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)
(2)累计和:会显示计算的中间结果
3. 完整代码与分析
iris_sepal_length = np.loadtxt("../data/iris_sepal_length.csv",delimiter=",") #读取文件
print('花萼长度表为:',iris_sepal_length)iris_sepal_length.sort() #对数据进行排序
print('排序后的花萼长度表为:',iris_sepal_length)#去除重复值
print('去重后的花萼长度表为:',np.unique(iris_sepal_length))print('花萼长度表的总和为:',np.sum(iris_sepal_length)) #计算数组总和#计算所有元素的累计和
print('花萼长度表的累计和为:',np.cumsum(iris_sepal_length))print('花萼长度表的均值为:',np.mean(iris_sepal_length)) #计算数组均值#计算数组标准差
print('花萼长度表的标准差为:',np.std(iris_sepal_length))print('花萼长度表的方差为:',np.var(iris_sepal_length)) #计算数组方差
print('花萼长度表的最小值为:',np.min(iris_sepal_length)) #计算最小值
print('花萼长度表的最大值为:',np.max(iris_sepal_length)) #计算最大值
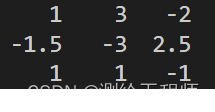
4. 结果示意图

sum 和 cumsum的最后结果是一样的:876.5

补充:iris_sepal_length.csv文件展示

三、思考
1.numpy通常在案例中是如何使用的,用来做什么???
2.numpy的作用???
是一个高效的多维数据容器,用于处理大型矩阵。
使用numpy可以快速整合各种数据。
3.如何使用numpy整合数据,常见的使用方法???
4.numpy缺点?
数据分析功能差,主要用于数组计算,我们要使用pandas数据处理工具来改善。
5.numpy如何和pandas一起使用,如何使用效果更好???
总结
提示:这里对文章进行总结:
💕💕💕