Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,关注+收藏,欢迎欢迎~~
💥个人主页:小羊在奋斗
💥所属专栏:C语言
本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为同样是初学者的学友展示一些我的学习过程及心得。文笔、排版拙劣,望见谅。
1、调试
2、Debug 和 Release
3、VS调试快捷键
4、监视和内存观察
5、调试举例
6、编程常见错误
1、调试
当我们发现写的程序中存在问题(bug)的时候,接下来就要找到问题并修复,这个过程就叫调试(debug)。调试一个程序,首先要承认出现了问题,然后通过手段定位问题的位置,可以是逐过程的调试,也可以屏蔽部分代码等,找到问题所在的位置,然后确定产生问题的原因,再修改代码重新测试。
调试是一个强大的功能,有时候我们百思不得其解的问题,通过调试就能一目了然,很快的找出问题所在。另外,有些问题就算我们想破脑袋都想不出个所以然来,只能通过调试来知道其内部原因。
2、Debug 和 Release

在VS上,能看到有 Debug 和 Release 两个选项,分别是什么意思呢?
Debug 称为调试版本,它包好调试信息,并且不作任何优化,便于程序员调试程序;
Release 称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户更好的使用。Release 版本是不包含调试信息的。
3、VS调试快捷键
在VS中,有很多的调试快捷键便于程序员调试代码,很大提高了调试效率。
3.1环境准备
首先,我们得设在 Debug 环境下。
3.2调试快捷键
F9:创建断点和取消断点;
断点的作用是:在程序的任意位置设置断点使得程序执行到想要的位置暂停执行,再使用F10和F11快捷键观察代码的执行细节;
条件断点:断点还可以设置条件,满足这个条件才会出发断点;
F5:启动调试,经常用来直接跳到下一个断点处,一般是和F9配合使用;
F10:逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句;
F11:逐语句,就是每次都只执行一条语句,在函数调用的地方可以进入函数内部;
CTRL + F5: 开始执行不调试。
4、监视和内存观察
我们在调试的过程中,如果想要观察代码执行过程中变量值的变化,有哪些办法呢?这些观察的前提条件是在开始调试后观察。
4.1监视
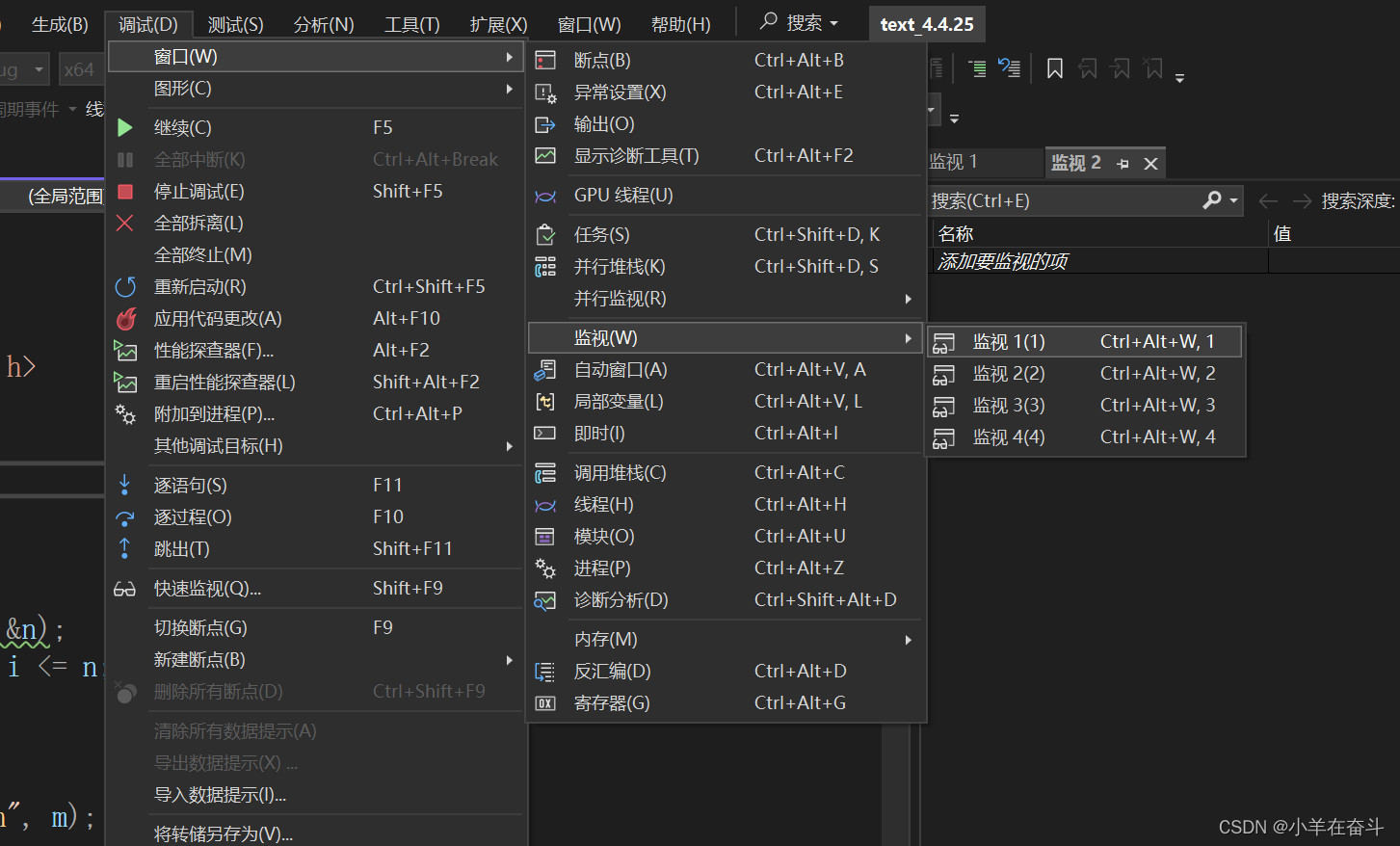
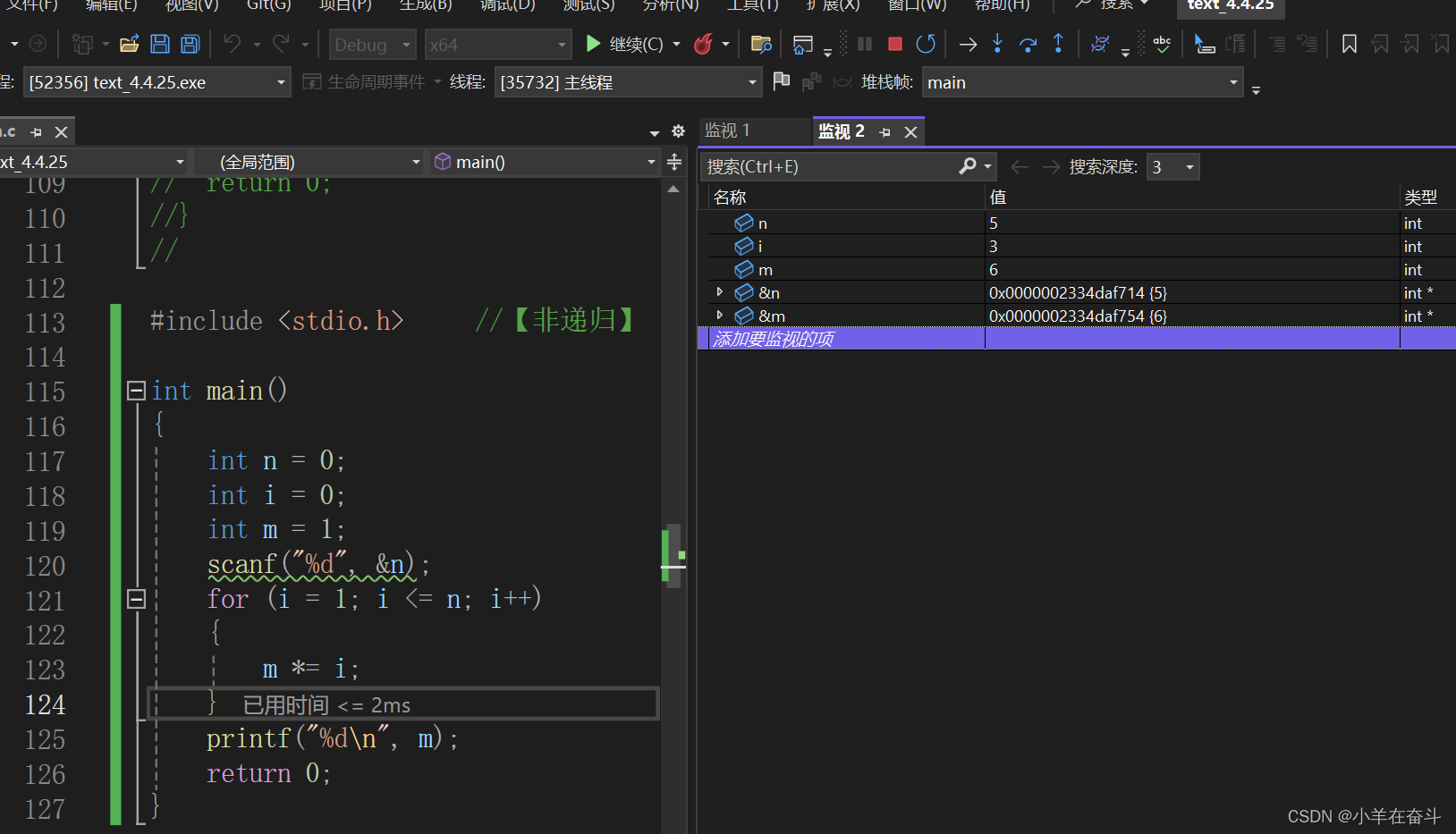
开始调试后,在菜单栏中【调试】—> 【窗口】—> 【监视】,打开任意一个监视窗口,输入想要观察的对象即可,加上取地址符还可以看到地址。
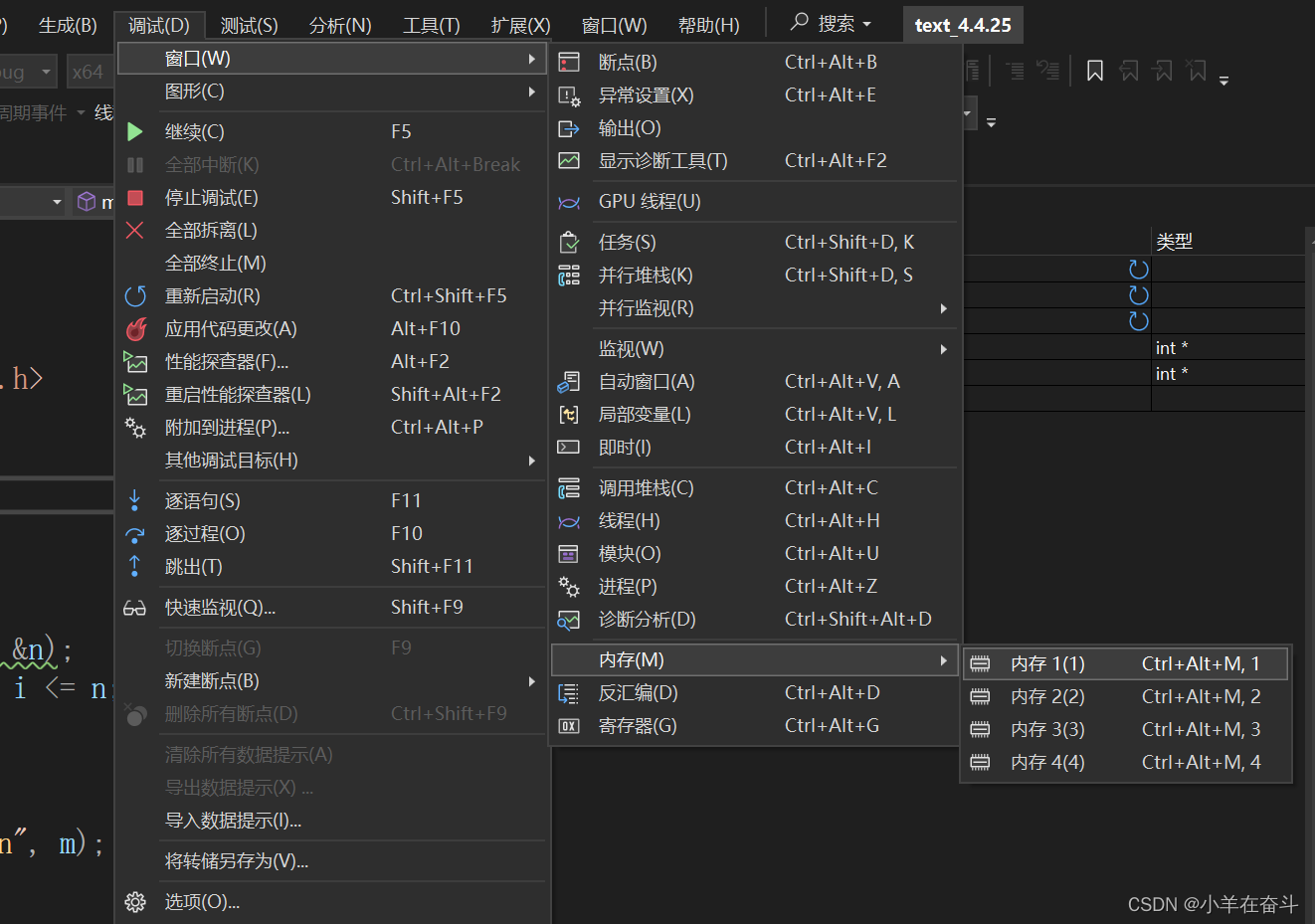
4.2内存
如果监视窗口看的不够仔细,还可以观察变量在内存中的存储情况,还是在【调试】—> 【窗口】—> 【内存】打开内存窗口:

5、调试举例
5.1示例一
在VS2022、x86、Debug 环境下,执行下面代码,结果会是什么呢?
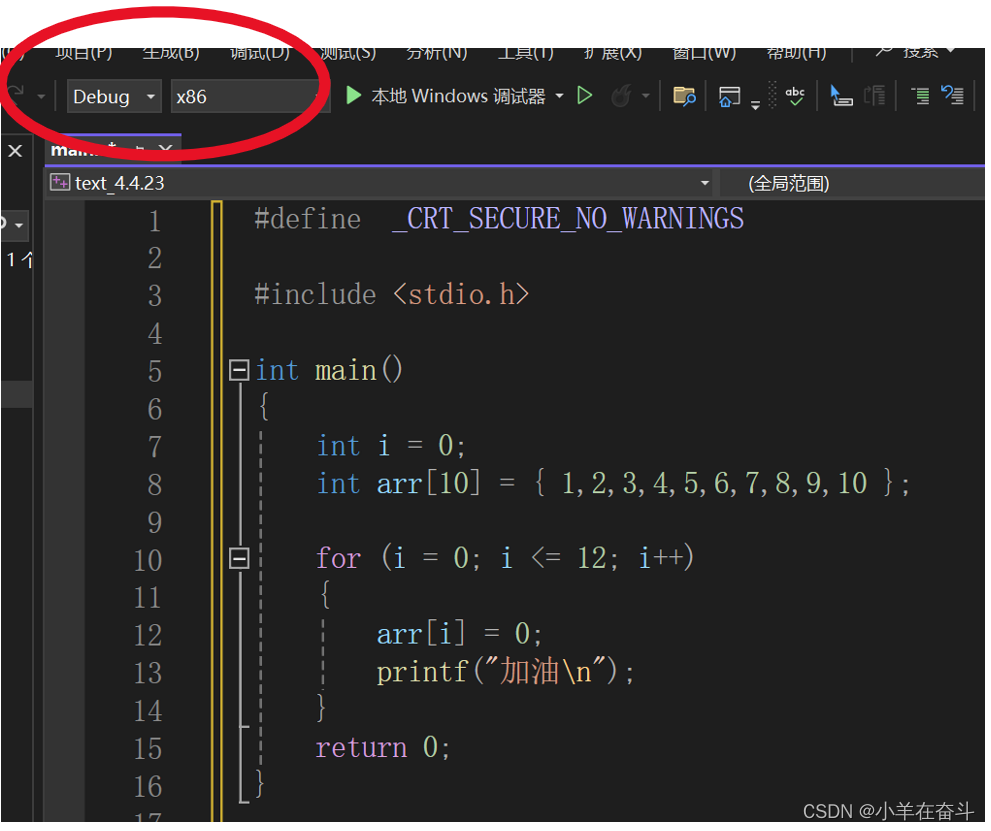
我们可以看到,数组是越界非法访问的,那么这一小段代码的执行结果是打印10个“加油”呢?还是13个“加油”呢?还是其他不可预测的结果?
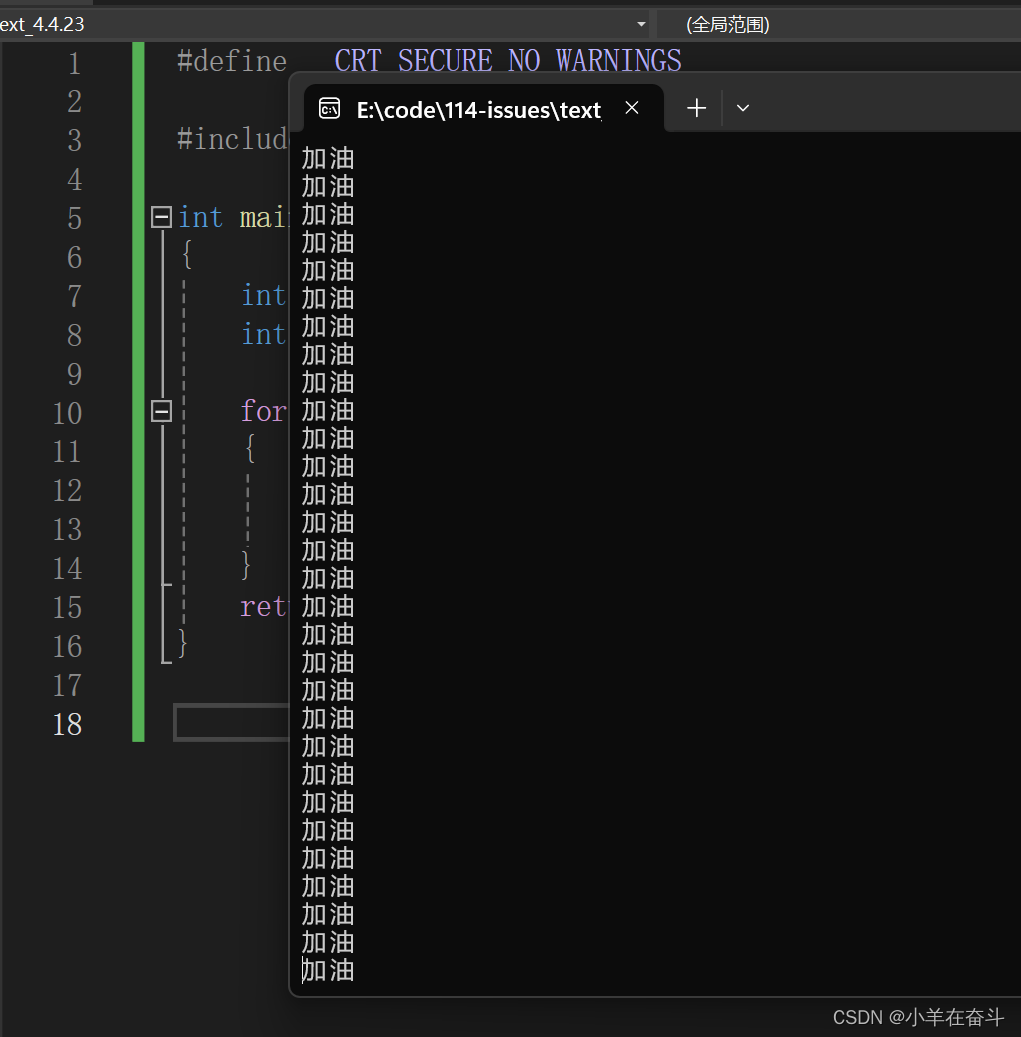
事实上当我们运行起来后屏幕上会一直打印“加油”,好像跟我们的猜测有很大的差别。那么为什么会发生这样的现象呢?像这种情况我们光靠脑子想是想不出来个所以然的,我们需要借助强大的调试功能。
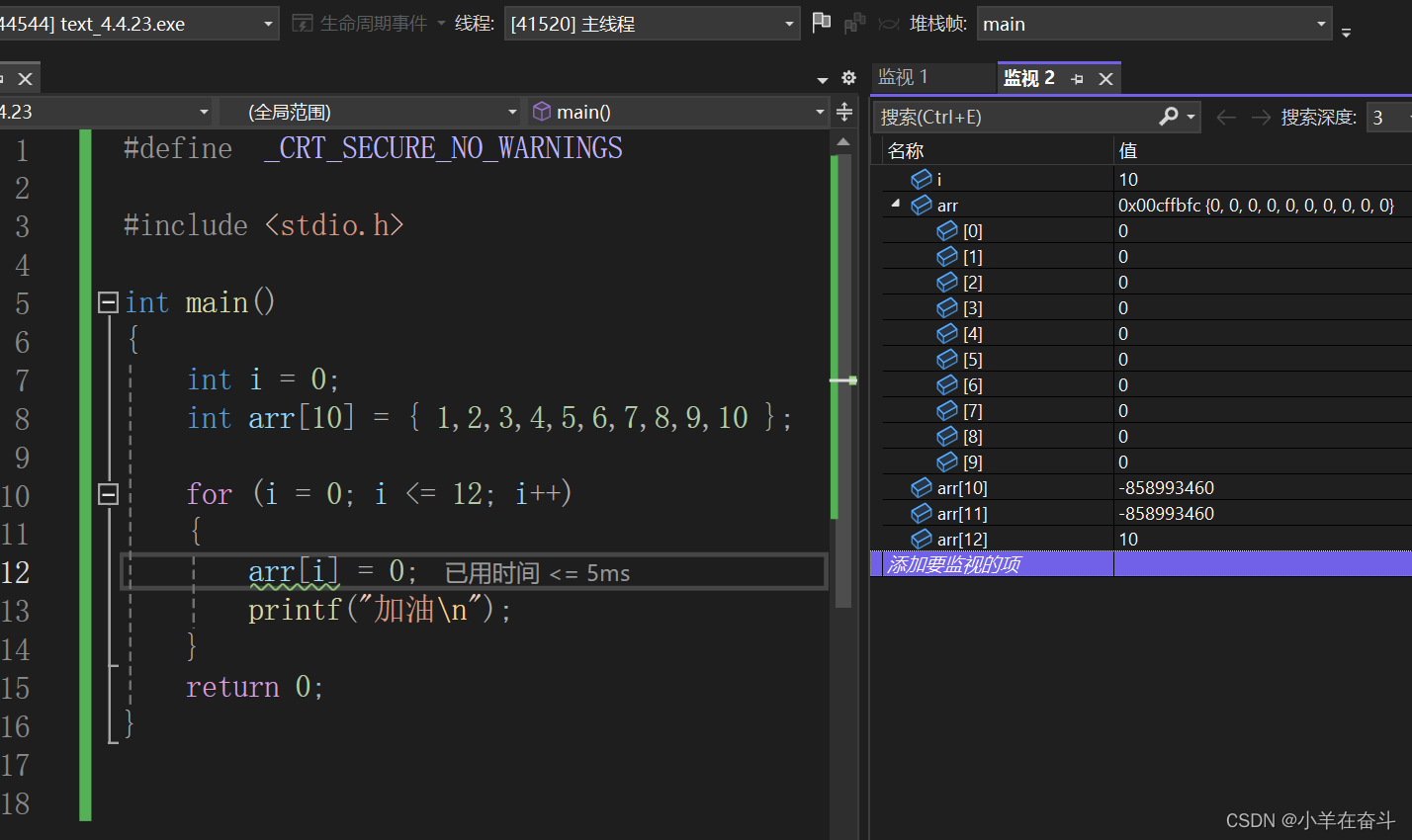
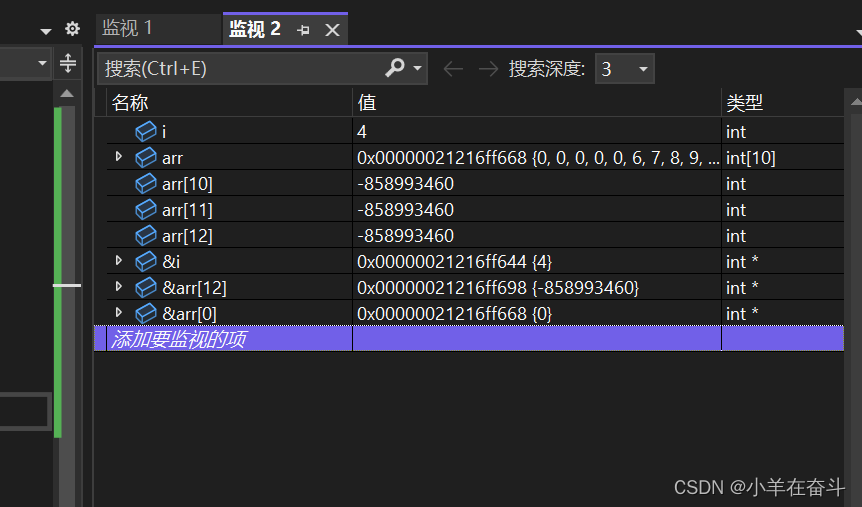
当我们按F10逐过程一直到 i 的值为10的时候,我们把 arr[10]、arr[11]、arr[12] 添加到监视,再按F10(此时已经是非法访问)的时候我们看到,arr[12] 的值一直跟着 i 的值在变化,这是为什么呢?我们把 i 的地址和 arr[12] 的地址添加到监视看一下:

i 的地址跟 arr[12] 的地址是一样的,所以说 i 跟 arr[12] 是等价的。当我们继续按F10给 arr[12] 赋0值后,i 的值也跟着变为0。如此循环下去,程序就陷入了死循环。
在之前的文章中我们已经简单了解过内存中的数据存储(数据和变量),我们这里再补充一下。
(1)局部变量存储在内存中的栈区,而栈区的使用习惯是从高地址向低地址使用的,所以我们先创建的变量 i 的地址是比较大的,arr 数组的地址整体是小于 i 的地址的;
(2)一维数组中我们知道,数组在内存中的存储规则是:随着下标的增大地址由低到高变化。再结合下面的图我们就能很好的理解。
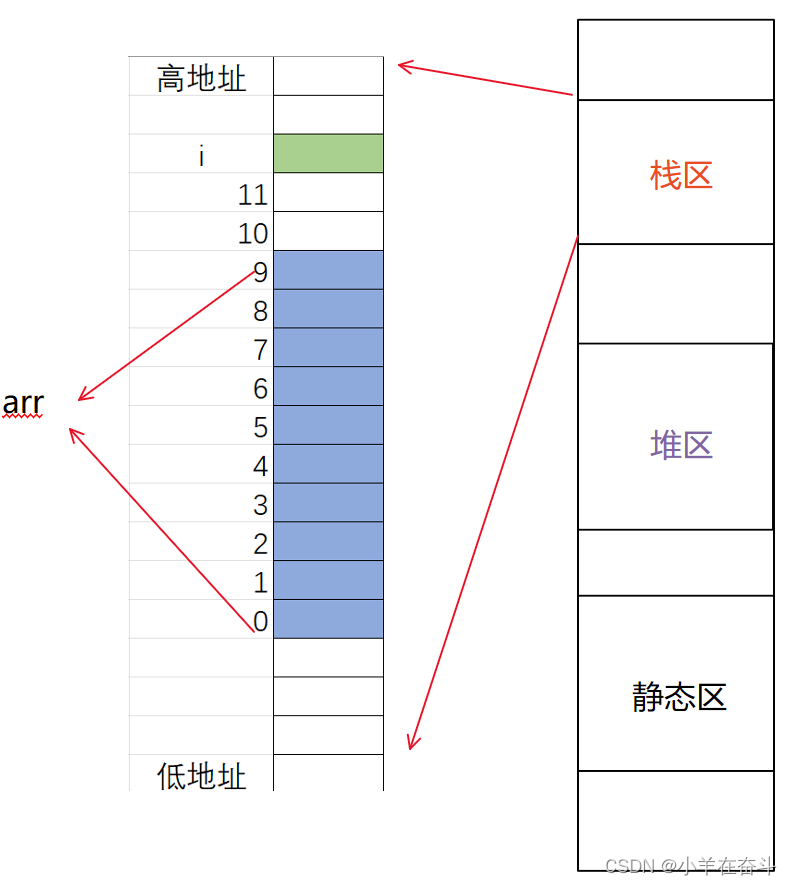
当数组 arr 的下标逐渐增大,地址越来越接近变量 i ,当下标为12的时候,arr[12] 就跟变量 i 的地址重合了,这时 arr[12] 就跟变量 i 是一个值,操作 arr[12] 就是操作变量 i 。
至于为什么 arr 数组和变量 i 之间恰好是2个 int 型的空间,这纯属是巧合,在不同的编译器中两者之间空出来的大小是不一样的。
注意:栈区的默认使用习惯是先使用高地址再使用低地址,但是这个具体还要看编译器的实现,比如:在VS上切换x64,这个使用的顺序就是相反的,在 Release 版本中,这个使用顺序也是相反的。
上面的程序是在x64环境下的,我们可以看到 arr[0] 的地址都比变量 i 的地址大。
5.2示例二
看下面的代码:
//【编写一个函数实现n的k次方,使用递归实现。】#include <stdio.h>int fun(int x, int y)
{if (1 == x || 0 == y){return 1;}else if (0 == x && 0 != y){return 0;}else{return x * fun(x, y--);}
}int main()
{int n = 0;int k = 0;scanf("%d %d", &n, &k);int m = fun(n, k);printf("%d\n", m);return 0;
}像我一样的新手乍一看可能觉得没什么问题(如果你已经看出了问题所在,还请不要声张),但是运行起来才发现有问题,程序陷入了死循环。我们来调试一下哪里出了问题:
第一步:F10开始调试;
第二步:输入我们想要观察的变量;

第三步:通过不断F10来观察变量值的变化,当变量的值与我们想要的不一样的时候,我们就找到了问题所在;
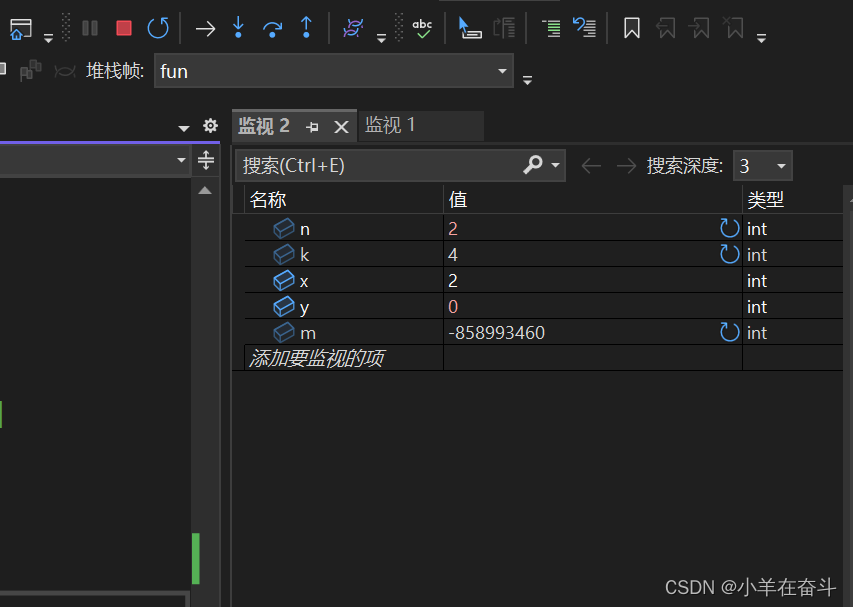
假如我们要求2的4次方:


当我们不断F10,执行了 return x * fun(x,y--);这条语句后,突然弹出了栈溢出的提示(栈溢出简单说是因为函数调用层级过深引起的,这里我们不作过多介绍,后面会有相关文章),那么问题应该就在这条语句中。
第四步:在知道问题所在后,就要分析其原因。
我们的想法是通过让形参 y 的值自减,来实现 x 自乘的次数。但我们知道,y-- 和 --y 确实能实现自减的效果,但两者是有很大区别的(如果你还不知道,罚你去看这篇文章 —> C语言基础),我们改正过来继续调试。
可以看到,在我们修改了错误后就实现了 y 不断自减的效果,现在我们写的程序就能执行我们想要的任务了。
总结:通过上面两个示例,只是想告诉大家调试是一个很强大的功能,就算是编程高手也不见得总是一次就能写成正确的代码,在不断地修改中才能解决所有的问题,而调试无疑是最好的助手。作为程序员,不使用调试或不会调试是万万不可的。同时,调试还可以让开发者深入了解程序的运行机制,提高编程技能和经验。
6、编程常见错误
6.1编译型错误
编译型错误一般是语法错误,这类错误一般看错误信息就能找到一些蛛丝马迹,双击错误信息也能初步跳转到代码错误的地方或附近。编译型错误,随着语句的熟练,会越来越少,也容易解决。例如缺少分号、使用未定义的变量等:
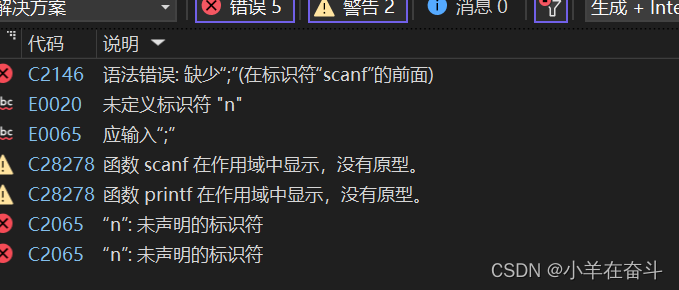
6.2链接型错误
看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。一般是因为标识符名不存在、拼写错误、头文件没包含、引用的库不存在等。
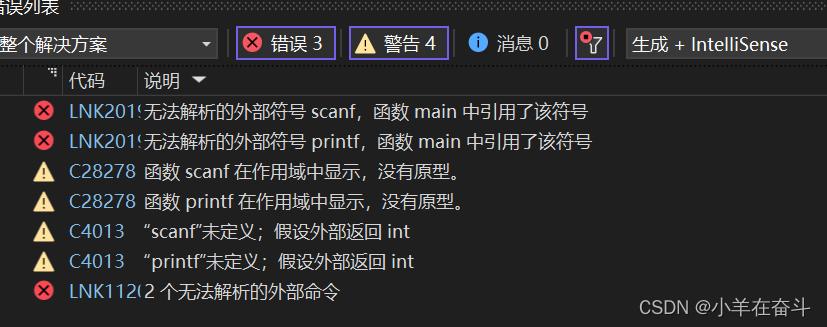
6.3运行时错误
运行时错误,是千变万化的,也是最难解决最令我们头疼的,需要借助调试,逐步定位问题。调试解决的是运行时问题,也就是说调试的前提是你的程序得先能运行起来,没有简单的语法和链接错误,然后才能调试。
点击跳转主页—> 💥个人主页:小羊在奋斗