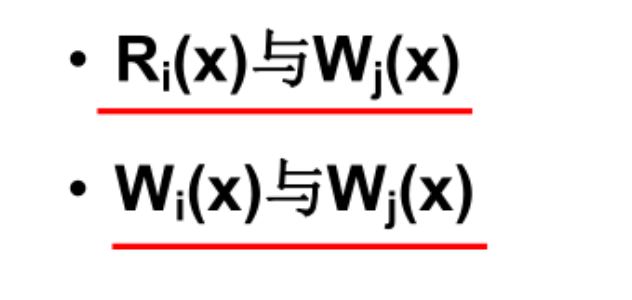在自然语言处理和特别是在使用Transformer模型中,位置编码(Positional Encoding)是一个关键的概念。它们的作用是为模型提供序列中各个元素的位置信息。由于Transformer架构本身并不像循环神经网络(RNN)那样具有处理序列的固有能力,位置编码因此显得尤为重要。
为什么需要位置编码?
Transformer模型依赖于自注意力机制来处理输入数据。自注意力机制本身只关注输入元素之间的关系,而不关心这些元素在序列中的顺序。例如,对于句子“the cat sat on the mat”,不使用位置信息,模型将无法区分“the cat sat on the mat”和“the mat sat on the cat”两句话的不同,因为这两句话具有完全相同的单词集合。因此,位置编码的引入是为了让Transformer理解单词在句子中的相对或绝对位置。
如何实现位置编码?
位置编码可以通过多种方式实现,其中一种常用的方法是使用正弦和余弦函数的组合来为每个位置生成一个唯一的编码。在原始的Transformer模型中,位置编码的定义如下:

引申:维度索引
在自然语言处理和其他相关的机器学习任务中,我们经常使用嵌入向量来表示词汇、句子或其他类型的输入。这些嵌入向量通常是高维的,意味着每个向量包含多个元素。每个元素代表向量中的一个特定维度。
例如,如果我们有一个128维的词嵌入向量,那么这个向量将包含128个独立的数值。每个数值都有一个“维度索引