目录
一、集合介绍
二、List
三、Map
HashMap的数据结构
如何理解红黑树
四、set
一、集合介绍
在Java中,集合是一种用于存储对象的数据结构,它提供了一种更加灵活和强大的方式来处理和操作数据。Java集合框架提供了一系列接口和类,用于表示和操作不同类型的集合。

图片来源:《面渣逆袭手册》V1.1
List :存储的元素有序,可重复。(相当于是个篮子,临时给你放数据用的 )Set :存储的元素无序,不可重复。(去重的List,放进去的东西如果一样,后面的会把前面的覆盖掉,得到的是个无重复值的列表 )Map 是另外的接口,是键值对映射结构的集合。(Map是个键值对,可以实现用a来搜b的作用,比如用用户的id搜用户的名称之类的操作 )
以下是Java中常见的集合:
-
List(列表):
ArrayList:基于数组实现的动态数组,支持快速随机访问元素,但插入和删除操作效率较低。LinkedList:基于链表实现的双向列表,插入和删除操作效率较高,但访问元素的效率较低。Vector:与ArrayList类似,但是线程安全的,不推荐在新代码中使用。Stack:基于Vector实现的栈,通常用于实现后进先出(LIFO)的数据结构。
-
Set(集合):
HashSet:基于哈希表实现的集合,不保证元素的顺序。TreeSet:基于红黑树实现的有序集合,可以按照自然顺序或者自定义顺序对元素进行排序。LinkedHashSet:具有预期插入顺序的集合,内部使用链表维护元素的顺序。
-
Map(映射):
HashMap:基于哈希表实现的映射,键值对无序。TreeMap:基于红黑树实现的有序映射,键值对按照键的自然顺序或者自定义顺序进行排序。LinkedHashMap:具有预期插入顺序的映射,内部使用链表维护键值对的顺序。
-
Queue(队列):
PriorityQueue:基于堆实现的优先级队列,按照元素的优先级顺序进行排序。
此外,Java集合框架还包括一些接口和抽象类,如 Collection、Map、Iterator 等,它们提供了一组通用的操作和方法,可以方便地对集合进行操作和遍历。
二、List
在 Java 中,ArrayList 和 LinkedList 是两种常见的集合实现,它们有以下主要区别:
- 内存分配:
ArrayList:使用连续的内存空间来存储元素。LinkedList:使用链式存储结构,内存空间不连续,它们在空间占用上都有一些额外的消耗。- ArrayList 是预先定义好的数组,可能会有空的内存空间,存在一定空间浪费LinkedList 每个节点,需要存储前驱和后继,所以每个节点会占用更多的空间
- 随机访问:
ArrayList:基于数组,所以它可以根据下标查找,支持快速的随机访问,通过索引可以快速获取元素。LinkedList:基于链表,所以它没法根据序号直接获取元素,在随机访问方面效率较低。
- 插入和删除:
- 多数情况下,ArrayList更利于查找,LinkedList更利于增删。
- ArrayList 基于数组实现, get(int index) 可以直接通过数组下标获取,时间复杂度是 O(1) ; LinkedList 基于链表实现, get(int index) 需要遍历链表,时间复杂度是O(n) ;当然, get(E element) 这种查找,两种集合都需要遍历,时间复杂度都是O(n) 。
- ArrayList增删如果是数组末尾的位置,直接插入或者删除就可以了,但是如果插入中间的位置,就需要把插入位置后的元素都向前或者向后移动,甚至还有可能触发扩容;双向链表的插入和删除只需要改变前驱节点、后继节点和插入节点的指向就行了,不需要移动元素。
-

-

- 图片来源:《面渣逆袭手册》V1.1
- 内存占用:
ArrayList:需要预先分配一定的内存空间,如果元素数量超过容量,需要进行扩容。基于数组的集合,数组的容量是在定义的时候确定的,如果数组满了,再插入,就会数组溢出。所以在插入时候,会先检查是否需要扩容,如果当前容量+1 超过数组长度,就会进行扩容。- ArrayList的扩容是创建一个1.5倍的新数组,然后把原数组的值拷贝过去。
LinkedList:不需要预先分配固定的内存空间。
- 遍历方式:
ArrayList:可以通过索引或迭代器进行遍历。LinkedList:还可以通过指针依次访问元素。
示例代码如下:-
import java.util.ArrayList; import java.util.LinkedList; import java.util.List;public class CollectionExample {public static void main(String[] args) {// 使用 ArrayListList<String> arrayList = new ArrayList<>();arrayList.add("Apple");arrayList.add("Banana");arrayList.add("Orange");System.out.println("使用 ArrayList 遍历:");for (String item : arrayList) {System.out.println(item);}// 使用 LinkedListList<String> linkedList = new LinkedList<>();linkedList.add("Apple");linkedList.add("Banana");linkedList.add("Orange");System.out.println("\n 使用 LinkedList 遍历:");for (String item : linkedList) {System.out.println(item);}} }
三、Map
在 Java 中,常见的 Map 实现有 HashMap 和 TreeMap 。
HashMap 基于哈希表实现,它的数据结构如下:
- 存储键值对。
- 通过哈希函数计算键的哈希值,以确定元素在哈希表中的存储位置。
TreeMap 基于红黑树实现,它的数据结构如下:
- 按照键的自然顺序进行排序。
- 提供有序的键值对访问。
HashMap的数据结构
数据结构示意图如下:

图片来源:《面渣逆袭手册》V1.1
哈希表的基本原理是通过哈希函数将键映射到特定的存储位置,以实现快速的插入、查找和删除操作。
哈希函数用于计算键的哈希值,并根据哈希值确定元素在哈希表中的存储位置。哈希表通常包含以下组件:
- 数组:用于存储元素。
- 哈希函数:将键转换为数组的索引。
- 冲突处理机制:处理不同键可能映射到相同索引的冲突。
在插入元素时,通过哈希函数计算键的哈希值,确定存储位置。如果该位置为空,则直接插入元素;如果存在冲突,使用冲突处理机制解决。
在查找元素时,同样通过哈希函数计算哈希值,找到对应的位置进行查找。
哈希表的优点包括:
- 快速的插入、查找和删除操作。
- 不需要按照特定顺序存储元素。
如何理解红黑树
- 颜色规则:每个节点要么是红色,要么是黑色。
- 特性规则:
- 根节点是黑色的。
- 如果一个节点是红色的,那么它的子节点必须是黑色的。
- 从每个叶子节点到根节点的所有路径上,黑色节点的数量相同。
在进行插入或删除操作时,红黑树会通过一系列的旋转和颜色调整来保持这些规则,以确保树的平衡性。
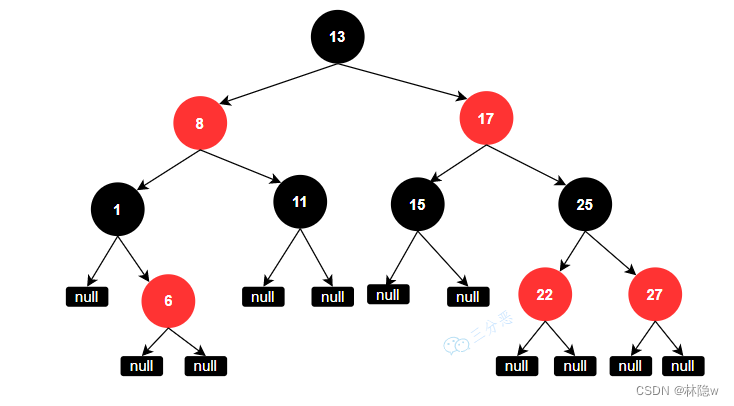
图片来源:《面渣逆袭手册》V1.1
旋转操作包括左旋和右旋,用于调整树的结构。
红黑树有两种方式保持平衡: 旋转 和 染色 。通过保持红黑树的平衡性,可以提高搜索、插入和删除操作的效率,避免出现最坏情况下的线性搜索。
有关HashMap的知识点非常多,这里不做详述,后面会单独写一篇有关HashMap的相关内容。
哈希表在以下场景中比较适用:
- 快速查找:当需要快速查找数据时,哈希表可以提供高效的查找性能。
- 存储和检索数据:适用于需要频繁地插入、删除和查找数据的场景。
- 缓存:可以用于缓存数据,以提高系统的性能。
- 统计频率:用于统计元素的出现频率。
- 数据去重:去除重复的数据。
- 关联数据:建立键值对的关联。
例如,在以下场景中可能会使用哈希表:- 数据库索引:加速数据的查询。
- 缓存系统:提高数据的访问速度。
- 网页搜索引擎:快速检索和索引网页。
- 数据处理和分析:高效地处理大量数据。
四、set
HashSet 是 Java 中的一个集合类,它不允许存储重复的元素。HashSet 底层就是基于 HashMap 实现的。( HashSet 的源码⾮常⾮常少,因为除了 clone() 、 writeObject() 、 readObject() 是 HashSet⾃⼰不得不实现之外,其他⽅法都是直接调⽤ HashMap 中的⽅法。
HashSet的add方法,直接调用HashMap的put方法,将添加的元素作为key,new一个 Object作为value,直接调用HashMap的put方法,它会根据返回值是否为空来判断是否插入元素成功。
以下是 HashSet 的一些特点:
- 无序性:元素的存储顺序是无序的。
- 不允许重复元素:确保每个元素在集合中唯一。
- 基于哈希表实现:提供快速的插入、查找和删除操作。
参考
《面渣逆袭手册》V1.1.pdf