Transformer step by step往期文章:
Transformer step by step--层归一化和批量归一化
要把Transformer中的Embedding说清楚,那就要说清楚Positional Embedding和Word Embedding。至于为什么有这两个Embedding,我们不妨看一眼Transformer的结构图。
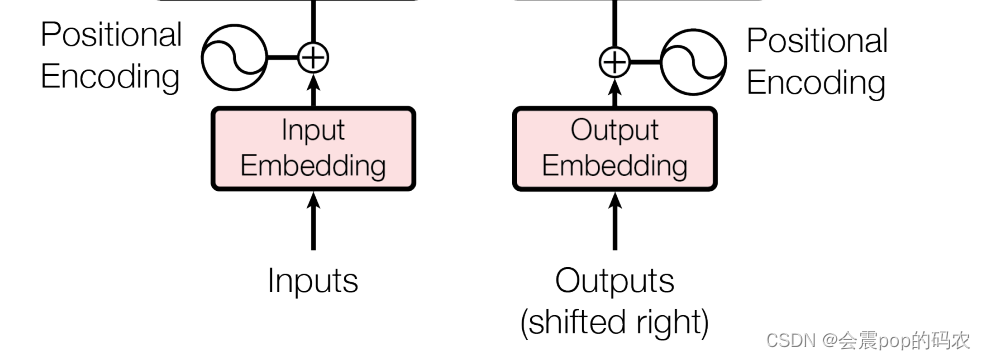
从上图可以看到,我们的输入需要在Input Embedding和Positional Encoding的共同作用下才会分别输入给Encoder和Decoder,所以我们就分别介绍一下怎么样进行Input Embedding和Positional Encoding。
同时为了帮助大家更好地理解这两种Embedding方式,我们这里生成一个自己的迷你数据集。
import tiktoken
import torch
import torch.nn as nn
encoding = tiktoken.get_encoding("cl100k_base") #导入openai的开源tokenizer库
context_length = 4 #选取4个token
batch = 4 # 批处理大小
example_text1 = "I am now writing an example to show the usage of word embedding."
example_text2 = "I am now writing an sentence to show the usage of another word embedding."
total_text = example_text1 + example_text2 #形成总数据集
tokenize_text = encoding.encode(total_text) #进行tokenize
tokenize_text = torch.tensor(tokenize_text, dtype=torch.long) #这里转换成tentor是因为后续我们要用pytorch的框架
idxs = torch.randint(low = 0,high = len(tokenize_text) - context_length,size = (batch,))#这里我们随机选batch个id
x_batch = torch.stack([tokenize_text[idx:idx + context_length] for idx in idxs]) #根据id和context_length抽取训练数据一、Word Embedding
这里的Word Embedding就是论文中提到的Input Embedding。我们在之前的文章中已经介绍使用tokenizer将原始的文本信息转换为数字,便于输入进模型。 可是使用tokenizer有一个问题,这个问题就是我们虽然用不同的ID表示了不同的子词,但是这些ID所能蕴含的语义信息非常有限,比如dog和dogs这两个单词语义非常相近,但很有可能它们的ID相隔非常远,所以为了更好地体现不同单词之间的语义关系,我们将每个ID通过Word Embedding的方式变为一个向量。
这里的实现在Pytorch框架之下变得非常简单,只需要一行代码就可以搞定,但是我们这里还是详细对代码的参数进行一些讲解。
max_token_value = tokenize_text.max().item()
d_model = 16
input_embedding_lookup_table = nn.Embedding(max_token_value + 1, d_model)
x_batch_embedding = input_embedding_lookup_table(x_batch)
print(max_token_value)
#
40188这里的第一、二行我们一起讲:
max_token_value = tokenize_text.max().item()是取出当前token中ID最大的那个数。
input_embedding_lookup_table = nn.Embedding(max_token_value + 1, d_model)是根据最大的ID去构建Embedding层。
首先第一个问题,nn.Embedding的两个参数是什么意思?
首先第一个参数我们这里使用的是 max_token_value + 1,这个是用来表示我们词汇库的最大长度。那这里可能又有一个新的问题,就是我们上面的句子,算上标点符号一共也就十几个词,为什么我们这里要用40188+1作为这个词汇库的最大长度呢?这是因为我们这里用的tokenizer是openai的第三方库,这个库在做tokenize的时候对应着大量的原始文本,而我们example_text中的文本在经过tokenize之后,最大的token ID对应的是这个库中的原始文本的40188。那么这里还有第二个问题,这里返回的是40188,我们为什么要加上1呢?因为tokenize之后的ID是从0开始算的,也就是说40188对应的词汇表的最大长度应该是40189。
第二个参数我们使用的是d_model,这个参数会好理解一些。我们之前说过,一个ID没有什么语义信息,但变成向量之后就可以通过余弦相似度计算两个向量之间的相关性。那么这里的一个问题就在于,我用多少维的向量去表示呢?d_model这个参数就是来解决这个事情,我们想让ID变成多少维的向量,就把d_model设置成多少。
那么第三行,就是我们讲原来形状为4 * 4的x_batch变为了4 * 4 * 16 的x_batch_embedding。后面多出来的16就是我们自己设置的嵌入的维度。
二、Positional Embedding
总体来说,word_embedding还是比较通俗易懂的,接下来我们根据论文当中的公式去写一下Positional Encoding,也就是Positional Embedding(同一个意思)。

这里我们解释一下这两行公式啥意思,Positional Embedding简单来说,就是给每个token分配一个位置信息,因为 𝑠𝑒𝑙𝑓 - 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 本身无法判断不同token所在的位置。PE对应Positional Encoding的缩写,括号中的pos对应我们设置的context length的长度,2i对应嵌入维度中的偶数维度,2i+1对应嵌入维度中的奇数维度。
接下来我们就来实现一下相关的代码:
positional_encoding = torch.zeros(context_length, d_model) #首先初始化一个和token形状大小一样的positional encoding
positional = torch.arange(0, context_length).float().unsqueeze(1) #按照我们设置的context length去初始化position
_2i = torch.arange(0, d_model, 2) # 这里用生成d_model/2的步长,因为sin和cos两个加起来就变成了d_model
positional_encoding[:, 0::2] = torch.sin(torch.exp(positional/10000**(_2i/d_model))) #按照公式写一遍
positional_encoding[:, 1::2] = torch.cos(torch.exp(positional/10000**(_2i/d_model)))
positional_encoding = positional_encoding.squeeze(0).expand(batch, -1, -1) #最终根据batch的数量对维度进行扩充
input_x = x_batch_embedding + positional_encoding # 将word embedding和positional embedding相加得到模型的输入
print(positional_encoding.shape)
print(input_x.shape)
##
torch.Size([4, 4, 16])
torch.Size([4, 4, 16]) 到这里,我们也就完成了两个embedding操作。
知乎原文链接:安全验证 - 知乎知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视、时尚、文化等领域最具创造力的人群,已成为综合性、全品类、在诸多领域具有关键影响力的知识分享社区和创作者聚集的原创内容平台,建立起了以社区驱动的内容变现商业模式。![]() https://zhuanlan.zhihu.com/p/691169616
https://zhuanlan.zhihu.com/p/691169616